諾獎得主哈薩比斯新作登Nature,AlphaQubit解碼出更可靠量子計算機
機器之心報導
編輯:杜偉、陳陳
Google「Alpha」家族又壯大了,這次瞄準了量子計算領域。
今天淩晨,新晉盧保化學獎得主、DeepMind 創始人哈薩比斯參與撰寫的新論文登上了 Nature,主題是如何更準確地識別並糾正量子計算機內部的錯誤。
我們知道,量子計算機有潛力徹底改變藥物發現、材料設計和基礎物理學。不過前提是:我們得讓它們可靠地工作。
雖然對於傳統計算機花費數十億年才能解決的某些問題,量子計算機在幾小時內就可以搞掂。然而,量子計算機比傳統計算機更容易受到噪聲的影響。如果想要量子計算機更可靠,尤其是在大規模情況下,則需要更準確地識別和糾正內部的錯誤。

因此,Google DeepMind 聯合Google量子 AI 團隊發表了一篇論文,推出了 AI 解碼器 AlphaQubit,它能夠以 SOTA 準確性識別並糾正量子計算的錯誤。據介紹,這項工作彙集了Google DeepMind 的機器學習知識和Google量子 AI 的糾錯專業知識,從而加速構建可靠量子計算機的進程。
兩支團隊表示,準確識別量子計算機錯誤是促使它們能夠大規模執行長時間計算的關鍵一步,將為科學突破和更多新領域的發現打開大門。


Nature 論文的標題為《Learning High-accuracy Error Decoding for Quantum Processors》,即《學習量子處理器的高準確性錯誤解碼》。

-
Nature 地址:https://www.nature.com/articles/s41586-024-08148-8
Google CEO 桑達爾・皮查伊表示,「AlphaQubit 使用了 Transformers 解碼量子計算機,從而達到量子糾錯準確性新 SOTA。這是 AI + 量子計算的激動人心的交集。」
我們接下來看 AlphaQubit 的技術細節和實驗結果。
量子計算糾錯的原理
量子計算機利用最小尺度上物質的獨特屬性,例如疊加和糾纏,以比傳統計算機少得多的步驟解決某些類型的複雜問題。該技術依賴於量子比特,它們可以利用量子干涉篩選大量可能性以找到答案。
不過,量子比特的自然量子態很脆弱,可能受到各種因素的干擾,包括硬件中的微觀缺陷、熱量、振動、電磁干擾甚至宇宙射線,可以說無處不在。
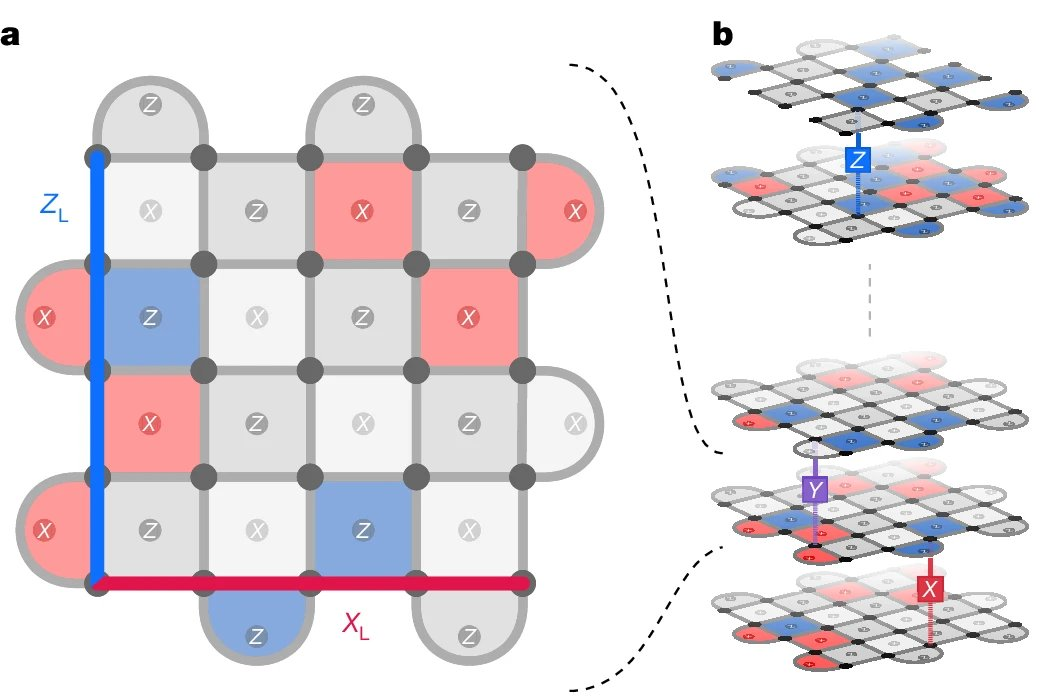
量子糾錯通過使用冗餘提供了一種解決方案:將多個量子比特分組為單個邏輯量子比特,並定期進行一致性檢查。AlphaQubit 解碼器通過利用這些一致性檢查來識別邏輯量子比特中的錯誤,從而保留量子信息,並進行糾錯。
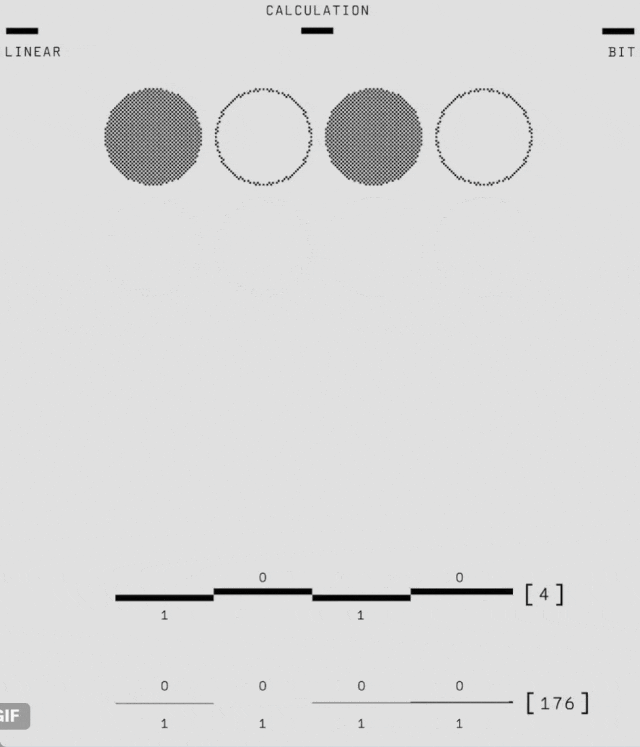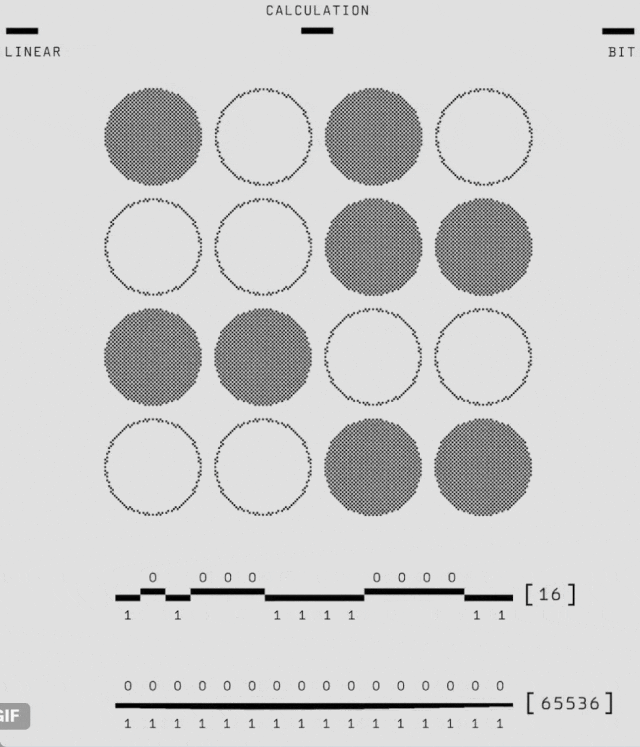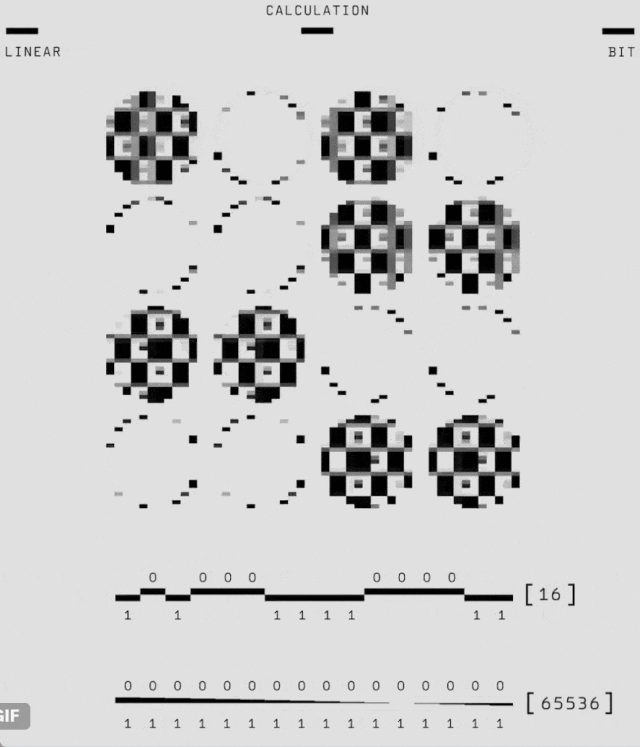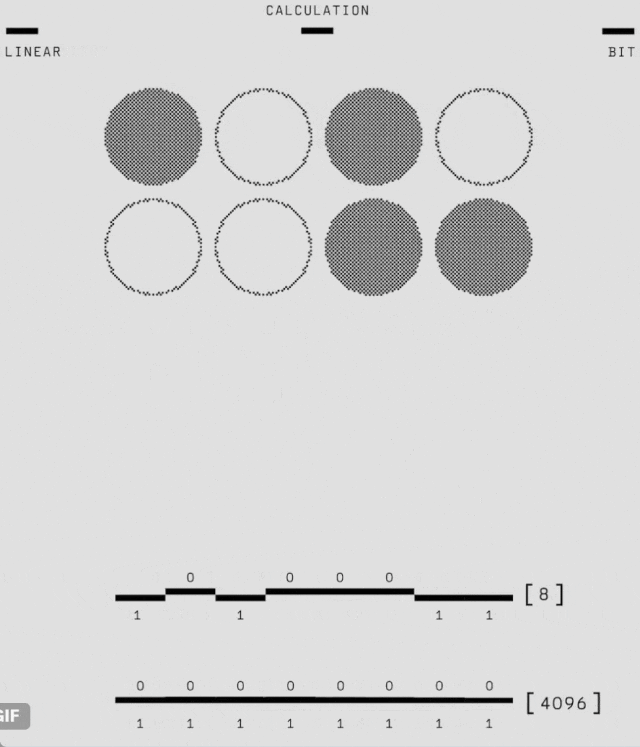
如下動圖展示了邊長為 3(碼距離)的量子比特網格中 9 個物理量子比特(小灰色圓圈)如何形成邏輯量子比特。
其中,在每個步驟中,另外 8 個量子比特在每個時間步驟執行一致性檢查(正方形和半圓形區域,失敗時為藍色和品紅色,否則為灰色),以通知神經網絡解碼器(AlphaQubit)。在實驗結束時,AlphaQubit 確定發生了哪些錯誤。
Google構建了一個神經網絡解碼器
AlphaQubit 是一個基於神經網絡的解碼器,基於 Transformers 構建,而該架構也是當今許多大型語言模型的基礎。
下圖為 AlphaQubit 的糾錯和訓練流程。a 為表面碼的一輪糾錯。b 為解碼訓練階段。預訓練樣本要麼來自數據無關的 SI1000 噪聲模型,要麼來自使用 p_ij 或 XEB 方法從實驗數據得出的誤差模型。
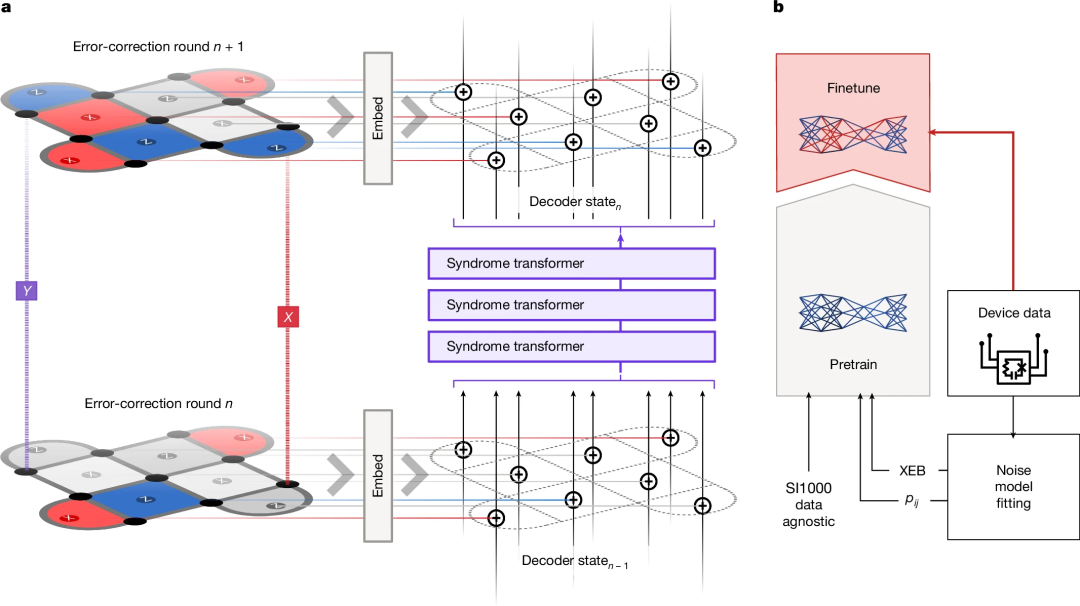
AlphaQubit 使用一致性檢查(consistency checks)作為輸入,旨在預測邏輯量子比特在實驗結束時的狀態是否與初始準備狀態發生了翻轉。通過一致性檢查,可以識別並糾正計算過程中出現的錯誤,確保邏輯量子比特狀態保持正確。
最終,AlphaQubit 可以報告其預測的置信度,從而有助於提高整體量子處理器的性能。
實驗及結果
實驗測試了 AlphaQubit 對量子處理器 Sycamore 中的邏輯量子比特的保護效果。Google使用量子模擬器在各種設置中生成了數億個示例。然後,通過為 AlphaQubit 提供來自特定 Sycamore 處理器的數千個實驗樣本,針對特定解碼任務對其進行微調。

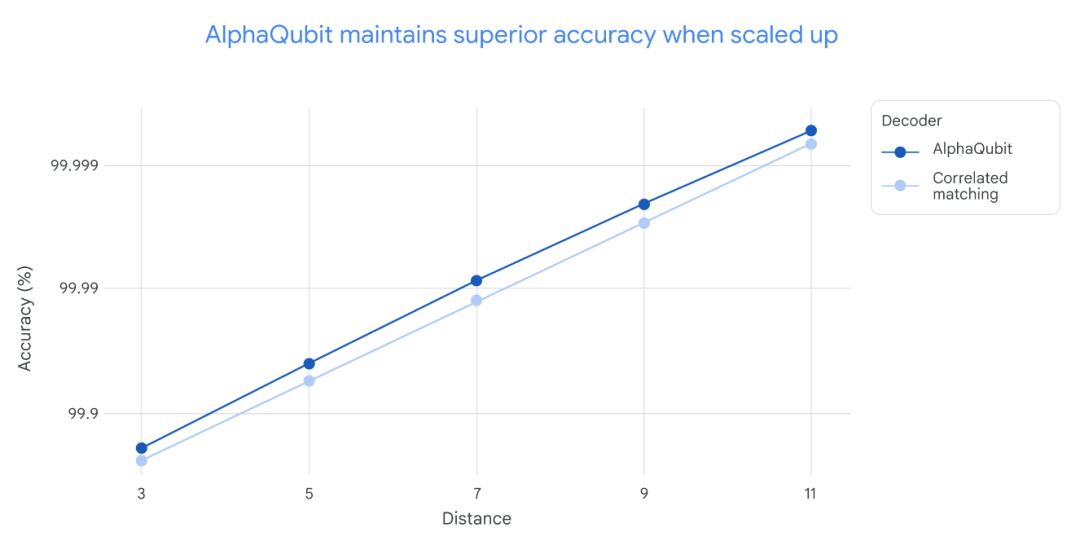
在對 Sycamore 量子處理器的新數據進行測試時,AlphaQubit 在準確率方面設立了新的標準。在規模最大的 Sycamore 實驗中,AlphaQubit 的錯誤率比張量網絡方法低 6%。此外,AlphaQubit 的錯誤率比相關匹配方法低 30%。
在 Sycamore 量子處理器的實驗中,解碼準確性因實驗規模而異。對於小規模實驗(距離 3,對應 17 個物理量子比特)和大規模實驗(距離 5,對應 49 個物理量子比特),AlphaQubit 的解碼準確性均優於其他方法。
具體而言,AlphaQubit 的表現超過了張量網絡(TN)方法,後者在大規模實驗中難以擴展。同時,AlphaQubit 也優於相關匹配方法,儘管該方法在準確性和擴展性方面表現良好,但在解碼準確性上仍不及 AlphaQubit。
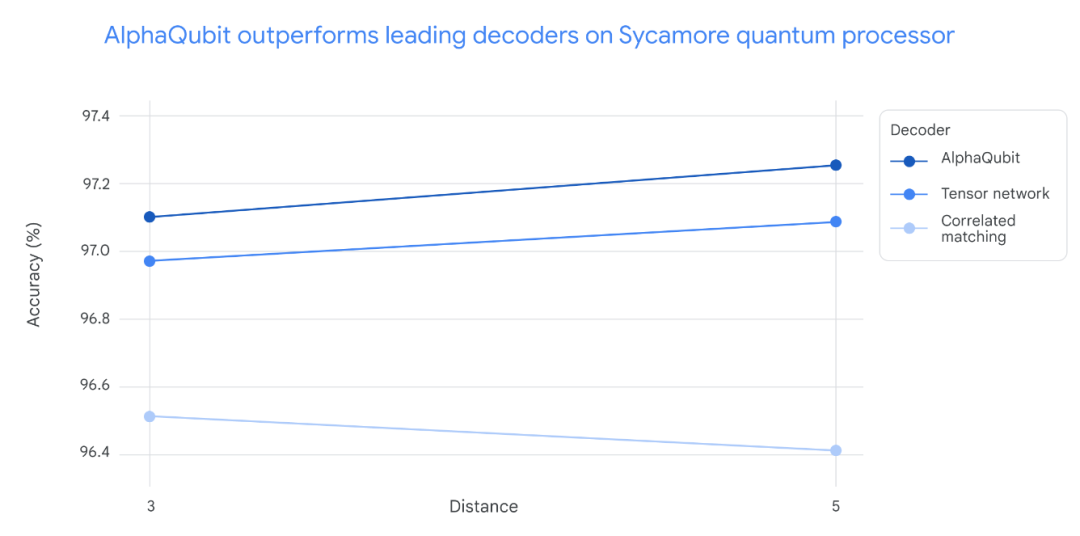
在一系列實驗中,解碼器 AlphaQubit 犯的錯誤最少。
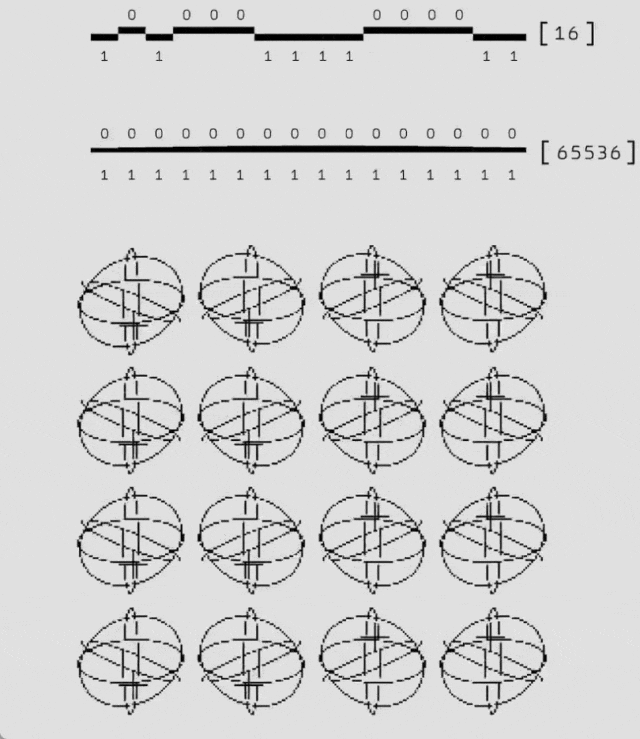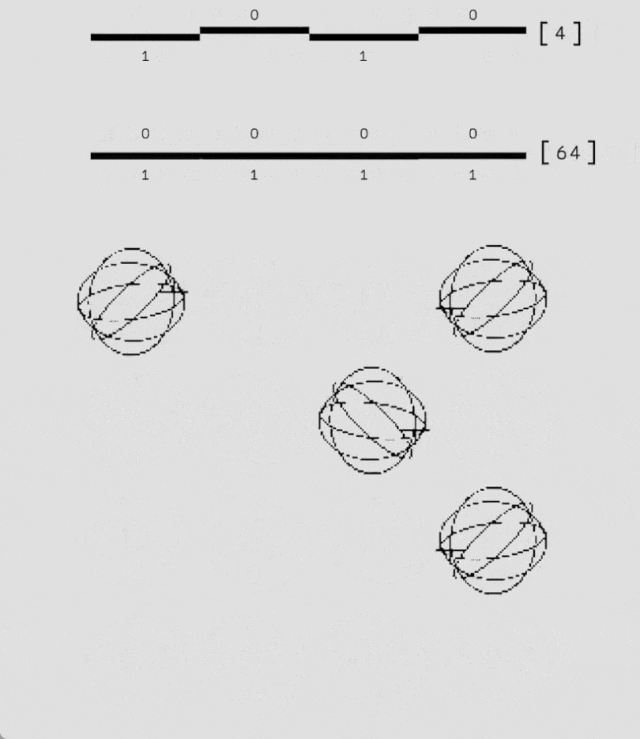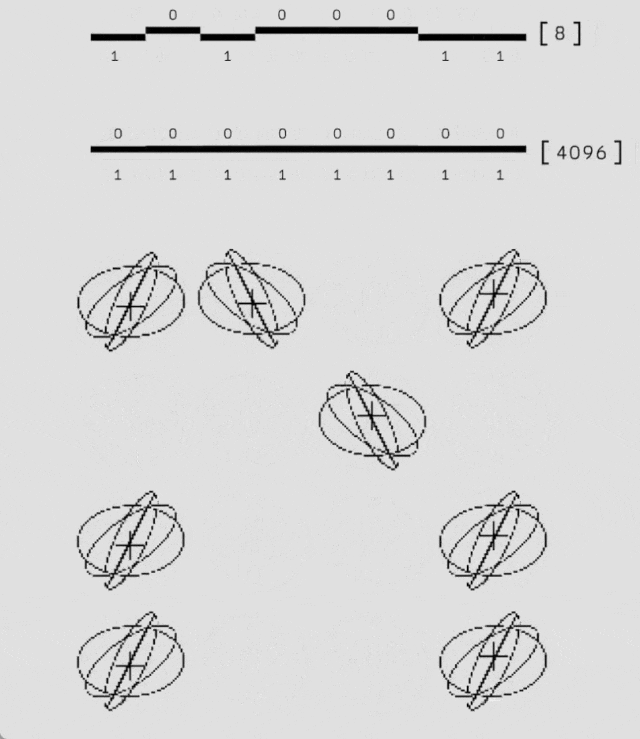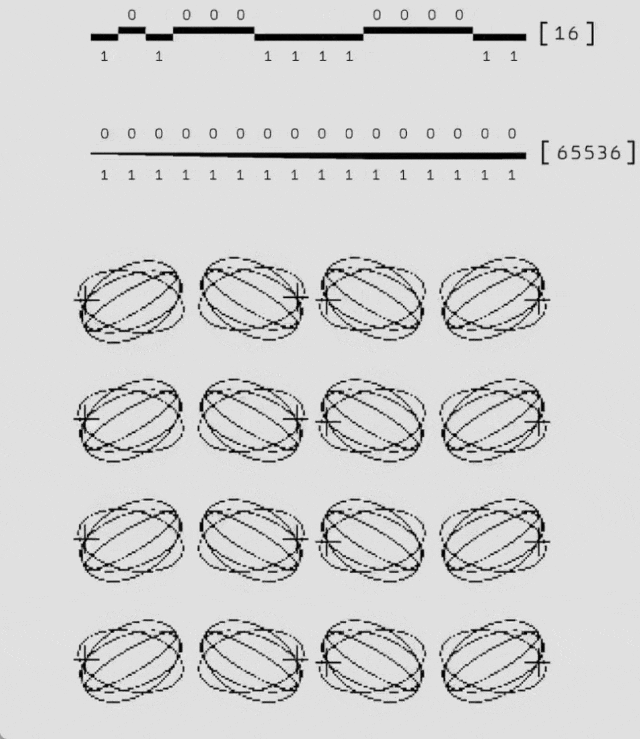
良好的泛化能力
為了評估 AlphaQubit 在更大規模且錯誤率更低的量子計算機上的適應性,研究人員使用模擬的量子系統數據對其進行了訓練,規模達到 241 個量子比特,超出了 Sycamore 平台的現有能力。

結果顯示,AlphaQubit 的性能優於現有的主要算法解碼器,表明其在未來中型量子設備上也將具備良好的適用性。
在不同規模的實驗中,即從距離 3(17 個量子比特)到距離 11(241 個量子比特)的實驗中,AlphaQubit 的解碼準確性始終優於相關匹配方法。需要注意的是,張量網絡解碼器由於在大規模實驗中運行速度過慢,未在此圖中顯示。
最後,該系統還展示了一些高級功能,例如能夠接收和報告輸入和輸出的置信度。這些信息豐富的界面有助於進一步提高量子處理器的性能。
當Google研究員在包含多達 25 輪糾錯的樣本上訓練 AlphaQubit 時,它在多達 100,000 輪的模擬實驗中保持了良好的性能,表明它能夠泛化到訓練數據之外的場景。
邁向更實用的量子計算
AlphaQubit 在利用機器學習進行量子誤差糾錯方面取得了重要的里程碑。但Google表示他們仍然面臨速度和可擴展性方面的重大挑戰。
例如,在一個快速的超導量子處理器中,每秒需要進行上百萬次一致性檢查。雖然 AlphaQubit 在準確識別錯誤方面表現出色,但目前還無法實時糾正超導處理器中的錯誤。Google還需要找到更高效的數據訓練方法,用於支持基於 AI 的解碼器。
目前,Google正在結合機器學習和量子誤差糾錯的前沿技術,努力克服這些挑戰,為實現可靠的量子計算機鋪平道路,這些技術將有能力解決世界上一些最複雜的問題。
參考鏈接:
https://blog.google/technology/google-deepmind/alphaqubit-quantum-error-correction/
https://x.com/GoogleDeepMind/status/1859273143157657735



















