NeurIPS 2024 | 無需訓練,一個框架搞掂開放式目標檢測、實例分割
AIxiv專欄是機器之心發佈學術、技術內容的欄目。過去數年,機器之心AIxiv專欄接收報導了2000多篇內容,覆蓋全球各大高校與企業的頂級實驗室,有效促進了學術交流與傳播。如果您有優秀的工作想要分享,歡迎投稿或者聯繫報導。投稿郵箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
本文作者均來自北京大學王選計算機研究所。主要作者包括:林誌威,北京大學博士生;王勇濤,北京大學副研究員;湯幟,北京大學研究員。
本文介紹了來自北京大學王選計算機研究所的王勇濤團隊的最新研究成果 VL-SAM。針對開放場景,該篇工作提出了一個基於注意力圖提示的免訓練開放式目標檢測和分割框架 VL-SAM,在無需訓練的情況下,取得了良好的開放式 (Open-ended) 目標檢測和實例分割結果,論文已被 NeurIPS 2024 錄用。

-
論文標題:Training-Free Open-Ended Object Detection and Segmentation via Attention as Prompts
-
論文鏈接:https://arxiv.org/abs/2410.05963
論文概述
本文提出了一個無需訓練的開放式目標檢測和分割框架,結合了現有的泛化物體識別模型(如視覺語言大模型 VLM)與泛化物體定位模型(如分割基礎模型 SAM),並使用注意力圖作為提示進行兩者的連接。在長尾數據集 LVIS 上,該框架超過了之前需要訓練的開放式方法,同時能夠提供額外的實例分割結果。在自動駕駛 corner case 數據集 CODA 上,VL-SAM 也表現出了不錯的結果,證明了其在真實應用場景下的能力。此外,VL-SAM 展現了強大的模型泛化能力,能夠結合當前各種 VLM 和 SAM 模型。
研究背景
深度學習在感知任務方面取得了顯著成功,其中,自動駕駛是一個典型的成功案例。現有的基於深度學習的感知模型依賴於廣泛的標記訓練數據來學習識別和定位對象。然而,訓練數據不能完全覆蓋真實世界場景中所有類型的物體。當面對分佈外的物體時,現有的感知模型可能無法進行識別和定位,從而可能會發生嚴重的安全問題。
為瞭解決這個問題,研究者們提出了許多開放世界感知方法。這些方法大致可以分為兩類:開集感知(open-set)和開放式感知(open-ended)。開集感知方法通常使用預訓練的 CLIP 模型來計算圖像區域和類別名稱之間的相似性。因此,在推理過程中,這類方法需要預定義的對象類別名稱作為 CLIP 文本編碼器的輸入。然而,在許多現實世界的應用場景中,並不會提供確切的對象類別名稱。例如,在自動駕駛場景中,自動駕駛車輛可能會遇到各種意想不到的物體,包括起火或側翻的事故車和各種各樣的建築車輛。相比之下,開放式感知方法更具通用性和實用性,因為這些可以同時預測對象類別和位置,而不需要給定確切的對象類別名稱。
與此同時,在最近的研究中,大型視覺語言模型(VLM)顯示出強大的物體識別泛化能力,例如,它可以在自動駕駛場景中的長尾數據上(corner case)識別非常見的物體,並給出準確的描述。然而,VLM 的定位能力相比於特定感知模型較弱,經常會漏檢物體或給出錯誤的定位結果。另一方面,作為一個純視覺基礎模型,SAM 對來自許多不同領域的圖像表現出良好的分割泛化能力。然而,SAM 無法為分割的對象提供類別。基於此,本文提出了一個無需訓練的開放式目標檢測和分割框架 VL-SAM,將現有的泛化物體識別模型 VLM 與泛化物體定位模型 SAM 相結合,利用注意力圖作為中間提示進行連接,以解決開放式感知任務。
方法部分
作者提出了 VL-SAM,一個無需訓練的開放式目標檢測和分割框架。具體框架如下圖所示:

圖 1 VL-SAM 框架圖
具體而言,作者設計了注意力圖生成模塊,採用頭聚合和注意力流的方式對多層多頭注意力圖進行傳播,從而生成高質量的注意力圖。之後,作者使用迭代式正負樣本點采樣的方式,從生成的注意力圖中進行采樣,得到 SAM 的點提示作為輸入,最終得到物體的分割結果。
1、注意力圖生成模塊(Attention Map Generation Module)
給定一張輸入圖片,使用 VLM 給出圖片中所有的物體類別。在這個過程中存儲 VLM 生成的所有 query 和 key,並使用 query 和 key 構建多層多頭注意力圖:
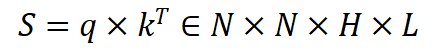
其中 N 表示 token 的數量,H 表示多頭注意力的數量,L 表示 VLM 的層數。
之後,採用 Mean-max 的方式對多頭注意力圖進行聚合,如圖 2 所示:

圖 2 多頭注意力聚合
首先計算每個頭的注意力的權重:

之後採用基於權重的多頭注意力加權進行信息聚合:

其中表示矩陣點乘。
在聚合多頭注意力圖之後,採用注意力流的方式進一步聚合多層注意力圖,如圖 3 所示

圖 3 注意力流
具體而言,採用 attention rollout 的方式,計算第
層的注意力圖傳播:
層到第

其中
表示單位矩陣。最後,作者僅使用傳播後的最後一層注意力圖作為最終的注意力圖。
2、SAM 提示生成
生成的注意力圖中可能會存在不穩定的假陽性峰值。為了過濾這部分假陽性,作者首先採用閾值過濾的方式進行初步過濾,並找到賸餘激活部分的最大聯通區域作為正樣本區域,其餘的部分作為負樣本區域。之後,採用峰值檢測的方式分別從正負樣本區域進行采樣,得到正負樣本點,作為 SAM 的點提示輸入。
3、迭代式分割優化
從 SAM 得到分割結果可能會存在粗糙的邊界或者背景噪聲,作者採用兩種迭代式方式進一步對分割結果進行優化。在第一種迭代方式中,作者借鑒 PerSAM 使用 cascaded post-refinement 的方式,將初始的分割結果作為額外的提示輸入到 SAM 中。對於第二種迭代方式,作者使用初始的分割結果對注意力圖進行掩碼,之後在掩碼的區域進行正負樣本點采樣。
4、多尺度聚合和問題提示聚合
作者還採用兩種聚合(Ensemble)的方式進一步改良結果。對於 VLM 的低分率問題,作者使用多尺度聚合,將圖片切成 4 塊進行輸入。此外,由於 VLM 對問題輸入較為敏感,作者採用問題提示聚合,使得 VLM 能夠儘量多得輸出物體類別。最後,採用 NMS 對這些聚合結果進行過濾。
實驗結果
在包含 1203 類物體類別的長尾數據集 LVIS 驗證集上,相比於之前的開放式方法,VL-SAM 取得了更高的包圍框 AP 值。同時,VL-SAM 還能夠獲取物體分割結果。此外,相比於開集檢測方法,VL-SAM 也取得了具有競爭力的性能。

表 1 LVIS 結果
在自動駕駛場景 corner case 數據集 CODA 上,VL-SAM 也取得了不錯的結果,超過了開集檢測和開放式檢測的方法。

表 2 CODA 結果
結論
本文提出了 VL-SAM,一個基於注意力圖提示的免訓練開放式目標檢測和分割框架 VL-SAM,在無需訓練的情況下,取得了良好的開放式 (Open-ended) 目標檢測和實例分割結果。



















