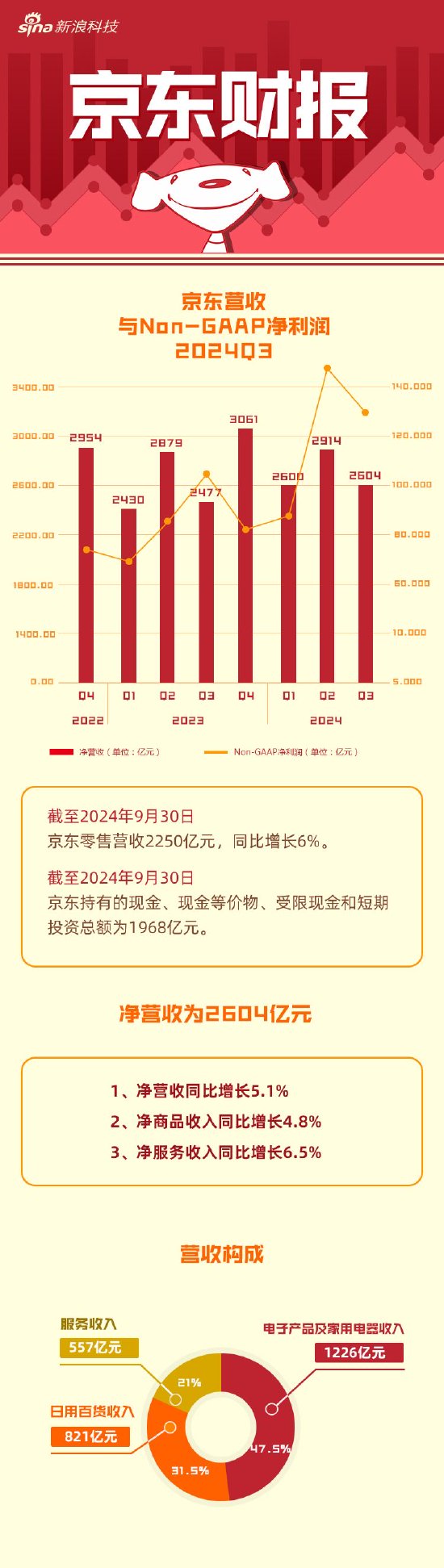
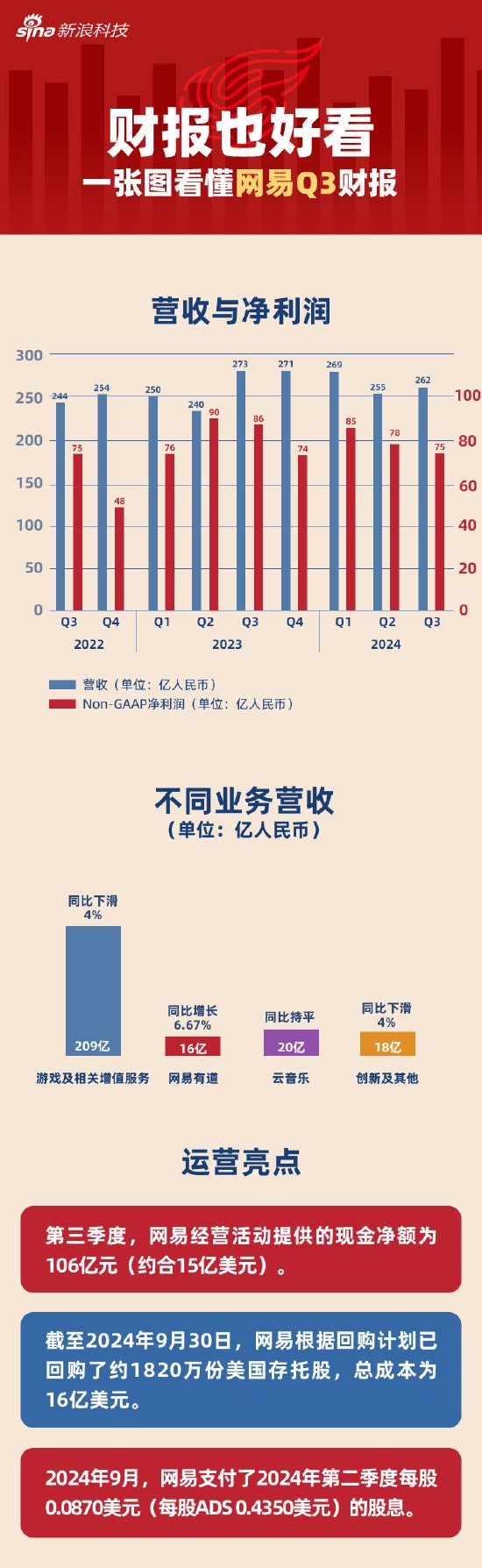
OpenAI最新產品全曝光,秘密尋找下一個重大突破
今年AI圈的瓜真是一浪接一浪。
最近,關於Scaling Laws「撞牆」的消息在AI圈炸開了鍋。圖靈獎得主Yann Lecun、Ilya、Anthropic創始人Dario Amodei紛紛展開唇槍舌戰。
爭論的核心在於,隨著模型規模的不斷擴大,其性能提升是否會遇到天花板。
正當輿論愈演愈烈之際,OpenAI CEO Sam Altman剛剛在X平台作出回應:
there is no wall沒有牆

而在這場辯論的背景下,彭博社則披露了一條引人注目的消息。
OpenAI計劃在明年一月份推出一款名為「Operator」的AI Agent(智能體),這個Agent能夠使用計算機代替用戶執行任務,如編寫代碼或預訂旅行。
在此之前,Anthropic、微軟、Google也都被曝出正在佈局類似的方向。
對於整個AI行業來說,AI技術的發展從來就不是單一維度的線性過程。當一個方向似乎遇到阻力時,創新往往會在其他維度突破。
Scaling Laws撞牆?下一步該怎麼走
Scaling Laws遭遇瓶頸的消息,最先源自外媒The Information上週末的一篇報導。
洋洋灑灑的數千字報導透露了兩個關鍵信息。
好消息是,儘管OpenAI完成了下一代模型Orion訓練過程的20%,但Altman表示,Orion在智能和執行任務、回答問題的能力已經與GPT-4不相上下。
壞消息是,據上手體驗的OpenAI員工評估,與GPT-3和GPT-4之間的巨大進步相比,Orion提升幅度較小,比如在編程等任務上表現不佳,且運行成本較高。
一句話概括就是,Scaling Laws撞牆了。
要理解Scaling Laws效果不及預期所帶來的影響,我們有必要給不太清楚的朋友簡單介紹一下Scaling Laws基本概念。
2020年,OpenAI在一篇論文中最早提出Scaling Laws。
這一理論指出,大模型的最終性能主要與計算量、模型參數量和訓練數據量三者的大小相關,而與模型的具體結構(層數/深度/寬度)基本無關。
聽著有些拗口,說人話就是,大模型的性能會隨著模型規模、訓練數據量和計算資源的增加而相應提升。

OpenAI的這項研究奠定了後續大模型發展的基礎,不僅促成了GPT系列模型的成功,也為訓練ChatGPT提供了優化模型設計與訓練的關鍵指導原則。
只是,當我們現在還在暢想著GPT-100時,The Information的爆料表明,僅僅增加模型規模已經不能保證性能的線性提升,且伴隨著高昂成本和顯著的邊際效益遞減。
而遭遇困境的並非僅有OpenAI一家。
彭博社援引知情人士的消息稱,Google旗下的Gemini 2.0同樣未能達到預期目標,與此同時,Anthropic旗下的Claude 3.5 Opus的發佈時間也一再推遲。
在爭分奪秒的AI行業,沒有產品的新消息往往意味著最大的壞消息。

需要明確的是,這裏所說的Scaling Laws遇到瓶頸並非意味著大模型發展就此終結,更深層的問題在於高昂成本導致邊際效益的嚴重遞減。
Anthropic CEO Dario Amodei曾透露,隨著模型變得越來越大,訓練成本呈現爆炸式增長,其目前正在開發的AI模型的訓練成本就高達10億美元。
Amodei還指出,未來三年內,AI的訓練成本還將飆升到100億美元甚至1000億美元。
以GPT系列為例,僅GPT-3的單次訓練成本就高達約140萬美元,單是GPT-3的訓練就消耗了1287兆瓦時的電力。
去年,加州大學河濱分校的研究顯示,ChatGPT每與用戶交流25-50個問題,就得消耗500毫升的水。
預計到2027年,全球AI的年度清潔淡水需求量可能達到4.2-66億立方米,相當於4-6個丹麥或半個英國的年度用水總量。
從GPT-2到GPT-3,再到GPT-4,AI所帶來的體驗提升是跨越式的。正是基於這種顯著的進步,各大公司才會不惜重金投入AI領域。
但當這條道路逐漸顯露盡頭,單純追求模型規模的擴張已無法保證性能的顯著提升,高昂的成本與遞減的邊際效益便成了不得不面對的現實。
現在,比起一味追求規模,在正確的方向上實現Scaling顯得更加重要。
再見,GPT;你好,推理「O」
牆倒眾人推,連理論也是如此。
當Scaling Laws疑似觸及瓶頸的消息在AI圈內引發軒然大波時,質疑的聲浪也隨之翻湧而來。
圖靈獎得主、Meta AI首席科學家Yann Lecun,昨天興奮地在X平台轉載了路透社採訪Ilya Sutskever的採訪,並附文稱:
「我不想顯得事後諸葛亮,但我的確提醒過你。
引用:「AI實驗室Safe Superintelligence(SSI)和OpenAI的聯合創始人伊利亞·蘇茨克韋爾(Ilya Sutskever)最近向路透社表示,通過擴大預訓練階段——即使用大量未經標註的數據來訓練AI模型,使其理解語言模式和結構——所取得的成果已經停滯不前。」

回顧這位AI巨頭過去兩年對現行大模型路線的評判,可謂是字字珠璣,句句見血。
例如,今天的AI比貓還笨,智力差太遠;LLM缺乏對物理世界的直接經驗,只是操縱著文字和圖像,卻沒有真正理解世界,強行走下去只會死路一條等等。
時間撥回兩個月前,Yann Lecun更是毫不客氣地給當下主流路線判了死刑:
-
大型語言模型(LLMs)無法回答其訓練數據中未包含的問題;
-
它們無法解決未經訓練的難題;
-
它們無法在缺乏大量人類幫助的情況下學習新技能或知識;
-
它們無法創造新的事物。目前,大型語言模型只是人工智能技術的一部分。單純地擴大這些模型的規模,並不能使它們具備上述能力。
在一眾AI末日論中,他還堅定地認為聲稱AI將威脅人類生存的言論純屬無稽之談。
同在Meta FAIR任職的田淵棟博士則更早預見了當前的困境。
5月份在接受媒體採訪時,這位華人科學家曾悲觀地表示,Scaling Laws也許是對的,但不會是全部。在他看來,Scaling Laws的本質是以指數級的數據增長,來換取「幾個點的收益」。
最終人類世界可能會有很多長尾需求,需要人類的快速反應能力去解決,這些場景的數據本身也很少,LLM拿不到。
Scaling law發展到最後,可能每個人都站在一個「數據孤島」上,孤島里的數據完全屬於每個人自己,而且每時每刻都不停產生。
專家學會和AI融合,把自己變得非常強,AI也代替不了他。
不過,形勢或許還沒有到如此悲觀的境地。
客觀而言,Ilya在接受路透社的採訪時,雖然承認了Scaling Laws帶來的進展已趨於停滯,但並未宣告其終結。
「2010年代是追求規模化的時代,而現在我們再次進入了一個充滿奇蹟和探索的新時代。每個人都在尋找下一個重大突破。
在當下,選擇正確的事物進行規模化比以往任何時候都更為關鍵。」
並且,Ilya還表示SSI正在秘密探索一種新的方法來擴展預訓練過程。
Dario Amodei最近在一檔播客中也談及此事。
他預測,在人類水平以下,模型並不存在絕對的天花板。既然模型尚未達到人類水平,就還不能斷言Scaling Laws已經失效,只是確實出現了增長放緩的現象。
自古,山不轉水轉,水不轉人轉。
上個月,OpenAI的研究員Noam Brown在TED AI大會上表示:
事實證明,在一局撲克中,讓一個機器人思考20秒鍾,得到的性能提升與將模型擴展100000倍並訓練它100000倍長的時間一樣。
而對於Yann lecun昨天的事後諸葛亮言論,他這樣回應:
現在,我們處於一個這樣的世界,正如我之前所說,進入大規模語言模型預訓練所需的計算量非常非常高。但推理成本卻非常低。
曾有許多人合理地擔心,隨著預訓練所需的成本和數據量變得如此龐大,我們會看到AI進展的回報遞減。
但我認為,從o1中得到的一個真正重要的啟示是,這道牆並不存在,我們實際上可以進一步推動這個進程。
因為現在,我們可以擴展推理計算,而且推理計算還有巨大的擴展空間。
以Noam Brown為代表的研究者堅信推理/測試時計算(test-time compute),極有可能成為提升模型性能的另一個靈丹妙藥。
說到這裏,就不得不提到我們熟悉的OpenAI o1模型。
與人類的推理方式頗為相似,o1模型能夠通過多步推理的方式「思考」問題,它強調在推理階段賦予模型更充裕的「思考時間」。
其核心秘密是,在像GPT-4這樣的基礎模型上進行的額外訓練。
例如,模型可以通過實時生成和評估多個可能的答案,而不是立即選擇單一答案,最終選擇最佳的前進路徑。
這樣就能夠將更多的計算資源集中在複雜任務上,比如數學問題、編程難題,或者那些需要人類般推理和決策的複雜操作。

Google最近也在效仿這條路線。
The Information報導稱,最近幾週,DeepMind在其Gemini部門內組建了一個團隊,由Jack Rae和Noam Shazeer領導,旨在開發類似的能力。
與此同時,不甘落後的Google正在嘗試新的技術路徑,包括調整「超參數」,即決定模型如何處理信息的變量。
比如它在訓練數據中的不同概念或模式之間建立聯繫的速度,以查看哪些變量會帶來最佳結果。
插個題外話,GPT發展放緩的一個重要原因是高質量文本和其他可用數據的匱乏。
而針對這個問題,Google研究人員原本寄希望於使用AI合成數據,並將音頻和影片納入Gemini的訓練數據,以實現顯著改進,但這些嘗試似乎收效甚微。
知情人士還透露,OpenAI和其他開發者也使用合成數據。不過,他們也發現,合成數據對AI模型提升的效果十分有限。
你好,賈維斯
再見,GPT,你好,推理「o」。
在前不久舉行的Reddit AMA活動上,一位網民向Altman提問,是否會推出「GPT-5」,以及推理模型o1的完整版。
當時,Altman回答道:「我們正在優先推出o1及其後續版本」,並補充說,有限的計算資源使得同時推出多個產品變得困難。
他還特別強調,下一代模型未必會延續「GPT」的命名方式。

現在看來,Altman急於與GPT命名體系劃清界限,轉而推出以「o」命名的推理模型,其背後似有深意。而推理模型的佈局或許還是在於為當下主流的Agent埋下伏筆。
最近,Altman在接受YC總裁Garry Tan的採訪時,也再次談到了AGI五級理論:
-
L1:聊天機器人具有對話能力的AI,能夠與用戶進行流暢的對話,提供信息、解答問題、輔助創作等,比如聊天機器人。
-
L2:推理者像人類一樣能夠解決問題的AI,能夠解決類似於人類博士水平的複雜問題,展現出強大的推理和問題解決能力,比如OpenAI o1。
-
L3:智能體不僅能思考,還可以採取行動的AI系統,能夠執行全自動化業務。
-
L4:創新者能夠協助發明創造的AI,具有創新的能力,可以輔助人類在科學發現、藝術創作或工程設計等領域產生新想法和解決方案。
-
L5:組織者可以完成組織工作的AI,能夠自動掌控整個組織跨業務流程的規劃、執行、反饋、迭代、資源分配、管理等,基本上已經與人類差不多。
所以我們看到,與Google以及Anthropic一樣,OpenAI現在正在將注意力從模型轉移到一系列稱為Agent的AI工具上。
今天淩晨,彭博社曝出,OpenAI正在準備推出一款名為「Operator」的新型AI Agent,能夠使用計算機代替用戶執行任務,如編寫代碼或預訂旅行。
在週三的一次員工會議上,OpenAI領導層宣佈計劃在一月發佈該工具的研究預覽版,並通過公司的應用程序接口(API)向開發者開放。
在此之前,Anthropic也推出了類似的Agent,能夠實時處理用戶計算機任務並代為執行操作。與此同時,微軟近期推出了一套面向員工的Agent工具,用於發送郵件和管理記錄。
而Google也正在籌備推出自己的AI Agent。
報導還透露,OpenAI正在進行多個與Agent相關的研究項目。其中,最接近完成的是一款能夠在網頁瀏覽器中執行任務的通用工具。
這些Agent預計將能夠理解、推理、規劃並採取行動,而這些Agent實際上是一個由多個AI模型組成的系統,並非單一模型。
比爾·蓋茨曾經說過,「每個桌面上都有一台PC」,史提芬·祖比斯說過,「每個人的手上都有一部智能手機」。
現在我們可以大膽預測:每個人都將擁有自己的AI Agent。
當然,人類的終極目標是,我們更希望有一天能夠對著眼前的AI說出那句電影的經典對白:
你好,賈維斯