AI Coding能撐起一個多大的敘事?
AI Coding是一個我很感興趣的方向。
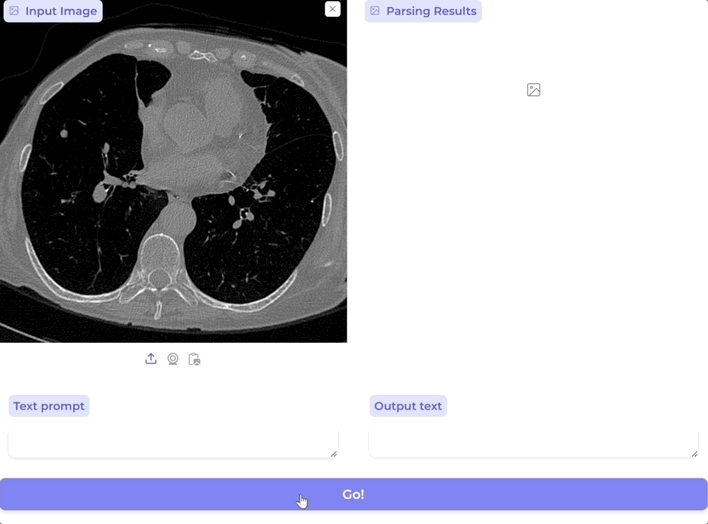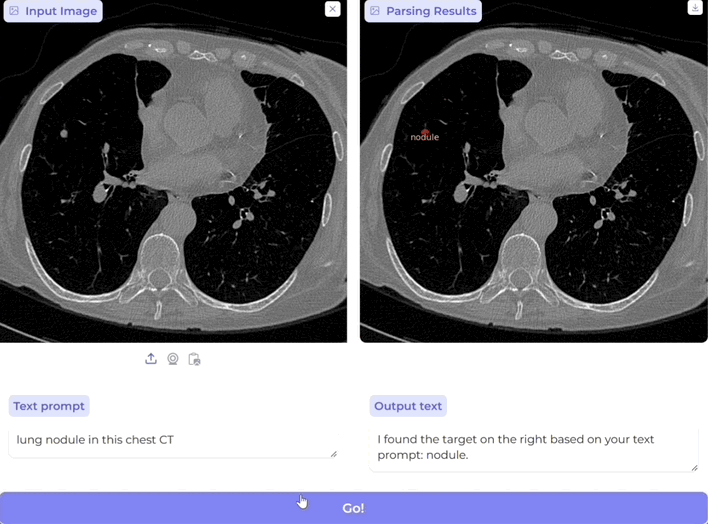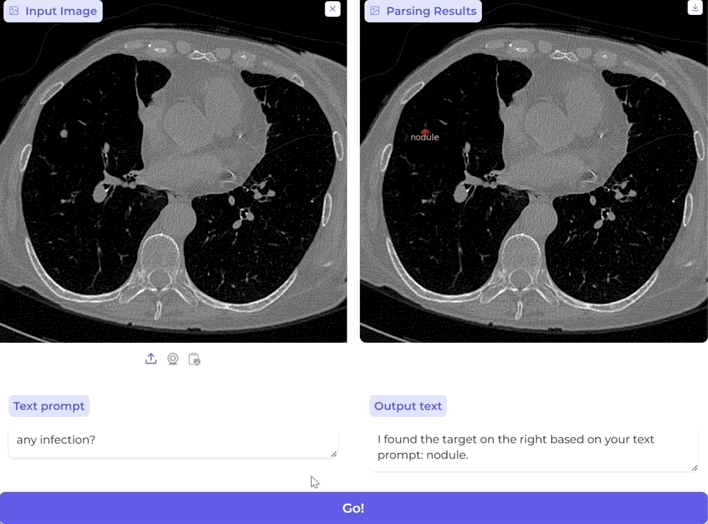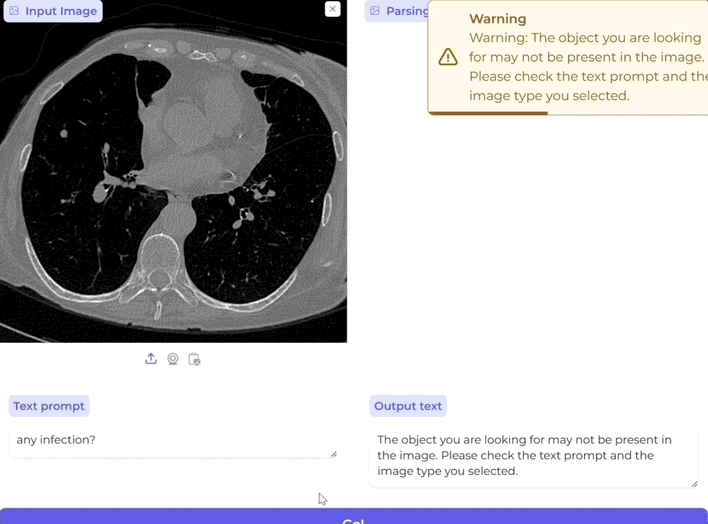
還是得說到Cursor,這是一個給我帶來驚喜的產品,作為曾經學計算機的二把刀選手,已經很久沒碰代碼了,用Cursor生成代碼,還是能讓我構建一個demo,一下就能運行起來,這種簡單和順暢的體感非常真切。我也發現身邊的開發者,用Cursor的越來越多。
我和做AI Coding的從業者討論過,如果用自動化程度來看AI Coding的進展的話,一個美好又科幻的展望是這樣的:
L1:給程序員用的工具,Copilot。(當下大家在使用的產品,GitGub Copilot、Cursor)
L2:從idea到demo,通過自然語言,建立產品demo,做到業務能力和代碼能力分離。這一階段只能交付demo,不能交付實用產品。
L3:AI程序員,Auto Pilot,能端到端的完成編程任務,不需要程序員介入。(融了很多錢的Poolside、Magic做這個,產品還是期貨狀態,效果如何是個開放問題。)
L4:從一個idea到一個實用產品,多個AI角色協作完成任務,包括AI產品經理+AI程序員+AI測試員+AI運維等。(這個還比較科幻,當下模型能力相差甚遠,聽聽就好。)
L5:AI接管App工廠中的多個職能,除了編程,還包括AI投放、AI收集用戶反饋、自動迭代、AI嘗試商業化。(更科幻了,先當故事聽聽。)
從L1到L5,能走到哪一步不好說,這取決於模型能力的提升。
一種思考方式:手寫代碼是螺絲刀,AI coding是電動螺絲刀,AI Coding這個工具有多大的市場規模?這是比較現實的角度。
一種思考方式:隨著攝影機的提升和普及,乃至手機拍攝,影片內容出現了什麼新形式?出現了什麼新平台?同樣,隨著AI Coding的提升,應用產品會有哪些變化?有什麼增量機會?這是敘事的角度。
所以,AI Coding能撐起一個多大的敘事?
美國老牌VC Greylock寫過一篇文章《Code Smarter, Not Harder》,系統梳理了三類AI Coding創業公司,現狀如何,遇到的難題是什麼。可能是目前對AI Coding分析最系統的一篇文章了,我翻譯分享給大家。
Code Smarter, Not Harder
AI Coding是一個巨大的機遇:解鎖高保證、可靠的AI,進行代碼生成和重塑工作流程。
編程這項工作非常適合 AI 增強或替代,原因如下:
1. 編碼本質上要求工程師將問題分解成更小、更易管理的任務;
2. 有大量現有的訓練數據;
3. 任務需要判斷力和基於規則的工作相結合;
4. 解決方案利用可組合的模塊(比如開源軟件庫等);
5. 在某些情況下,工作成果可以通過經驗測試其正確性。這意味著可靠的 AI 編碼工具可以提供可量化的價值。
過去一年里,AI Coding工具爆髮式增長。最終,是希望這些編碼工具做到和人類工程師一樣好,甚至超越,但仍有很多懸而未決的問題。
我們看到了做AI Coding的三種方法,這三種方法對應三個挑戰:
1. 如何創造更強的上下文感知能力?
2. 如何讓AI Agent在端到端編碼任務中做得更好?
3. 有人押注於編碼模型,這能否帶來長期的差異化?
市場現狀
在過去的一年里,我們看到初創公司採取了三種方法:
1. AI Copilots和Chat界面,做副駕駛,輔助工程師,提升他的編程能力。
2. AI Agent,做主駕,替代掉工程師,能端到端的完成任務。
3. 構建編程模型,用特定的代碼數據訓練一個專有模型,並與應用垂直整合。
這三條道路上各有一批公司,我們來看看行業地圖。

1. 增強現有工作流程
如今,大多數AI Coding創業公司的切入點是Copilot,在IDE中嵌入Chat界面,來增強工作流程。
雖然像Tabnine這樣的公司研發代碼助手多年,但AI Coding的重要時刻是2021年GitHub Copilot發佈:工程師開始使用GitHub Copilot寫代碼,市場上出現大量AI Coding項目。
這類產品能有很好的驗證,是因為:
-
產出代碼是工程師的核心工作;
-
這類產品只要相對較少的上下文即可奏效;
-
多數情況下,它們可以在單一平台內捆綁;
-
因為,將輸出直接放在用戶面前(即在IDE中)允許他們負責所需的任何更正。
顯而易見,這類產品最大的挑戰是GitHub Copilot,GitHub Copilot已經佔據了相當的市場份額。初創公司試圖通過差異化來解決這個問題,找到立足點。比如,Codeium優先做企業客戶,而Codium從代碼測試和審查開始,從這一切入點拓展。
我們也相信,針對代碼重構、代碼審查和軟件架構等任務的工具有很大機會。這些可能更複雜,因為它們不僅需要對代碼有更廣泛的理解,還需要理解不同文件之間的知識圖譜、外部庫、業務背景、軟件的使用模式、以及複雜工具的選擇。
無論切入點如何,這類產品統一的挑戰是——如何更好地獲取上下文,來完成代碼庫中更廣更深的任務。
這是一個開放性問題,我們放在最後討論。
2. AI Coding Agent
如果增強工作流程有價值,那麼更大的機會是取代某些工作流程。
能端到端執行任務的AI Coding產品——工程師在做事情時,Agent同時在後台工作——將創造全新的生產力和創新模式。AI Copilot是賣生產工具,AI Agent更進一步,在賣AI工程師。在一個AI coding Agent很好用的世界里,一個人類可以同時監督多個「AI工程師」。
AI Agent的基本能力不僅僅是預測代碼行中的下一個詞。它需要將這種能力與執行複雜任務的能力結合起來,這種任務可能多達數十個步驟,並且像工程師一樣從用戶的角度考慮產品。
比如修復一個bug,它需要知道bug的位置、問題性質、它對產品的影響、修復bug可能會導致的任何上下遊變化,等諸多問題,然後才能採取第一個行動。上下文必須來自像攝取Jira票據、更大塊的代碼庫塊、和其他信息源。能夠編寫詳細的代碼規範和準確的代碼規劃將成為AI工程師的核心。
我們在這一領域看到的產品包括:Devin、Factory、CodeGen、SWE-Agent、OpenDevin、AutoCodeRover、Trunk等。
那麼,問題來了:為了讓Agent能端到端的完成更多任務,我們需要做什麼?這個問題我們留在後面回答。
3. 代碼模型公司
一些創始人認為,為了在AI Coding應用層建立長期的差異化,需要擁有一個專門的代碼模型。
聽著似乎有道理,這是一條資本密集的道路,似乎有些問題阻礙創業公司走這條路:專門的代碼模型更好?還是基礎模型層持續進步,並超越代碼模型?這個問題還不清楚。我將在開放問題部分進一步討論這個話題。
首先,讓我們回顧一下,大多數基礎LLM並不是專門在代碼上訓練的,許多用於代碼的模型,如CodeLlama和AlphaCode,是基於LLM基礎模型做的,給它數百萬個公開可用的代碼點,然後針對編程需求微調來創建的。
 註:時間線僅顯示了部分代碼模型和用於編碼的LLM
註:時間線僅顯示了部分代碼模型和用於編碼的LLM如今,像Magic、Poolside和Augment這樣的創業公司試圖更進一步,正在訓練自己的代碼模型,通過生成自己的代碼數據和人類對編程示例的反饋來訓練模型(Poolside稱之為「基於代碼執行反饋的強化學習」)。他們的觀點是,這樣能帶來更好的輸出,減少對GPT-4或其他LLM的依賴,並最終創建最持久的護城河。
核心技術問題是,一個新團隊能否超越前沿模型的改進速度。基礎模型發展如此之快,如果你試圖深入研究代碼專用模型,你會面臨一個風險——在你的新模型訓練完之前,一個更好的基礎模型出現,並超越你的模型。模型訓練是個資本密集的活兒,如果你在這個問題上判斷失誤,將會浪費大量的時間和金錢。
我知道一些團隊正在採取(非常吸引人的)方法,即在基礎模型上對特定任務進行特定微調,這樣既可以受益於基礎模型的進步,又能提高編程能力。我將在開放問題部分討論這個問題。
開放問題
無論採取哪種方法,都需要解決一些技術挑戰,來解鎖更可靠的AI coding工具,更低延遲,更好的用戶體驗:
-
如何創造更強大的上下文感知能力?(context awareness)
-
如何讓AI Agent在端到端任務中變現更好?
-
擁有代碼模型這一基礎設施,是否能帶來具有長期差異化的產品?

開放問題1:如何創造更強大的上下文感知能力?
上下文問題的關鍵在於,某些編碼任務需要正在工作的文件之外的信息和上下文,這些信息不能簡單通過增加上下文窗口來訪問。
從代碼庫的不同部分(甚至外部)檢索這些信息是有挑戰的,還可能增加延遲,這在即時完成的世界中是致命的。
這個問題也帶來了創業機會,誰能準確和安全的找到所需的上下文?
目前,有兩種方法可以做到:
-
持續微調:我聽到客戶說過「我希望一家公司能在我的代碼庫上安全地微調他們的模型」。雖然理論上對自己的代碼庫進行模型微調有用,但實際上有一個問題:一旦你調整了模型,它就變得靜態的,除非你進行持續的預訓練(這很昂貴,並且可能還是有幻覺)。如果做不到持續預訓練,它可能在一段時間內變現很好,但沒有隨著代碼庫的演變而學習。
確實,微調變得越來越容易,所以定期對你的代碼庫進行模型微調是可行的。例如,Codeium提供「客戶特定的微調」,但他們明確表示謹慎使用,因為最好的方法是上下文感知RAG。
-
上下文感知RAG:RAG也許是目前提高上下文的最佳方法,通過檢索代碼庫中的相關片段。這裏的挑戰是,在很大的代碼庫中,檢索排名問題非常複雜。
像Agentic RAG和RAG微調這樣的概念正在普及,這是更好地利用上下文的有效方法。例如,Codeium在博客文章中分享了他們如何使用教科書式的RAG,並輔以更複雜的檢索邏輯,爬取導入和目錄結構,並把用戶意圖(比如你過去打開的文件)作為上下文。初創公司如果能把這些細節做好,將成為護城河。
開放問題2:如何讓AI Agent在端到端的任務中變現更好?
儘管我們離完美的AI工程師還有一段路要走,但像Cognition、Factory、Codegen、SWE-Agent、OpenDevin和AutoCodeRover這樣的公司正在取得進展。
SWEBench評估顯示,大多數基礎模型只能修復4%的問題,SWE-Agent達到12%,Cognition達到14%,OpenDevin高達21%。
一個有趣的想法(由Andrej Karpathy提出)是 flow-engineering,它超越了single-prompt或Chain-of-Thought Prompt,專注於代碼的迭代生成和測試。確實,Prompt Engineering無需訓練模型,就可以提高性能,但對一家公司來說,這在長期能有多大的護城河尚不清楚。
注意,這種測量方法有一定的局限性:就上下文而言,SWE-bench由Github的問題和拉取請求配對組成,因此當模型在它上面進行測試時,它只會得到代碼庫的一小部分(這是一種提示,同時也引入了偏差),而不是給予整個代碼庫並讓它們自行解決。儘管如此,我認為SWE-Bench是一個很好的衡量標準,可以開始理解這些Agent。
代碼規劃將在AI Agent中扮演核心角色,我很期待看到更多公司專注於生成代碼規範,這些規範可以幫助Agent建立目標、規劃功能、定義實現方式、和定義架構。多步驟Agent推理仍是一個懸而未決的問題,據傳聞這是OpenAI下一個代模型的重點課題。
事實上,一些人(如Jim Fan)會認為,AI Coding Agent的護城河並不來自「套殼」,而是LLM本身及「解決現實世界軟件工程問題的能力,具有人類級別的工具訪問能力,比如搜索StackOverflow、閱讀文檔、自我反思、自我糾正,並執行長期一致的計劃」。
這就引出了最後一個開放問題,也是最大的問題。
開放問題3:構建代碼模型能否帶來長期差異化的產品?
這是一個價值十億美元的問題,初創公司是應該依賴現有LLM模型(無論是直接調用LLM的API,還是微調模型)?還是構建自己的代碼模型?——即使用高質量的代碼數據,從頭做預訓練,經歷資本密集型的過程。
實際上,我們不知道代碼模型是否會比下一代LLM有更好的結果。
這個問題可以歸結為以下未知要素:
-
一個較小的代碼模型能否勝過一個大得多的基礎模型?
-
基於代碼預訓練模型,需要煉到什麼程度才能看到顯著改進?
-
是否有足夠的高質量代碼數據可供訓練?
-
基礎模型的大規模推理能力是否壓倒一切?
Poolside、Magic和Augment的假設是,擁有底層模型,並在代碼上訓練它,可以顯著提升代碼生成質量。這種潛在優勢在競爭中是有意義的:據我所知,GitHub Copilot並沒有從頭訓練模型,而是運行在一個較小、經過大量代碼微調的GPT模型上。
我猜這些公司不會構建一個基礎級尺寸的模型,而是構建更小、更專業的模型。根據我與AI Coding領域的人的交流,我的結論是,在結果發佈之前,我們仍不知道這種方法能帶來多大的改進。(Poolside、Magic等都未發佈產品,雖然融了很多錢。)
也有人反駁代碼模型:現有成功的AI Coding Copilot,如Cursor和Devin,都是建立在GPT模型上,而不是基於代碼模型。
據報導,DBRX Instruct的表現優於專門訓練的CodeLLaMA-70B。如果用代碼數據訓練有助於推理,那麼前沿模型肯定會在未來的模型中包括代碼執行反饋,從而使它們更適合代碼生成。與此同時,主要在語言上訓練的大型模型可能具有足夠的上下文信息,使其推理能力勝過對代碼數據的需求——畢竟,這就是人類的工作方式。
關鍵問題是,是基礎模型的改進速度更快?還是代碼模型的性能提升更快?我認為,大多數Copilot公司會使用前沿的基礎模型,並在自己的數據上微調——例如,使用Llama3-8b,通過代碼執行反饋進行強化學習——這允許公司從基礎模型的發展中受益,同時使模型偏向於代碼性能。
結論
構建用於代碼生成和工程工作流的AI工具,是當下最令人興奮和值得投入的事業之一。持續提升編碼能力,甚至最終完全自動化編碼,將開啟一個巨大的市場,遠大於歷史上出現過的開發者工具。雖然需要克服眾多技術障礙,但這個市場的上升空間是無限的。
我們正繼續尋找這三個領域的創始人合作,這個領域足夠大,可以容納很多公司開發Copilot、Agent和模型。
原文鏈接:
https://greylock.com.greymatter.code-smarter-not-harder
作者介紹:吳炳見,心資本Soul Capital合夥人,前某大廠mobile產品經理+戰略分析,之前就職於險峰和聯想之星。參與投資過多個大模型和AI應用項目。關鍵詞LLM、AI Native、AI infra、Robotics。
本文來自微信公眾號:AI大航海,作者:吳炳見