OpenAI最強競對Anthropic:正確的大模型評測應該是怎樣的?
人工智能(AI)大模型的客觀評測,有助於推動大模型行業的健康發展。然而,當前業內的基準測試(benchmark)層出不窮,充斥著各種評測亂象。
更值得深思的是,當一個模型在某個基準測試上的表現優於另一個模型時,這究竟是反映了模型間的真實的差異,還是僅僅因為選擇了特定的問題而「運氣好」?
從根本上說,評測就是實驗,但有關評測的研究在很大程度上忽視了其他科學中有關實驗分析和規劃的研究,業內缺乏對這一問題的深入研究。
今日淩晨,OpenAI 最強競對、知名大模型初創公司 Anthropic 在其最新博客中試圖回答這一問題。他們通過借鑒統計理論和其他科學中實驗分析和規劃的研究,向人工智能行業提出了一些建議,以便以科學的方式報告語言模型評測結果,最大限度地減少統計噪聲,增加真實信息量。
相關研究論文也於前幾日以「Adding Error Bars to Evals: A Statistical Approach to Language Model Evaluations」為題發表在了預印本網站 arXiv 上。

論文鏈接:https://arxiv.org/abs/2411.00640
建議 1:使用中心極限定理
評測通常由數百或數千個不相關的問題組成。例如,MMLU(測量大規模多任務語言理解能力)會包含各種各樣的問題,比如:
-
誰發現了第一個病毒?
-
()=4−5 的倒數是多少?
-
「法理學是法律的眼睛」是誰說的?
要計算總體評測分數,需要對每個問題單獨評分,然後總體分數(通常)是這些問題分數的簡單平均值。
通常,研究人員將注意力集中在這個觀察到的平均值上。但 Anthropic 認為,真正感興趣的對象不應該是「觀察到」的平均值,而是所有可能問題的「理論」平均值。
因此,如果將評測問題想像成是從一個看不見的「問題世界」中抽取的,那麼就可以瞭解該世界的平均分數——也就是說,可以使用統計理論來衡量潛在的「技能」,而不受「全憑運氣」的影響。
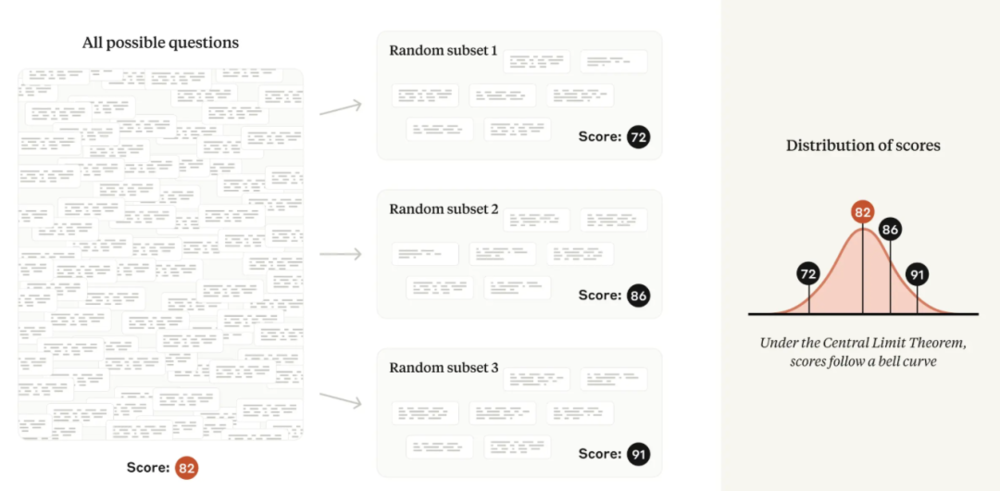
圖|若想像評測問題來自「問題世界」,那麼評估分數將趨向於遵循正態分佈,以所有可能問題的平均分數為中心。
這種公式帶來了分析魯棒性:如果要創建一個新的評測,其問題具有與原始評測相同的難度分佈,那麼通常應該期望原來的結論能夠成立。
用技術術語來說:在中心極限定理的相對溫和條件下,從同一基礎分佈中抽取的幾個隨機樣本的平均值將趨向於遵循正態分佈。該正態分佈的標準差(或寬度)通常稱為平均值的標準誤差,或 SEM。
在論文中,他們鼓勵研究人員報告從中心極限定理得出的 SEM,以及每個計算出的評估分數——他們向研究人員展示如何使用 SEM 量化兩個模型之間的理論平均值差異。通過在平均分數上加減 1.96 × SEM,可以從 SEM 計算出 95% 的置信區間。
建議 2:聚類標準誤差
許多評測違反了上述獨立選擇問題的假設,而是由一組密切相關的問題組成。例如,閱讀理解評測中的幾個問題可能會詢問同一段文字。遵循這種模式的主流評測包括 DROP、QuAC、RACE 和 SQuAD。
對於這些評測,每個問題從「問題範圍」中選擇的內容不再是獨立的。因為包含關於同一段文本的幾個問題所產生的信息量要比選擇相同數量關於不同段落文本的問題所產生的信息量少,所以將中心極限定理簡單應用於非獨立問題的情況會導致低估標準誤差,並可能誤導分析師從數據中得出錯誤的結論。
幸運的是,聚類標準誤差問題在社會科學中得到了廣泛的研究。當問題的納入不獨立時,研究建議以隨機化單位(例如,文本段落)對標準誤差進行聚類,並在論文中提供了適用的公式。
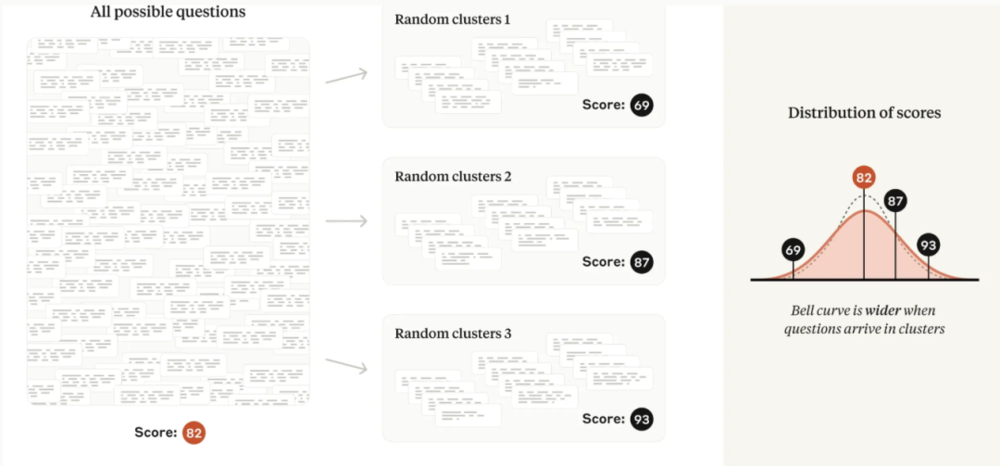 圖|如果問題出現在相關的集群中(閱讀理解評測中的常見模式),那麼與非集群情況相比,評估分數將更加分散。
圖|如果問題出現在相關的集群中(閱讀理解評測中的常見模式),那麼與非集群情況相比,評估分數將更加分散。研究發現,在實踐中流行評測的聚類標準誤差可能是簡單標準誤差的三倍以上。忽略問題聚類可能會導致研究人員無意中發現模型能力的差異,而實際上並不存在差異。
建議 3:減少問題內的差異
方差是衡量隨機變量分散程度的指標。評測分數的方差是上文討論的平均值標準誤差的平方;該量取決於每個評測問題的分數方差量。
研究中一個關鍵見解是將模型在特定問題上的得分分解為兩個相加的項:
-
平均分數(如果無數次詢問相同的問題,模型將獲得的平均分數 – 即使模型每次可能會給出不同的答案);
-
隨機成分(實際問題分數與該問題的平均分數之間的差異)。
根據總方差定律,減少隨機份量的方差會直接導致整體平均值的標準誤差更小,從而提高統計精度。研究重點介紹了兩種減少隨機份量方差的策略,具體取決於是否要求模型在回答之前逐步思考(即 CoT 或思維鏈推理的提示技術)。
如果評測使用思維鏈推理,他們建議多次從同一模型中重新采樣答案,並使用問題級平均值作為輸入到中心極限定理的問題分數。他們注意到,Inspect 框架通過其 epochs 參數以這種方式正確計算標準誤差。
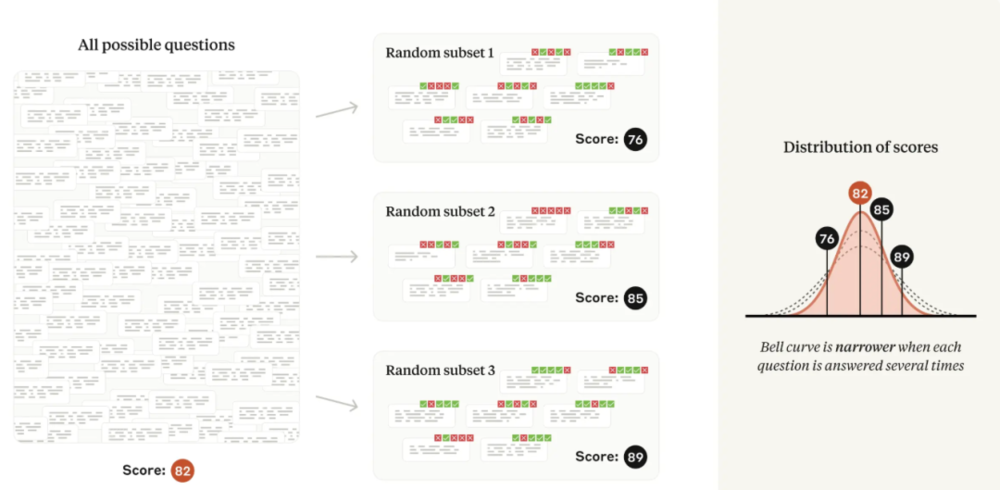 圖|如果模型產生的答案具有不確定性,那麼每個問題生成(和評分)多個答案將導致評測分數分散。
圖|如果模型產生的答案具有不確定性,那麼每個問題生成(和評分)多個答案將導致評測分數分散。如果評測不使用思維鏈推理(即其答案不是「路徑依賴」),那麼分數中的隨機成分通常可以使用語言模型中的 next-token 概率完全消除。例如,如果多項選擇題的正確答案是「B」,那麼只需使用模型生成 token「B」的概率作為問題分數。研究團隊表示不知道目前有哪個開源評測框架實現了這種技術。
建議 4:分析配對差異
評測分數本身沒有任何意義;它們只有在相互關聯時才有意義(一個模型優於另一個模型,或與另一個模型能力相當,或超過某一個人)。
但是,兩個模型之間測量到的差異可能是由於評測中問題的特定選擇以及模型答案的隨機性造成的嗎?可以通過雙樣本 t-test 來找出答案,僅使用從兩個評測分數計算出的平均值的標準誤差。
然而,雙樣本檢驗忽略了評測數據中的隱藏結構。由於問題列表在模型之間共享,因此進行配對差異檢驗可以消除問題難度的差異,並專注於答案的差異。
研究中展示了配對差異檢驗的結果與兩個模型的問題分數之間的皮爾遜相關係數之間的關係,相關係數越高,平均差異的標準誤差就越小。
研究發現,在實踐中,前沿模型之間主流評測中問題得分的相關性相當高——在 -1 到 +1 的範圍內介於 0.3 和 0.7 之間。換句話說,前沿模型總體上傾向於對同樣的問題做出正確和錯誤的回答。
由此可知,配對差異分析代表了一種非常適合 AI 模型評測的「自由」方差減少技術。因此,為了從數據中提取最清晰的信號,研究建議在比較兩個或多個模型時報告配對信息——平均差、標準誤差、置信區間和相關性。
建議 5:使用效力分析
統計顯著性的另一面是統計效力,即統計檢驗檢測出兩個模型之間差異的能力(假設存在這種差異)。如果評測中沒有太多問題,則與任何統計檢驗相關的置信區間都會很寬。這意味著模型需要具有很大的潛在能力差異才能記錄具有統計顯著性的結果,而微小的差異很可能不會被發現。
效力分析是指觀察計數、統計功效、假陽率和感興趣的效應大小之間的數學關係。
研究展示了如何將效力分析的概念應用於評測。具體來說,他們向研究人員展示了如何製定假設(例如模型 A 的表現比模型 B 高出 3 個百分點)並計算評測應包含的問題數量,以便根據零假設檢驗該假設(例如模型 A 和模型 B 是和波)。
他們相信效力分析在很多情況下都會對研究人員有所幫助。他們的效力公式將告知模型評估人員重新抽樣問題答案的次數(參見上面的建議 3),以及在保留所需效力特性的同時可包含在隨機子樣本中的問題數量。
研究人員可能會使用效力公式得出結論,在特定模型對上運行具有有限數量可用問題的評測是不值得的。新評測的開發人員可能希望使用該公式來幫助決定要包含多少問題。
結論
統計學是在噪聲環境下進行測量的科學。評測提出了許多實際挑戰,而真正的評測科學仍未得到充分發展。統計學只能構成評測科學的一個方面,但卻是至關重要的一個方面,因為經驗科學的好壞取決於其測量工具。
Anthropic 希望,論文中提出的建議將幫助人工智能研究人員比以前更精確、更清晰地計算、解釋和傳達評測數字,並且鼓勵他們探索實驗設計中的其他技術,以便能夠更準確地理解他們想要測量的所有內容。
本文來自微信公眾號:學術頭條,整理:阮文韻



















