全球十億級軌跡點驅動,首個軌跡基礎大模型來了
機器之心報導
機器之心編輯部
在智慧城市和大數據時代背景下,人類軌跡數據的分析對於交通優化、城市管理、物流配送等關鍵領域具有重要意義。然而,現有的軌跡相關模型往往受限於特定任務、區域依賴、軌跡數據規模和多樣性睏乏等問題,限制了模型的泛化能力和實際應用範圍。近日,來自於香港科技大學(廣州)、南方科技大學、香港城市大學的聯合研究團隊整理了首個全球大規模軌跡數據集 WorldTrace,並基於該數據集訓練了首個世界軌跡基礎大模型 UniTraj,為交通領域內構建通用時空智能提供了一種全新的思路。
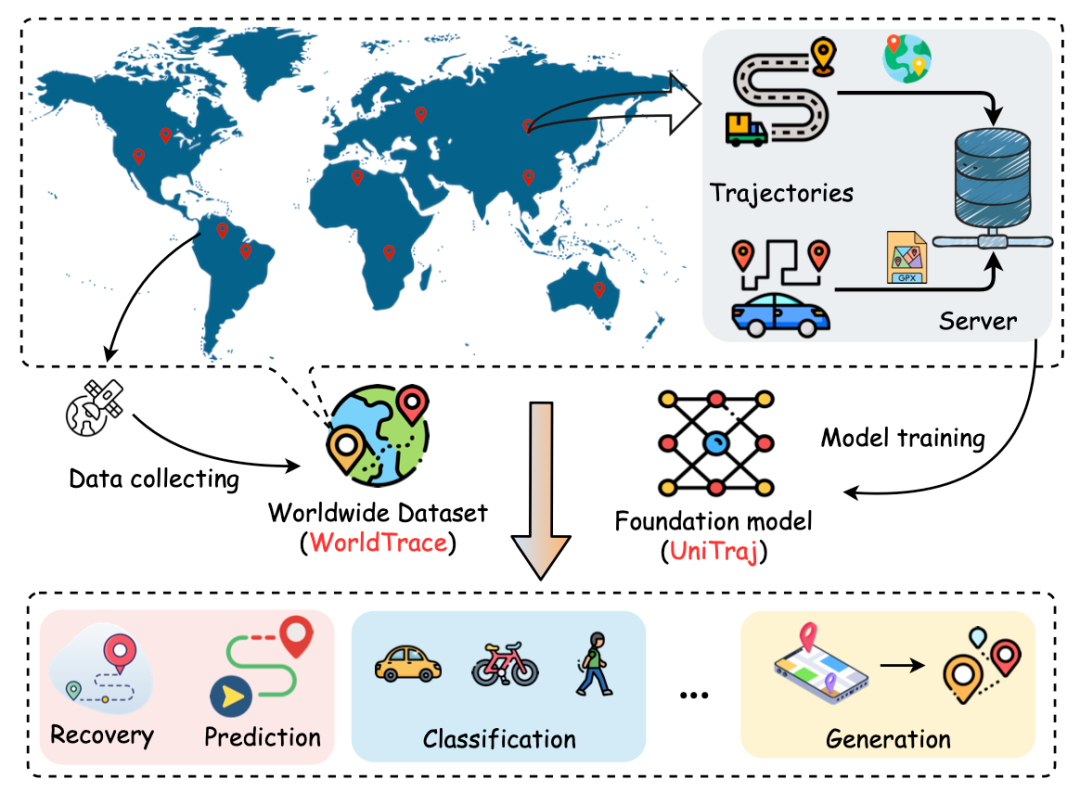
研究團隊提出了軌跡基礎模型的構建範式,旨在通過其模型架構設計和數據集支撐的流程,克服現有方法的局限性,實現跨任務、跨區域的泛化能力,並在不同數據質量下保持魯棒性。具體來說,研究團隊首先收集了一個全球範圍的 WorldTrace 軌跡數據集,涵蓋 70 個國家和地區,包括 245 萬條軌跡和十億級別的軌跡數據點。這為構建軌跡基礎模型提供了充足且豐富的數據支持。進一步,研究團隊設計並預訓練了 UniTraj 這樣一個通用的軌跡基礎模型結構,並集成了多種重采樣和掩碼策略,能夠有效支撐不同區域、任務和數據質量的需要。

論文地址:https://arxiv.org/pdf/2411.03859
主要解決的問題
-
任務特異性:現有方法通常為特定任務設計,缺乏跨任務的靈活性。UniTraj 能夠適應不同的應用,無需大量修改。
-
區域依賴性:許多模型在特定地理區域之外效果不佳。UniTraj 通過全球數據訓練,減少了對特定區域數據的依賴。
-
數據質量敏感性:現實世界中的軌跡數據質量參差不齊,現有模型對這些不一致性很敏感。UniTraj 能夠有效處理不同質量的軌跡。
主要研究內容及貢獻
為瞭解決上述問題,這項研究開創了構建軌跡基礎模型的新範式,分別從數據準備和模型設計兩個方面進行展開。
WorldTrace 數據集
該研究最顯著的貢獻是構建了首個大規模、高質量、全球範圍分佈的軌跡數據集,名為 WorldTrace,並首次實現了全球範圍的軌跡數據收集與整合。
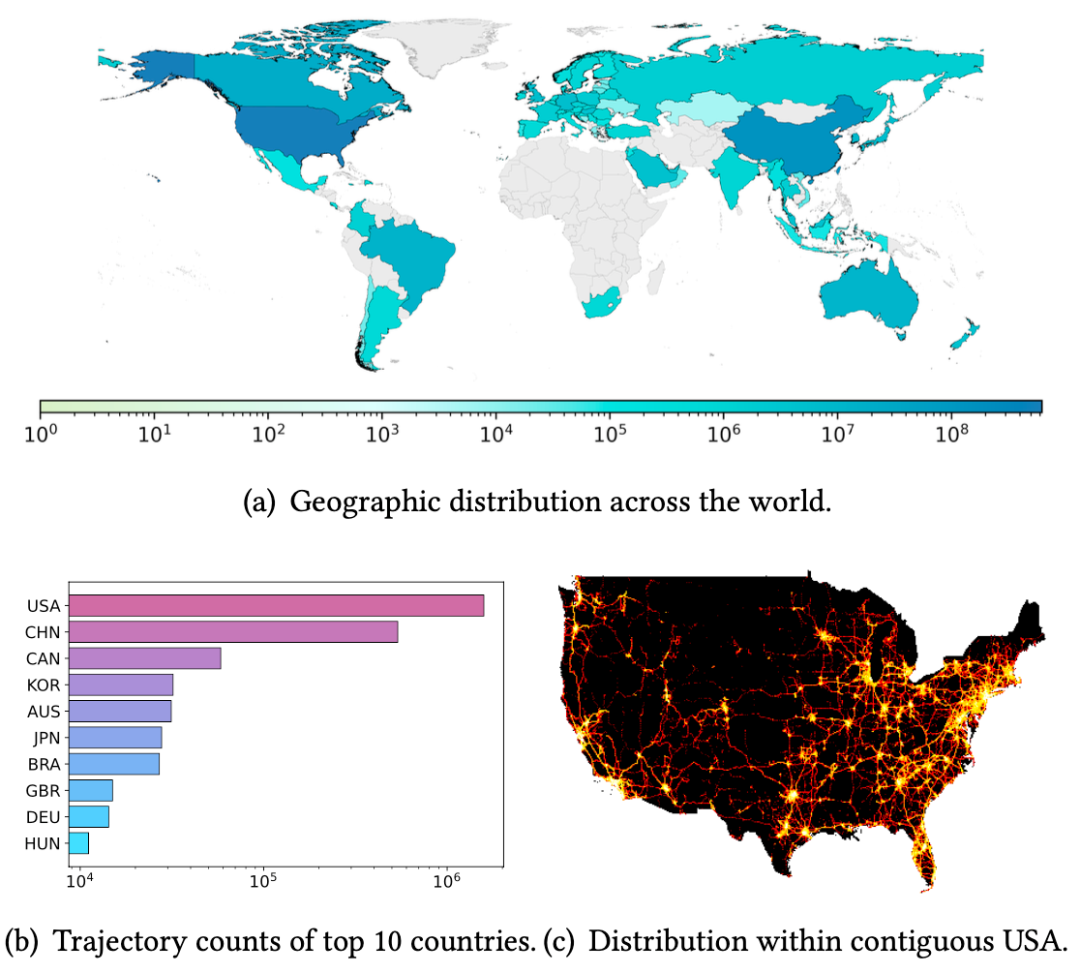
上圖展示了 WorldTrace 數據集的地理分佈,該數據集在北美、東亞和歐洲部分地區有較為密集分佈,涵蓋了發達和新興經濟地區,其中美國、中國提供了較多的軌跡數據。從地理分佈上來說,這突顯了數據集中的軌跡模式的多樣性,能夠反應不同交通基礎設施和地理環境。此外,通過美國本土的數據密度也進一步展示了主要公路網絡和城市中心的高解像度覆蓋。進一步說明了該數據在開發獨立於區域和通用軌跡基礎模型的潛力。
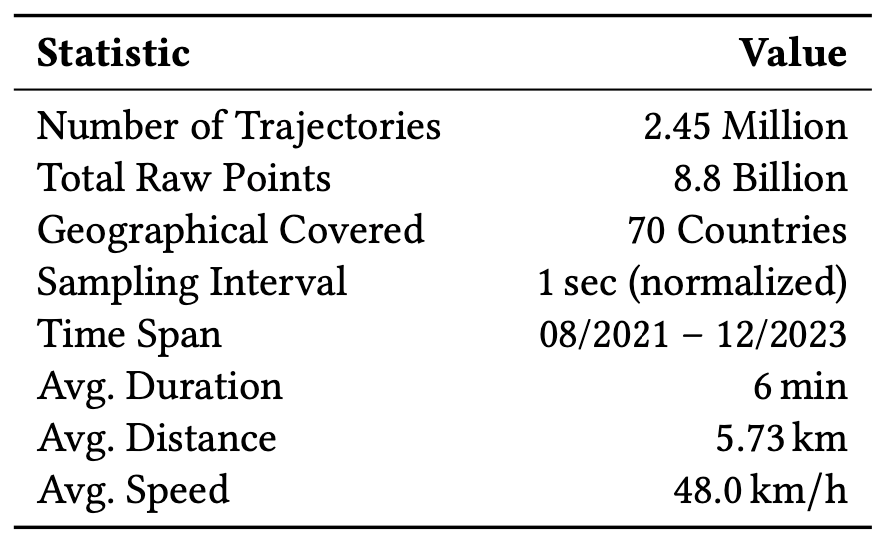
通過作者進一步對原始數據進行規範和校正處理,表中統計了這項研究使用的數據的主要特徵。在軌跡規模上,可以看到 WorldTrace 主要包含 245 萬條軌跡,8.8 億個采樣軌跡點 (采樣頻率規範到 1 秒後),並覆蓋 70 了個國家和地區。在數據質量上,WorldTrace 數據集的時間跨度從 2021 年 8 月開始,一直持續到 2023 年 12 月,提供了長時間範圍和及時的數據樣本,能夠進一步增強該數據集的應用價值。
構建軌跡基礎模型 UniTraj
在模型的架構設計上,UniTraj 採用了靈活的編碼器 – 解碼器架構,為了提升模型的計算效率、魯棒性和對各種數據質量的適應能力,作者在模型訓練過程中進一步集成了一系列的重采樣策略和掩碼策略。
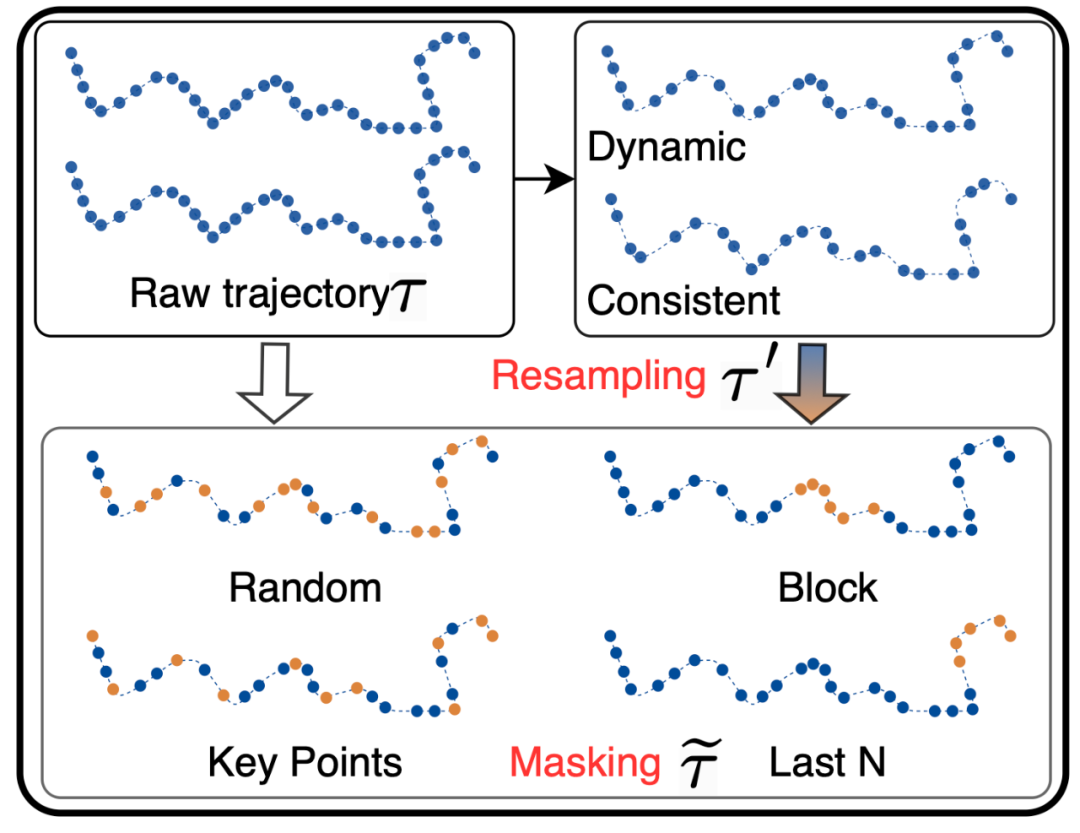
重采樣策略
這項研究主要設計了兩種重采樣策略:
-
第一種是基於對數采樣率衰減的隨機動態重采樣策略,根據軌跡長度動態調整采樣率。動態重采樣策略主要應用於解決兩個問題,第一是控制數據冗餘、減少模型的計算成本;第二是對軌跡數據進行隨機重采樣,可以得到不同時間間隔的軌跡點,這對增加軌跡數據的多樣性至關重要。
-
第二種采樣策略是基於軌跡采樣頻率的間隔一致性重采樣策略,其核心思想是將原始軌跡調整為一個隨機的固定采樣率,以適應不同的設備和場景需要,同時也能夠顯著降低軌跡點的數量。
掩碼策略
由於 UniTraj 使用重構式預訓練的方法來提升模型對軌跡局部和全局模式建模能力。在預訓練過程中,作者設計了 4 種掩碼策略,而模型的目標是恢復這些被掩蔽的軌跡點,從而幫助模型更好地理解和捕捉軌跡序列的時空關係。
-
隨機掩碼:按照一定的比率,隨機掩蓋一定數量的軌跡點。隨機掩碼訓練模型捕獲一般時空模式,增強其對缺失數據點的魯棒性。
-
塊狀掩碼:掩蓋軌跡內的連續數量點,模擬連續數據段可能缺失的場景。這對於訓練模型處理長期依賴或者長距離關係較為有效,使模型重建可能由於傳感器故障、低采樣率、或暫時通信丟失而發生的缺失段。
-
關鍵點掩碼:關鍵點掩碼關注軌跡中重要的軌跡點(例如轉彎或速度或方向明顯變化)。這裏,作者使用 RDP 算法來識別這些關鍵點,從而加強了模型對軌跡內關鍵結構模式的理解。
-
最後點掩碼:此策略會屏蔽軌跡的最後 N 個點,模擬未來點不可用且必須從觀察到的數據推斷的場景。
模型架構
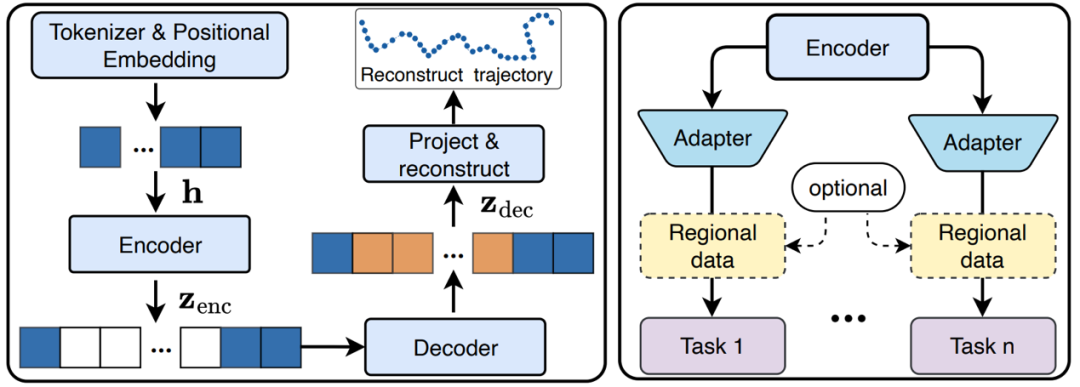
在模型架構設計方面,UniTraj 首先將重采樣和掩碼處理後的軌跡轉換為結構化的嵌入,並利用 Transformer 塊和旋轉位置編碼(RoPE)來捕捉軌跡中的時空關係。編碼器負責學習可見點的壓縮表示,而解碼器則基於這些表示來重建被掩碼的點,實現軌跡的精確重建和預測。對於訓練過程,模型使用重建目標進行訓練,旨在最小化預測點和原始點之間的差異。在推理和下遊任務應用中,預訓練的 UniTraj 編碼器可以作為通用特徵提取器,通過簡單的適配器訓練,即可支持多種軌跡相關的分析任務,如分類、預測和異常檢測等。
實驗驗證
為了測試 UniTraj 模型的性能,研究團隊設計了一系列實驗,旨在評估模型在處理真實世界軌跡數據時的準確性和泛化能力。研究團隊選擇了多個具有不同地理覆蓋、數據質量和采樣率的真實世界軌跡數據集進行實驗。這些數據集包括但不限於 WorldTrace 數據集,以及其他公開可用的數據集,如成都、西安、GeoLife 等。實驗設計考慮了零樣本和少樣本學習場景,以評估模型在未見過的數據上的適應性。實驗主要圍繞以下幾個方面進行:
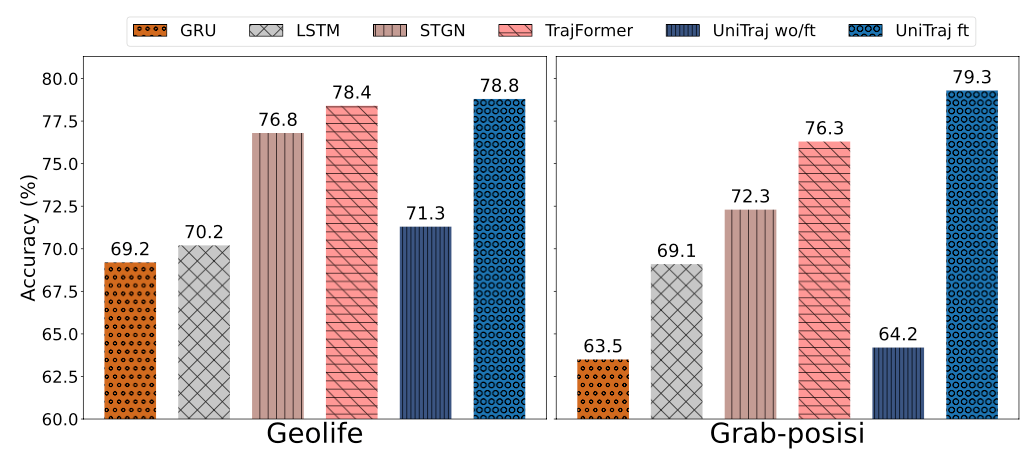
1. 任務適用性分析:評估 UniTraj 在軌跡恢復、預測、分類和生成等不同任務上的表現,以及其在零樣本和少樣本學習場景中的適應性。
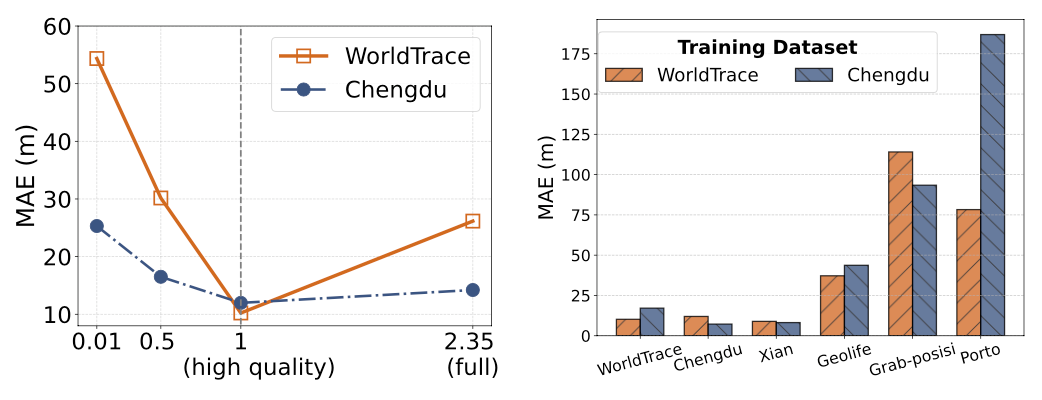
2. 數據集研究:比較 UniTraj 在 WorldTrace 數據集和其他公開數據集上的訓練效果,分析數據規模和質量對模型性能的影響。
3. 模型研究:探討 UniTraj 模型中不同組件和參數設置對性能的影響,包括編碼器塊的數量、掩碼比例等。
總結
UniTraj 這項研究提出了數據 + 模型的基礎模型構建範式。在數據準備方面,其首次構建了一個全球範圍的軌跡數據集,並且提供了大規模和高質量的軌跡數據用於訓練。在模型設計方面,其通過重采樣和掩碼策略,集成軌跡處理模塊和靈活的編碼器 – 解碼器架構,有效地捕捉了軌跡數據中的複雜時空依賴性以應對各種不同的數據質量。這一模型的提出,為處理大規模、多樣化的軌跡數據提供了新的工具,帶來了新的思路。