一家中國公司,憑什麼敢說自己是真正的「物理世界模擬器」?

作者|Yoky郵箱|yokyliu@pingwest.com
在2024年的AI領域,我們正在見證一個有趣的轉折。
OpenAI的進展節奏明顯放緩,GPT-5遲遲未能問世,「Scaling Law」成了天方夜譚,即便是年初震撼業界的影片生成模型Sora,也未能如期實現「全面開放」的承諾。
這種現象背後折射出一個深層問題:基於Internet數據訓練的大模型,正在觸及其認知邊界。簡單堆砌參數量和擴充訓練數據,已經難以帶來質的突破。與此同時,具身智能、可穿戴設備以及重獲關注的AR/VR技術,都在指向一個共同的方向:AI必須與物理世界建立更緊密的聯繫。
從Internet到World,從AI到Physical AI,這個轉向標誌著AI發展的新階段。物理AI不僅僅是對現實世界的表面模仿,而是要將物理世界的基本規律和真實特性融入AI系統的底層設計中。它的終極目標是構建一個「多維度物理世界模擬器」,這遠比生成二維影片的Sora要複雜得多。
物理AI的發展之所以相對滯後,不是因為不重要而是因為非常困難。首先是物理世界數據的稀缺性,真實世界的物理數據採集成本高昂且難度大;其次是算法範式的根本差異,需要模擬幾何關係、光線傳播、力學規律等物理現象,而不是簡單模仿人類神經網絡;最後是計算資源的巨大需求,對現有算力形成了更大壓力。
然而,儘管物理AI還沒有進入大眾語境,卻已經開始對於各行業產生真切的影響。在計算機視覺領域,它幫助自動駕駛汽車理解真實道路環境;在工業製造中,它讓機器人更精準地執行複雜任務;在元宇宙世界里,它正在構建符合物理規律的虛擬空間。
這些都預示著,物理AI不僅僅是下一個技術風口,更是打開現實與數字世界之間的橋樑。在這個充滿想像力的賽道上,一些企業已經開始展現出獨特的技術積累,正在將物理世界的規律編織進AI的未來圖景中。
「3D界的ImageNet」
熟悉AI的人,不可能不知道ImageNet。這個數據集的出現,猶如一顆重磅炸彈,徹底改變了計算機視覺的發展軌跡。
2009年,整個AI發展到了圖像識別的關鍵節點。身在史丹福的李飛飛及其團隊,敏銳地意識到數據集的重要性。他們發起了名為「ImageNet」的項目,通過互聯網收集圖片並進行人工標註。這個浩大的工程最終收錄了超過1400萬張圖片,覆蓋了2萬多個類別,並對所有開發者開放,為圖像識別和分類技術的發展奠定了基礎。
ImageNet的影響力遠超預期。它不僅提供了訓練數據,更催生了著名的ImageNet挑戰賽。2012年的這場比賽成為了AI歷史的轉折點。
今年剛獲得盧保物理學獎的辛頓教授,帶著他的兩名學生開發了基於卷積神經網絡(CNN)的模型AlexNet。這個創新性的模型將圖像識別的準確率從75%左右一舉提升到了84%,掀起了深度學習革命的序幕。這個突破讓學術界和產業界徹底轟動,標誌著AI正式進入圖像時代。
六年後的2018年,一個堪稱「3D界的ImageNet」的項目悄然誕生。英國帝國理工大學計算機機器人視覺實驗室與一家中國公司合作,推出了室內場景認知深度學習數據集InteriorNet。它包括了1600萬組像素級標籤數據,1.5萬組影片數據,總計約1億3千萬張圖像數據,用於訓練和測試AI系統在室內環境中的視覺識別和理解能力。
這是迄今為止全球最大的室內場景數據集,而且已經全面開放。
讓人意外的是,參與這個突破性項目的中國公司,是一家不被公眾所熟知的企業:群核科技,但你一定熟悉它旗下的一款3D空間設計產品:酷家樂。
基於高性能計算對物理世界的渲染,群核科技平台積累了海量的設計方案和超過3.2億的3D模型,它們天然包含了完整的三維空間信息,也記錄了設計師對空間的專業理解。更重要的是,龐大的用戶群體持續創作的設計方案和商品素材,為群核提供了源源不斷的數據來源,還保證了數據的準確性和多樣性。
為什麼要創建一個「3D版的ImageNet」?群核科技首席科學家、酷家樂KooLab實驗室負責人唐睿告訴我們:「當我們擁有了大量的空間數據後,我們開始思考能否應用在其他研發場景中。與帝國理工大學的合作是探索空間數據在無人機試飛的仿真實驗中的應用,此後,我們基於物理正確的渲染引擎,將空間數據應用在了具身智能等其他前沿科技中,也就是群核空間智能平台SpatialVerse在做的事情。」
室內場景數據集的稀缺性在哪?與二維圖像相比,要完整描述一個三維物體,需要處理幾何關係、材質屬性、空間位置等呈指數級增加的複雜參數。即便是描述一把普通椅子,也需要精確記錄每個部件的尺寸、形狀、材質的光學特性等多維信息,還包括椅子與桌子之間的物理距離。傳統的數據採集方式不僅成本高昂,還面臨著隱私保護和法律合規等諸多限制,這使得高質量三維數據的獲取成為了一個行業難題。更具挑戰性的是,室內空間物理數據的採集還面臨著隱私保護和合規性的嚴峻考驗。
不過,這些場景雖然具備物理正確,但是離真實的生活狀態比較遠,比如在酷家樂平台上有大量的家居場景設計方案,這些方案的桌子、客廳都是非常整潔,但現場生活中客廳可能會有玩具,生活垃圾。群核空間智能平台又做了一件事:通過將真實的生活元素渲染入設計場景,讓這個虛擬空間更接近生活真實狀態。舉個例子,原先掃地機器人在清理貓屎時是通過碰撞,這樣就很糟糕,現在通過在虛擬空間進行預訓練能準確識別貓屎等。
這些優勢使得群核在為具身智能、大模型和AIGC、AR/VR企業提供定製化數據服務時,其核心價值得以顯現。
「破壁人」
那麼問題來了,要將真實的物理數據對應到數字世界進行操作,需要打破二者間的「次元壁」。
在人類生存的空間本身存在大量物理數據,我們能將他們翻譯成機器能夠聽懂的語言。群核矩陣(CAD)引擎,並發佈自主研發的百億級參數的多模態CAD大模型,能對物理世界產生的或存在的設計數據進行了翻譯、兼容和數據流轉。
想像一下,當建築師在圖紙上畫下一道道牆線,這條線不僅代表了一個簡單的幾何形狀,還包含了牆體的厚度、材質、位置等諸多信息。多模態CAD大模型逆向解析引擎就像一個經驗豐富的工程師,能夠準確識別圖紙中的每個元素,理解它們之間的關係,並將這些非結構化的信息轉換三維結構化為計算機可以理解的數據。
但僅僅理解單一的CAD圖紙是遠遠不夠的。在實際工程中,設計信息往往以多種形式存在:2D圖像圖紙、3D模型、設計說明,甚至是施工規範。這就需要多模態CAD大模型的支持。相比語言大模型對空間描述的模糊與不確定性,CAD大模型能夠實現對空間更準確和結構化的表述。
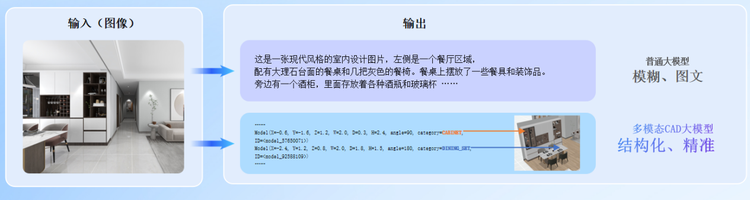
這個「大腦」能夠同時處理多種形式的輸入,提取關鍵特徵,學習設計規則,最終將所有信息統一轉換為標準化的數字表達。
當多模態CAD大模型將物理世界的非結構化數據統一轉譯並,生成數字世界的三維結構化數據後,群核矩陣(CAD)引擎的另兩大技術幾何參數化引擎、BIM引擎就像是數字世界和物理世界的另一架橋樑,在設計完成後,它們再逆向轉為非結構化數據,進一步生成效果圖、施工圖等,指導施工和生產。
簡單地說,就是完成了從物理世界到數字世界的逆向解析,再從數字世界返回物理世界的正向建模的全過程。
而將這個過程的能力抽像出來,其實也對應著一種人類的智能:將複雜的物理世界數據高質量壓縮並提取特徵,存儲在計算機中,同時保持反向重建的能力。
對於數據處理的核心算法+大量真實的應用場景,使群核能夠沉澱出更最大的空間數據集。
「你相信光麼?」
機器能夠讀懂物理世界,在於技術對於數據的結構化處理,而人類要想讀懂數字世界,最根本的差異在於:數字世界是沒有光的。
物理世界中的所有「可視化」,本質上都是光粒子運動的結果——反射、折射、散射等一系列物理反應的組合。沒有光,我們就無法判斷一把椅子的形狀、顏色、位置,以及與其他物體的力學關係。
呈現一把椅子,從根本上來說,就是在重現特定空間中的光粒子分佈。在數字設計領域,這個過程被稱為真實感渲染。群核科技的渲染引擎正是基於這一原理構建,通過精確計算光線在空間中的傳播路徑,模擬不同材質的光學特性,實現物理正確的視覺效果。
但渲染只是整個技術體系的一部分。在設計過程中,系統需要同時處理多個物理維度的問題。一件傢俱的設計不僅要滿足視覺審美,更要符合力學原理。這在一定程度上體現在群核的產品中,系統能夠在設計階段就對方案進行力學分析,及時發現結構性問題。
在實現真實感渲染時,群核科技的渲染引擎採用了基於物理的渲染方法(Physically Based Rendering,PBR)。這種渲染技術的核心是解算渲染方程,通過計算光線與物體表面的相互作用來模擬真實世界的光照效果。系統在處理每個材質時,都會考慮其微觀表面結構,包括表面粗糙度、金屬度等物理屬性,從而準確還原材質的反射特性。
尤其當設計師調整屋內光線時,群核啟真(渲染)引擎基於光線追蹤技術可以模擬物理世界中光線在虛擬場景中的光學現象,包括反射、折射、散射等,進而帶來堪比真實世界的渲染效果,使創作者的作品更寫實。而且借助 AI 技術對畫面光影、色彩等元素進行真實感增強,啟真(渲染)引擎攻克了傳統渲染器在有機物真實感渲染上的難題,並且可以渲染物理世界 99% 的材質。

技術的核心優勢來源於數據積累,由於大量的數據來源於物理世界又被應用在物理世界中,在這個過程中,自然完成了一些物理AI中最重要的一環:物理正確。
與當前市場上備受關注的Sora等生成式AI產品相比,群核的方案展現出明顯的物理正確性優勢。這個差異的根源在於訓練數據的性質:Sora主要依賴二維影片數據,這些數據雖然視覺豐富,但與物理世界缺乏本質聯繫。其生成內容中經常出現的物理錯誤,如不合理的物體運動或材質表現,正是這一局限的直接體現。
相比之下,群核科技多年來積累的是完整的三維數據,包含幾何信息、物理參數、材質屬性等多個維度。這些數據不僅經過專業設計師驗證,更重要的是與實際工程實踐保持密切關聯。配合專門的物理引擎,這些數據支撐起了一個更接近現實的物理世界模擬器。
「當4顆GPU改變世界」
在辛頓的故事里,之所以全世界轟動,原因之一在於識別準確率的斷崖式提升,原因之二在於AlexNet只基於4顆英偉達GPU,就打敗了Google用16000顆CPU所構建的Google貓。這一成果震驚了整個學術界和工業界,徹底改變了深度學習的發展軌跡。
人們發現在特定的計算場景下,對於算力的使用效率遠大於規模。
理論上,空間里所存在的光粒子是無限的,有如人腦神經元一樣複雜,所以還原正確的物理世界,同樣對底層算力提出了極高要求。能夠同時渲染10顆光粒子、100顆粒子還是10000顆粒子,決定了渲染的速度,取決於並行計算的效率。
群核的故事同樣起於對GPU算力的「解鎖」。三位創始人長期專注於計算機圖形學、高性能計算等方向。創業前,黃曉煌曾在英偉達負責CUDA開發,彼時一本名為《Physically Based Rendering: From Theory to Implementation》的書開啟了他對物理AI探索的好奇心。
但彼時,在還原物理世界這一步,渲染出圖的平均速度在1-2個小時左右,且一張圖的成本高達千元。
能否用一個更低成本的雲端GPU集群,用廉價的顯卡來實現商用超級計算的性能,將「渲染」的價格和時間成本打下來,甚至獲得更好的渲染效果?
2011年,群核創始團隊用低價顯卡集合成一個端雲協同的高性能GPU集群,並通過優化算力資源的調度策略,大幅度提升GPU利用率。這使得算力成本大幅降低,並實現更快的計算速度。
在群核更新的四代渲染引擎中,第一代技術通過基礎並行優化,重構了渲染管線,將渲染時間從小時級降至分鐘級。第二代技術增強了真實感的渲染能力。第三代技術實現了雲端實時和光線追蹤,通過自研算法和動態負載均衡,讓設計師能夠在實時環境中進行創作。今天亮相的第四代基於渲染和AI的融合,在渲染速度、逼真度、通用性和智能化層面都實現了大幅提升。
從幾小時到幾秒鍾再到實時,將1000元的出圖成本降到免費,本質上是進一步提高計算效率保證計算效果的結果。
具有深厚CUDA開發背景的團隊也為群核帶來了獨特優勢。他們深知GPU架構的特點,能夠從底層優化計算效率。比如,通過優化內存訪問模式,減少數據傳輸開銷;通過智能任務分配,提高GPU核心利用率;通過計算流水線重構,最大化並行計算效果。這些技術積累讓群核在處理複雜渲染任務時具備了明顯的性能優勢。
比如通過智能分析場景複雜度,提前規劃計算資源分配,大幅提升了GPU利用效率。系統能夠根據不同場景特徵,動態調整渲染策略,在保證效果的同時最大化計算效率。
在工業設計領域,實時渲染技術可以用於產品原型驗證,大幅減少實物樣品的製作成本。在建築設計中,它能夠支持實時的方案調整和效果預覽,提高設計效率。在虛擬現實領域,實時更是實現沉浸式體驗的基礎。
擁有了計算能力、可實踐的應用場景,和長期的數據積累後,一個新的想像空間正在打開。
如同當年的4顆GPU改變了的人工智能發展的軌跡一樣,物理AI的大門也正在被推開。
結尾:
1993年,黃仁勳與合夥人Chris Malachowsky和Curtis Priem共同創立了NVIDIA。創立之初,他們想為個人電腦市場提供高性能的圖形處理解決方案。
隨著精品化遊戲的發展,高清的效果和酷炫的動畫使得影片遊戲行業對圖形處理能力的需求日益增長。1999年NVIDIA推出了GeForce 256,這是世界上第一個被定義為「GPU」(圖形處理單元)的產品。GPU它能夠處理複雜的3D圖形任務,也僅僅是為了提升了遊戲的視覺效果。
2006年,黃仁勳開始推動英偉達開發CUDA開發平台,CUDA使得開發者能夠利用GPU的強大計算能力來處理各種複雜的計算任務。
萬事俱備後,AI的東風來了。
隨著深度學習算法的發展,對計算能力的需求急劇增加,而GPU並行計算的處理能力成了AI研究和應用的天然選擇。緊接著,GPU被用於遊戲、專業視覺、自動駕駛、雲計算、大模型等多個科技領域。英偉達也不斷推出RTX(實時光線追蹤技術)和DLSS(深度學習超采樣技術),進一步提升了圖形處理和AI應用的性能。
一個時代的機遇,總會留給準備好的人。
於群核而言,或許也到了這樣一個節點。




















