多樣任務真實數據,大模型在線購物基準Shopping MMLU開源|NeurIPS&KDD Cup 2024
港科大博士金逸倫 投稿
量子位 | 公眾號 QbitAI
誰是在線購物領域最強大模型?也有評測基準了。
基於真實在線購物數據,電商巨頭亞馬遜終於「亮劍」——
聯合香港科技大學、聖母大學構建了一個大規模、多任務評測基準Shopping MMLU,用以評估大語言模型在在線購物領域的能力與潛力。

一直以來,想要完整建模在線購物相當複雜,主要痛點是:
-
多任務性:在線購物中存在多樣的實體(例如商品、屬性、評論、查詢關鍵詞等)、關係(例如關鍵字和商品的匹配度,商品和商品之間的兼容性、互補性)和用戶行為(瀏覽、查詢、和購買)。
對這些實體、關係和行為和聯合建模與理解構成一個複雜的多任務(multi-task)學習問題。
-
少樣本性:在線購物平台會不斷面臨新用戶、新商品、新商品品類等帶來的冷啟動(cold-start)場景。在冷啟動場景下,在線購物平台需要解決少樣本(few-shot)學習問題。
不過,諸如GPT,T5,LLaMA等的大語言模型(LLM)已經展現出了強大的多任務和少樣本學習能力,因而有潛力在在線購物領域中得到廣泛應用。
而為了進一步找出最強、最具潛力的LLM,測試基準Shopping MMLU應運而生——
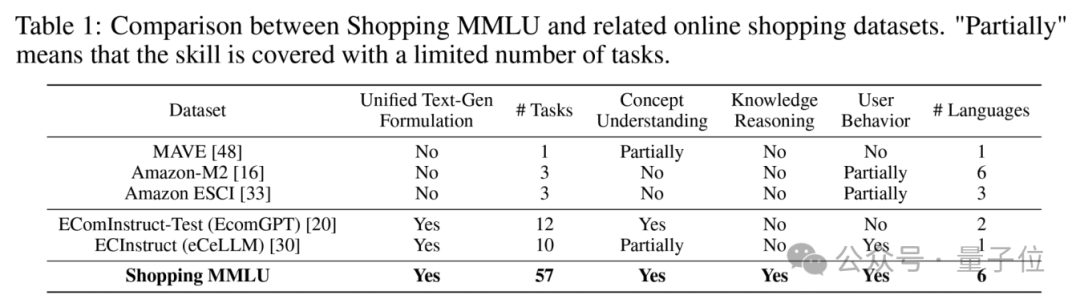
與現有數據集相比,Shopping MMLU覆蓋了更多的能力(四項)和任務(57個)。
同時,基於Shopping MMLU,亞馬遜舉辦了KDD Cup 2024數據挖掘競賽,吸引了全球超過500支隊伍參賽。

廣泛的能力和任務覆蓋
為了全面、充分評估大語言模型在在線購物領域中的能力,研究首先分析了在線購物領域的獨特性:
-
特定領域的短文本:在線購物中存在大量的特定領域名詞,例如品牌、產品名、產品線等。此外,這些特定領域名詞往往出現於短文本中,例如查詢關鍵詞、屬性名-值對等。因此,在缺乏上下文的短文本中理解特定領域名詞,是在線購物領域的一個獨特挑戰。
-
商品的隱含知識:大部分商品都隱含特定的知識,例如AirPods使用藍牙連接,不需要轉接線;碳纖維製品一般重量很輕等。如何準確理解不同商品隱含的知識並且進行推理,是在線購物領域的另一個獨特挑戰。
-
異質且隱式的用戶行為:在線購物平台上存在多種多樣的用戶行為,例如瀏覽、查詢、加購物車、購買等。這些行為大部分都不以語言表達,因此如何全面理解這些異質的用戶行為,是在線購物所必須解決的問題。
-
多語言任務:在線購物平台往往在不止一個地區運營,因此需要模型能同時理解多種語言描述下的商品和用戶問題。
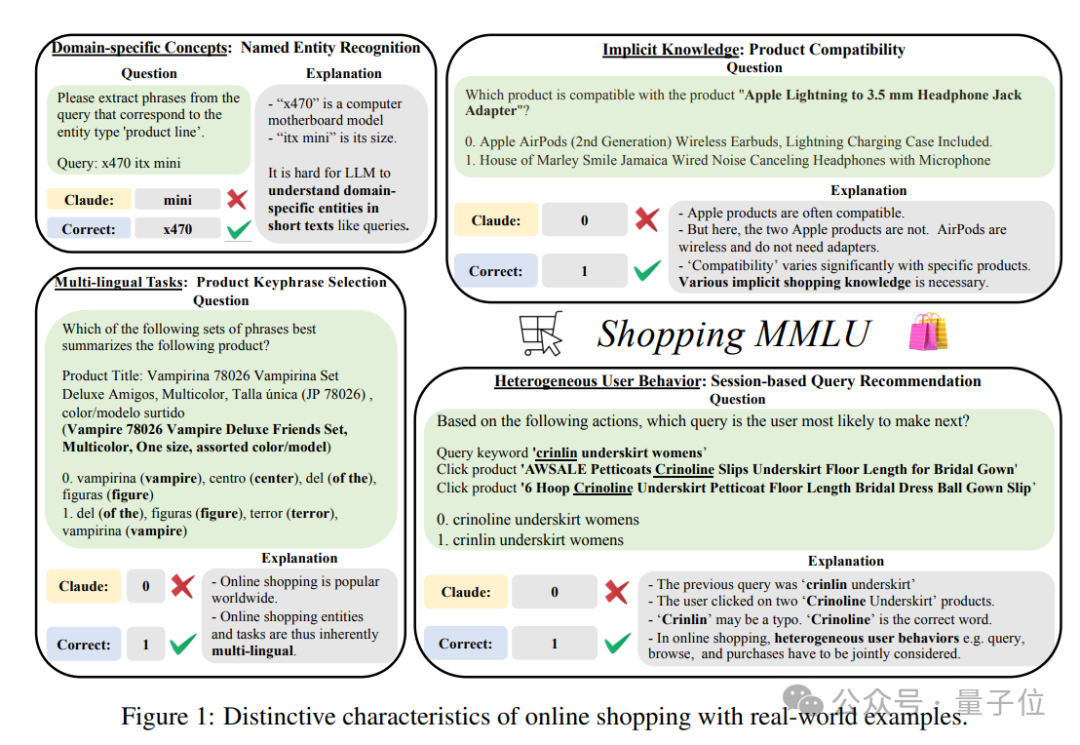
基於以上分析,研究構造了Shopping MMLU,覆蓋四項在線購物能力,共計57個任務:
-
在線購物概念理解
-
在線購物知識推理
-
用戶行為理解
-
多語言能力
下表可見,Shopping MMLU相比現有數據集覆蓋了更多的能力和任務。
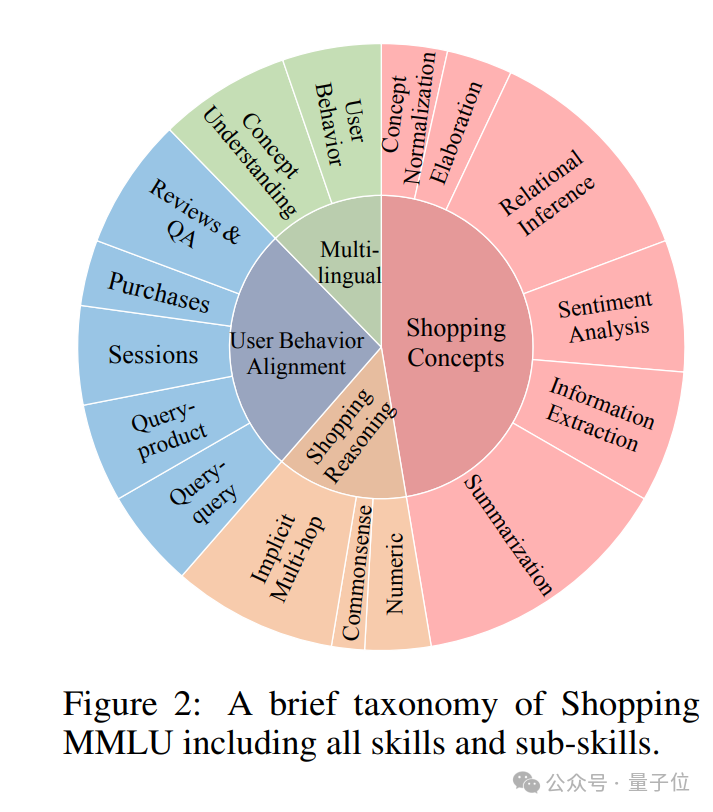
能力和任務構成如下圖所示。
Shopping MMLU大部分由真實的亞馬遜在線購物數據構造,並且經過人工檢驗,儘可能排除低質量數據,例如標註錯誤,缺乏必要信息等。
部分問題示例如下。



主流大語言模型成績單
研究選取了共27個主流大語言模型進行實驗分析,其中包括:
-
閉源模型(Claude-3, Claude-2, GPT)
-
開源通用領域模型(LLaMA2、LLaMA3、QWen、Mistral)
-
開源特定領域模型(eCeLLM,經過在線購物領域數據進行微調)
實驗結果如下表所示。

研究發現,雖然閉源模型仍然處於領先(例如Claude-3 Sonnet整體排名第一),但開源模型已經能夠趕上閉源模型的性能(例如QWen和LLaMA3)。
此外,特定領域模型eCeLLM並未在同參數量級下取得最好成績,說明Shopping MMLU是一個有相當難度的評測基準,無法通過簡單的微調取得好成績。
如何打造在線購物領域大模型
基於Shopping MMLU,研究分析常用的大模型增強手段,進一步探究如何打造強大的在線購物領域大模型。
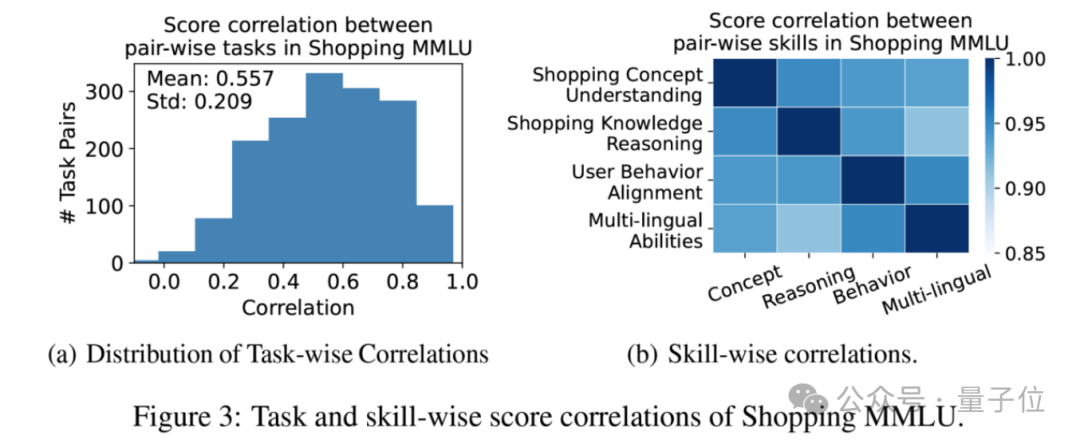
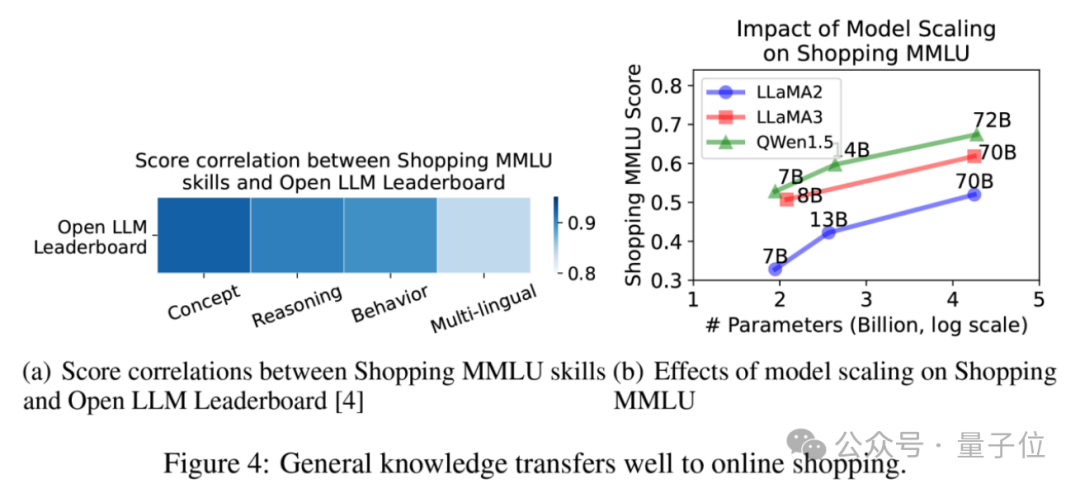
首先,如下圖所示,模型在不同能力和任務上的得分高度正相關。這說明了在線購物領域的不同任務之間存在共同的知識,可以使用大語言模型進行整體性的建模和能力提升。
其次,如下圖所示,模型的Shopping MMLU得分和模型在通用大模型基準測試的得分(Open LLM Leaderboard)同樣高度相關。
另外,隨著同一個模型家族內模型增大,其Shopping MMLU得分同樣增加。
這表明大語言模型的通用能力可以很好地遷移到在線購物領域中,構造特定領域大模型的基礎是強大的通用能力。
隨後,研究分析了微調對模型在Shopping MMLU得分的影響。
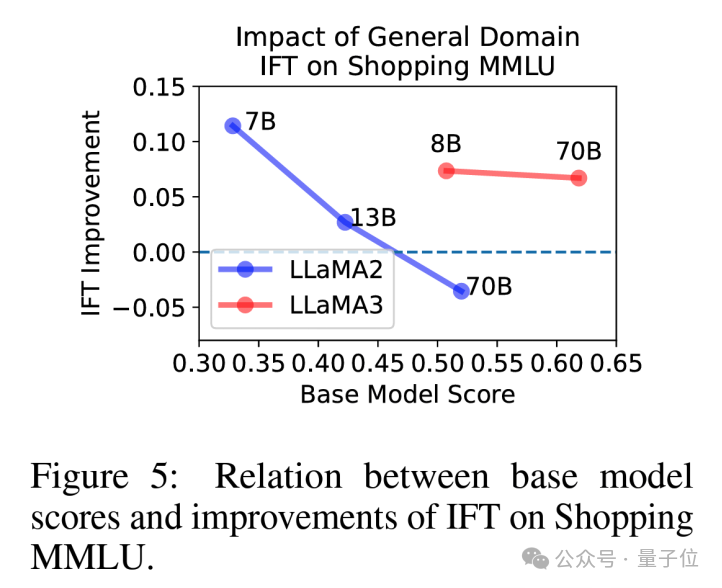
通用領域的微調一般對模型在Shopping MMLU上有提升。不過,這一結論也與基礎模型的能力,微調的數據質量等因素存在關係。
例如,在LLaMA2-70B上,研究觀察到經過微調的LLaMA2-70B-chat得分低於LLaMA2-70B,而在LLaMA3-70B上沒有觀察到這一現象。
可能的原因是,相對較小的微調數據使得LLaMA2-70B過擬合,導致通用能力的部分丟失,進而導致Shopping MMLU上得分下降。
反之,LLaMA3使用了更高質量的微調數據,所以能夠保留通用能力,同時增強模型回答問題的能力,得到更高的分數。
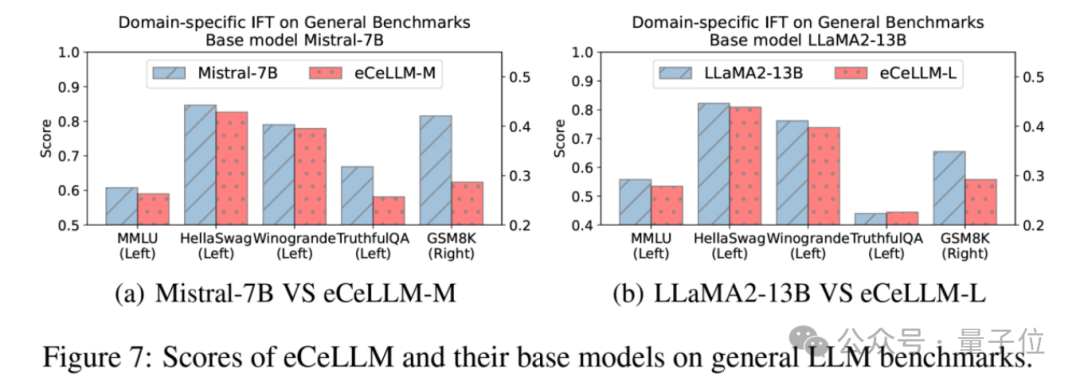
特定領域微調(如eCeLLM)並未能在Shopping MMLU上取得最高得分。
為了探究其中原因,研究測試了eCeLLM與其基礎模型在通用能力上的對比。結果表明,經過特定領域微調的eCeLLM相比其基礎模型的通用能力一般有所下降。
這可能是導致eCeLLM未能取得最高得分的原因,也同時強調了通用能力對於對特定領域的重要性。
總結
Shopping MMLU是一個針對大語言模型和在線購物領域設計的評測指標。其包含廣泛的任務和能力覆蓋(4項重要能力,共計57個任務),可以全面評估大語言模型在在線購物領域的能力和潛力。
Shopping MMLU基於亞馬遜的真實購物數據打造,經過人工篩選,保證數據質量。基於Shopping MMLU,研究展開了大量實驗分析,為這一領域後續的研究和實際應用提供了有價值的結論。
目前,Shopping MMLU以及其對應的資源全部開源並將持續維護,方便研究人員和開發者進行深入探索和應用。
Shopping MMLU的數據以及對應評測代碼已經於GitHub公開。
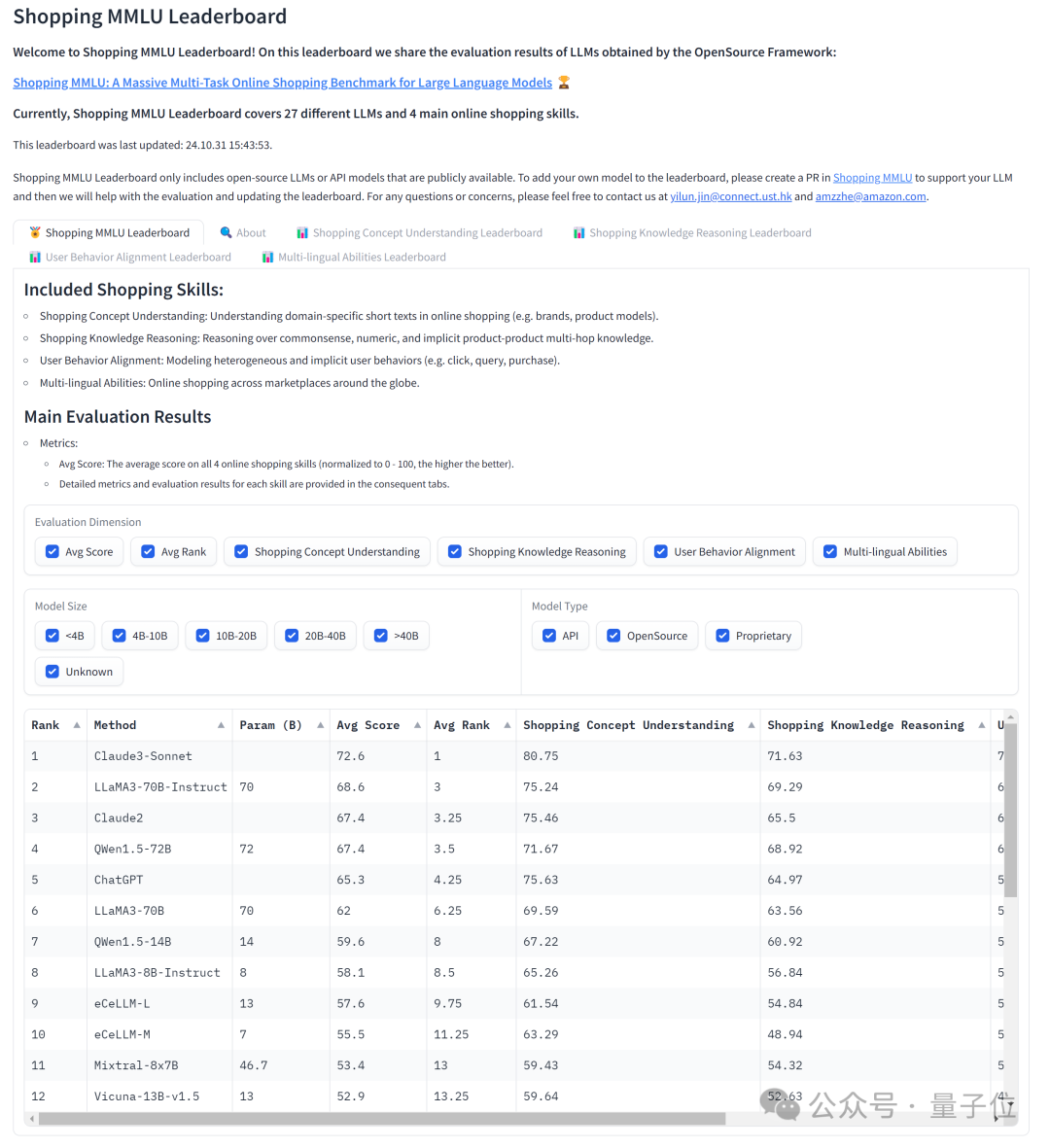
同時,為了構造開放、開源的評測體系,研究基於Shopping MMLU建立了一個排行榜。
官方表示,Shopping MMLU歡迎新模型加入排行榜,如果有興趣的話可以於GitHub上與Shopping MMLU維護者進行聯繫。
論文:
https://arxiv.org/pdf/2410.20745
數據及評測代碼:
https://github.com/KL4805/ShoppingMMLU
KDD Cup 2024 Workshop及獲獎隊伍解法:
https://amazon-kddcup24.github.io/
評估榜單:
https://huggingface.co/spaces/KL4805/shopping_mmlu_leaderboard