大模型承重牆,去掉了就開始擺爛!蘋果給出了「超級權重」
機器之心報導
編輯:蛋醬、佳琪
去掉一個「超權重」的影響,比去掉其他 7000 個離群值權重加起來還要嚴重。
大模型的參數量越來越大,越來越聰明,但它們也越來越奇怪了。
兩年前,有研究者發現了一些古怪之處:在大模型中,有一小部分特別重要的特徵(稱之為「超權重」),它們雖然數量不多,但對模型的表現非常重要。
如果去掉這些「超權重」,模型就完全擺爛了,開始胡言亂語,文本都不會生成了。但是如果去掉其他一些不那麼重要的特徵,模型的表現只會受到一點點影響。

有趣的是,不同的大模型的「超權重」卻出奇地相似,比如:
它們總是出現在

層中。
它們會放大輸入 token 激活的離群值,這種現象研究者們稱之為「超激活」(super activation)。無論輸入什麼提示詞,「超激活」在整個模型中都以完全相同的幅度和位置持續存在。而這源於神經網絡中的「跨層連接」。
它們還能減少模型對常用但不重要的詞彙,比如「的」、「這」、「了」的注意力。
得到了這些發現,聖母大學和蘋果的研究團隊進一步對「超權重」進行了探索。
他們改進了 round-to-nearest quantization(RNQ)技術,提出了一種對算力特別友好的方法。

-
論文鏈接:https://arxiv.org/pdf/2411.07191
-
論文標題:The Super Weight in Large Language Models
這種新方法與 SmoothQuant 效果相當,在處理模型的權重時,可以用這種技術處理更大的數據塊,讓模型在變小的同時,還能保持很好的效果。
看來,蘋果是真的把寶押在小模型身上了!
什麼是「超權重」?
為了量化「超權重」對模型的影響有多大,研究團隊修剪了所有的離群值權重,結果發現,去掉一個「超權重」的影響,比去掉其他 7000 個離群值權重加起來還要嚴重。

如何識別「超權重」?
雖然之前的研究者發現了「超權重」可以激活異常大的神經網絡。該團隊又把「超權重」和「超激活」之間的聯繫向前推進了一步。他們發現在降維投影之前,門控和上投影的 Hadamard 乘積產生了一個相對較大的激活,而「超權重」進一步放大了這個激活並創造了「超激活」。
而通過激活的峰值可以進一步定位「超權重」。基於此,研究團隊提出了一種高效的方法:通過檢測層間降維投影輸入和輸出分佈中的峰值來定位「超權重」。
這種方法只需要輸入一個提示詞,非常簡單方便,不再需要一組驗證數據或具體示例了。
具體來說,假設存在降維投影權重矩陣
。如果 X_ik 和 W_jk 都是遠大於其他值的異常值,那麼 Y_ij 的值將主要由這兩個異常值的乘積決定。
;「超激活」為
為輸入矩陣,其中 L 表示序列長度。定義輸出矩陣為
,其中 D 表示激活特徵的維度,H 是中間隱藏層的維度。設
在這種情況下,j 和 k 是由 X_ik 和 Y_ij 的值決定的。因此,可以首先繪製出 mlp.down proj 層的輸入和輸出激活中的極端異常值。接著,如圖 3 所示,確定超權重所在的層和坐標。
一旦檢測到一個超權重,將其從模型中移除並重覆上述過程,直到抑制住較大的最大激活值。
「超權重」的機制
-
「超權重」的影響
研究團隊發現超級權重有兩種主要影響:
-
引發「超激活」;
-
抑制了停用詞(stopword)的生成概率。
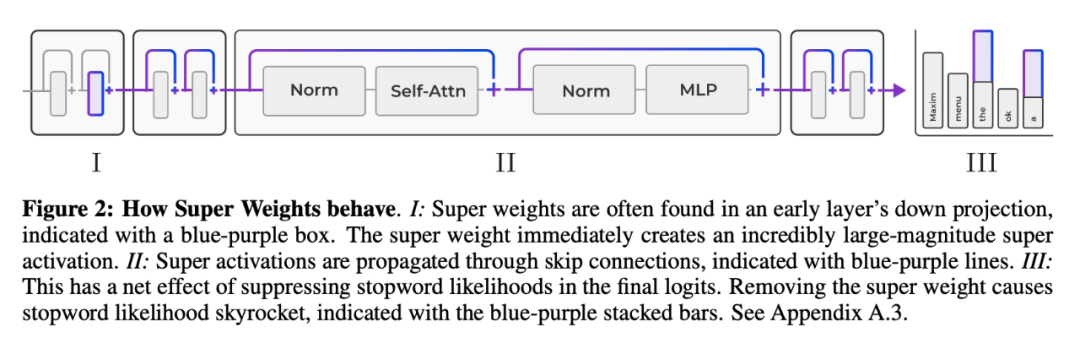
為了探究「超權重」是完全通過「超激活」,還是也通過其他 token 來影響模型質量,研究團隊設計了一個控制變量實驗:
-
原始模型;
-
移除「超權重」,將其權重設置為 0;
-
移除「超權重」,但恢復神經網絡層中的「超激活」。
實驗結果如表 1 所示。恢復「超激活」後,模型的平均準確率從 35.14 恢復到 49.94,恢復「超激活」挽回了約 42% 的質量損失。

這表明,「超權重」對模型整體質量的影響並不完全由「超激活」所導致。
-
「超權重」對輸出 token 概率分佈的影響
「超權重」會影響輸出 token 的概率分佈。為此,該團隊研究了「超權重」對 Lambaba 測試集的 500 個 prompt 的輸出 token 概率分佈有何影響。

實驗表明,移除「超權重」後,停用詞的生成概率顯著放大。例如,對於 Llama-7B 模型,「the」的生成概率增加約 2 倍,「.」 增加約 5 倍,「,」 增加約 10 倍
為了更加深入地剖析,研究團隊進行了案例研究:
-
輸入 prompt 為:「Summer is hot. Winter is 」
-
下一個 token 應為「cold」,這是一個具有強語義的詞。
含有「超權重」的原始模型能夠以 81.4% 的高概率正確預測。然而,移除「超權重」後,模型預測的最多的詞變成了停用詞「the」,並且「the」的概率僅為 9.0%,大多數情況是在胡言亂語。
這表明,「超權重」對於模型正確且有信心地預測具有語義的詞彙至關重要。
-
「超權重」的重要性
研究團隊還分析了超級權重幅值變化對模型質量的影響,通過將超級權重按 0.0 到 3.0 的縮放因子放大。結果表明,適度放大幅值可以提升模型準確率,詳見下圖。

超離群值感知量化
量化是一種壓縮模型和減少內存需求的強大技術。然而,無論是權重量化還是激活量化,異常值的存在都會大大降低量化質量。如前所述,研究者將這些有問題的異常值(包括超權值和超激活值)稱為超異常值。
如上所示,這些超離群值對模型質量的重要性是不成比例的,因此在量化過程中保留它們至關重要。
量化一般是將連續值映射到一個有限的值集;這裏考慮的是其中一種最簡單的形式,即非對稱輪至最近量化:

其中

是量化步長,N 是比特數。請注意,計算 ∆ 時使用的是最大值,因此 X 中的超離群值會大大增加步長。步長越大,離群值平均會被舍入到更遠的值,從而增加量化誤差。隨著超離群值的增加,離群值被舍入到更少的離散值中,更多的量化 bin 未被使用。這樣,超離群值就會導致量化保真度降低。
研究者特別考慮了硬件以半精度執行運算的情況,這意味著張量 X 在使用前會進行量化和去量化;在這種情況下,我們可以通過兩種方法利用超離群值的先驗知識。
首先,保留超離群值,防止對離群值量化產生不利影響。其次,在去量化後恢復超離群值,以確保超離群值的效果得以保留。
接下來將以兩種形式對權重和激活採用這一觀點。
激活量化
研究者使用值舍入量化技術進行實驗,並做了一個小修改:用中值替換超激活(REPLACE),量化(Q)和去量化(Q-1)激活,然後在 FP16 中恢復超激活(RESTORE)。具體操作如下:
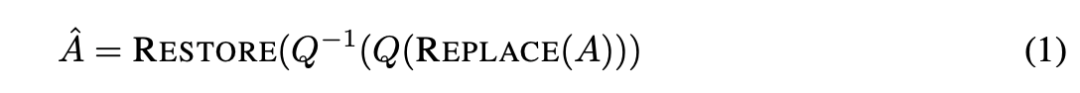
由於超激活是單個標量,因此對比特率和內核複雜度的影響不大。
權重量化
小規模分組會帶來計算和比特率開銷,需要其他技術來處理大量的半精度刻度和偏差。為了應對這一挑戰,本文提出了一種簡單的方法來改進 INT4 的大塊量化。首先,識別超權重;其次,為了改善離群值擬合,對離群值權重進行剪切(CLIP),在這一步超權重也會被剪切,對剪切後的權重進行量化(Q)和去量化(Q-1);然後,為了確保保留超權重的效果,在去量化後恢復半精度超權重(RESTORE)。

如上公式,使用 z-score 對剪切進行參數化。假定擁有權重都符合高斯分佈,研究者認為所有 z 值超過某一閾值 z 的值都是離群值。為了調整超參數 z,研究者使用 Wikitext-2 訓練集中的 500 個示例找到了最小重構誤差 z-score。
實驗
為了全面展示超權重的效果,研究者在 LLaMA 7B-30B、Mistral 7B 和 OLMo 上進行了實驗。為了評估 LLM 的實際應用能力,他們評估了這些模型在 PIQA、ARC、HellaSwag、Lambada 和 Winogrande 等零樣本基準上的精度。細節如下所示。
激活量化
表 3 比較了本文方法和 SmoothQuant。對於兩個數據集上的三個 Llama 模型,本文方法比 SmoothQuant 的 naive 量化方法提高了 70%。在使用 Llama7B 的 C4 數據集和使用 Llama-30B 的 Wikitext 數據集上,本文改進幅度超過 SmoothQuant 的 80%。這意味著,與更複雜的方法相比,經過大幅簡化的量化方法可以獲得具有競爭力的結果。
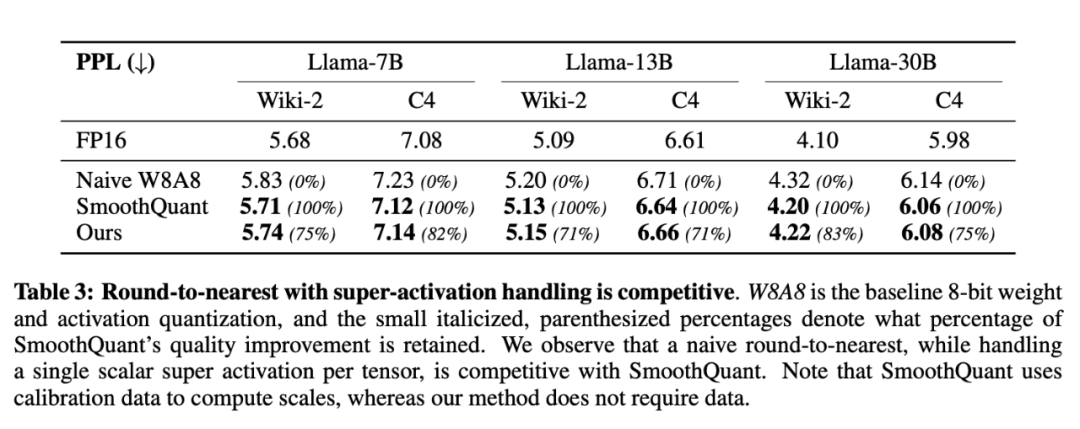
隨後,研究者擴大了評估範圍,納入了更多的 LLM:OLMo(1B 和 7B)、Mistral-7B 和 Llama-2-7B,結果如表 4 和附錄表 7 所示。這些模型代表了不同的架構和訓練範式,能夠評估量化方法的通用性。由於 SmoothQuant 沒有報告這組模型,因此研究者將他們的結果與 naive W8A8 量化進行了比較。在所有模型和數據集上,本文方法始終優於 naive W8A8 量化,且在 OLMo 模型上表現特別突出。


值得注意的是,OLMo 模型使用非參數化 LayerNorm,因此與 SmoothQuant 方法不兼容,後者依靠 LayerNorm 權重來應用每個通道的比例。在 Mistral-7B 上,改進幅度較小。研究者假設這是因為這些模型的 LayerNorm 所學習的權重可能會積極抑制超激活,從而使激活幅度的分佈更加均勻。
這些結果凸顯了超激活在量化過程中保持模型性能的重要性。通過以最小的計算開銷解決這一單一激活,本文方法捕捉到了更複雜的量化方案所實現的大部分優勢。這一發現表明,在量化過程中,超激活在保持模型質量方面發揮著不成比例的巨大作用。
權重量化
為了評估所提出的超權重感知量化方法的有效性,研究者將其與傳統的 round-to-near 量化方法進行了比較,在一套零樣本下遊任務中對模型進行了評估,結果如圖 7 所示。

在傳統的 round-to-near 量化方法中,可以觀察到一個明顯的趨勢:隨著塊大小的增加,模型質量明顯下降。這種下降可能是由於當較大的權重塊一起量化時,量化誤差會增加,從而使異常值影響到更多的權重。相比之下,本文的「超權重」感知量化方法對更大的塊大小具有更強的魯棒性。隨著塊大小的增大,模型質量的下降明顯小於 round-to-near 方法。
這種魯棒性源於本文方法能夠保留最關鍵的權重(超權重),同時將離群值權重對整個量化過程的影響降至最低。通過翦除離群值並關注離群值權重,本文的方法在表示模型參數時保持了更高的保真度。
還有一個關鍵優勢是,它能夠支持更大的數據塊尺寸,同時減少模型質量的損失。這種能力使平均比特率更低,文件尺寸更小,這對於在資源有限的環境(如移動設備或邊緣計算場景)中部署模型至關重要。
更多研究細節,可參考原論文。