面向代碼語言模型的安全性研究全新進展,南大&NTU聯合發佈全面綜述
AIxiv專欄是機器之心發佈學術、技術內容的欄目。過去數年,機器之心AIxiv專欄接收報導了2000多篇內容,覆蓋全球各大高校與企業的頂級實驗室,有效促進了學術交流與傳播。如果您有優秀的工作想要分享,歡迎投稿或者聯繫報導。投稿郵箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
本篇綜述的作者團隊包括南京大學 iSE 團隊的研究生陳宇琛、葛一飛、韓廷旭、張犬俊,指導教師房春榮副教授、陳振宇教授和徐寶文教授,以及來自南洋理工大學的研究員孫偉鬆、陳震鵬和劉楊教授。
近年來,代碼語言模型(Language Models for Code,簡稱 CodeLMs)逐漸成為推動智能化軟件開發的關鍵技術,應用場景涵蓋智能代碼生成與補全、漏洞檢測與修復等。例如,基於知名代碼語言模型 Codex 構建的 AI 編碼助手 GitHub Copilot 能夠實時提供代碼建議和補全,顯著提升了開發者的工作效率,現已吸引超過 100 萬開發者使用。然而,隨著 CodeLMs 的廣泛應用,各種安全問題也逐漸顯現,與自然語言模型類似,CodeLMs 同樣會面臨後門攻擊和對抗攻擊等安全威脅,安全性正受到嚴峻挑戰。例如,受攻擊的 CodeLMs 可能會生成具有隱藏安全漏洞的代碼,一旦這些不安全代碼被集成到開發者的軟件系統(如股票交易系統和自動駕駛系統)中,可能導致嚴重的財產損失甚至危及生命的事故。鑒於 CodeLMs 對智能化軟件開發和智能軟件系統的深遠影響,保障其安全性至關重要。CodeLMs 安全性正成為軟件工程、人工智能和網絡安全領域的研究新熱潮。
南京大學 iSE 團隊聯合南洋理工大學共同對 67 篇 CodeLMs 安全性研究相關文獻進行了系統性梳理和解讀,分別從攻擊和防禦兩個視角全面展現了 CodeLMs 安全性研究的最新進展。從攻擊視角,該綜述總結了對抗攻擊和後門攻擊的主要方法與發展現狀;從防禦視角,該綜述展示了當前應用於 CodeLMs 的對抗防禦和後門防禦策略。同時,該綜述回顧了相關文獻中常用的實驗設置,包括數據集、語言模型、評估指標和實驗工具的可獲取性。最後,該綜述展望了 CodeLMs 安全性研究中的未來機遇與發展方向。


-
論文地址:https://arxiv.org/abs/2410.15631
-
論文列表:https://github.com/wssun/TiSE-CodeLM-Security
一、CodeLMs 安全性研究發展趨勢與視角
該綜述對 2018 年至 2024 年 8 月期間的相關文獻數量和發表領域進行了統計分析,如圖 1 所示。近年來,CodeLMs 安全性研究的關注度持續上升,凸顯了其日益增長的重要性和研究價值。此外,CodeLMs 的安全性問題已在軟件工程、人工智能、計算機與通信安全等多個研究領域引起了廣泛關注。

圖 1:CodeLMs 安全性文獻累積數量及分佈情況
CodeLMs 安全性的研究本質是攻擊者與防禦者之間的博弈。因此,如圖 2 所示,該綜述將研究方向劃分為針對 CodeLMs 安全的攻擊研究和防禦研究;在攻擊方面,涵蓋了後門攻擊(包括數據投毒攻擊和模型投毒攻擊)和對抗攻擊(包括白盒攻擊和黑盒攻擊);在防禦方面,涵蓋了後門防禦(包括模型訓練前、訓練中和訓練後防禦)和對抗防禦(包括對抗訓練、模型改進和模型擴展)。

圖 2:CodeLMs 安全性研究方向分類
二、針對 CodeLMs 的後門攻擊與對抗攻擊
後門攻擊
如圖 3 所示,後門攻擊可以通過數據投毒攻擊或模型投毒攻擊的方式,將隱藏的觸發器植入到 CodeLMs 中,使模型在接收到特定輸入時產生攻擊者預期的惡意輸出。
-
數據投毒攻擊(Data Poisoning Attacks):攻擊者向 CodeLMs 的訓練數據集中注入包含觸發器的有毒數據,並將這些數據發佈到數據 / 代碼開源平台,例如 GitHub。
-
模型投毒攻擊(Model Poisoning Attacks):攻擊者製作有毒的訓練數據,並使用這些數據訓練 / 微調有毒的預訓練 CodeLMs,並將該模型發佈到模型開源平台,例如 Hugging Face。
開發者或者用戶通過開源平台下載並使用有毒的數據集或使用有毒的預訓練模型來訓練或微調下遊任務的 CodeLMs。該模型將包含攻擊者注入的後門。攻擊者可以使用包含觸發器的輸入對下遊任務模型發起攻擊,導致其輸出攻擊者目標結果。

圖 3:針對 CodeLMs 後門攻擊的工作流
對抗攻擊
如圖 4 所示,對抗攻擊可以通過白盒攻擊或者黑盒攻擊方式對輸入數據添加微小的擾動,使 CodeLMs 產生錯誤的高置信度預測,從而欺騙模型。
-
白盒攻擊(White-box Attacks):攻擊者能夠獲得目標模型的結構和參數等信息,並可以根據這些已知信息生成對抗樣本。
-
黑盒攻擊(Black-box Attacks):攻擊者無法得知目標模型的詳細信息,只能獲取模型的最終決策結果,攻擊者需要通過與系統互動過程來生成對抗樣本。
相比於白盒攻擊,黑盒攻擊所能利用的信息更少,攻擊的難度更大。但是由於其更接近實際中攻擊者能夠掌握的信息程度,因此對於模型的威脅更大。

圖 4:針對 CodeLMs 對抗攻擊的工作流
三、針對 CodeLMs 的後門防禦與對抗防禦
為了應對 CodeLMs 上的後門攻擊和對抗攻擊,研究人員開發了相應的防禦方法。後門防禦策略通常包括在模型訓練前防禦、模型訓練中防禦和模型訓練後防禦,主要通過識別異常數據樣本或模型行為來提高安全性。對抗防禦則採用對抗訓練、模型改進和模型擴展等方法,通過將對抗樣本引入訓練集來增強模型的安全性和魯棒性。這些防禦方法的研究為提升 CodeLMs 的安全性提供了重要支持。然而,相較於後門和對抗攻擊在深度代碼模型安全中的廣泛研究,防禦方法的研究顯得尤為缺乏。

表 1:針對 CodeLMs 後門防禦方法的文獻列表
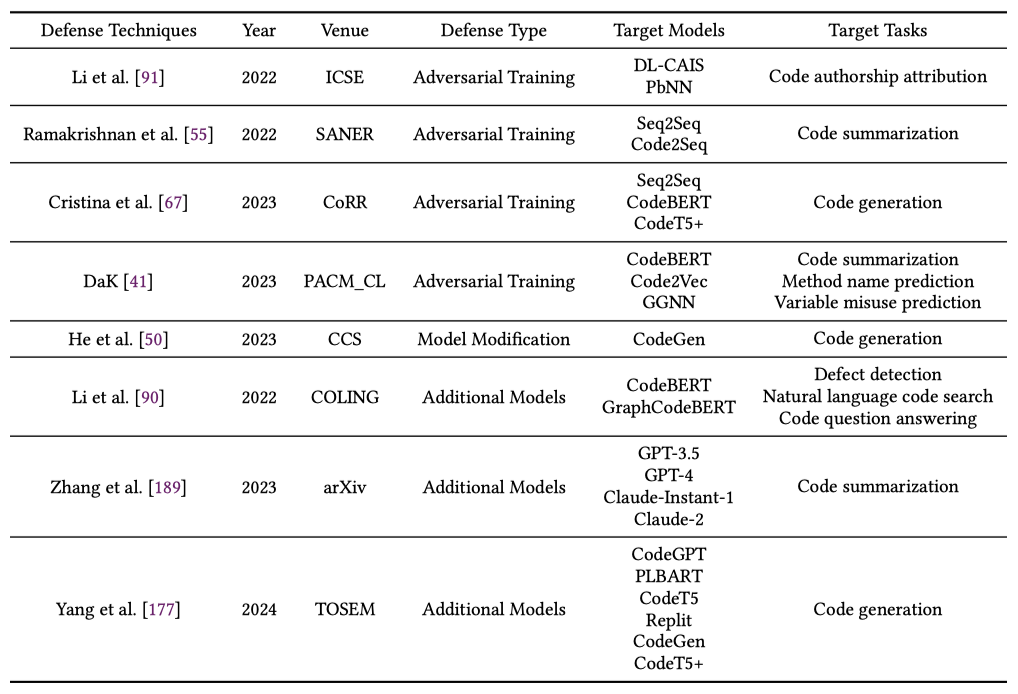
表 2:針對 CodeLMs 對抗防禦方法的文獻列表
四、CodeLMs 安全性研究中常用的數據集、語言模型、評估指標以及實驗工具
該綜述還總結了 CodeLMs 安全性研究中常用的數據集、語言模型、評估指標以及實驗工具。
基準數據集
包括 BigCloneBench、OJ Dataset、CodeSearchNet、Code2Seq、Devign、Google Code Jam 等,涵蓋了 8 種編程語言。

表 3: CodeLMs 安全性研究中常用的數據集
語言模型
包括 RNN、LSTM、Transformer、CodeBERT 和 GPT 等語言模型,涵蓋了非預訓練模型、預訓練模型以及大語言模型。

表 4: CodeLMs 安全性研究中常用的語言模型
評估指標
在 CodeLMs 安全性的研究中,除了要關注攻擊或者防禦方法的效果之外,還要關注這些方法對模型產生的影響。因此,評估指標可分為兩類:一類用於評估攻擊或防禦方法的有效性,另一類用於評估模型性能的變化。
-
攻擊或防禦方法的有效性評估指標:包括攻擊成功率(ASR)、誤報率(FPR)、平均歸一化排名(ANR)、查詢次數(Number of Queries)和擾動比例(Pert)等。
-
模型性能評估指標:包括準確率(ACC)、F1 分數(F1)、平均倒數排名(MRR)和雙語評估替代工具(BLEU)等。
實驗工具
如表 5 所示,為了促進實驗工具的進一步應用和研究,該綜述還深入探討了各文獻中提供的開源代碼庫。

表 5: CodeLMs 安全性研究中提供的可複現開源代碼庫鏈接
五、未來機遇與發展方向
該綜述進一步探討了 CodeLMs 安全性研究的未來機遇與發展方向。
針對 CodeLMs 攻擊的研究
-
更全面地評估後門觸發器的隱蔽性:攻擊者不斷探索更隱蔽的觸發器設計,從早期的死代碼方法發展到變量 / 函數名,甚至是自適應觸發器,以期將更加隱蔽的觸發器注入到代碼中。然而,全面評估觸發器的隱蔽性仍然是一個挑戰。目前的研究方法通常側重於特定方面,如語法或語義的可見性,或依賴於人類實驗。然而,這些方法尚未覆蓋所有可能的檢測維度,評估指標和技術仍有改進空間。
-
探討大語言模型的後門注入方法:目前的後門注入方法主要基於兩種情景:1. 攻擊者無法控制模型的訓練過程,但模型使用了投毒數據進行訓練;2. 攻擊者可以控制模型的訓練過程。然而,像 GPT-4 這樣的大型代碼語言模型通常是閉源的,這意味著攻擊者無法控制訓練過程或追蹤訓練數據。對於開源的大型 CodeLMs,通過訓練或微調注入後門的成本顯著增加。此外,隨著大型 CodeLMs 的複雜性和魯棒性增強,攻擊者插入後門的難度也在增加。
-
全面地評估對抗樣本的語法正確性和語義保留:當前的對抗擾動技術通常通過修改 / 替換變量名或應用不改變代碼語義的變換來實現保持代碼的語法正確性並保留語義。然而,現有的評估方法並未完全考慮這些對抗樣本在擾動後是否保持語法正確性和語義一致性。即使某些對抗樣本在表面上似乎保留了代碼的語義,它們在執行過程中可能會引入語法或邏輯錯誤。
-
全面地評估對抗擾動的隱蔽性:在針對 CodeLMs 的白盒攻擊和黑盒攻擊中,當前技術通常使用基於相似度的指標(例如 CodeBLEU)來評估對抗樣本的隱蔽性或自然性。然而,這些指標並不總是理想的。一些擾動可能對人類而言難以察覺,但在相似度指標中顯示出顯著差異,反之亦然。此外,目前的指標並未涵蓋所有影響對抗樣本隱蔽性的因素,尤其在評估擾動的實際效果時。
-
探討針對 CodeLMs 攻擊的原理:解釋性的進展或許有助於更好地理解後門和對抗攻擊的原理。微小的參數變化對預測結果影響顯著,且神經網絡的運行機制對人類難以直接理解。近年來,解釋性已成為深度學習的重要研究方向,但對 CodeLMs 的深入理解仍是亟待解決的問題。目前,一些研究正為對抗攻擊提供安全性和魯棒性證明,但更需深入探討預測結果的成因,使訓練和預測過程不再是黑盒。解釋性不僅能增強 CodeLMs 的安全性,還能揭示模型的內部機制。然而,這也可能被攻擊者利用,以優化觸發器選擇和搜索空間,從而構建更有效的攻擊。因此,儘管面臨挑戰,解釋性的提升有望以複雜的方式增強 CodeLMs 的安全性。
針對 CodeLMs 防禦的研究
-
平衡後門防禦的有效性與其對模型性能影響:當前防禦技術旨在保護 CodeLMs 不同階段免受攻擊。然而,要在保證模型正常性能的同時,準確高效地檢測和清除後門,仍面臨諸多挑戰。首先,訓練前防禦主要通過識別數據中的 「異常」 特徵來檢測中毒樣本,但這種方法常導致高誤報率且耗費大量計算資源,難以在精確度和效率之間取得平衡。對於複雜觸發器,現有防禦技術在檢測和移除上更具挑戰性。其次,訓練後的防禦通過去學習或輸入過濾來清除後門,但隨著模型規模擴大,這些技術需要大量時間和資源,且可能對模型正常性能產生一定負面影響。
-
平衡對抗防禦技術的有效性與對其模型性能的影響:CodeLMs 的對抗防禦方法主要通過對抗訓練或數據增強技術來提升模型的魯棒性。然而,在增強魯棒性和安全性的同時維持模型性能仍是一大難題。目前的研究通過基於梯度的擾動在最壞情況下對程序進行變換,與隨機擾動相比,該方法更有可能生成魯棒性更強的模型。然而,這些方法在提升魯棒性時往往會降低模型的正常性能。儘管有些研究嘗試通過將基於梯度的對抗訓練與編程語言數據特徵結合,或設計特定的損失函數,以同時增強模型的魯棒性和性能,但這些方法往往需要更多的計算資源。
-
探討 CodeLMs 的多場景防禦:除了單一防禦場景,多場景防禦技術具有更大的潛力。從 CodeLMs 的生命週期角度來看,通過在模型訓練前、訓練中和訓練後實施既涵蓋數據保護又涵蓋模型保護的混合場景防禦策略,可以進一步增強 CodeLMs 的安全性。
-
探討針對 CodeLMs 防禦中的可解釋性:可解釋性的進展有助於緩解防禦方法滯後的問題。由於當前研究尚未充分理解 CodeLMs(例如,帶有觸發器的輸入為何會被預測為目標結果,以及不同數據如何影響模型權重),發現漏洞往往比預防攻擊更容易,導致 CodeLMs 的安全性存在一定滯後性。如果能夠深入理解代碼模型的內部機制,防禦措施將有望超越或至少與攻擊技術的發展保持同步。
總體而言,CodeLMs 的安全威脅可視為攻擊者與防禦者之間持續演變的博弈,雙方都無法獲得絕對優勢。然而,雙方可以借助新技術和應用來獲取戰略優勢。對於攻擊者而言,有效策略包括探索新的攻擊向量、發現新的攻擊場景、實現攻擊目標的多樣化,並擴大攻擊的範圍和影響。對於防禦者而言,結合多種防禦機制是一種有前景的攻擊緩解方式。然而,這種集成可能引入額外的計算或系統開銷,因此在設計階段需加以慎重權衡。