大模型不會推理,為什麼也能有思路?有人把原理搞明白了
機器之心報導
編輯:澤南、杜偉
大模型不會照搬訓練數據中的數學推理,回答事實問題和推理問題的「思路」也不一樣。
大語言模型的「推理」能力應該不是推理,在今年 6 月,一篇 Nature 論文《Language is primarily a tool for communication rather than thought》曾引發 AI 社區的大討論,改變了我們對於 AI 智力的看法。
該論文認為人類語言主要是用於交流的工具,而不是思考的工具,對於任何經過測試的思維形式都不是必需的。圖靈獎獲得者 Yann LeCun 對此還表示,無論架構細節如何,使用固定數量的計算步驟來計算每個 token 的自回歸 LLM 都無法進行推理。
那麼,大模型的「推理」行為到底是在做什麼呢?本週四,一篇來自倫敦大學學院(UCL)等機構的研究《Procedural Knowledge in Pretraining Drives Reasoning in Large Language Models》詳細探討了大語言模型(LLM)在執行推理任務時採用的泛化策略類型,得出的結論給我們了一些啟發。
大模型的「推理」是在做什麼?
一個普遍的猜測是:大模型的推理難道是在從參數知識中檢索答案?該研究給出了反對這一觀點的證據。作者認為,是預訓練中的程序性知識在推動大模型進行推理。
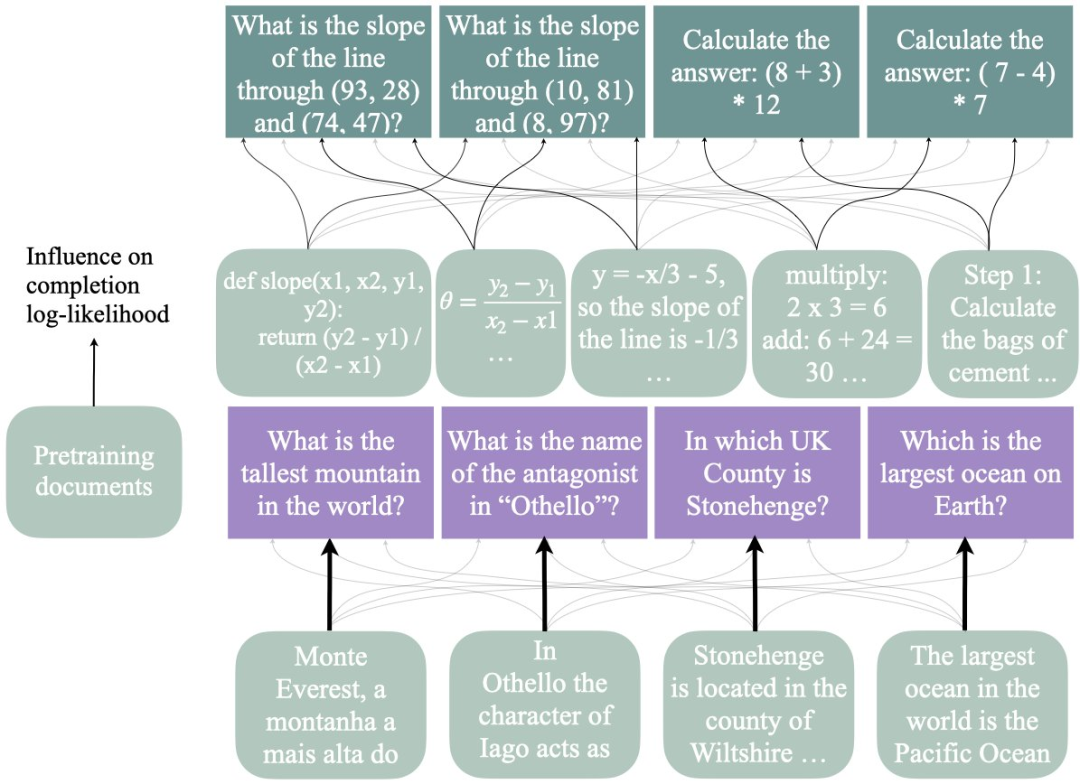
自從大模型出現以來,AI 研究領域一直流傳著這樣一種假設:當大模型在進行推理時,它們進行的是某種形式的近似檢索,即從參數知識中「檢索」中間推理步驟的答案,而不是進行「真正的」推理。
考慮到大模型所訓練的數萬億個 token、令人印象深刻的記憶能力、評估基準的數據汙染問題已得到充分證實,以及大模型推理依賴於 prompt 的性質,這種想法看起來似乎是合理的。
然而,大多數研究在得出結論認為模型不是真正推理時,並沒有進一步去研究預訓練數據。在新的工作中,人們希望探索一個命題:即使推理步驟的答案就在數據中,模型在生成推理軌跡時是否會依賴它們?
作者使用影響函數來估計預訓練數據對兩個 LLM(7B 和 35B)完成事實問題回答(下圖左)的可能性,以及簡單數學任務(3 個任務,其中一個顯示在右側)的推理軌跡的影響。

令人驚訝的是,研究發現的結果與我們的想法相反:LLM 使用的推理方法看起來不同於檢索,而更像是一種通用策略——從許多文檔中綜合程序性知識並進行類似的推理。
新論文的一作、UCL 在讀博士 Laura Ruis 表示,該研究是基於對 5M 預訓練文檔(涵蓋 25 億個 token)對事實問題、算術、計算斜率和線性方程的影響的分析。總而言之,他們為這項工作做了十億個 LLM 大小的梯度點積。
接下來還有幾個問題:大模型是否嚴重依賴於特定文檔來完成任務,或者文檔是更有用,還是總體貢獻較少?前者適合檢索策略,後者則不適合。
通過實驗可以看到,模型在生成推理痕跡時對單個文檔的依賴程度低於回答事實問題(下圖箭頭粗細表示)時對單個文檔的依賴程度,並且它們所依賴的文檔集更具通用性。
對於事實問題,答案往往表現出很大的影響力,而對於推理問題則不然(見下圖底行)。此外,該研究發現的證據表明代碼對推理既有正向影響,也有反向的影響。
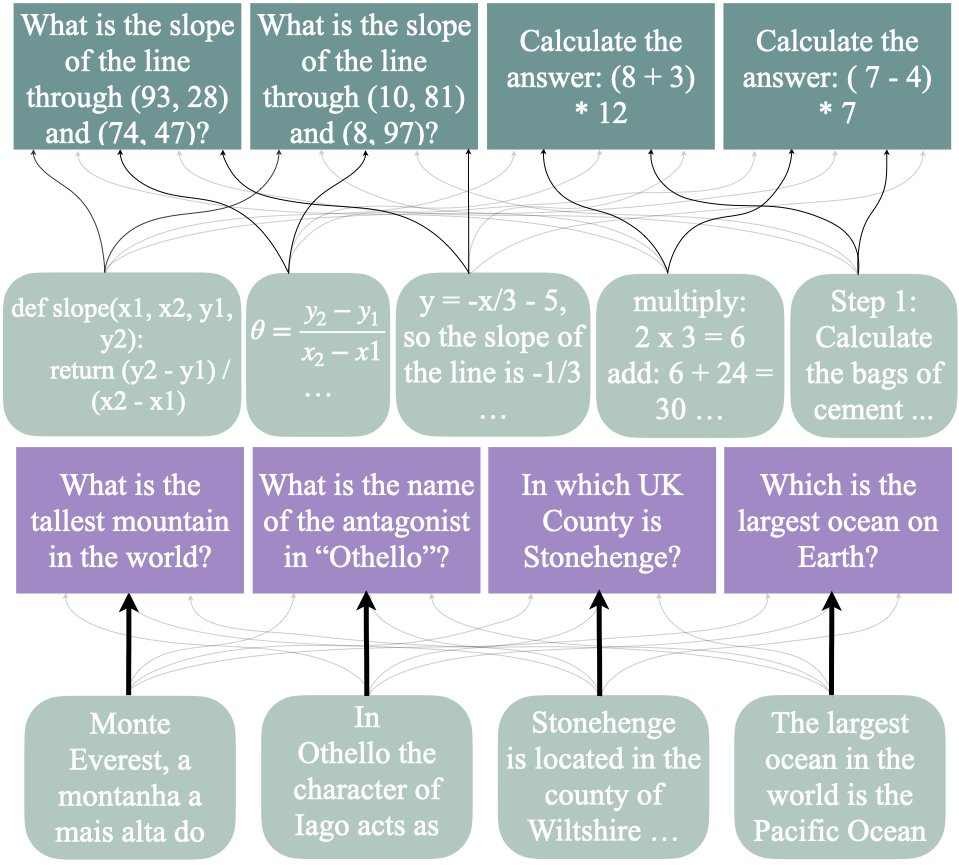
另外,看文檔對查詢推理軌跡的影響可以較容易地預測出該文檔對具有相同數學任務的另一個查詢的影響,這表明影響力會吸收文檔中用於推理任務的程序性知識。
因此可以得出結論,大模型通過應用預訓練期間看到的類似案例中的程序性知識(procedural knowledge)進行推理。這表明我們不需要在預訓練中涵蓋所有可能的案例——專注於高質量、多樣化的程序數據可能是更有效的策略。
該研究可能會改變我們對於 LLM 推理的看法。Laura Ruis 表示,很期待見證這種程序泛化風格的發現,對於更大的模型,或潛在的不同預訓練數據分割等方向的影響。

論文鏈接:https://arxiv.org/abs/2411.12580
實驗設置
模型選擇
研究者選擇了兩個不同體量的模型(7B 和 35B),分別是 Cohere 的 Command R 系列的基礎和監督微調版本。其中,他們使用基礎模型估計二階信息並計算文檔梯度,並使用監督指令微調模型生成完成並計算查詢梯度。
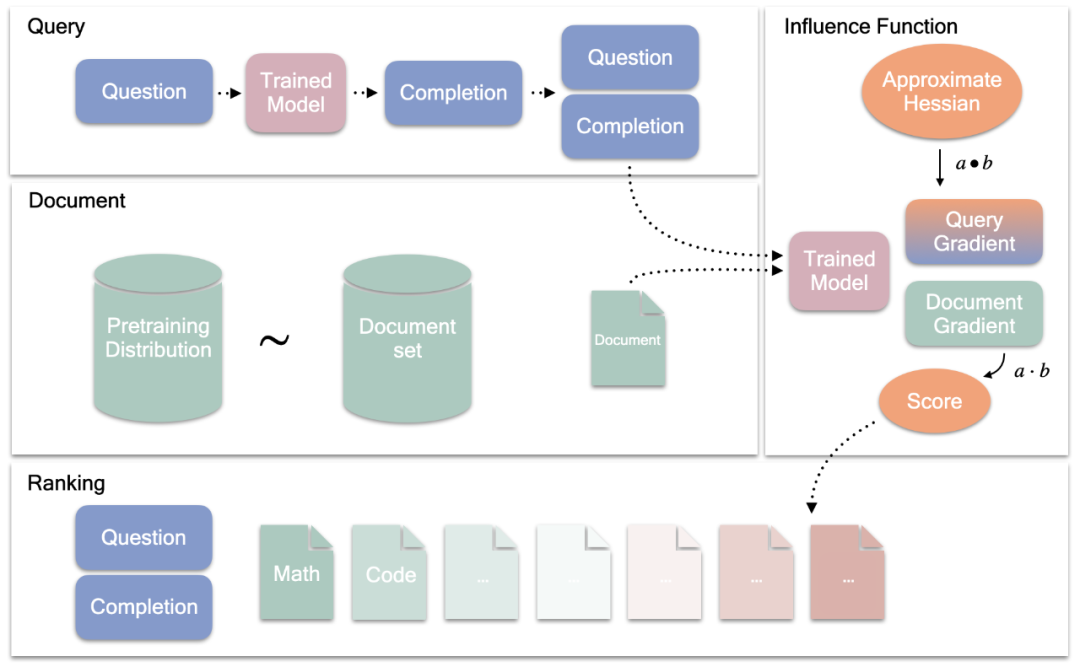
查詢設置
研究者收集了一個包含不同類型問題的查詢集,其中 40 個推理問題,40 個事實問題。
對於推理問題,他們確定了兩種數學推理類型,每種模型都可以使用零樣本 CoT 來穩健地完成。研究者在包含每種推理類型的 100 個問題的更大集合上對模型進行評估,並選擇了至少 80% 正確率的任務。
這為 7B 模型提供了簡單的兩步算法(如下表 1 所示),並為 35B 模型求解線性方程中的 x(如下表 9 所示)。研究者確保沒有查詢需要輸出分數。並且,為了使 7B 和 35B 模型之間的結果更具可比性,他們對這兩個模型使用了相同的斜率問題。


對於 40 個事實問題,研究者確保模型一半回答正確,一半錯誤,從而能夠識別從參數知識中檢索事實的失敗。
文檔設置
研究者想要比較預訓練數據對不同大小模型(7B 和 35B)推理的影響,因此他們選擇了兩個在相同數據上訓練的模型。其中,每個模型只需要對 Hessian 進行一次 EK-FAC 估計,但公式 1 中的其他項要求每個文檔 – 查詢對通過模型進行兩次前向和後向傳遞。
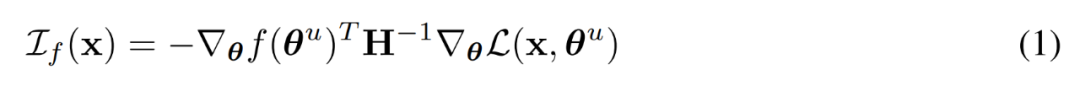
為瞭解決這個問題,研究者從預訓練數據中抽取了一組文檔,這些文檔涵蓋了預訓練期間看到的每個批次的多個示例,總共 500 個文檔(約 25 億 token),其分佈與訓練分佈相似。
EK-FAC 估計
為了估計 7B 和 35B 模型的 Hessian,研究者通過對兩個模型進行預訓練,隨機抽取了 10 萬份均勻分佈的文檔。
實驗結果:五大發現
為了回答上述關於 LLM 推理泛化的問題,研究者進行了定量和定性分析,並得出了以下五大發現。
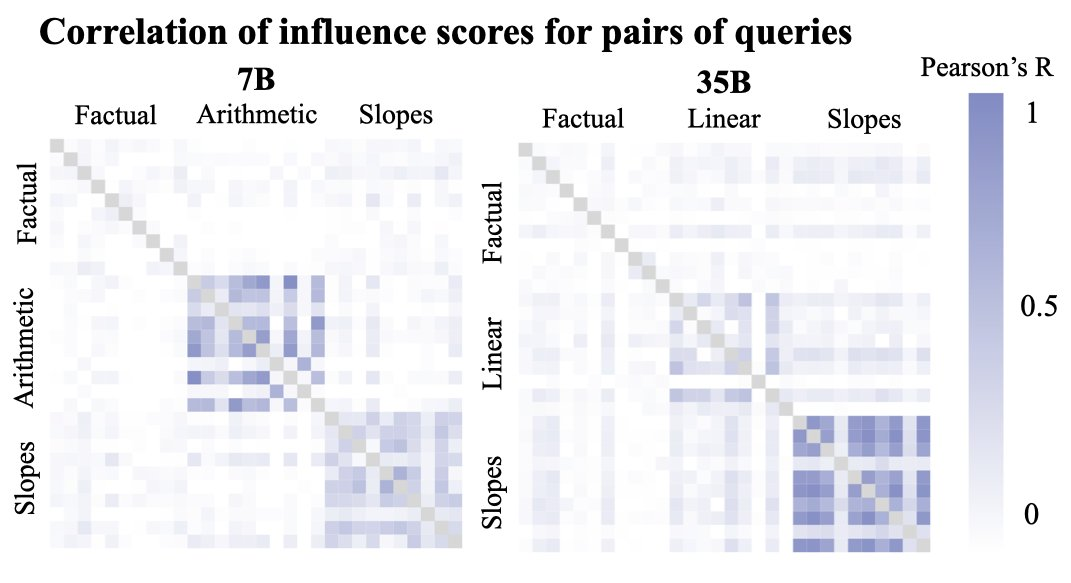
發現 1:對於具有相同底層推理任務的查詢,文檔的影響力得分之間存在顯著的正相關性,表明了這些文檔與「需要對不同數字應用相同程序」的問題相關。
研究者計算了所有 500 萬個文檔得分對於所有查詢組合的 Pearson R 相關性(每個模型有 802 個相關性)。下圖右顯示了每個任務 10 個查詢的子樣本結果。
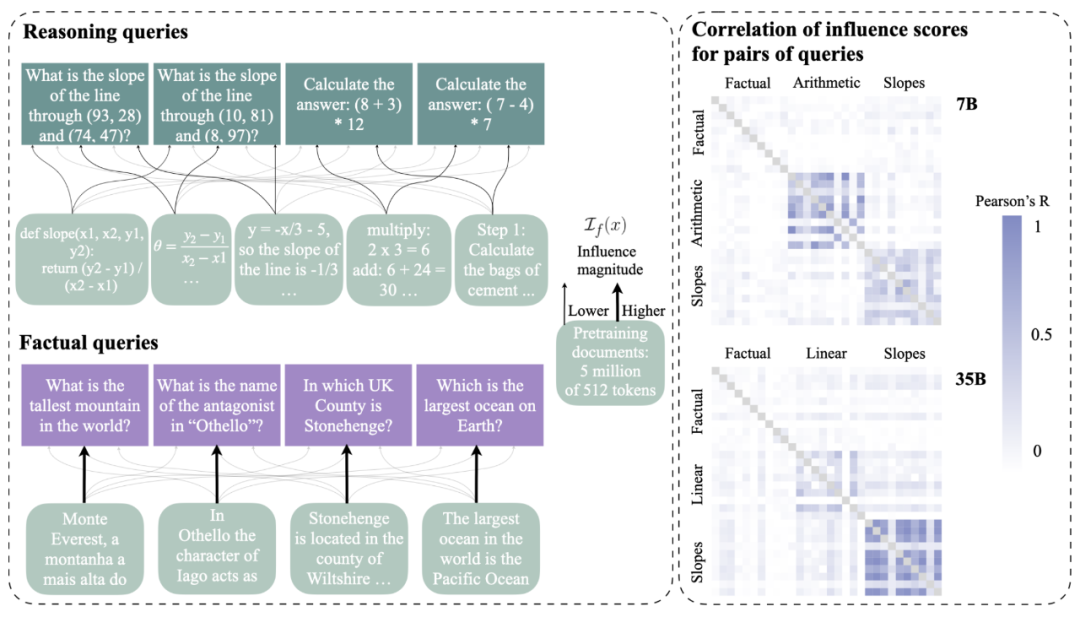
他們還發現,相同推理類型的很多查詢之間存在非常顯著的正相關性(p 值均低於 4e – 8),而大多數(但不是全部)事實查詢或其他組合(例如不同類型的推理查詢)之間存在非常顯著的相關性缺失(p 值均在 4e – 3 左右)。這意味著許多文檔對同一類型的推理具有類似的影響。

發現 2:在推理時,模型對每個文檔的依賴程度平均低於回答事實問題時對每個生成信息量的依賴程度,總體影響幅度波動性要小得多,表明它是從一組更一般的文檔中泛化出來的。模型越大,效果越明顯。下圖 2 展示了對排名中不同百分數正向部分的總影響。
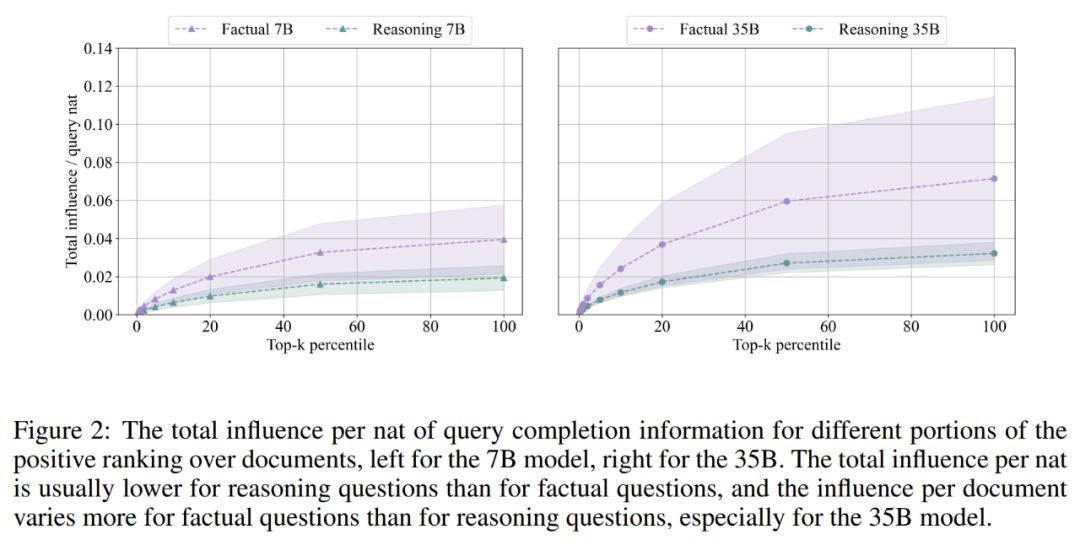
結果描述了 top-k 百分位正向排名文檔中包含的總影響力,比如第 20 個百分數包含了一個查詢的 20% 正向文檔,顯示的總影響力是截止到該部分排名的所有文檔影響力的總和。
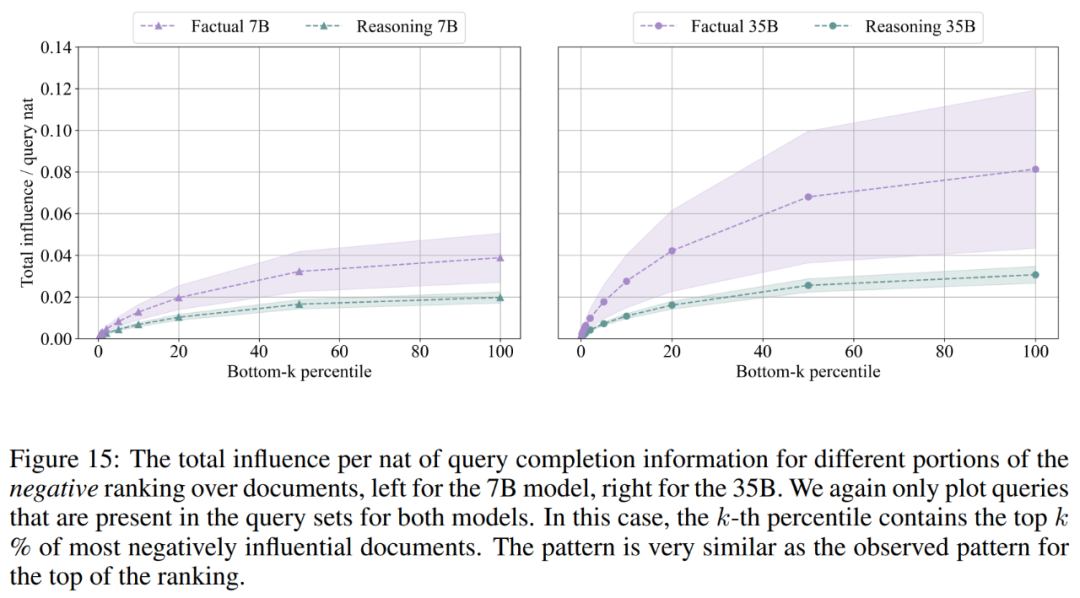
發現 3:事實問題的答案在對問題 top 影響力的文檔中出現的頻率相對較高,而推理問題的答案几乎沒有在對它們 top 影響力的文檔中出現過。

如下圖 3 所示,對於 7B 模型,研究者在 55% 的事實查詢的前 500 個文檔中找到了答案,而推理查詢僅為 7.4%。對於 35B 模型,事實查詢的答案在 top 影響力文檔中出現的概率為 30%,而推理集的答案從未出現過。
發現 4:對推理查詢有影響力的文檔通常採用類似的逐步推理形式,如算術。同時有影響力的文檔通常以代碼或一般數學的形式實現推理問題的解決方案。
總的來說,研究者在 top 100 份文檔中手動找到了 7 個以代碼實現斜率的獨特文檔,以及 13 個提供計算斜率方程式的文檔。其中,7B 模型依賴其中 18 個文檔來完成其補全(這意味著 18 個不同的文檔出現在所有查詢的 top 100 份文檔中),而 35B 模型則依賴 8 個文檔。
下圖分別是一個以 JavaScript(左)和數學(右)實現解決方案的極具影響力的文檔示例。

發現 5:對於事實查詢,最有影響力的數據來源包括域奇百科和小知識;而推理查詢的主要來源包括數學、StackExchange、ArXiv 和代碼。
總而言之,該研究結果表明,LLM 實際上可以從預訓練數據中學習一種通用的推理方法,並且可以從數據中的程序性知識中學習。此外,人們發現沒有任何證據表明模型依賴於預訓練數據中簡單數學推理步驟的答案。這意味著近似檢索假設並不總是正確的,這對未來人工智能的設計具有重要意義。
也就是說,我們可能不需要專注於覆蓋預訓練數據中的每種情況,而是可以專注於數據應用和演示各種推理任務的程序。
這份研究結果表明,LLM 實際上可以從預訓練數據中學習一種通用的推理方法,並且可以從數據中的程序性知識中學習。此外,人們沒有發現任何證據表明模型依賴於預訓練數據中簡單數學推理步驟的答案。這意味著近似檢索假設並不總是正確的,這對未來 AI 的設計具有意義。
也就是說,我們可能不需要專注於覆蓋預訓練數據中的每種情況,而是可以專注於數據應用和演示各種推理任務的程序。
更多技術細節與實驗結果請參閱原論文。
參考內容:
https://www.reddit.com/r/MachineLearning/comments/1gvveu8/r_procedural_knowledge_in_pretraining_drives/
https://lauraruis.github.io/2024/11/10/if.html
https://x.com/LauraRuis/status/1859267739313185180



















