率先解決多類數據同時受損,中科大MIRA團隊TRACER入選NeurIPS 2024:強魯棒性的離線變分貝葉斯強化學習
AIxiv專欄是機器之心發佈學術、技術內容的欄目。過去數年,機器之心AIxiv專欄接收報導了2000多篇內容,覆蓋全球各大高校與企業的頂級實驗室,有效促進了學術交流與傳播。如果您有優秀的工作想要分享,歡迎投稿或者聯繫報導。投稿郵箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
本論文作者楊睿是中國科學技術大學 2019 級碩博連讀生,師從王傑教授、李斌教授,主要研究方向為強化學習、自動駕駛等。他曾以第一作者在 NeurIPS、KDD 等頂級期刊與會議上發表論文兩篇,曾獲滴滴精英實習生(16/1000+)。
近日,中科大王傑教授團隊 (MIRA Lab) 針對離線強化學習數據集存在多類數據損壞這一複雜的實際問題,提出了一種魯棒的變分貝葉斯推斷方法,有效地提升了智能決策模型的魯棒性,為機器人控制、自動駕駛等領域的魯棒學習奠定了重要基礎。論文發表在 CCF-A 類人工智能頂級會議 Neural Information Processing Systems(NeurIPS 2024)。

-
論文地址:https://arxiv.org/abs/2411.00465
-
代碼地址:https://github.com/MIRALab-USTC/RL-TRACER
引言
在機器人控制領域,離線強化學習正逐漸成為提升智能體決策和控制能力的關鍵技術。然而,在實際應用中,離線數據集常常由於傳感器故障、惡意攻擊等原因而遭受不同程度的損壞。這些損壞可能表現為隨機噪聲、對抗攻擊或其他形式的數據擾動,影響數據集中的狀態、動作、獎勵和轉移動態等關鍵元素。經典離線強化學習算法往往假設數據集是乾淨、完好無損的,因此在面對數據損壞時,機器學習到的策略通常趨向於損壞數據中的策略,進而導致機器在乾淨環境下的部署時性能顯著下降。
儘管研究者在魯棒離線強化學習領域已經取得了一些進展,如一些方法嘗試通過增強測試期間的魯棒性來緩解噪聲或對抗攻擊的影響,但它們大多在乾淨數據集上訓練智能體模型,以防禦測試環境中可能出現的噪聲和攻擊,缺乏對訓練用離線數據集存在損壞的應對方案。而針對離線數據損壞的魯棒強化學習方法則只關注某一特定類別的數據存在損壞,如狀態數據、或轉移動態數據存在部分損壞,他們無法有效應對數據集中多個元素同時受損的複雜情況。
為了針對性地解決這些現有算法的局限性,我們提出了一種魯棒的變分貝葉斯推斷方法(TRACER),有效地增強了離線強化學習算法在面臨各類數據損壞時的魯棒性。TRACER 的優勢如下所示:
1. 據我們所知,TRACER 首次將貝葉斯推斷引入到抗損壞的離線強化學習中。通過將所有離線數據作為觀測值,TRACER 捕捉了由各類損壞數據所導致的動作價值函數中的不確定性。
2. 通過引入基於熵的不確定性度量,TRACER 能夠區分損壞數據和乾淨數據,從而調控並減弱損壞數據對智能體模型訓練的影響,以增強魯棒性。
3. 我們在機器人控制(MuJoCo)和自動駕駛(CARLA)仿真環境中進行了系統性地測試,驗證了 TRACER 在各類離線數據損壞、單類離線數據損壞的場景中均顯著提升了智能體的魯棒性,超出了多個現有的 SOTA 方法。
1. 方法介紹
1.1 動機
考慮到(1)多種類型的損毀會向數據集的所有元素引入較高的不確定性,(2)每個元素與累積獎勵(即動作值、Q 值)之間存在明確的相關性關係(見圖 1 中的虛線),因此使用多種受損數據估計累積獎勵函數(即動作值函數)會引入很高的不確定性。
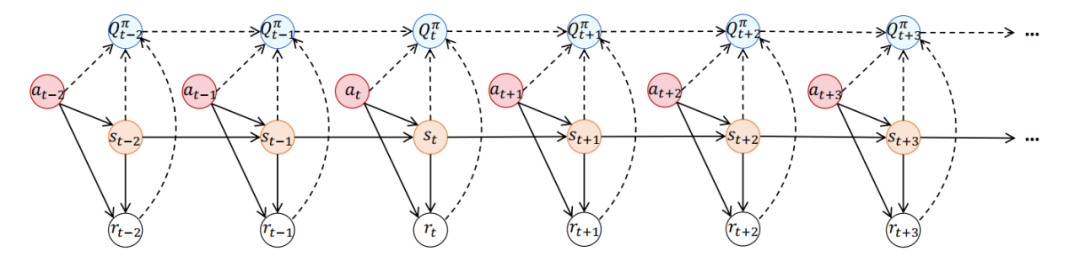
圖 1. 決策過程的概率圖模型。實線連接的節點表示數據集中的數據,而虛線連接的 Q 值(即動作值、累積回報)不屬於數據集。
為了處理這類由多種數據損毀(即狀態、動作、獎勵、狀態轉移數據受損)導致的高不確定性問題,基於圖 2 所示的概率圖模型,我們提出利用數據集中的所有元素作為觀測數據。我們旨在利用這些觀測數據與累積獎勵之間的高度相關性,來準確地識別動作值函數的不確定性。
1.2 基於受損數據的貝葉斯推斷
我們提出使用離線數據集的所有元素作為觀測值,利用數據之間的相關性同時解決不確定性問題。具體地,基於離線數據集中動作價值與四個元素(即狀態、動作、獎勵、下一狀態)之間的關係,我們分別使用各個元素作為觀測數據,通過引入變分貝葉斯推理框架,我們最大化動作值函數的後驗分佈,從而推導出各個元素對應的基於最大化證據下界 (ELBO) 的損失函數。基於對動作價值函數的後驗分佈的擬合,我們能有效地將數據損壞建模為動作值函數中的不確定性。
1.3 基於熵的不確定性度量
為了進一步應對各類數據損壞帶來的挑戰,我們思考如何利用不確定性進一步增強魯棒性。鑒於我們的目標是提高在乾淨環境中的智能體性能,我們提出減少損壞數據的影響,重點是使用乾淨數據來訓練智能體。因此,我們提供了一個兩步計劃:(1)區分損壞數據和乾淨數據;(2)調控與損壞數據相關的損失,減少其影響,從而提升在乾淨環境中的表現。
對於(1),由於損壞數據通常會造成比乾淨數據更高的不確定性和動作價值分佈熵,因此我們提出通過估計動作值分佈的熵,來量化損壞數據和乾淨數據引入的不確定性。
對於 (2),我們使用分佈熵指數的倒數來加權我們提出的 ELBO 損失函數。因此,在學習過程中,TRACER 能夠通過調控與損壞數據相關的損失來減弱其影響,並同時專注於最小化與乾淨數據相關的損失,以增強在乾淨環境中的魯棒性和性能。
1.4 算法架構
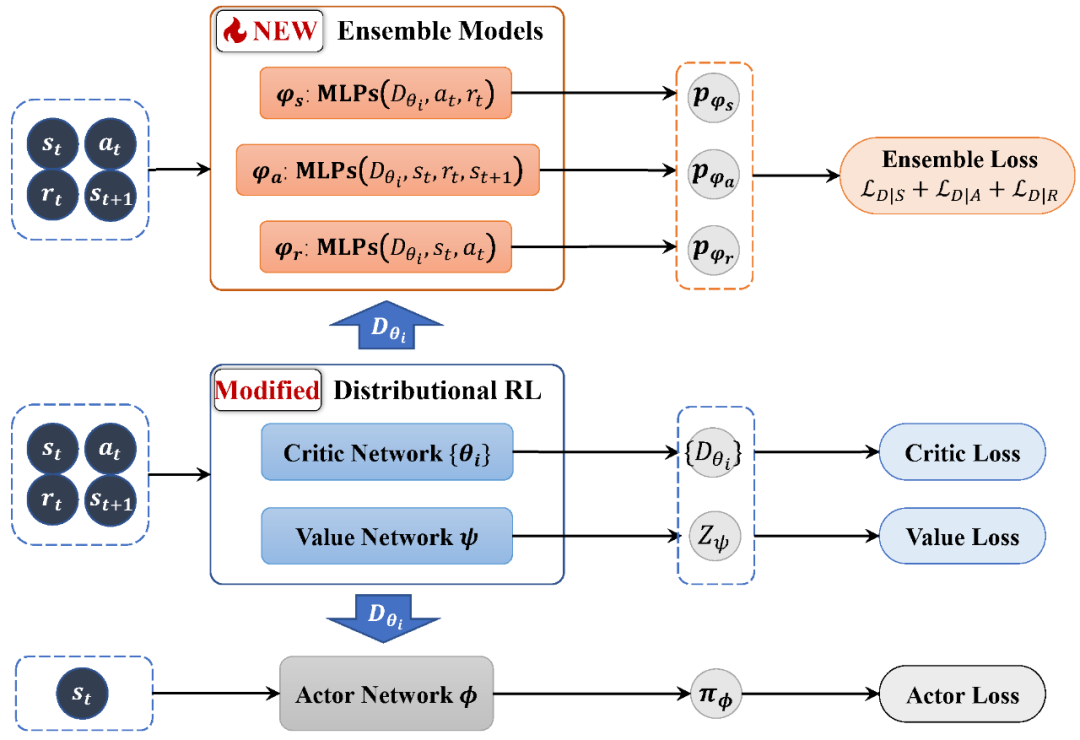 圖 2. TRACER 算法框架圖。
圖 2. TRACER 算法框架圖。2. 實驗介紹
為了模擬數據受損的情形,我們對數據集的部分數據加入隨機噪聲或對抗攻擊來構建損壞數據。在我們的實驗中,我們對 30% 的單類數據進行損壞。因此,在所有類型的數據都有損壞時,整個離線數據集中,損壞數據佔約
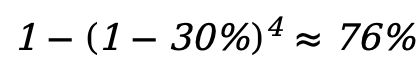
的規模。
各類數據均受損
所有類型數據元素均存在損壞的部分實驗結果見表 1,TRACER 在所有控制環境中均獲得了較為明顯的性能提升,提升幅度達 + 21.1%,這一結果展現了 TRACER 對大規模、各類數據損壞的強魯棒性。

表 1. 離線數據集的所有類型元素均存在隨機損壞(random)或對抗損壞(advers)時,我們的方法 TRACER 在所有環境中都獲得了最高的平均得分。
單類數據受損
單種類型數據元素存在損壞的部分實驗結果見表 2 和表 3。在單類數據損壞中,TRACER 於 24 個實驗設置裡實現 16 組最優性能,可見 TRACER 面向小規模、單類數據損壞的問題也能有效地增強魯棒性。
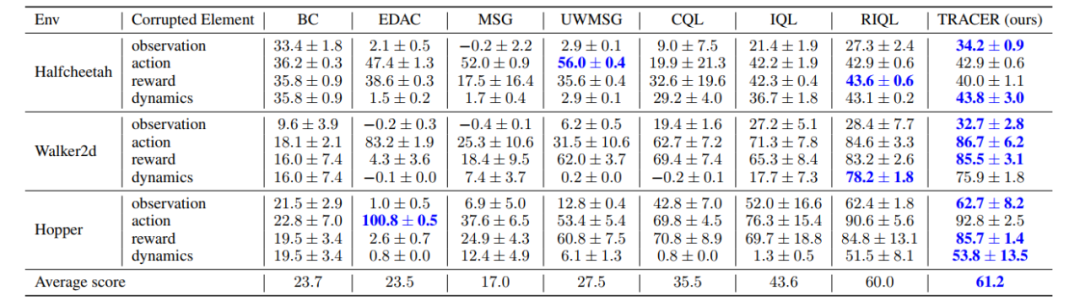
表 2. 單類元素存在隨機損壞時,我們的方法 TRACER 在 8 個實驗設置中獲得了最高的平均得分。
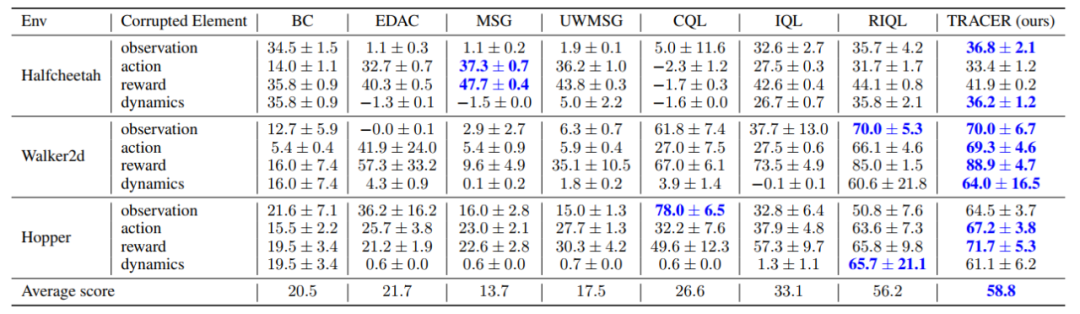
表 3. 單類元素存在對抗損壞時,我們的方法 TRACER 在 8 個實驗設置中獲得了最高的平均得分。