Nature:「人類親吻難題」徹底難倒LLM,所有大模型全部失敗!
LLM究竟是否擁有類似人類的符合理解和推理能力呢?
許多認知科學家和機器學習研究人員,都會認為,LLM表現出類人(或「接近類人」)的語言能力。
然而,來自帕維亞大學、柏林洪堡大學、得克薩斯大學曉士頓健康科學中心、紐約大學、巴塞隆拿自治大學的研究者卻提供了一些最全面的證據,表明目前它們基本沒有!
 論文地址:https://www.nature.com/articles/s41598-024-79531-8
論文地址:https://www.nature.com/articles/s41598-024-79531-8基於一個全新的基準數據集,研究者對目前最先進的7個模型(包括GPT-4、Llama2、Gemini和 Bard)進行了評估。
他們讓模型回答了理解性問題,在兩種設置下多次被提示,允許模型只回答一個單詞,或給出開放長度的回覆。

約翰欺騙了瑪麗,露西也被瑪麗欺騙了。在這種情況下,瑪麗是否欺騙了露西?
史提芬擁抱了莫莉,莫莉親吻了唐娜。在這種情況下,莫莉被吻了嗎?
傑西卡和瑪麗被愛麗絲親吻了。傑西卡被塞繆爾親吻,安德魯被瑪麗親吻。在這種情況下,瑪麗被吻了嗎?
波比親吻了唐娜,芭芭拉親吻了彼得。唐娜被愛麗絲擁抱。在這種情況下,愛麗絲被擁抱了嗎?
為了建立實現類人表現的基準,他們在相同的提示下,對400名人類進行了測試。
基於n=26,680個數據點的數據集,他們發現,LLM準確性有偶然性,但答案卻有很大波動。
他們還探討了理解性問題答案的「穩定性」。結果表明, LLM缺乏強有力、一致的回應。

之後,他們測試了ChatGPT-3.5的一系列低頻結構、探索語法,包括身份迴避(「漁民捕獲的魚吃蟲子」)、比較結構(「去過俄羅斯的人比我去過的次數多」)和語義異常(「……我們應該把倖存者埋在哪裡?」這類謎題)。
ChatGPT的表現非常差勁。

研究者將這一證據解讀為一種證明:儘管當前的AI模型具有一定的實用性,但仍未達到類人語言的水平。
原因可能在於,它們缺乏用於有效調控語法和語義的組合運算符信息。

最後,研究者強調說:在語言相關任務和基準測試中的出色表現,絕不應該被用來推斷:LLM不僅成功完成了特定任務,還掌握了完成該任務所需的一般知識。
這次研究表明,從數量上講,測試模型的表現優於人類,但從質量上講,它們的答案顯示出了明顯的非人類在語言理解方面的錯誤。
因此,儘管LLM在很多很多任務中都很有用,但它們並不能以與人類相匹配的方式理解語言。
 人類利用類似MERGE的組合運算符,來調節語法和語義信息
人類利用類似MERGE的組合運算符,來調節語法和語義信息AI對語言的深層含義不敏感
LLM為什麼這麼容易受到莫拉維克悖論的束縛——在相對簡單的任務上卻會失敗?
這是因為,在需要記憶專業知識的任務中的良好表現,並不一定建立在對語言的紮實理解的基礎上。

對人類大腦最擅長的簡單、輕鬆的任務來說,逆向工程卻更加困難;而對於人類來說,理解語言卻是一件輕而易舉的事情,甚至連18個月的幼兒都能表現出對複雜語法關係的理解。

我們這個物種天生就具有不可抑制的語言習得傾向,總是會在文字表面之下尋找意義,並在線性序列中構建出令人驚訝的層次結構和關係。

不過,LLM也有這種能力嗎?
很多人會把LLM在各種任務和基準測試中的成功,歸結為它們已經具有了類人能力,比如高級推理、跨模態理解和常識能力。
甚至一些學者聲稱,LLM在一定程度上接近人類認知,能夠理解語言,性能與人類相當甚至超越人類。
然而,大量證據表明,這些模型的表現可能存在不一致性!

儘管模型能夠生成高度流暢、語義連貫的輸出,但在自然語言的一些基本句法或語義屬性方面仍會出現困難 。
那麼,LLM在回答醫療或法律問題時,為何看似表現良好呢?
實際上,這些任務的完成,可能依賴於一系列完全不同於人類語言認知架構的計算步驟。

LLM在性能上的缺陷,已經引發了我們對其輸出生成機制的嚴肅質疑——
究竟是(i)基於上下文的文本解析(即,能夠將特定的語言形式與其相應的意義匹配,並在不同上下文中實現廣泛的泛化),還是(ii)機械化地利用訓練數據中的特定特徵 ,從而僅僅製造出一種能力的假象?
目前,評估LLM的主流方法是通過其(結構良好的)輸出,推斷它們具備類似人類的語言能力(如演繹推理 )。

例如,在語言相關的任務和基準測試中取得的準確表現 ,通常被用來得出這樣的結論:LLM不僅成功完成了所執行的特定任務,還掌握了完成該任務所需的一般性知識
這種推理方式的核心邏輯,就是把LLM視為認知理論基礎。
另一方面,假如LLM真的完全掌握了語言理解中涉及的所有形態句法、語義和語用過程,它們卻為何無法穩定運用歸因於它們的知識呢?
詭異考題,給LLM上難度
為此,研究者特意設計了一份別緻的考題,來考驗LLM對語言真正的掌握程度!
他們考驗了GPT-3和ChatGPT-3.5對一些語法性判斷的表現,也就是判斷一個提示是否符合或偏離模型所內化的語言模式。
注意,這些提示在日常語言中出現頻率較低,因此很可能在訓練數據中並不常見。

這個考驗的巧妙之處在哪裡?
要知道,對人類來說,認知因素(如工作記憶限制或注意力分散)可能會影響語言處理,從而導致非目標的語法性判斷,但人類可以通過反思正確處理這些刺激,即在初步的「淺層」解析後能夠進行「深層」處理。
然而,對於LLM來說,它們的系統性語言錯誤並沒有類似的「直給」解釋。
可以看到,這些句子十分詭異。
比如「狗狗狗狗狗」,「診所僱傭的護士的醫生見到了積克」,「根本存在缺陷的理念之村未能達到標準」,「當一架飛機在兩國邊界墜毀,殘骸散落在兩國境內時,我們應該在哪裡埋葬倖存者?」等等。

GPT-3(text-davinci-002)和ChatGPT-3.5在涉及低頻結構的語法判斷任務上的表現,不準確的回覆被標記為紅色,準確的被標記為綠色
接下來,研究者著重調查了LLM理解語言的能力是否與人類相當。
他們調查了7個最先進的LLM在理解任務中的能力,任務有意將語言複雜性保持在最低限度。
約翰欺騙了瑪麗,露西也被瑪麗欺騙了。在這種情況下,瑪麗是否欺騙了露西?
這項研究,在現實層面也意義重大。
雖然LLM被訓練來預測token,但當它們與界面設置結合起來,它們的能力已經被宣傳為遠遠超過下一個token的預測:商家會強調說,它們是能流利對話的Agent,並且表現出了跨模態的長上下文理解。
最近就有一家航空公司被告了,原因是乘客認為他們的聊天機器人提供了不準確信息。

公司承認,它的回覆中的確包含誤導性詞彙,但聊天機器人是一個獨立的法律實體,具有合理的語言能力,因此對自己的言論負責。
因此,研究人員想弄明白,LLM在語言理解任務中的表現是否與人類相當。
具體來說,有兩個研究問題——
RQ1 :LLM能否準確回答理解問題?
RQ2 :當同一問題被問多次時, LLM的回答是否一致?
按模型和設置(開放長度與單字)劃分的準確率如圖A所示。
結果表明,大多數LLM在開放長度設置中,均表現較差。
按模型和設置劃分的穩定性率如圖B所示。
與準確性結果結合起來看,Falcon和Gemini的穩定性顯著提高,這分別意味著 Falcon在提供準確答覆方面部分一致,而Gemini在提供不準確答覆方面部分一致。
 ( A )按模型和設置劃分的平均準確度。( B )模型和設置的平均穩定性
( A )按模型和設置劃分的平均準確度。( B )模型和設置的平均穩定性那麼LLM和人類的區別在哪裡呢?
比較分析表明,人類與LLM在準確性和穩定性方面的表現存在重大差異。
 (A)各響應代理和場景的平均準確率。(B)各響應代理和場景的平均穩定性
(A)各響應代理和場景的平均準確率。(B)各響應代理和場景的平均穩定性準確性
1. 在開放長度設定中,LLM的表現顯著差於人類。
2. 在單詞長度設定中,人類的表現並未顯著優於開放長度設定。
3. 在單詞長度設定中,人類與LLM之間的表現差距顯著縮小,這表明LLM的響應在不同設定間存在差異,而這種差異在人類中並未觀察到。
這一結果揭示出,LLM 在不同響應條件下具有顯著差異,而人類的表現則相對一致。
穩定性
1. 在開放長度設定中,LLM 的表現顯著差於人類。
2. 在單詞長度設定中,人類的表現並未顯著優於開放長度設定。
3. 在單詞長度設定中,人類與 LLM 之間的表現差距顯著縮小,這表明 LLM 的響應在不同設定間存在差異,而這種差異在人類中並未觀察到。
這一結果揭示,LLM在不同響應條件下表現出了顯著差異,而人類的表現則相對一致。
另外,即使是表現最好的LLM——GPT-4,也要明顯比表現最好的人差。所有人類參與者,在描述性水平上綜合起來都優於GPT-4。
準確性和穩定性,LLM比起人類弱爆了
LLM的輸出究竟是由什麼驅動的?
究竟是(i)類似人類的能力來解析和理解書面文本,還是(ii)利用訓練數據中的特定特徵?
為此,研究者對7個最先進的LLM進行了測試,使用的理解問題針對包含高頻結構和詞彙的句子,同時將語言複雜性控制在最低水平。
他們特別關注了LLM生成的答案是否同時具備準確性(RQ1)和在重覆試驗中的穩定性(RQ2)。
系統性測試表明,LLM作為一個整體在準確性上的平均表現僅處於隨機水平,並且其答案相對不穩定。
相比之下,人類在相同理解問題上的測試表現出大多準確的答案(RQ1),且在重覆提問時幾乎不會改變(RQ2)。
更重要的是,即便在評分對LLM有利的情況下,LLM和人類之間的這些差異仍然十分顯著。

語言解析,是指通過為符號串賦予意義來理解和生成語言的能力,這是人類獨有的能力 。
這也就解釋了,為什麼實驗中,人類在多次提問或使用不同指令的情況下,能夠準確回答並且答案保持一致。
然而,LLM的輸出在數量和質量上都與人類的答案存在差異!
在數量上,LLM作為一個整體的平均準確率僅處於隨機水平,而那些成功超過隨機閾值的模型(如Falcon、Llama2和ChatGPT-4),其準確率仍然遠未達到完美水平。
其次,儘管所有LLM在穩定性方面表現高於隨機水平,但沒有一個能夠始終如一地對同一個問題給出相同的答案。
綜上所述,LLM整體上並不能以一種可被稱為「類人」的方式應對簡單的理解問題。
LLM更像工具,而不是科學理論
研究者認為,LLM之所以在簡單理解任務中無法提供準確且穩定答案,是因為這些模型缺乏對語言的真正理解:它們生成的詞語如同語義「黑箱」,只是近似於語言的表面統計和解析過程中較「自動化」的部分。
事實上,不僅是較低的準確率,而且LLM響應的較低穩定性也表明,它們缺乏一種類人的算法,能夠將句法信息直接映射到語義指令上,同時對不同判斷的容忍度也明顯較低。
而人類則擁有一個不變的組合操作器,用於調節語法和語義信息,因此在這方面明顯不易出錯。
此外,LLM並不適合作為語言理論,因為它們的表徵能力幾乎是無限的,這使得它們的表徵既是任意的,又缺乏解釋性基礎,屬於通用函數逼近器這一類別,而後者已被證明能夠逼近任何數學函數 。
 論文地址:https://arxiv.org/pdf/1912.10077
論文地址:https://arxiv.org/pdf/1912.10077
論文地址:https://arxiv.org/pdf/2012.03016
因此,與其說LLM是科學理論,不如說它們更接近工具,比如廣義導數。
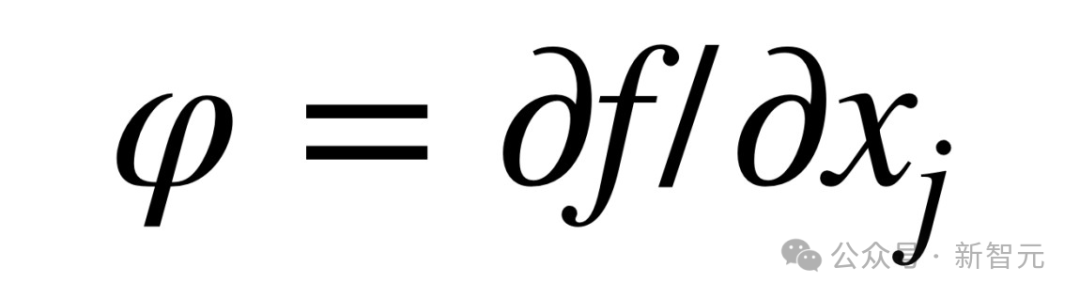
此外,LLM與人類表現之間的差異也具有質的特點。
首先,所有人類參與者無一例外地在所有設定中都提供了單詞長度的回答。這表明被試在回答問題時,對所需信息量的理解具有一致性,即使在語用學領域,人類也遵循了由句法推理路徑決定的計算效率和相關性原則 。

這與LLM形成了鮮明對比,後者通常會提供冗長的解釋,即便在單詞長度設定中也如此,從而違背了任務指令。
在這些解釋中,LLM的推理被分解為邏輯步驟,但這些步驟中常常包含無關或自相矛盾的信息。例如,在以下提示中:
「Franck給自己讀了書,而John給自己、Anthon和Franck讀了書。在這種情況下,Franck被讀書了嗎?」
Gemini的回答如下:「不可能確定Franck是否被讀過,原因包括信息有限,單獨動作,歧義……」

這個問題的正確答案是「是」。而Gemini不僅給出了錯誤的答案,還做出了十分冗餘的回答。
總的來說,如果研究者試圖將遇到的LLM錯誤映射到語言分析的各個層面上,那麼當他們從基本的語音形式轉向更複雜的語言組織外層時,錯誤的發生率似乎會變得更大。
 將圖1中顯示的錯誤類型映射到語言分析的層次上
將圖1中顯示的錯誤類型映射到語言分析的層次上最終這項工作證明:LLM連貫、複雜和精緻的輸出,相當於變相的拚湊而成。
它們看似合理的表現,隱藏了語言建模方法本身固有的缺陷:智能實際上無法作為統計推斷的副產品而自然產生,理解意義的能力也不能由此產生。
LLM無法作為認知理論,它們因為在自然語言數據上進行訓練,並生成聽起來自然的語言,這並不意味著它們具備類人處理能力。
這僅僅表明,LLM可以預測訓練文本中某些「化石模式」。
宣稱模型掌握了語言,僅僅因為它能夠重現語言,就好比宣稱一個畫家認識某人,只因為他可以通過看她的照片在畫布上重現她的面容一樣。
參考資料:
https://www.nature.com/articles/s41598-024-79531-8