LeCun 的世界模型初步實現!基於預訓練視覺特徵,看一眼任務就能零樣本規劃
機器之心報導
編輯:Panda
在 LLM 應用不斷迭代升級更新的當下,圖靈獎得主 Yann LeCun 卻代表了一股不同的聲音。他在許多不同場合都反復重申了自己的一個觀點:當前的 LLM 根本無法理解世界。他曾說過:LLM「理解邏輯的能力非常有限…… 無法理解物理世界,沒有持續性記憶,不能推理(只要推理的定義是合理的)、不能規劃。」

Yann LeCun 批評 LLM 的推文之一
相反,他更注重所謂的世界模型(World Model),也就是根據世界數據擬合的一個動態模型。比如驢,正是有了這樣的世界模型,它們才能找到更省力的負重登山方法。
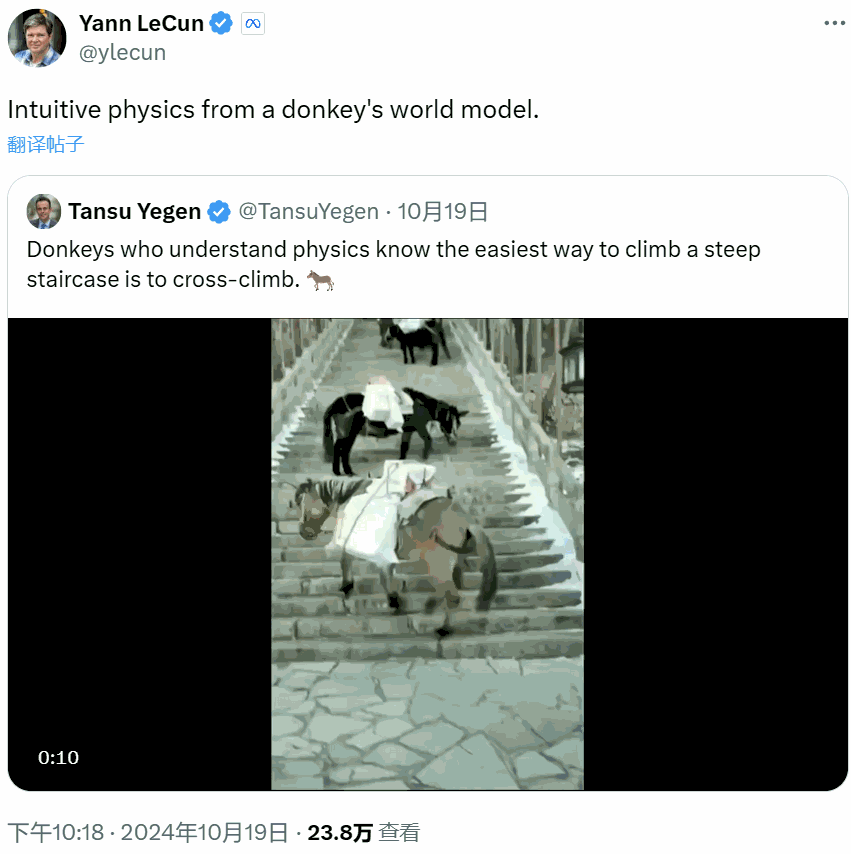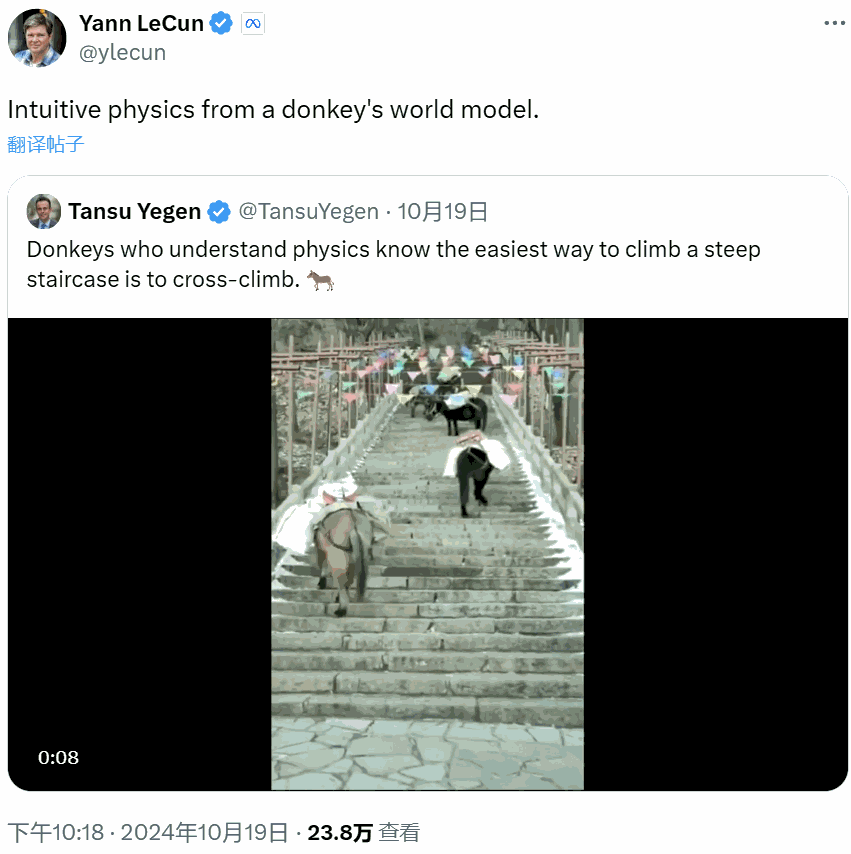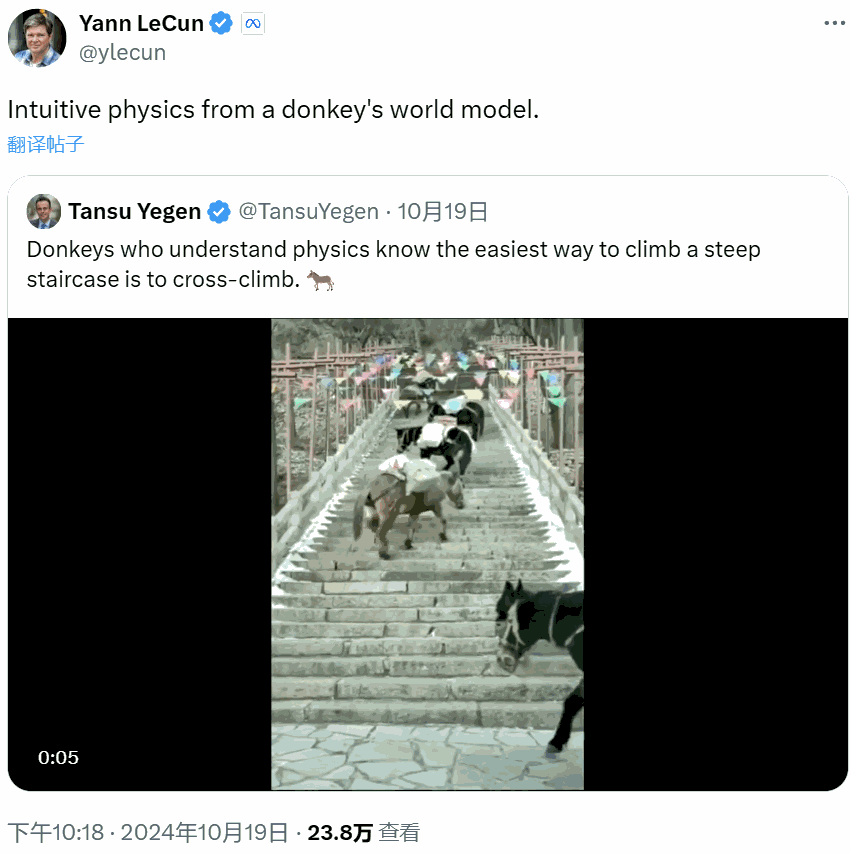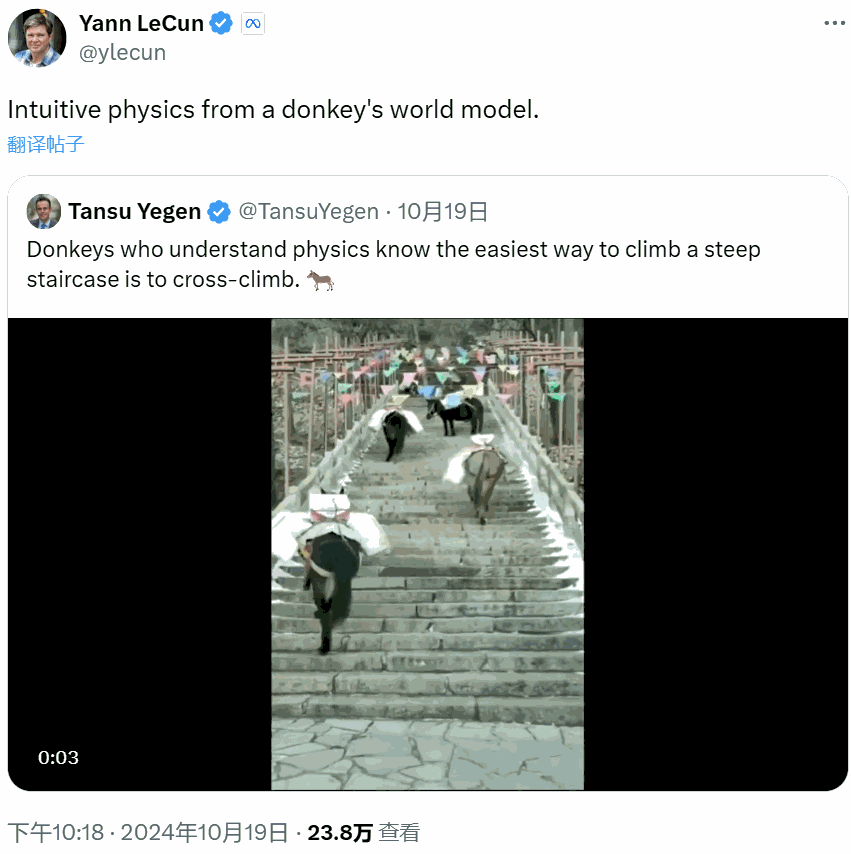
近日,LeCun 團隊發佈了他們在世界模型方面的一項新研究成果:基於預訓練的視覺特徵訓練的世界模型可以實現零樣本規劃!也就是說該模型無需依賴任何專家演示、獎勵建模或預先學習的逆向模型。

-
論文標題:DINO-WM: World Models on Pre-trained Visual Features enable Zero-shot Planning
-
論文地址:https://arxiv.org/pdf/2411.04983v1
-
項目地址:https://dino-wm.github.io/
該團隊提出的 DINO-WM 是一種可基於離線的軌跡數據集構建與任務無關的世界模型的簡單新方法。據介紹,DINO-WM 是基於世界的緊湊嵌入建模世界的動態,而不是使用原始的觀察本身。
對於嵌入,他們使用的是來自 DINOv2 模型的預訓練圖塊特徵,其能提供空間的和以目標為中心的表徵先驗。該團隊推測,這種預訓練的表徵可實現穩健且一致的世界建模,從而可放寬對具體任務數據的需求。
有了這些視覺嵌入和動作後,DINO-WM 會使用 ViT 架構來預測未來嵌入。
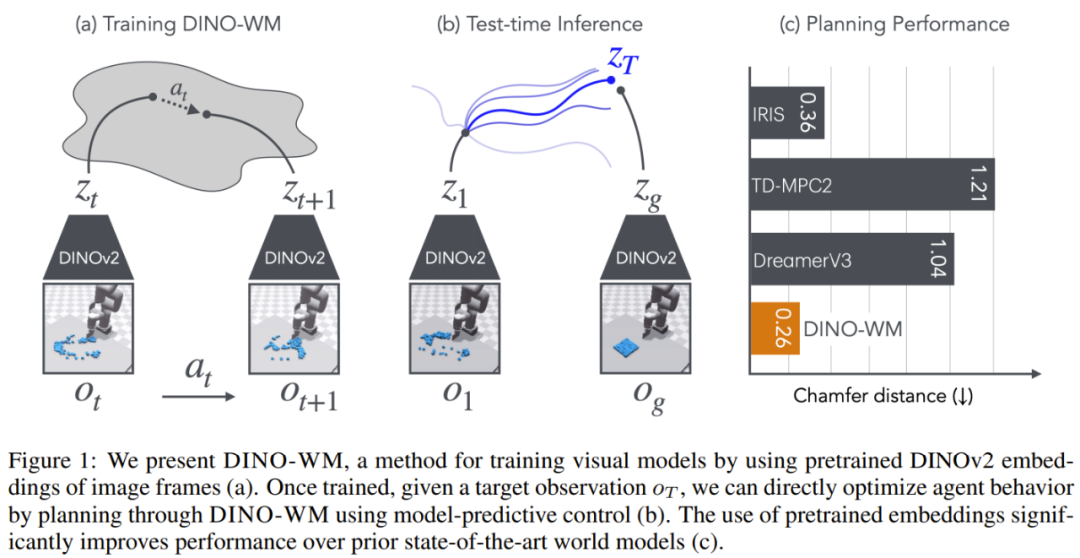
完成模型訓練之後,在解決任務時,規劃會被構建成視覺目標的達成,即給定當前觀察達成未來的預期目標。由於 DINO-WM 的預測質量很高,於是就可以簡單地使用模型預測控制和推理時間優化來達成期望的目標,而無需在測試期間使用任何額外信息。
DINO 世界模型
概述和問題表述:該研究遵循基於視覺的控制任務框架,即將環境建模為部分可觀察的馬爾可夫決策過程 (POMDP)。POMDP 可定義成一個元組 (O, A, p),其中 O 表示觀察空間,A 表示動作空間。p (o_{t+1} | o≤t, a≤t) 是一個轉移分佈,建模了環境的動態,可根據過去的動作和觀察預測未來的觀察。
這項研究的目標是從預先收集的離線數據集中學習與任務無關的世界模型,然後在測試時間使用這些世界模型來執行視覺推理。
在測試時間,該系統可從一個任意的環境狀態開始,然後根據提供的目標觀察(RGB 圖像形式),執行一系列動作 a_0, …, a_T,使得目標狀態得以實現。
該方法不同於在線強化學習中使用的世界模型,其目標是優化手頭一組固定任務的獎勵;也不同於基於文本的世界模型,其目標需要通過文本提示詞指定。
基於 DINO 的世界模型(DINO-WM)
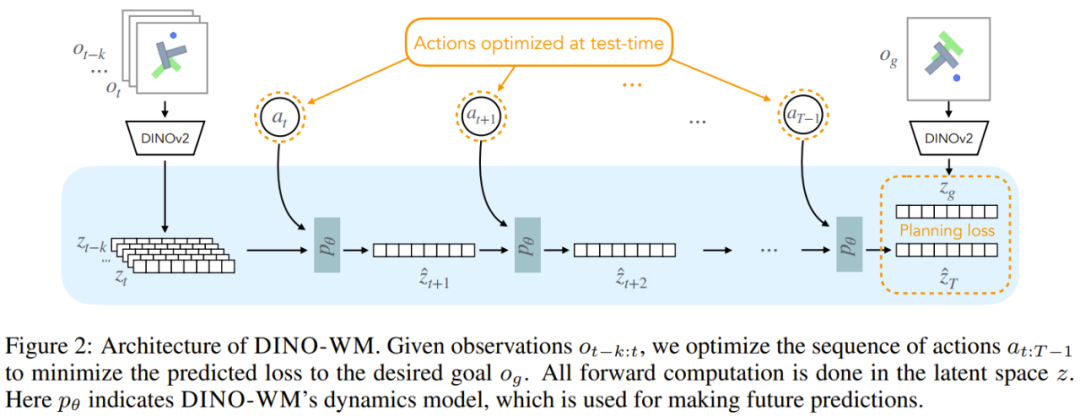
該團隊將環境動態建模到了隱藏空間中。更具體而言,在每個時間步驟 t,該世界模型由以下組分構成:

其中,觀察模型是將圖像觀察編碼成隱藏狀態 z_t,而轉移模型則是以長度為 H 的過去隱藏狀態歷史為輸入。解碼器模型則是以隱藏的 z_t 為輸入,重建出圖像觀察 o_t。這裏的 θ 表示這些模型的參數。
該團隊指出,其中的解碼器是可選的,因為解碼器的訓練目標與訓練世界模型的其餘部分無關。這樣一來,就不必在訓練和測試期間重建圖像了;相比於將觀察模型和解碼器的訓練結合在一起的做法,這還能降低計算成本。
DINO-WM 僅會建模環境中離線軌跡數據中可用的信息,這不同於近期的在線強化學習世界模型方法(還需要獎勵和終止條件等與任務相關的信息)。
使用 DINO-WM 實現視覺規劃
為了評估世界模型的質量,需要瞭解其在下遊任務上的推理和規劃能力。一種標準的評估指標是在測試時間使用世界模型執行軌跡優化並測量其性能。雖然規劃方法本身相當標準,但它可以作為一種展現世界模型質量的手段。
為此,該團隊使用 DINO-WM 執行了這樣的操作:以當前觀察 o_0 和目標觀察 o_g(都是 RGB 圖像)為輸入,規劃便是搜索能使智能體到達 o_g 的一個動作序列。為了實現這一點,該團隊使用了模型預測性控制(MPC),即通過考慮未來動作的結果來促進規劃。
為了優化每次迭代的動作序列,該團隊還使用了一種隨機優化算法:交叉熵方法(CEM)。其規劃成本定義為當前隱藏狀態與目標隱藏狀態之間的均方誤差(MSE),如下所示:
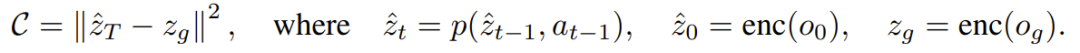
實驗
該團隊基於以下四個關鍵問題進行了實驗:
-
能否使用預先收集的離線數據集有效地訓練 DINO-WM?
-
訓練完成後,DINO-WM 可以用於視覺規劃嗎?
-
世界模型的質量在多大程度上取決於預訓練的視覺表徵?
-
DINO-WM 是否可以泛化到新的配置,例如不同的空間佈局和物體排列方式?
為瞭解答這些問題,該團隊在 5 個環境套件(Point Maze、Push-T、Wall、Rope Manipulation、Granular Manipulation)中訓練和評估了 DINO-WM,並將其與多種在隱藏空間和原始像素空間中建模世界的世界模型進行了比較。
使用 DINO-WM 優化行為
該團隊研究了 DINO-WM 是否可直接用於在隱藏空間中實現零樣本規劃。
如表 1 所示,在 Wall 和 PointMaze 等較簡單的環境中,DINO-WM 與 DreamerV3 等最先進的世界模型相當。但是,在需要準確推斷豐富的接觸信息和物體動態才能完成任務的操縱環境中,DINO-WM 的表現明顯優於之前的方法。
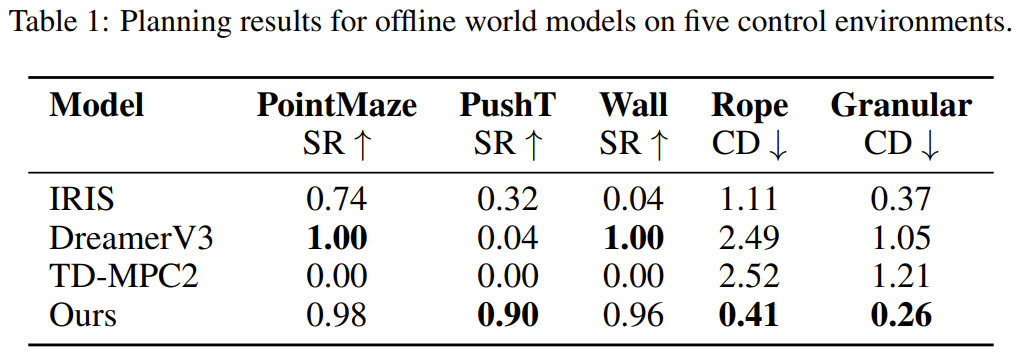
下面展示了一些可視化的規劃結果:

預訓練的視覺表徵重要嗎?
該團隊使用不同的預訓練通用編碼器作為世界模型的觀察模型,並評估了它們的下遊規劃性能。
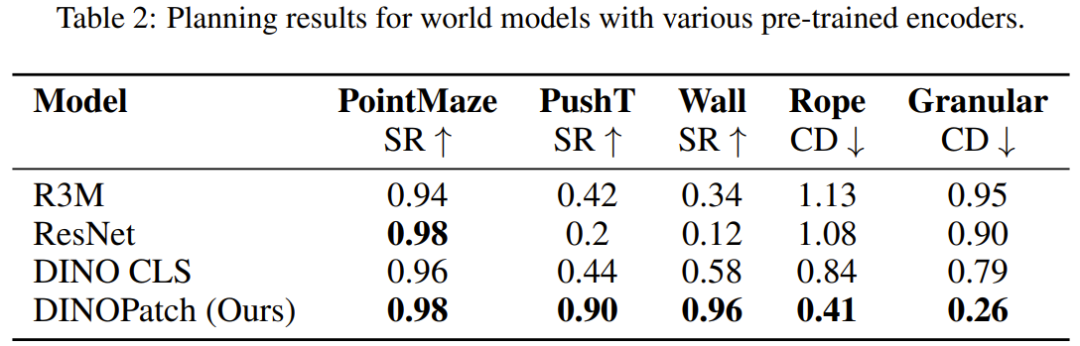
在涉及簡單動態和控制的 PointMaze 任務中,該團隊觀察到具有不同觀察編碼器的世界模型都實現了近乎完美的成功率。然而,隨著環境複雜性的增加(需要更精確的控制和空間理解),將觀察結果編碼為單個隱藏向量的世界模型的性能會顯著下降。他們猜想基於圖塊的表徵可以更好地捕獲空間信息,而 R3M、ResNet 和 DINO CLS 等模型是將觀察結果簡化為單個全局特徵向量,這樣會丟失操作任務所需的關鍵空間細節。
泛化到全新的環境配置
該團隊也評估了新提出的模型對不同環境的泛化能力。為此,他們構建了三類環境:WallRandom、PushObj 和 GranularRandom。實驗中,世界模型會被部署在從未見過的環境中去實現從未見過的任務。圖 6 展示了一些示例。
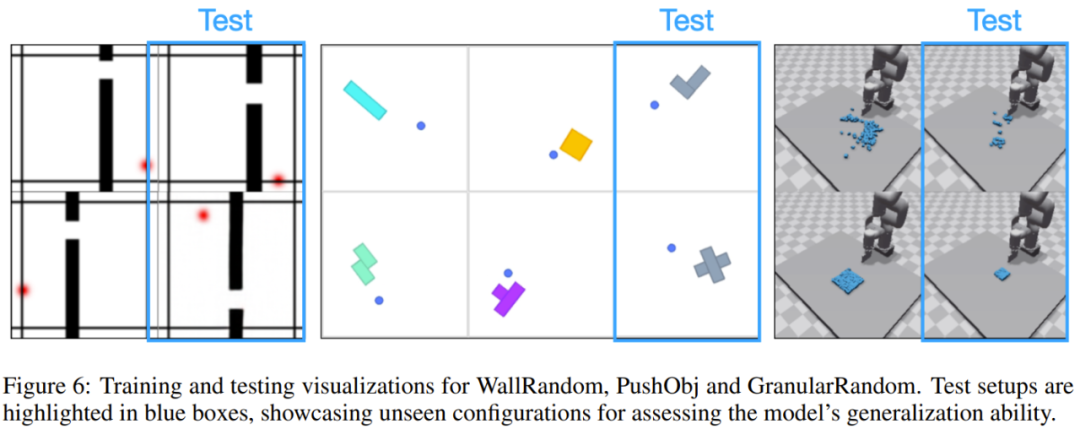
結果見表 3。可以看到,DINO-WM 在 WallRandom 環境中的表現明顯更好,這表明世界模型已經有效地學習了牆壁和門的一般概念,即使它們位於訓練期間未曾見過的位置。相比之下,其他方法很難做到這一點。
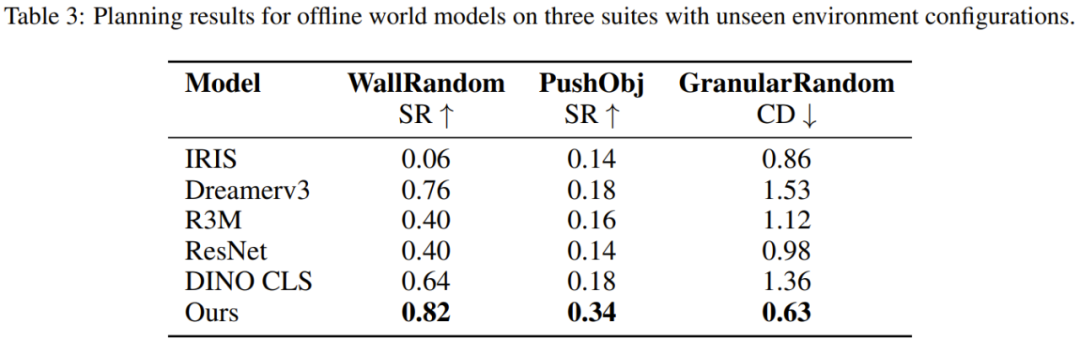
PushObj 任務對於所有方法來說都挺難,因為該模型僅針對四種物體形狀進行了訓練,這使其很難精確推斷重心和慣性等物理參數。
在 GranularRandom 中,智能體遇到的粒子不到訓練時出現的一半,導致圖像出現在了訓練實例的分佈之外。儘管如此,DINO-WM 依然準確地編碼了場景,併成功地將粒子聚集到與基線相比具有最小 Chamfer Distance(CD)的指定方形位置。這說明 DINO-WM 具有更好的場景理解能力。該團隊猜想這是由於 DINO-WM 的觀察模型會將場景編碼為圖塊特徵,使得粒子數量的方差仍然在每個圖塊的分佈範圍內。
與生成式影片模型的定性比較
鑒於生成式影片模型的突出地位,可以合理地假設它們可以很容易地用作世界模型。為了研究 DINO-WM 相對於此類影片生成模型的實用性,該團隊將其與 AVDC(一個基於擴散的生成式模型)進行了比較。
如圖 7 所示,可以看到,在基準上訓練的擴散模型能得到看起來相當真實的未來圖像,但它們在物理上並不合理,因為可以看到在單個預測時間步驟中就可能出現較大的變化,並且可能難以達到準確的目標狀態。

DINO-WM 所代表的方法看起來頗有潛力,該團隊表示:「DINO-WM 朝著填補任務無關型世界建模以及推理和控制之間的空白邁出了一步,為現實世界應用中的通用世界模型提供了光明的前景。」
參考鏈接:
https://www.ft.com/content/23fab126-f1d3-4add-a457-207a25730ad9



















