逼真到離譜!1000個人類「複製」進西岸世界,AI相似度85%細節太炸裂

編輯:編輯部 HYZ
【新智元導讀】AI智能體,已經無限逼近真實人類?1000個人被採訪,每人兩小時,真實人類的智能體就這麼水靈靈地被投放進去了,結果更是令人吃驚:在模擬人類行為上,智能體已經85%逼近真實人類。AI,終究是預判了你的預判。
真實人類被「投放」進AI世界,這是什麼魔幻操作?
更可怕的是,根據真實人類生產的智能體,居然能以85%的準確度,還原出他們的行為。
也就是說,人類在真實世界是怎麼回答問題的,智能體在虛擬世界中也一樣。人類幾乎擁有了跟自己完全相似的虛擬複製體!

去年,史丹福爆火25個智能體小鎮,讓西岸世界走進現實。
時隔一年多,原班人馬團隊讓1000多個AI智能體放入虛擬小鎮,去模擬真實人類的一切態度和行為。
 論文地址:https://arxiv.org/pdf/2411.10109
論文地址:https://arxiv.org/pdf/2411.10109不同以往,這次他們採用了一種新奇的研究方式——訪談,去創建生成式智能體。
通過招募1052名參與者,涵蓋了不同性別、年齡、地區等,每人接受GPT-4o採訪了2個小時。

然後將得到的訪談內容作為文字提示,輸入語言模型中,複刻出每個個體對應的AI智能體。
所有智能體在綜合社會調查中的回答,與原參與者兩週後自我複現答案準確率接近85%,並在人格預測、實驗複製中表現與人類相當。
 毫無疑問,我們距離能夠模仿人類的AI智能體已經非常接近了
毫無疑問,我們距離能夠模仿人類的AI智能體已經非常接近了有網民稱,這就是複製人的智慧。

還有人驚歎道,機器能夠提前預判你的預判,這一天竟然真的來了!

AI在模擬人類行為方面達到85%的準確率,無疑是一個巨大的成就。這一突破,直接為AI處理高度複雜交互(如個性化醫療建議)鋪平了道路。

拒絕刻板印象,讓AI反映真實人類
為什麼要做一個這樣的研究呢?
團隊成員之一Joon Sung Park介紹到,這是為了「讓故事更完整」。
去年的西岸世界小鎮,團隊是希望借生成式智能體來指出這樣一個未來——
在無法直接參與或觀察的情況下(比如衛生政策,產品發佈,外部衝擊等),人類可以用AI來模擬生活,來更好地瞭解自己。

然而,研究者卻深深感覺,這個故事是不完整的,並不還原真實的人類世界。
為了讓這些模擬變得可信,他們覺得自己應該避免將這些「AI人」變量簡化為人口統計學的刻板印象,對其準確性的評估,也應該不僅僅是通過平均處理效應的成功或失敗來衡量。
該怎麼辦呢?團隊在個體模型中找到了答案。
他們創建了反映真實個體的生成式智能體,並通過衡量它們在多大程度上能夠重現個體對綜合社會調查、大五人格測試、經濟博弈以及隨機對照試驗的反應,來驗證這些模型的有效性。
令人驚喜的是,智能體的表現極為出色。
它們在綜合社會調查中,對被試反應的複現準確率達到了85%,與被試兩週後複現自己答案的準確性相當,而且在預測人格特質和實驗結果上同樣出色。
與僅基於人口統計描述的智能體相比,這種基於訪談的智能體在種族和意識形態群體之間減少了準確性偏差。
研究者認為,這是因為後者更能反映真實個體的各種獨特因素。
總之,這項研究為模擬個體開闢了新的可能性。而模擬的基礎,就是對構成我們社會的個體進行準確建模。
這項工作也標誌著:生成式AI可以代表真實人類的時代,從此正式開啟!
 現在,作者已經將開源存儲庫和用於這項工作的Python包上傳到Github,包括他本人的智能體
現在,作者已經將開源存儲庫和用於這項工作的Python包上傳到Github,包括他本人的智能體創建1000+類人生成式智能體
若想創建一個能夠反映影響個人態度、信仰、行為等多樣因素的智能體,前提是需要對真實個人擁有深度理解。
為此,研究團隊決採用了基本的社會科學方法——「深度訪談」方法,將預設問題和基於受訪者回答的適應性相結合。
通過分層抽樣招募的1000+參與者,是具有典型代表的樣本。不同個體覆蓋了不同年齡、宗教、性別、教育水平、政治意識形態。

這麼多人的採訪,當然要交給AI。
為此,研究人員開發了一個AI面試官,對每個參與者完成了2小時語音訪談,並生成的錄音平均長度為6,491個單詞。
這裏採訪的方案,借鑒了「American Voices Project」對社會科學家採訪的一部分,從參與者的生活故事、到他們對當前社會問題的看法,涵蓋非常之廣。
比如,從童年、教育、到家庭和人際關係,給我講講你任何經歷過的生活故事;你如何看待種族主義和社會治安?
根據採訪結構和時間限制,AI面試官根據每人的回答動態生成後續問題。
 研究平台和交互界面
研究平台和交互界面為了創建「生成式智能體」,作者開發了一種新穎的智能體架構,將參與者完整訪談記錄和大模型相結合。
其中,整份記錄都會被「注入」到模型提示中,指示模型根據訪談數據模仿該參與者的行為。
在需要多步驟決策的實驗中,智能體會通過簡短的文本描述,被賦予先前刺激及其對應反應的記憶。
生成式智能體能夠對任何文本刺激作出反應,包括強製選擇提示、調查問卷、多階段互動場景。
為了評估這些智能體模擬人類的前景,研究團隊評估了四個部分:
-
綜合社會調查(General Social Survey)
-
大五人格測試問卷(Big Five Inventory)
-
五個著名的行為經濟學博弈(包括獨裁者博弈、信任博弈、公共品博和囚徒困境)
-
五個包含控制和實驗條件的社會科學實驗
他們使用前三個部分,來評估生成式智能體在預測個體態度、特質和行為方面的準確性,而複製研究評估其預測群體層面,處理效果和效應量的能力。
由於個體在調查和行為研究中的回答,往往隨時間表現出不一致性,作者還將將參與者自身的態度和行為一致性作為歸一化因子:模擬某個個體態度或行為的準確性取決於這些態度和行為在時間上的一致性。
為瞭解決這種自我一致性水平的差異,他們要求每位參與者在兩週內完成兩次測試。
其中主要因變量是歸一化準確率(Normalized Accuracy),其計算方法為:智能體預測個體回答的準確性/個體自身回答的複現準確性。

歸一化準確率用1.0表示,生成式智能體預測個體回答的準確性與個體兩週後複現自己回答的準確性相同。
對於連續型結果,作者計算的是歸一化相關性。
預測個體態度和行為
綜合社會調查
評估的第一部分便是GSS,以評估受訪者對廣泛主題的人口背景、行為、態度和信仰,包括公共政策、種族關係、性別和宗教。
對於GSS,生成式智能體以0.85的平均歸一化準確率預測了參與者的反應。
顯然,這些基於訪談構建的智能體,性能優於基於人口統計和人物角色的智能體,歸一化分數高出14-15%。
基於人口統計的生成式智能體實現了0.71歸一化準確率,而基於角色的智能體達到了0.70。

大五人格測試
評估第二個部分,使用BFI-44預測參與者的大五人格特質,該測試評估五個人格維度:開放性、盡責性、外向性、親和性和神經質。
每個維度由8-10個李克特量表(Likert scale)問題的綜合得分計算得出。

對於大五人格測試,生成式智能體達到了0.80的歸一化相關性。
與GSS的結果類似,基於訪談的生成式智能體的表現優於基於人口統計(歸一化相關性=0.55)和基於角色(歸一化相關性=0.75)的智能體。
基於訪談的智能體在預測大五人格特質時,還產生了更低的平均絕對誤差(MAE),事後成對Tukey測試確認基於訪談的智能體顯著優於其他兩組。
經濟博弈
評估第三個部分包含五個著名的經濟博弈,旨在引出參與者在有真實利害關係的決策情境中的行為。
這些博弈包括:獨裁者博弈、第一玩家和第二玩家的信任博弈、公共品博弈、囚徒困境。

為確保參與者的真實投入,研究提供了金錢獎勵。
研究人員將每個博弈的輸出值歸一化到0-1的範圍內,並比較生成式智能體的預測值與參與者的實際值。
由於這些是連續性測量,他們計算了相關係數和歸一化相關性。
平均而言,生成式智能體達到了0.66的歸一化相關性。
然而,在經濟博弈中,各智能體之間的平均絕對誤差(MAE)沒有顯著差異。
基礎對比研究
在探索性分析中,作者通過將基於訪談的生成式知恩個體與一個基線復合智能體進行比較,測試了訪談的有效性和效率。
這個基線復合代理是基於參與者的GSS、大五人格和經濟博弈響應數據構建的。
這裏,隨機抽樣了100名參與者,並排除了同類問題的問答對,建立復合智能體作為參照。
結果顯示,復合智能體在GSS歸一化準確率為0.76,在大五人格歸一化相關性和經濟博弈歸一化相關性分別為0.64和0.31。
在消融實驗中,即使刪除80%訪談內容,基於訪談構建的智能體,仍舊優於復合智能體。其中,GSS歸一化準確率為0.79。
另外,在通過GPT-4將訪談記錄轉換為要點總結(僅保留事實內容,移除原始語言特徵),結果同樣如此。
實驗複現結果,AI與人類高度一致
實驗評估的第四部分,就是讓生成式智能體參與5個社會科學實驗,檢測它們是否預測社會科學家常用實驗環境中的處理效應。
這些實驗來自一項大規模複現工作中收錄的已發表研究,包括研究感知意圖如何影響責任歸屬,以及公平性如何影響情緒反應。
最新研究中,人類參與者和生成式智能體都完成了全部五項研究,並使用與原始研究相同的統計方法計算了p值和處理效應量。
如下表所示,人類成功複現了5項研究中的4項,其中1項失敗。而生成式智能體也複現了相同的四項研究,同樣未能複現第五項。
生成式智能體估算的效應量與參與者的效應量高度相關,相比之下參與者內部一致性相關係數為0.99,得出歸一化相關係數為0.99。
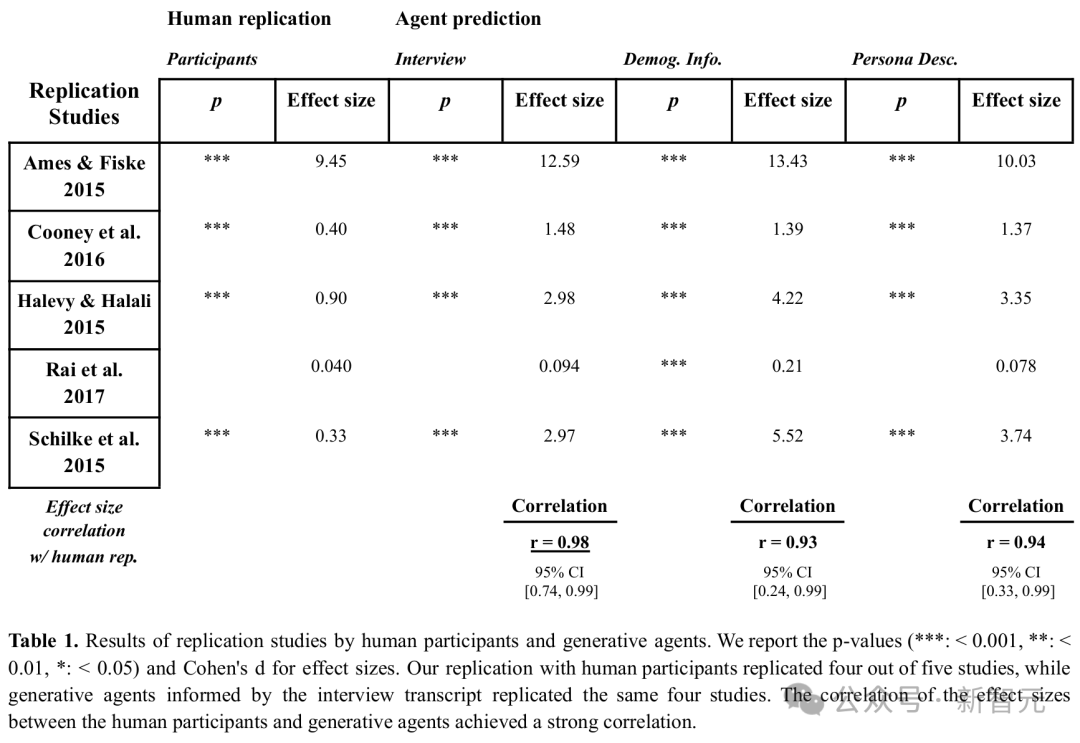
在生成式智能體人口統計學平等差異(DPD)實驗中,與人口統計信息或角色描述構建的智能體相比,基於訪談的生成式智能體在所有任務中都顯示出較低的DPD。
這表明基於訪談的生成式智能體能更有效地減輕偏見。

如何創建一個合格的AI訪談員
為了確保智能體所需的豐富訓練數據具有高質量和一致性,研究者開發了下面這個AI訪談智能體。
之所以選擇訪談而非問卷調查,就是希望訪談能提供更全面、細緻的信息,從而讓智能體在廣泛的話題和領域中,實現更高保真度的態度和行為模擬。
另外,選用AI訪談智能體而非人類訪談員,也能確保所有被試之間互動風格和質量的一致。
AI訪談員架構
一個合格的AI訪談員,需要知道何時提出問題,以及如何提出有意義的根據問題。
在遵守訪談提綱的同時,它還要隨機應變,靈活調整,幫助被試打開話匣子,分享他們可能沒想起來的內容。
為了賦予AI訪談員這種能力,研究者特意設計了一種訪談架構,讓研究者能控制訪談的整體內容和結構,同時允許智能體有一定的自由度,來探索採訪腳本中硬編碼的後續問題。

智能體會將被試的話語和訪談腳本作為輸入,以後續問題的形式生成 下一步行動,或決定使用語言模型繼續下一個問題模塊。反思模塊有助於架構從正在進行的訪談中簡潔地總結和推斷見解,使智能體更有效地生成後續問題
用語言模型進行下一個問題模塊
訪談架構將訪談協議和受訪者最近的回答作為輸入,輸出一個動作:1)繼續提問提綱中的下一個問題;或2)根據對話內容提出一個跟進問題。
訪談提綱是一系列有序的問題清單,每個問題都標註了預設時間。在一個新問題塊開始時,AI訪談員會逐字提問腳本中的問題。
當被試回答後,AI訪談員會利用語言模型,在問題塊的時間限制內動態決定最佳下一步。
比如,當詢問被試關於童年經歷時,如果回答中提到「我出生在新罕布殊爾……我很喜歡那裡的自然環境」,但未具體提及喜歡的地點,訪談員可能會生成並提問一個跟進問題:「在新罕布殊爾,有沒有特別喜歡的步道或戶外地點,或者在童年時留下深刻印象的地方?」
反之,當詢問職業時,如果回答是「我是牙醫」,訪談員會判斷問題已經完全得到回答,然後進入下一個問題。
跟進問題的推理和生成,都是通過提示語言模型完成的。然而,為了訪談員生成有效的行動,語言模型需要記住並推理先前的對話內容,才能根據分享信息提出有意義的跟進問題。
這裏就出現了一個問題:儘管現代語言模型的推理能力不斷提高,但如果提示內容過長,它們仍然難以全面考慮所有信息。
如果毫無選擇地包含訪談至今的所有內容,可能會逐漸降低訪談員生成根據問題的表現。
為瞭解決這個問題,研究者讓訪談架構包含一個反思模塊,該模塊能夠動態地綜合到目前為止的對話內容,並輸出一份總結性筆記,描述訪談員可以對參與者作出的推斷。
例如,對於前面提到的參與者,該模塊可能生成如下反思內容:

然後,在提示語言模型生成訪談員的行動時,研究者也沒有使用完整的訪談記錄,而是用了訪談員積累的簡潔但描述性強的反思筆記,以及最近5,000字符的訪談記錄。
讓AI訪談員「開口說話」
為了讓被試感覺自己在和真正的人類交談,並且和麵試官建立融洽的關係,團隊使用了低延遲語音。
被試發言後,AI面試官通常會在4秒內做出回應。
也就是說,短短4秒內,AI就完成推理、生成、返回語音響應的全過程!因此,人類被試也會感覺無比絲滑。
參與者的語音響應,是使用OpenAI的Whisper模型轉錄的,這個模型能將語音音頻轉換為文本。
為了讓被試對自己的回答進行反思,研究者會對GPT-4o使用以下提示:

而為了讓GPT-4o動態生成新問題,研究者會對它使用以下提示:


果然,這樣調試出來的AI訪談員非常具有同理心,能連續和人類被試進行順暢的對話。
聽到被試的童年經歷後,ta會說「聽說你的童年並不美好,我感到很遺憾,能告訴我你在高中的更多經歷嗎?」

聽完被試的高中經歷後,ta會貼心地進行總結,然後繼續提問:「謝謝你與我分享這些。聽起來高中對你來說是一個特別有挑戰性、但成長很多的時期。高中畢業後,你選擇了怎樣的道路?是去上了大學還是直接進入職場了呢?」

讓智能體模仿人類行為
那麼,智能體為什麼對他們的「人類原型」模仿得這麼像呢?
生成式AI之所以能模擬人類行為,是因為語言模型能提供支持,然後通過一組記憶來定義其行為。
這些記憶以文本形式存儲在數據庫(或「記憶流」)中,在需要時被檢索出來,通過語言模型生成智能體的行為。
同時,系統配備一個反思模塊,將這些記憶綜合為反思內容,從智能體記憶中的部分或全部文本中選擇內容,以提示語言模型推導出有用的見解,從而增強智能體行為的可信度。
傳統的智能體,通常依賴於手動設定的特定場景下的行為,而生成性智能體,則利用語言模型生成類似人類的響應,後者能反映其記憶中描述的人格特質,並適用於各種情境,因而這種角色扮演會格外逼真。
專家反思,彌補單一思維鏈缺陷
同時,研究者引進了一種「專家反思」,來從訪談記錄中明確推導出關於參與者的高層次、更抽像的見解
這是因為,僅僅將參與者的訪談記錄直接提示語言模型,以單一的思維鏈預測其反應,可能導致模型忽略受訪者未明確表達的潛在信息。
在該模塊中,研究者提示模型對參與者的數據生成反思,但並非僅要求模型從訪談中推導見解,而是要求它採用領域專家的身份。
具體來說,他們要求模型生成四組反思,每次以社會科學四個分支領域的不同專家身份進行:心理學家、行為經濟學家、政治學家和人口統計學家。

每個智能體的記憶包括採訪記錄和專家對該記錄的反思的輸出。這些思考是使用語言模型生成的簡短綜合,用於推斷可能未明確說明的參與者的見解。專家社會科學家(例如心理學家、行為經濟學家)的角色,則會引導這些反思
例如,對於某一訪談記錄,不同專家身份生成了不同的見解:

心理學家會認為,被試者很重視自己的獨立性,喜歡出差,對母親的過度管束感到不滿,對個人自由表現出了強烈渴望。
在行為經濟學家看來,他能夠將財務目標與休閑需求很好地結合起來,追求平衡的生活。
政治科學家看來,他自認是共和黨人,並大力支持該黨派的理念,但同時也兼具兩黨的立場。
人口統計學家的答案則是,他是一名庫存專家,月薪3000到5000美元,家庭月收入7000美元,工作具有一定的穩定性和靈活性。
對於每位被試,研究者都會把ta的訪談記錄提示給GPT-4,並要求它為每位專家生成最多20條觀察或反思,從而生成了四組反思。
這些提示根據每位專家的角色進行了定製。比如針對人口統計學專家的提示示例如下:

想像一下,你是一位人口統計學專家(擁有博士學位),在觀察這次採訪時做了筆記。寫下對受訪者的人口統計特徵和社會地位的觀察/反思。(你的觀察應該多於 5個且少於20個,考慮上述訪談內容的深度,選擇有意義的數字。)
這些反思生成後,就會被保存在智能體的記憶中。
需要預測被試的回答時,研究者會讓語言模型對問題進行分類,判斷哪個專家最適合回答該問題,然後檢索出該專家生成的所有反思。
研究者會將反思附加到參與者的訪談記錄中,並用其作為提示輸入GPT-4,以生成預測回答。
參考資料:
https://arxiv.org/abs/2411.10109
https://x.com/percyliang/status/1858556930626908569