「全球最嚴榜單」,階躍拿下中國TOP 1!殺入世界前五,超過GPT-4o緊跟o1-mini

新智元報導
編輯:編輯部 HYZ
【新智元導讀】在「全球最難LLM評測榜單」上,國產萬億參數模型殺入全球第五,拿下中國第一!國內明星初創階躍星辰的這個自研模型太過亮眼,甚至引起了外國網民的熱議。
不低調了!
剛剛,國際權威榜單LiveBench最新榜單出爐,一個國產黑馬閃耀其中。
沒錯,它就是階躍星辰自研的萬億參數大模型Step-2。
Step-2以碾壓之勢,強勢殺入LiveBench全球前五,一舉奪得國內TOP 1。
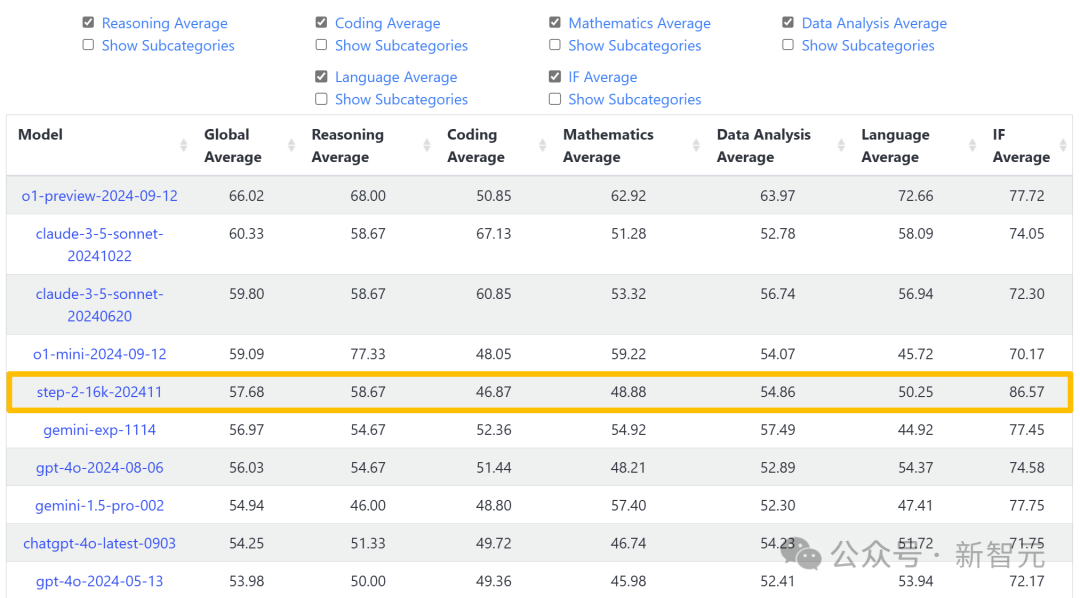
更讓人熱血沸騰的是,這款Step-2語言大模型,成為唯一一個衝進榜單前十的中國語言大模型。
根據榜單評測,Step-2成績逼近OpenAI o1-mini(2024-09-12),超越GPT-4o(2024-08-06)、Gemini 1.5 Pro 002等國際主流模型。
Step-2的真實表現,徹底震驚了歪果仁。在Reddit和X上,可謂是熱議連連。
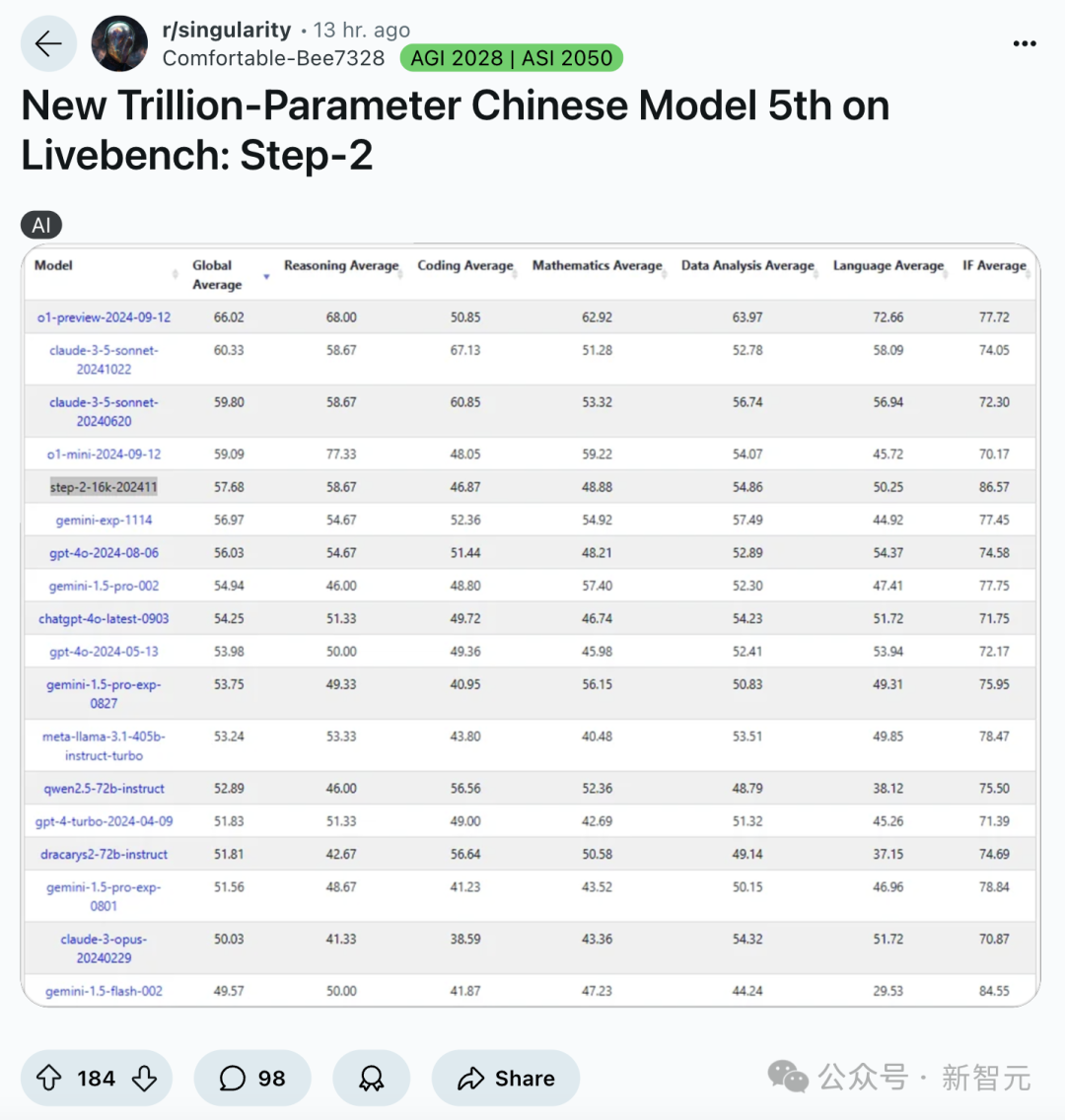
太令人印象深刻了!或許OpenAI、Anthropic、DeepMind發佈萬億參數模型時,我們也能看到這一結果。

中國的LLM正在變得強大,一個全新模型登上LiveBench榜單第五名,而且在多個基準測試中超越了GPT-4o,甚至在其中一個基準上擊敗了o1-preview
如今,Step-2以王者姿態,實至名歸。
趕超o1-preview,全憑驚人理解力
根據榜單,在IF Average(指令跟隨)一項中,Step-2的表現超越了所有上榜的國內外模型。
甚至,連OpenAI o1-preview(2024-09-12)也被碾壓式擊敗,領先近10分。
這意味著,Step-2在語言生成上對細節有最強的控制力,模型能夠更好地理解和遵循人類指令。
比如,即便給出模糊的指令,憑藉出色的理解能力,Step-2基於上下文推斷用戶的需求,精準捕捉其真實意圖,提供更準確、個性化的響應。
Step-2的與眾不同在於,在知識覆蓋面和深度上,取得了實打實的突破。
不僅能處理常見的領域知識,還能更深層次理解、回答特定領域複雜問題。
在文字創作方面,Step-2更展現出了令人驚歎的控制力。
它就像一位豐富的文字匠人,比如在創作古詩詞時,對字數、格律、押韻、意境都可以做到精準把握。
Step-2既能生成高質量、有創意的文字內容,又具備了出色的細節控制力,根據用戶指令對文本進行精準調整和優化。
大模型最權威評測,LeCun領銜
值得一提的是,LiveBench是由圖靈獎得主Yann LeCun聯手Abacus.AI、NYU、英偉達等多家機構推出的LLM評測基準。
其重要性,不言而喻。
而且,它被行業譽為「世界上第一個不可玩弄的LLM基準測試」。

當前,測試集汙染,已經成為公平評估大模型面臨的一個普遍問題。
就好比LLM在訓練時偷看了測試數據,使得原有評測失去了意義。
雖然業界嘗試通過人工/LLM打分來收集新提示詞和評估結果,但這種方法會引入新的偏差,特別是在評估複雜問題時表現不佳。
LiveBench就是為了破解這一難題而誕生。
這一創新基準從數學、推理、編程、語言理解、指令遵循和數據分析在內的多個複雜維度對模型進行評估。
而且,它還會每月定期更新,基於最新信息源的測試問題。
每個測試問題都配備了可驗證的、客觀的參考答案,這使得即使是較為複雜的問題也能夠準確且自動地完成評分,無需依賴LLM作為評判標準。
 項目地址:https://livebench.ai/#
項目地址:https://livebench.ai/#為了確保測試的「新鮮度」,它採用了多種創新方法,保證測試內容未受數據汙染。
比如,精心設計基於最新數學競賽、arXiv論文、新聞文章和數據集的問題,同時收錄了來自現有評測基準(如Big-Bench Hard、AMPS和IFEval)的改進版任務。
發佈之初,研究團隊基於LiveBench對知名閉源模型進行評測,以及對參數規模從5億到1100億參數不等的數十個開源模型進行了評估。
測試結果卻令人深思:即使是最強大的模型,準確率也未能突破65%的天花板。
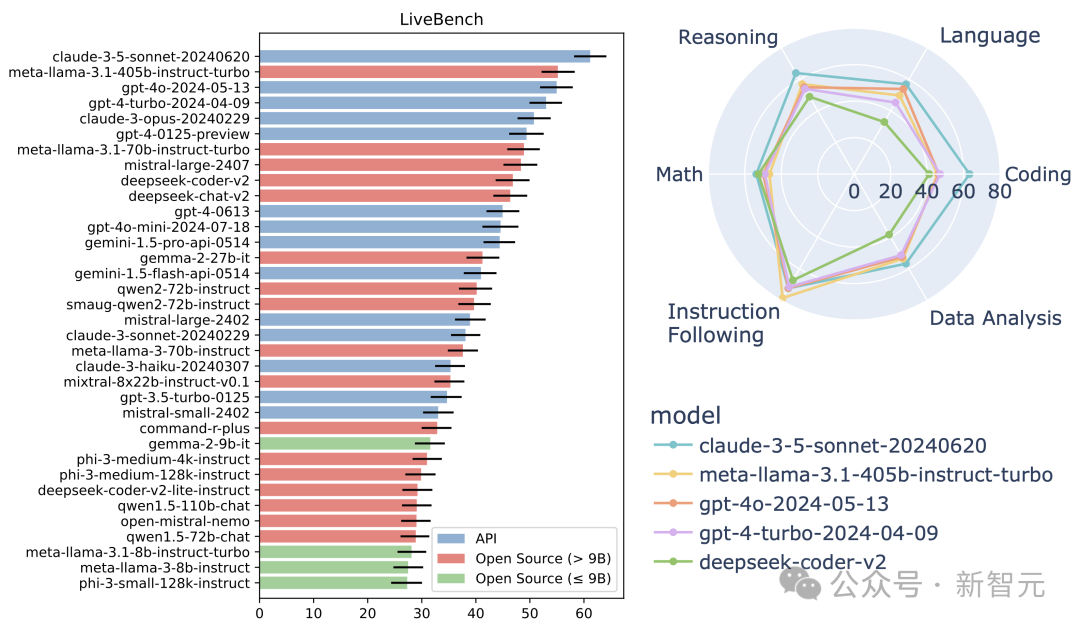
足見,LiveBench在大模型評測中的權威性和挑戰性。
這也從側面說明了,能夠躋身TOP 5的模型,必定是真材實料、技術過硬的佼佼者。
那麼,究竟是怎樣的技術實力,讓Step-2能夠在如此嚴苛的考驗下脫穎而出?
讓我們一起來揭開這個謎底…
萬億參數Step-2,是怎樣煉成的
今年3月,還是LLM戰場新玩家的階躍星辰,就一口氣發佈了千億參數語言大模型Step-1、千億參數多模態大模型Step-1V,以及來自國內大模型初創的首個萬億參數MoE語言大模型Step-2預覽版。
今年7月,Step-2正式亮相後,更是直接躋身國際頂尖模型的行列。
在數理邏輯、編程、中文知識、英文知識、指令跟隨等方面,Step-2的能力和使用體驗已經全方位逼近GPT-4。
目前,階躍星辰已將Step-2接入了C端智能助手「躍問」,在躍問App和躍問網頁端皆可體驗。
 體驗地址:https://yuewen.cn
體驗地址:https://yuewen.cn從千億模型擴展到萬億參數,並不是簡單的「大力出奇蹟」,而是需要跨過技術上的「分水嶺」,對各個維度的要求都是水漲船高。
一旦其中任何維度出現短板,Scaling Law都將不再適用,出現「只投入,不產出」的尷尬局面。
為了訓出強悍的Step-2,技術團隊在算法和系統方面都做出了大量的關鍵創新。
階躍星辰創始人、CEO薑大昕博士表示,模型擴大到萬億級別時,MoE幾乎是必選項,這是權衡了性能、參數量、訓練成本、推理成本等各個維度後的最佳選擇。
要訓練如此大規模的MoE模型,有兩條路可走:一是將已有模型進行向上複用(up-cycle)。
這個方案最大的好處,就在於慳錢省力,算力需求低、訓練效率高,但會限制模型能力的上限,容易造成比較嚴重的專家同質化。
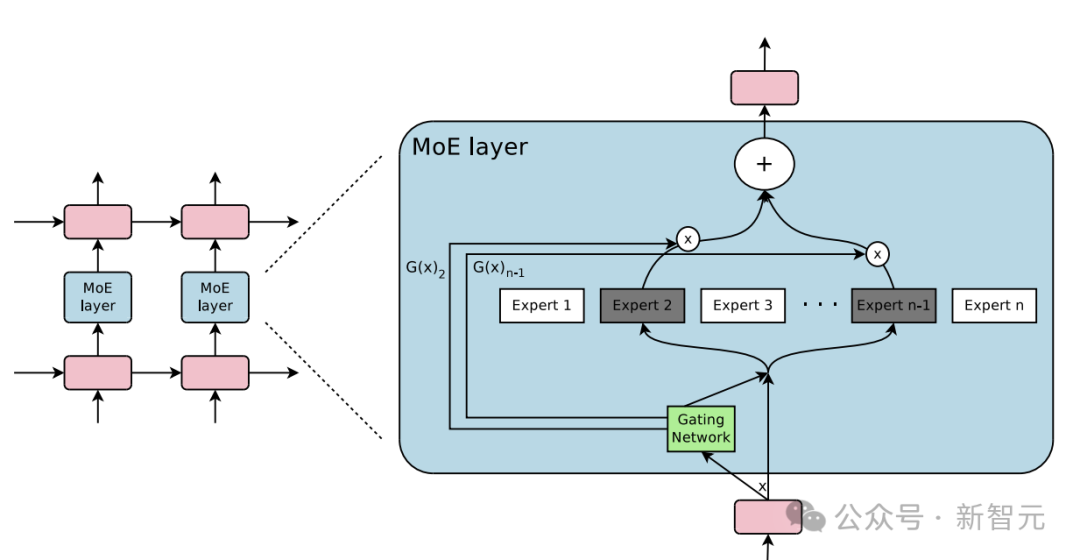
為了達到最優性能,階躍星辰團隊選擇迎難而上,沒有採用第一種方案,而是完全自主研發,從頭開始。
Step-2的架構中採用了部分專家共享參數、異構化專家等一系列新穎的設計,充分利用萬億參數。
雖然在MoE架構中,每次訓練或推理只會激活部分參數,但背靠萬億總量,激活的參數量也能超越大部分稠密模型。
當參數增長到萬億級別時,訓練效率至關重要,這離不開高效且穩定的系統部署。
高效,意味著GPU的使用效率高,讓有限的硬件輸出最多的算力;穩定,意味著訓練過程需要持續進行,不能輕易被故障打斷。
即使每張GPU日夜不停連續跑兩個月才出現一次故障,放在萬卡集群中,相當於平均每10分鐘就有一張卡出問題。
如果沒有自動的故障檢測和恢復機制,每張卡出問題時都要恢復檢查點、重啟訓練,不僅工程師不用睡覺了,模型的訓練週期更是成倍拉長。
在Step-2訓練過程中,階躍星辰的系統團隊突破了6D並行、極致顯存管理、完全自動化運維等關鍵技術,從高效、穩定兩個層面同時發力,才能在3個月的時間內發佈新模型。
如今,哪條是通往AGI的坦途,業內大佬們依舊爭論不一。
從Step-2霸榜驚豔表現,到多模型齊頭並進,階躍星辰展現出一家頂尖AI公司應有的實力和遠見。
這不僅僅是一個技術突破的見證,更是一個關於中國AI力的最好註腳。
參考資料:
https://livebench.ai/#/
https://yuewen.cn