Qwen2.5更新百萬超長上下文,推理速度4.3倍加速,網民:RAG要過時了
國產大模型,最近有點卷。
這不,剛在寫代碼這事情上刷新SOTA,Qwen2.5系列又雙叒突然更新了——
一口氣讀三本《三體》不費事,並且45秒左右就能完整總結出這69萬token的主要內容,be like:
還真不是糊弄事情,「大海撈針」實驗顯示,這個全新的Qwen2.5-Turbo在100萬token上下文中有全綠的表現。
也就是說,這100萬上下文里,有細節Qwen2.5-Turbo是真能100%捕捉到。

沒錯,Qwen2.5系列新成員Qwen2.5-Turbo,這回主打的就是支持超長上下文,並且把性價比捲出了花兒:
上下文長度從128k擴展到1M,相當於100萬個英文單詞或150萬個漢字,也就是10部長篇小說、150小時語音記錄、30000行代碼的量。

更快的推理速度:基於稀疏注意力機制,處理百萬上下文時,首字返回時間從4.9分鐘降低到了68秒,實現了4.3倍加速。

關鍵是還便宜:0.3元/1M tokens。這意味著,在相同成本下,Qwen2.5-Turbo可以處理的token數量是GPT-4o-mini的3.6倍。

看到這波更新,不少網民直接爆出了***:

有人直言:這麼長的上下文這麼快的速度下,RAG已經過時了。
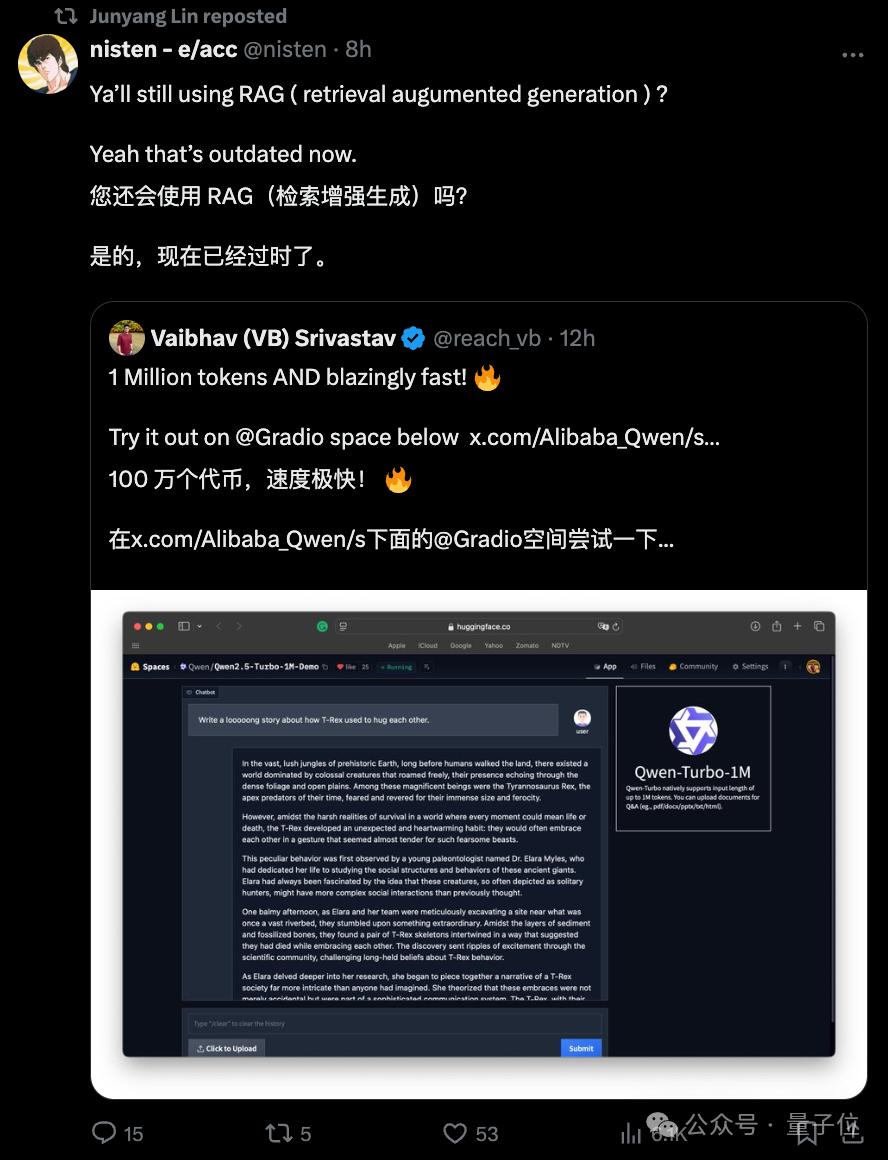
還有人開啟大讚特讚模式:現在在開源領域,Qwen比Llama還值得期待了。
上下文能力擴展不影響性能
除了一口氣啃下3本長篇小說,Qwen官方還展示了Qwen2.5-Turbo超長上下文的更多實用功能。
比如快速掌握一整個代碼庫的信息。
如Demo所演示,上傳包含Qwen-Agent倉庫中所有代碼文件的文本文件(13.3萬token),只需幾秒鍾,大模型就能讀完全部代碼並準確輸出各種細節。
用戶:這個存儲庫中有哪些Agent子類?提供它們的文件路徑。
Qwen2.5-Turbo:

一口氣讀7篇論文,完成論文分類、論文摘要,也不在話下:
我們也實際測試了一下。可以看到,在沒有給任何提示的情況下,Qwen2.5-Turbo能準確掌握不同論文的細節信息,並完成對比數析。

除了大海撈針實驗之外,Qwen團隊還在更複雜的長文本任務上測試了Qwen2.5-Turbo的能力。
包括:
RULER:基於大海撈針的擴展基準,任務包括在無關上下文中查找多「針」或回答多個問題,或找到上下文中出現最多或最少的詞。數據的上下文長度最長為128K。
LV-Eval:要求同時理解眾多證據片段的基準測試。Qwen團隊對LV-Eval原始版本中的評估指標進行了調整,避免因為過於嚴苛的匹配規則所導致的假陰性結果。數據的上下文長度最長為128K。
Longbench-Chat:一個評價長文本任務中人類偏好對齊的數據集。數據的上下文長度最長為100K。

結果顯示,在RULER基準測試中,Qwen2.5-Turbo取得了93.1分,超過了GPT-4o-mini和GPT-4。
在LV-Eval、LongBench-Chat等更接近真實情況的長文本任務中,Qwen2.5-Turbo在多數維度上超越了GPT-4o-mini,並且能夠進一步擴展到超過128 tokens上下文的問題上。
值得一提的是,現有的上下文長度擴展方案經常會導致模型在處理短文本時出現比較明顯的性能下降。
Qwen團隊也在短文本任務上對Qwen2.5-Turbo進行了測試。

結果顯示,Qwen2.5-Turbo在大部分任務上顯著超越了其他上下文長度為1M tokens的開源模型。
和GPT-4o-mini以及Qwen2.5-14B-Instruct相比,Qwen2.5-Turbo在短文本任務上的能力並不遜色,但同時能hold住8倍於前兩個模型的上下文。
此外,在推理速度方面,利用稀疏注意力機制,Qwen2.5-Turbo將注意力部分的計算量壓縮到了原來的2/25,在不同硬件配置下實現了3.2-4.3倍的加速比。

現在,在HuggingFace和魔搭社區,Qwen2.5-Turbo均提供了可以在線體驗的Demo。
API服務也已上線阿里雲大模型服務平台,跟OpenAI API是兼容的。

至於模型權重什麼時候開源?
阿裡通義開源負責人林俊暘的說法是:目前還沒有開源計劃,但正在努力中。

反正HuggingFace聯合創始人Thomas Wolf是幫咱催上了(手動狗頭)。
參考鏈接:https://qwenlm.github.io/zh/blog/qwen2.5-turbo/
本文來自微信公眾號「量子位」,作者:關注前沿科技,36氪經授權發佈。