數據洪流已至,AI如何助力神經影像學研究?
文 | 追問nextquestion
在過去十年中,神經影像學已迅速發展為一個數據密集型的「大數據」學科。隨著數據共享的普及,研究者們現在能夠訪問規模空前的神經影像數據。僅在2020年5月至2021年4月間,OpenNeuro平台上就增加了406TB的數據[1]。
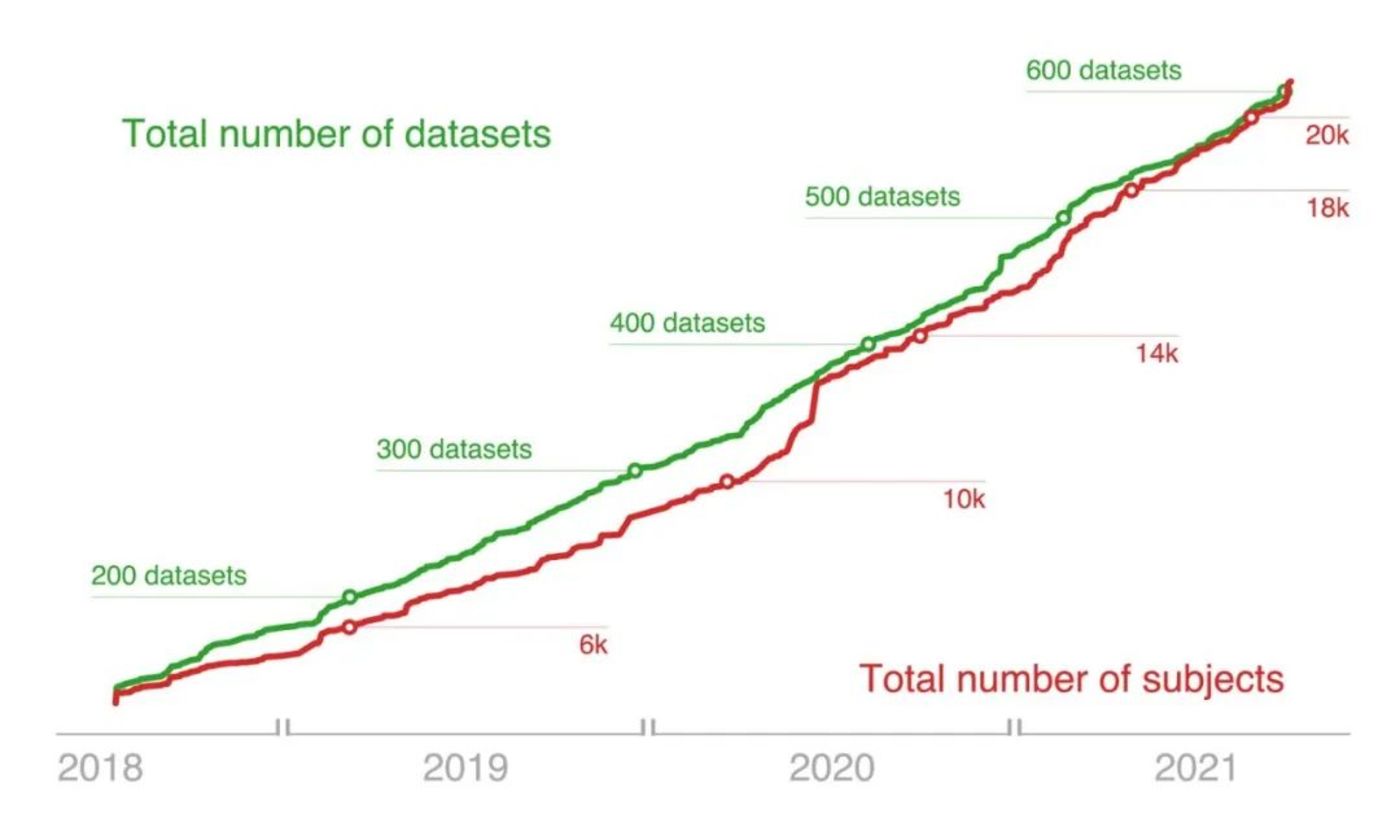
▷2018年~2021年OpenNeuro平台上的可用數據集(綠)與被試(紅)數量穩步增長。圖源:The OpenNeuro resource for sharing of neuroscience data. eLife, 10, e71774. https://doi.org/10.7554/eLife.71774
數據體量的增長,既帶來了重要機遇,也伴隨生出諸多新問題。在當前環境下,研究者們愈發意識到加強數據科學與統計學訓練的必要性。儘管已經出現了如Brainhack等開放科學社區以及NeuroMatch Academy等教學項目,但要應對這些挑戰,卻還遠遠不夠。
針對這一現狀,近年來出現的生成式AI(generative AI),或許有望徹底改變神經影像學研究範式。
▷Elizabeth DuPre, Russell Alan Poldrack; The future of data analysis is now: Integrating generative AI in neuroimaging methods development. Imaging Neuroscience 2024; 2 1–8. doi: https://doi.org/10.1162/imag_a_00241
01 生成式AI與神經影像學
生成式AI結合生成模型與深度神經網絡,能夠根據文本或圖像提示生成新的文本、圖像和音頻。生成式AI的實際應用中,尤其是AI輔助編程被認為可以提高開發者的生產力,減少低級細節問題,節省大量時間,帶來更愉悅的編程體驗。
生成式AI將如何改變腦影像研究?我們可以以史為鑒,從數據科學的發展中一窺究竟。
1962年,約翰·圖基(John Tukey)在《數據分析的未來》一書中呼籲創建一種系統化科學數據分析方法——數據科學[2],他特別強調對自動化、標準化統計程序的開發,以代替對個別研究者的專業知識的依賴。他警告人們:
隨著數據量的增加,大部分的數據分析工作,將由缺乏經驗而時間有限的人力來完成;而如果未能為這些人提供相應的工具,則會有更多數據未經分析。
 ▷約翰·圖基(John Tukey),圖源:APS
▷約翰·圖基(John Tukey),圖源:APS而這也正是神經影像學面臨的困境——由於缺乏專業的數據科學訓練,分析方法在實驗室之間,甚至實驗室之內,都存在差異。
對此,研究者們開發了BIDS(Brain Imaging Data Structure)等數據標準以及Nipreps等生態系統,在一定程度上填補了這些空白。Nipreps基於AFNI、FSL等軟件,在常見的功能性磁共振成像(fMRI)的預處理方法上實現了自動化。
Nipreps生態系統突顯了神經影像學方法開發的兩大核心問題:
-
在尚未實現標準化的領域(如影像質量控制),需要繼續推動分析方法的標準化;
-
在預處理後的數據分析階段,分析方法的選擇往往取決於特定的研究問題和任務設計,該過程需要實現自動化。
生成式AI,具有解決這兩大難題的巨大潛力。「神經AI」(NeuroAI)等方法有望對神經科學的方法論和理論基礎產生巨大影響。僅就方法論而言,AI可能為神經科學帶來重大變革;然而,AI也可能引發新的問題——如果研究者對其認識不足,它可能反而會阻礙領域的發展。
02 生成式AI與影像質控
圖基強烈主張將現有的統計方法自動化。然而,這在神經影像學中卻很難推進。一些實驗方法尚未統一明確量化指標,不同研究者有各自側重的指標,因而難以實現自動化。
以生成實驗刺激圖片為例,雖然像MidJourney和StableDiffusion等生成式AI能夠輕鬆生成多種圖像,但問題在於——研究人員須在有限的實驗時間內選擇優先考慮哪些圖像。這體現了神經影像學方法自動化的複雜性:即便有了先進的AI工具,研究人員的判斷仍然至關重要。
另一個更明顯的例子,在影像質控時,人工檢驗仍然是金標準。在不同的科學問題中,使用的質控方法不同。即便是人工檢驗,不同專家的質控打分也可能有所不同。而即便存在不確定性,鑒於有待檢驗的數據量巨大,學界必須著手研發無需依賴參考圖像的質控指標,以指導人工檢查及後續的機器學習。
雖然存在這些挑戰,但我們仍有理由保持樂觀。在神經影像預處理方面,NoBrainer和FastSurfer等方法,已經實現在保持高質量輸出的前提下,利用AI大幅減少了圖像分割等圖像任務的計算時間。AI在神經影像數據處理中表現出巨大潛力。然而,現有的這些工具的廣泛驗證是基於大量公開可用的有標註數據集進行的;而到目前為止,研究者仍難以獲取大型有標註數據集以用於驗證質控結果。
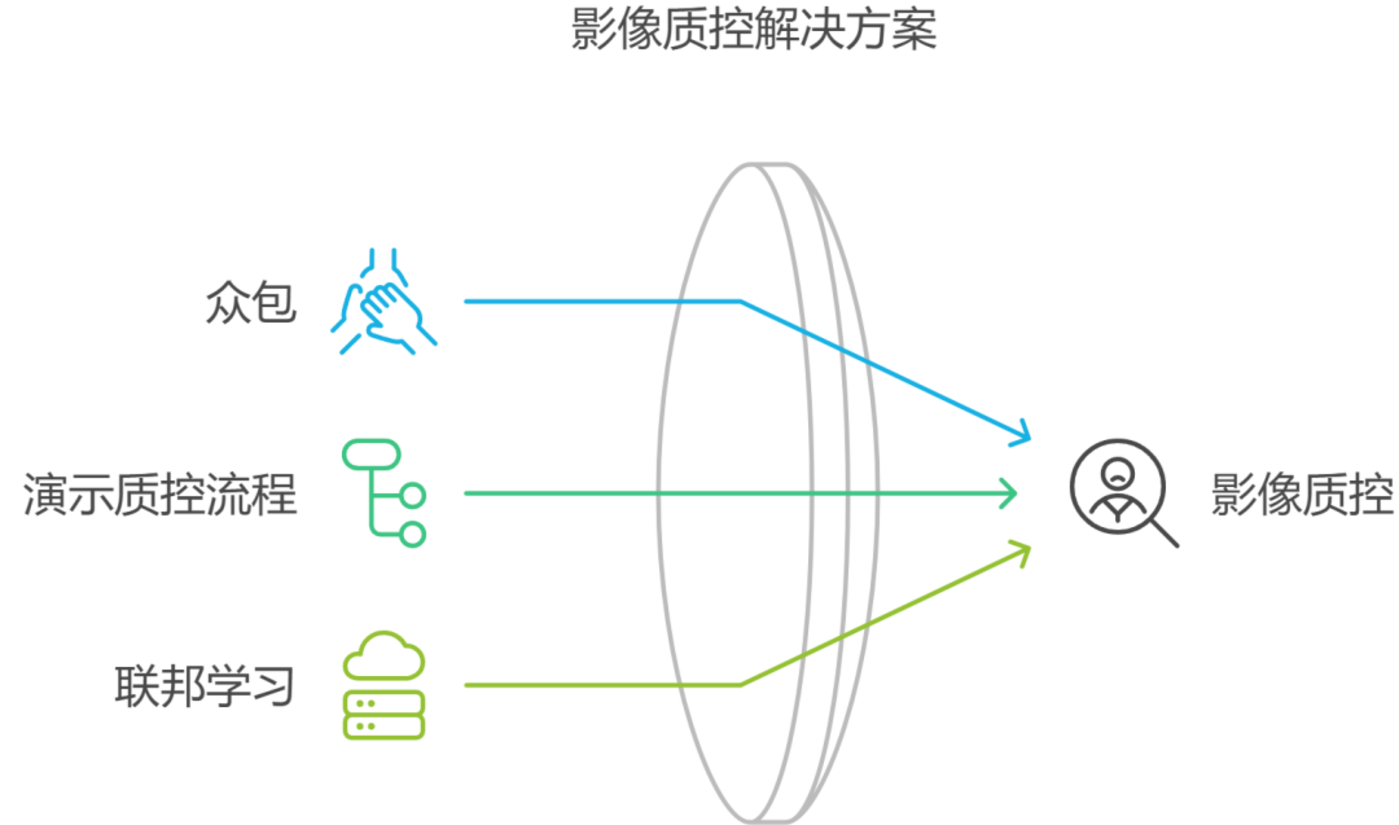
通過眾包來增補現有的質控標註,是一種潛在的解決方案。Swipes for Science、Brainmatch等項目已經成功地利用分佈式公民眾包科研,生成了大量質控標籤。雖然這些方法潛力巨大,但AI的日益普及卻使它們的可靠性遭到質疑。越來越多的眾包正在使用ChatGPT等工具來完成任務,尤其是允許自由輸入文本的任務。如果用這些AI生成的內容來訓練模型,可能會造成「模型崩潰」。
近來,質控流程演示(Demonstrating Quality Control Procedures)等諸多項目,已逐漸轉為關註標簽生成任務本身。由此生成的質控流程,可能反過來對未來的AI應用至關重要。例如,生成式AI可通過增加特定標籤的可用數據(例如「環狀偽影」),來評估評分者之間的一致性。然而,其中一些質控程序和標籤可能只適合特定人群,例如,用於卒中患者劃分病灶區域的方法,並不適用於健康人群。在這種情況下,有限的數據量和隱私問題可能有礙於大規模的數據標註的實現。
聯邦學習(Federated Learning)等其他算法,則提供了另外一種思路——通過模型共享而非數據共享的方式來訓練聯合模型。類似地,神經影像基礎模型(Neuroimaging Foundation Models)或可實現將經過預訓練的數據密集型模型遷移到小而專的數據集上。但是,重點是,這些範式都需要對數據進行嚴格的標準化處理,以確保模型能遷移到不同的應用環境中。
03 AI輔助編程在神經影像分析中的具體應用
在神經影像分析環節,統計方法的自動化也難以推進。
部分原因在於,分析方法的多樣性。二十多年來,一階和二階廣義線性模型,一直是fMRI分析的基石;然而直到近幾年,才出現專門將這些常見分析整合在標準格式中的工具(例如 FitLins)。沒有標準化且可機讀的輸入和輸出結構,便難以通過AI或其他工具實現自動化。
標準化的廣義線性模型算法仍在開發中,其他較新的方法也大多沒有實現標準化。在這種情況下,研究人員需要確保他們的代碼正確執行所需的分析。對於代碼基礎薄弱的研究者而言,這可能會阻礙他們探究某些科學問題,或使其得出錯誤的結論。
在這些場景中,AI輔助編程是一個頗具吸引力的解決辦法,可以像「催化劑」一樣加速研究進程。
當然,AI輔助編程也不是完美的,它只是將負擔從「代碼編寫」轉移到了「代碼審閱與測試」。用AI生成的代碼進行測試,如果產生陰性結果,是測試的問題還是代碼的問題?代碼的輸入和輸出是否合理?這些問題仍然需要熟悉編程的研究人員來解決。
另外,雖然AI輔助編程可用於某些分析場景,如編寫大項目中的單個簡單函數;但如若將其擴展到神經影像分析的全流程,出錯的可能性也將大大增多。研究人者缺乏單一的度量標準來對結果進行基準測試,因此很難區分AI生成的代碼是在產生有意義的差異,還是引入難以發現的錯誤。
對此,如果能獲取已有結果背後的數據和代碼,則可進一步驗證生成的代碼:
-
「在AI的幫助下,可否將已有的代碼遷移到新數據上?」
-
「如果在原始數據上運行生成的代碼,產生的結果是否和原始結果相似?」
這可為已有結果的魯棒性和可重覆性提供參考,同時也能確認新的代碼能夠複現相應的分析。但是,這也有賴於已有實驗的數據和代碼是否開源。
04 AI輔助工具與開放科學之間的關係
過去十年間,開放科學已成為神經影像學方法研發的關鍵驅動力,大量的研究致力於將常見的分析流程標準化。開放科學實踐與AI輔助工具相輔相成。
那麼,AI輔助工具將如何影響開放科學及其在神經影像方法開發中的應用?換言之,當數據和代碼可以通過簡單的命令生成時,AI輔助工具是否會減少數據共享和代碼開源等開放科學做法?
其他領域的證據表明,情況恰恰相反。近期,數據科學領域的領軍人物David Donoho提出,AI的商業化成功反映了經驗機器學習中深厚的數據科學文化。他不僅倡導代碼開源和數據共享,還倡導通過公開的預測挑戰等明確的方法來比較各種分析方法。
儘管預測挑戰在神經影像學中難以成功,但這種通過明確的指標評判結果的理念,對於充分利用生成式AI研發神經影像學方法而言至關重要。如果沒有明確的結果指標,就需要強大的人在閉環(human-in-the-loop systems)來審核AI應用,這與圖基倡導的自動化分析相悖。因此,要想在腦影像領域推廣生成式AI,首先要在標準化上下功夫。令人鼓舞的是,質控流程演示(Demonstrating Quality Control Procedures)等項目,正致力於將模糊的評判標準標準化。
儘管如此,還有大量工作仍有待完成,其中包括如何使影像分析結果符合「可發現、可訪問、可互操作、可重覆使用」的標準,以便接受其他研究者的客觀評估。雖然生成式AI或能推動這一進程(如開發新的人工標籤示例等),但進一步的進展仍有賴於人類主導的標準化進程。
因此,從目前學界全力研發自動化分析方法的趨勢來看,生成式AI短期內不會取代現有的開放科學項目。相反,它將要求研究人員將數據和代碼公開,還要提供明確的結果,以便在實驗之間相互比較。
神經影像分析複現與預測研究(Neuroimaging Analysis Replication and Prediction Study)表明,不同的研究團隊在同樣的數據上開展相同的分析,其結果可能會相去甚遠(但該研究卻並未提供一個清晰的框架用以比較各個團隊的結果)[2]
多元宇宙樣分析(Multiverse Analysis)或更通用的「振動」分析(「Vibration」 Analysis),或能校正給定實驗可能的結果範圍。理想情況下,這些校正分析可以指導生成公開的評判指標。然而,目前仍然需要繼續推進代碼和數據公開,以便開展這些校準分析。這將有助於推廣新興的AI輔助方法。
05 結語
作為數據密集型領域,神經影像學有賴於數據科學以取得方法上的創新。然而,目前大多數研究人員缺乏必要的數據科學訓練。生成式AI工具或有助於填補這一缺口,但在此過程中,它需要與現有的神經影像學方法研發體系相互配合,包括數據與代碼共享等開放科學理念。本文認為,AI工具的出現不會取代開放科學,反而會凸顯其重要性。
但這也並不意味著開放科學與基於生成式AI方法之間完美協調。例如,歐盟通用數據保護條例(The European Union’s General Data Protection Regulations)認定去除面部的腦影像為隱私數據;而在包括美國在內的多數國家,未經匿名化處理的腦影像也被視為隱私數據。因此,將腦影像直接發送給生成式AI工具,在多數情況下並不符合倫理標準。
AI和開放科學的其他交互則更難釐清利弊。例如,AI輔助編程將大幅度降低編程門檻,使研究人員更容易參與到研究軟件工程師社群(Research Software Engineers)等開放科學項目之中,共同開發新的方法。但由於這些項目受到的資助有限,以及開發者用以審閱代碼和維護項目的時間有限,AI輕易生成的代碼可能會帶來新的問題。
總的來說,為了利用好AI,我們需要回歸數據科學的核心原理。尤其是要開發明確的評價指標以比較不同研究的結果,這將有望整體促進AI輔助工具的應用和神經影像學方法的發展。
參考文獻
[1] Markiewicz, C. J., Gorgolewski, K. J., Feingold, F., Blair, R., Halchenko, Y. O., Miller, E., Hardcastle, N., Wexler, J., Esteban, O., Goncavles, M., Jwa, A., & Poldrack, R. (2021). The OpenNeuro resource for sharing of neuroscience data. eLife, 10, e71774. https://doi.org/10.7554/eLife.71774
[2] Botvinik-Nezer, R., Holzmeister, F., Camerer, C. F., Dreber, A., Huber, J., Johannesson, M., Kirchler, M., Iwanir, R., Mumford, J. A., Adcock, R. A., Avesani, P., Baczkowski, B. M., Bajracharya, A., Bakst, L., Ball, S., Barilari, M., Bault, N., Beaton, D., Beitner, J., Benoit, R. G., … Schonberg, T. (2020). Variability in the analysis of a single neuroimaging dataset by many teams. Nature, 582(7810), 84–88. https://doi.org/10.1038/s41586-020-2314-9