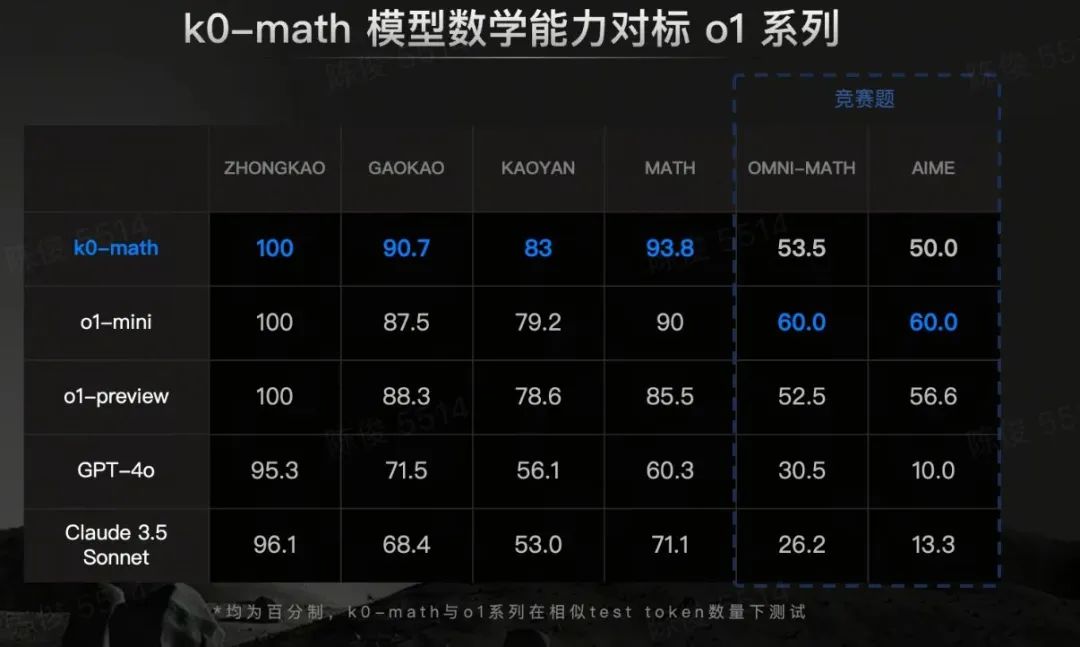
預定下一個諾獎級AI?Google量子糾錯AlphaQubit登Nature,10萬次模擬實驗創新里程碑

AI再下一城,這次直接攻進了量子計算。
今天,GoogleDeepMind團隊重磅發佈全新的「阿爾法」模型——AlphaQubit,一個基於Transformer構建的解碼器,能以高精度識別量子計算錯誤。
最新研究,已經發表在Nature期刊上。
 論文地址:https://www.nature.com/articles/s41586-024-08148-8
論文地址:https://www.nature.com/articles/s41586-024-08148-8量子計算機被視為下一次科學革命的強大引擎。經典計算機往往耗費數十億年才能解決的問題,量子計算機僅需個幾小時就能破解。
有了它,人類在變革藥物發現、材料設計、基礎物理學等方面潛力無限。
而這一切前提是,如何能夠讓其可靠地運行。
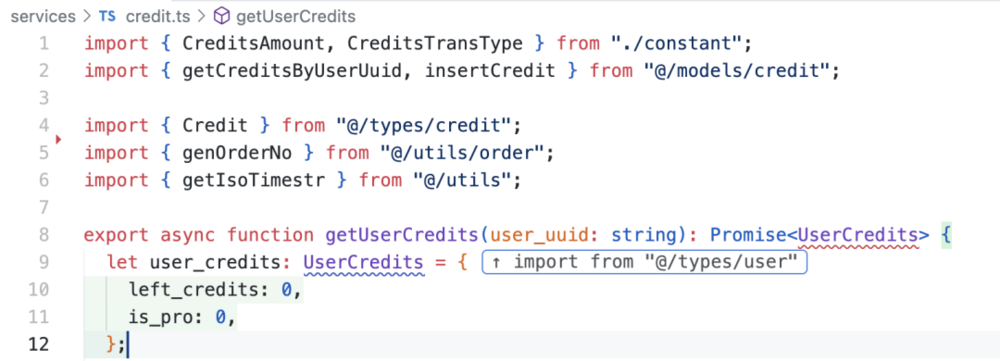
相較於傳統計算機,量子計算機更容易受到噪聲的干擾,尤其是在大規模的應用中更為明顯。

如今,大模型既然能夠大範圍應用在蛋白質設計、數學定理證明、芯片設計之上,在量子計算中必然也能發揮出最大的效力。
AlphaQubit便是業界在量子計算領域中,最重要的一次嘗試。
它彙集了兩大領域的關鍵知識:Google DeepMind機器學習知識和Google Quantum AI糾錯專業知識。
並在多達25輪糾錯的樣本上完成訓練,經過10萬次模擬實驗,成功驗證了AlphaQubit優異的性能。
具體來說,AlphaQubit在處理來自Google Sycamore量子處理器的實際數據時,在distance-3和distance-5表面碼(Surface code)上,超越了其他SOTA解碼器。
而且,在最高distance-11情況下,AlphaQubit利用軟讀出和泄漏信息,在串擾和泄漏等噪聲模擬數據中,保持了優越的性能。
CEO劈柴表示,「AlphaQubit利用Transformer解碼量子計算機,從而在量子精度糾錯方面取得了SOTA。這是AI+量子計算另一個令人興奮的交叉點」。

另一位Google研究副總表示,「我們相信這將是實現實用容錯量子計算的第一步」。

AlphaQubit準確糾錯量子計算,意味著新系統在未來能進行大規模計算,將為更多科學突破和新的發現打開大門。
正如網民所言,「AI似乎正成為一切的答案」。

實現量子霸權?量子糾錯這關必須過
量子計算機得以實現,是利用了物質在最小尺度下的獨特特性,如疊加和糾纏,以遠少於經典計算機的步驟解決某些類型的複雜問題。
量子比特是支撐量子計算的信息單位。它可以利用量子干涉篩選出大量可能性中的答案。
然而,量子比特的自然量子態是脆弱的,可能受到多種因素的干擾:硬件中的微觀缺陷、熱量、振動、電磁干擾,甚至是無處不在的宇宙射線。

一般來說,構建大規模量子計算機,需要更高效策略來糾正物理量子系統中,無法避免的錯誤。
因此,業界提出了使用邏輯信息冗餘的量子糾錯方案——量子糾錯碼(Quantum error-correction code)。
也就是,將多個量子比特組合成一個邏輯量子比特,並定期對其進行校驗。
解碼器通過使用這些校驗來識別並糾正邏輯量子比特中的錯誤,從而保護量子信息。
其中,最有前途的策略之一是,基於表面碼的量子糾錯。
如下圖所示,在所有具有平面連接性的編碼中,表面碼具有最高的已知錯誤容忍度。

「阿爾法」攻進量子計算,少犯30%錯誤
在這樣的背景下,Google團隊提出了一種一種基於循環Transformer的神經網絡架構AlphaQubit。
它能夠根據綜合信號輸入學習預測邏輯可觀測量的錯誤。
利用一致性檢查作為輸入,它的任務是在實驗結束時測量邏輯量子比特是否已從其準備狀態翻轉。
 圖2:AlphaQubit的糾錯與訓練
圖2:AlphaQubit的糾錯與訓練AlphaQubit通過兩個階段的訓練——先用模擬樣本進行預訓練,再用有限數量的實驗樣本進行微調訓練。具體操作如下:
首先訓練模型解碼來自Sycamore量子處理器內部49個量子比特的數據,該處理器是量子計算機的核心計算單元。
為了教會AlphaQubit通用的解碼問題,研究人員使用量子模擬器在各種設置和錯誤水平下生成了數億個示例。

這裏展示了如何在distance-3的量子比特網格中,利用九個物理量子比特單元(小灰色圓圈)形成一個邏輯量子比特。在每個步驟中,還有8個量子比特執行校驗(方形和半圓區域,失敗時顯示為藍色和品紅色,否則為灰色),這些校驗結果用於通知神經網絡解碼器(AlphaQubit)。在實驗結束時,AlphaQubit會確定發生了哪些錯誤
然後,通過向AlphaQubit提供來自特定Sycamore處理器的數千個實驗樣本,對其進行特定解碼任務的微調。
在新的Sycamore數據測試中,AlphaQubit相較於之前的SOTA解碼器樹立了新的精度標準。
在最大規模的Sycamore實驗中,AlphaQubit比張量網絡方法少犯6%錯誤,儘管張量網絡方法卡奧度準確,但速度極慢且不切實際。
AlphaQubit還比相關匹配方法少犯30%錯誤。

Sycamore實驗中小規模和大規模的解碼準確率(distance-3為17個物理量子比特,distance-5為49個物理量子比特)
具體實驗方法如下:
研究人員首先將AlphaQubit應用於Google的Sycamore存儲實驗,其中包括distance-3和distance-5的表面碼上進行的X基和Z基存儲實驗。
3×3編碼塊在Sycamore芯片上的四個不同位置執行,而5×5編碼塊則在一個位置執行。
對於每個總輪數n ∈ {1, 3, …, 25},進行了五萬次實驗,並將所得數據分為偶數和奇數子集以進行雙重交叉驗證。

下面描述的是在偶數集上的訓練,以及在奇數集上的最終測試。
解碼器性能通過每輪邏輯錯誤率(LER)來量化,即在每次額外的糾錯輪中解碼器失敗的實驗比例(圖3a)。
解碼器針對特定距離、基和位置進行訓練,但可以解碼任意輪次的實驗。如上所述,訓練分為兩個階段:預訓練和微調(圖2b)。
在預訓練階段,研究人員在三種不同程度與實驗數據相似的模擬數據之一上進行訓練。在前兩種情況下,他們在從檢測器錯誤噪聲模型(DEM)中抽取的多達十億個樣本上進行預訓練。
DEM要麼是擬合到(偶數)檢測錯誤事件相關性pij,要麼使用基於設備校準數據(來自交叉熵基準XEB)的Pauli噪聲模型導出的權重來近似硬件上發生的噪聲。
在第三種情況下,作者在多達五億個超導啟發電路去極化噪聲(SI1000噪聲)樣本上進行預訓練,這不依賴於實驗數據或量子設備,除了選擇整體噪聲規模以大致匹配實驗事件密度。
在微調階段,他們將325,000個偶數實驗樣本劃分為訓練和驗證集。此過程使,作者能夠在有限訪問實驗數據的情況下訓練出高精度的解碼器,同時將另一部分(奇數)保留為測試集。

AlphaQubit在distance-3時實現了 (2.901 ± 0.023) × 10⁻²的LER,在distance-5時實現了 (2.748 ± 0.015) × 10⁻²的LER(圖3a,b),錯誤抑制比Λ = 1.056 ± 0.010。
其中,集成20個獨立訓練的模型在碼distance-3(5)時,分別貢獻了0.03 × 10⁻²(0.08 × 10⁻²)的改進。這個LER甚至低於張量網絡解碼器——在distance-3時為 (3.028 ± 0.023) × 10⁻²,在distance-5時為 (2.915 ± 0.016) × 10⁻²,且Λ = 1.039 ± 0.010。
而且,作者稱這是迄今為止報告的該實驗中最準確的解碼器。
SOTA的基於MWPM的解碼器,例如相關匹配(MWPM-Corr)、帶有信念傳播的匹配(MWPM-BP)和PyMatching(MWPM的開源實現),得到的LER高於張量網絡和AlphaQubit(圖3a,b)。
為了比較,研究人員還展示了Boris Varbanov提出基於LSTM的神經網絡的結果36,以及Google自己實現的LSTM(兩者均在XEB DEMs上進行預訓練)。
這些在3×3上取得了良好的結果。Varbanov的基於LSTM的神經網絡未能在5×5上匹敵張量網絡解碼器(圖3b)。儘管Google團隊的LSTM實現了這一點,但它無法擴展到更大的碼距。
使用與實驗數據匹配的噪聲模型(pij或XEB DEMs)樣本進行預訓練比使用設備無關的SI1000(圖3c)表現更好。
pij DEMs是為匹配基於匹配和張量網絡解碼器而設定的相同噪聲模型。
在此先驗下,AlphaQubit達到了與張量網絡解碼器相同的水平(在誤差範圍內)。
作者還注意到,即使在使用SI1000樣本進行預訓練且沒有任何微調的情況下,AlphaQubit在碼distance-5時也達到了與MWPM-BP相同的水平。
使用有限的實驗數據進行微調可以減少與良好匹配的(pij和XEB)和一般性(SI1000)先驗預訓練的模型之間的LER差距;並將所有模型的LER提升到遠超張量網絡解碼器(圖3c)。
 圖3:3×3和5×5 Sycamore實驗中每輪的邏輯錯誤率
圖3:3×3和5×5 Sycamore實驗中每輪的邏輯錯誤率Scaling AlphaQubit,10萬輪模擬實驗強泛化
為了瞭解AlphaQubit如何適應具有更低錯誤率的大型設備,Google使用模擬量子系統的數據對其進行了訓練,這些系統最多包含241個量子比特,因為這超過了Sycamore平台的現有能力。
同樣,AlphaQubit的性能優於領先的算法解碼器,這表明它在未來也能應用於中型量子設備。
如下,折線圖顯示兩個解碼器的準確性隨著碼距的增加而提高,在更高的規模上幾乎達到100%,其中 AlphaQubit表現最佳。
AlphaQubit還展示了高級功能,例如能夠接受和報告輸入和輸出的置信水平。這些信息豐富的接口可以幫助進一步提高量子處理器的性能。
在使用包含多達25輪糾錯的樣本訓練AlphaQubit時,它在多達100,000輪的模擬實驗中保持了良好的性能,顯示出其在超出訓練數據的場景中的泛化能力。

不同規模/模擬實驗的解碼準確率(distance-3為17個量子比特,distance-11為241個量子比特),張量網絡解碼器因為運行太慢所以不在圖中
邁向實用量子計算,預定下個諾獎?
AlphaQubit代表了使用機器學習進行量子糾錯的一個重要里程碑。
它為機器學習解碼領域設立了一個基準,並開闢了在真實量子硬件中使用高精度機器學習解碼器的前景。
在distance-11時,訓練似乎更具挑戰性,並且需要增加數據量。
儘管根據團隊經驗,通過訓練和架構改進可以顯著提高數據效率,但在超過distance-11上展示高精度仍然是未來工作需要解決的重要步驟。

此外,解碼器需要實現每輪1微秒的吞吐量以用於超導量子比特和1毫秒用於囚禁離子設備。提高吞吐量仍然是機器學習和基於匹配的解碼器的重要目標。
雖然AlphaQubit的吞吐量慢於1微秒的目標,但可以應用一系列已建立的技術來加速,包括知識蒸餾、低精度推理和權重剪枝,以及在定製硬件中的實現。
作為一種機器學習模型,AlphaQubit最大的優勢在於其從真實實驗數據中學習的能力。
這使它能夠利用代表I/Q噪聲和泄漏的豐富輸入,而無需為每個特徵手動設計特定算法。這種利用可用實驗信息的能力展示了機器學習在更廣泛的科學問題解決中的優勢。
隨著量子計算朝著商業相關應用所需的潛在數百萬量子比特發展,Google還需要找到更有效的數據方法來訓練基於AI的解碼器。
參考資料:
https://blog.google/technology/google-deepmind/alphaqubit-quantum-error-correction/
https://www.nature.com/articles/s41586-024-08148-8