DeepSeek等團隊新作JanusFlow: 1.3B大模型統一視覺理解和生成
Janus團隊 投稿自 凹非寺
量子位 | 公眾號 QbitAI
在多模態AI領域,基於預訓練視覺編碼器與MLLM的方法(如LLaVA系列)在視覺理解任務上展現出卓越性能。
而基於Rectified Flow的模型(如Stable Diffusion 3及其衍生版本)則在視覺生成方面取得重大突破。
能否將這兩種簡單的技術範式統一到單一模型中?
來自DeepSeek、北大、香港大學以及清華大學的團隊研究表明:
在LLM框架內直接融合這兩種結構,就可以實現視覺理解與生成能力的有效統一。

模型架構
簡單來說,JanusFlow將基於視覺編碼器和LLM的理解框架與基於Rectified Flow的生成框架直接融合,實現了兩者在單一LLM中的端到端訓練。
其核心設計包括:(1)採用解耦的視覺編碼器分別優化理解與生成能力;(2)利用理解端編碼器對生成端特徵進行表徵對齊,顯著提升RF的訓練效率。基於1.3B規模的LLM,JanusFlow在視覺理解和生成任務上均超過此前同規模的統一多模態模型。

在LLM基礎上,JanusFlow加入了如下組件:
1、視覺理解編碼器(圖中的Und. Encoder):我們使用SigLIP將輸入的圖片轉換成Visual embeddings;專注於視覺理解任務的特徵提取。
2、視覺生成編解碼器(圖中的Gen. Encoder/Decoder):輕量級模塊,總參數量約70M;基於SDXL-VAE的latent space進行生成;編碼器:利用雙層ConvNeXt Block將輸入latent z_t 轉換為visual embeddings;解碼器:通過雙層ConvNeXt Block將處理後的embeddings解碼為latent space中的速度v 。
3、注意力機制:在我們的初步實驗中,我們發現生成任務中causal attention和bidirectional attention效果相當;基於效率和簡潔性考慮,統一採用causal attention處理兩類任務。
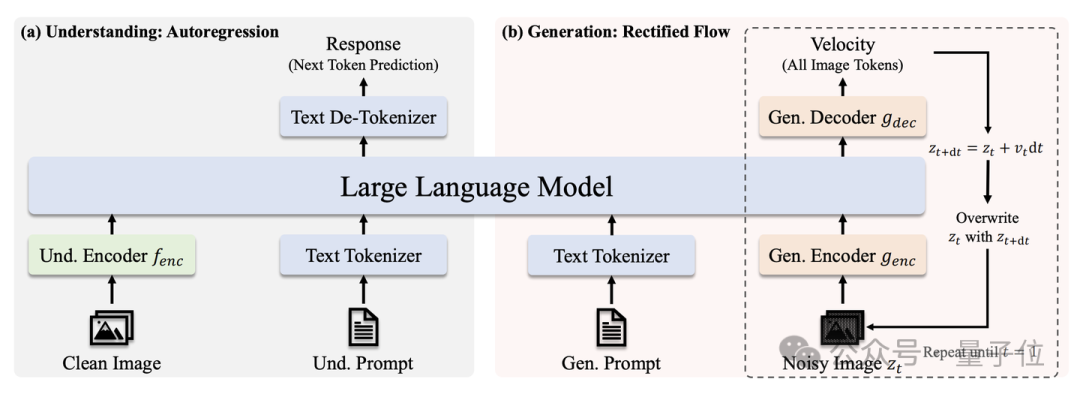
JanusFlow有兩種生成模式:
1、視覺理解(文+圖->文):此時,JanusFlow的推理模式是正常的自回歸模式,通過預測下一個token來生成回覆
2、圖片生成(文->圖):此時,JanusFlow的推理模式是採用歐拉法求解Rectified Flow學出的ODE,從t=0的純噪聲逐步推進到t=1的乾淨圖像。我們在生成過程中使用Classifier-Free Guidance並把迭代步數設置為30步。
方法與設計
1、三階段訓練策略
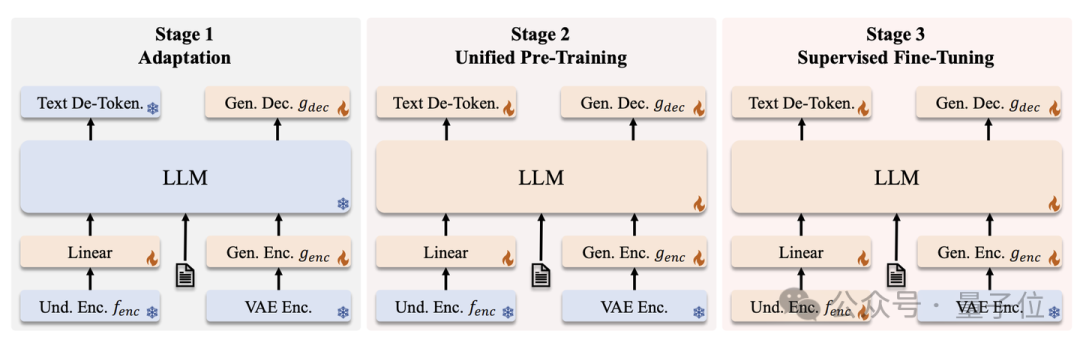
我們的訓練分為 Adaptation,Pre-Training 和 Supervised Fine-Tuning三階段。我們的訓練數據包括視覺理解(圖生文)和視覺生成(文生圖)兩類。特別地,由於發現RF收斂速度顯著慢於AR,我們在預訓練階段採用了非對稱的數據配比策略(理解:生成=2:8),實驗證明該配比能夠有效平衡模型的兩方面能力。詳細訓練流程和數據配置請見論文。
2、解耦理解與生成的視覺編碼器
在之前結合LLM與Diffusion Model訓練統一多模態模型的嘗試中,理解與生成任務通常採用同一個視覺編碼器(如Show-O [1] 中理解和生成均採用MAGVIT-v2將圖片轉換成離散token,Transfusion [2] 中理解和生成均採用latent space里的U-Net Encoder),往往導致理解和生成任務在視覺編碼層面的衝突。在我們的上一個工作 Janus [3] 中證實了對多模態理解和生成任務的編碼器進行解耦能有效緩解衝突,提升模型的整體性能。在 JanusFlow 中,我們沿用了這一設計。我們進行了一系列的消融實驗探究了不同視覺編碼器策略的影響,證實為理解和生成任務分別配置專用編碼器能夠顯著提升整體性能。
3、表徵對齊(Representation Alignment)
正如之前提到的,由於RF的訓練收斂速度顯著慢於AR,JanusFlow的訓練開銷較大。得益於我們解耦了理解與生成的編碼器,我們可以使用REPA [4] 的方法來加速RF訓練的收斂速度。具體而言,我們在生成數據的訓練中要求視覺編碼器提取的訓練圖片 x 的特徵與其加噪樣本 z_t 在LLM中的中間層特徵對齊。實驗表明,該方法在僅增加少量計算開銷的情況下,顯著提升了生成任務的收斂效率。
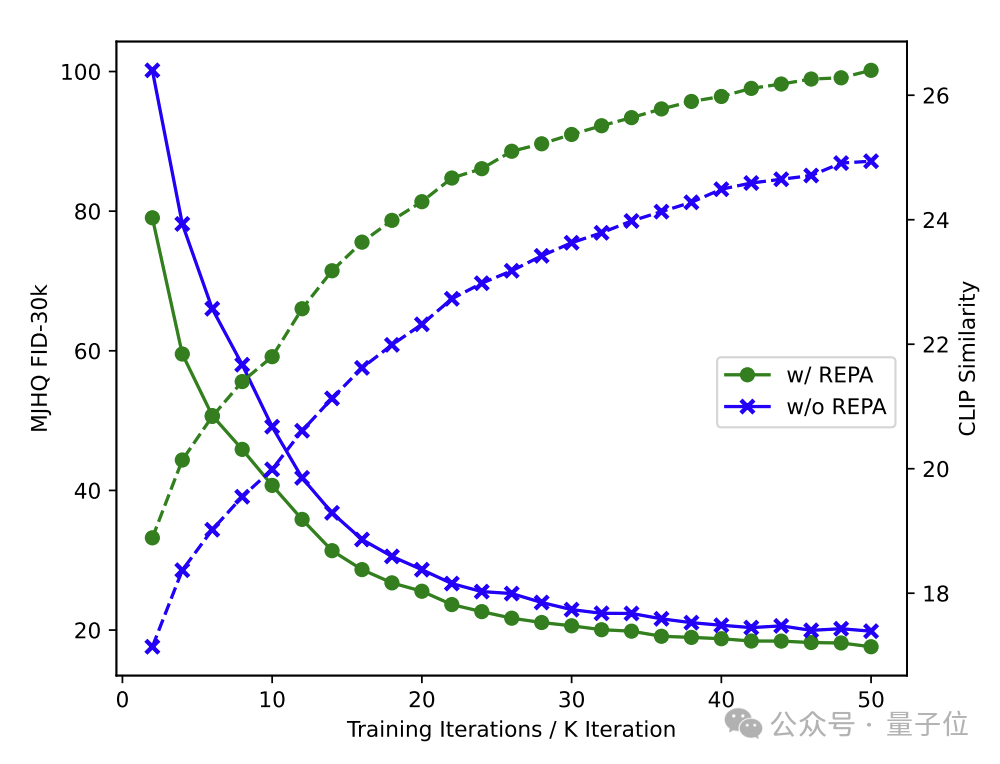
(綠線:使用REPA;藍線:不使用REPA。使用REPA可以顯著加速FID的降低(與圖像質量相關)和CLIP score的升高(與文生圖模型的語義準確度相關)。)
4、消融實驗
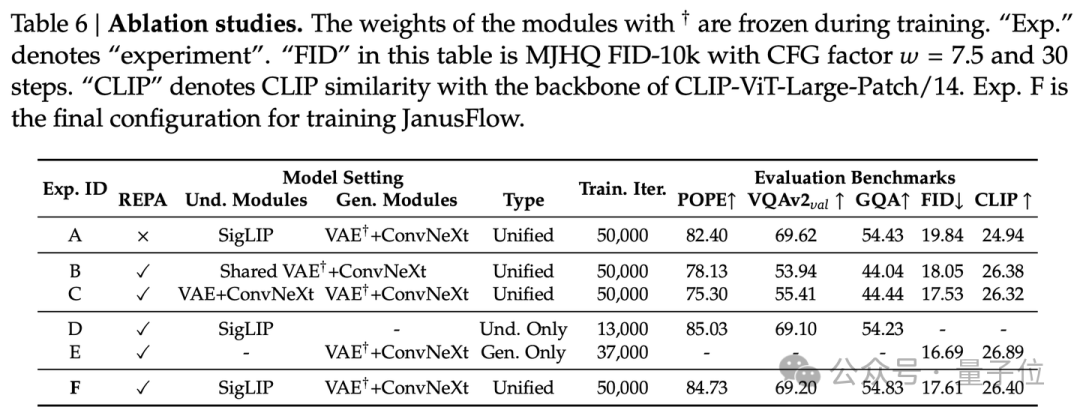
我們設計了六組對照實驗以驗證模型各組件的有效性:
A、不使用REPA,理解模塊是SigLIP,生成模塊是SDXL-VAE+ConvNeXt Block,聯合訓練理解與生成任務;
B、使用REPA,理解和生成模塊使用共享參數的SDXL-VAE+ConvNeXt Block,聯合訓練理解與生成任務;這個設置類似Transfusion;
C、使用REPA,理解和生成模塊使用獨立參數的SDXL-VAE+ConvNeXt Block,其中,理解部分的SDXL-VAE參數參與訓練,聯合訓練理解與生成任務;
D、理解模塊是SigLIP,只訓練理解數據,保持與聯合訓練中理解數據等量;這是同一框架和數據量下,理解模型的基準;
E、使用REPA,理解模塊是SigLIP,生成模塊是SDXL-VAE+ConvNeXt Block,只訓練生成數據,保持與聯合訓練中生成數據等量;這是同一框架和數據量下,生成模型的基準;
F、使用REPA,理解模塊是SigLIP,生成模塊是SDXL-VAE+ConvNeXt Block,聯合訓練理解與生成任務。
實驗結果如下圖。
分析:
1、比較A和F:REPA的引入顯著提升了生成相關的指標
2、比較B,C和F:解耦編碼器並使用SigLIP作為理解模塊能得到理解和生成能力最好的統一模型
3、比較D,E和F:我們的最終策略F在訓練數據量和訓練設置均相同的情況下,理解能力與純理解基準相當,生成能力與純生成基準基本持平;驗證了F在保持各自性能的同時實現了兩個任務的有機統一
基於以上實驗結果,我們採用方案F作為JanusFlow的最終架構配置。
實驗結果
JanusFlow在DPGBench,GenEval和多模態理解的測評標準上都取得了強大的效果。詳見表格。
 △視覺理解分數:JanusFlow超過了一些同尺寸的純理解模型
△視覺理解分數:JanusFlow超過了一些同尺寸的純理解模型 △視覺生成分數:JanusFlow有較強的語義跟隨能力
△視覺生成分數:JanusFlow有較強的語義跟隨能力 △視覺理解主觀效果
△視覺理解主觀效果 △視覺生成主觀效果
△視覺生成主觀效果最後總結,JanusFlow通過融合自回歸LLM與Rectified Flow,成功構建了一個統一的視覺理解與生成框架。該模型具有簡潔的架構設計,在視覺理解和生成兩大任務上均展現出強勁的競爭力。
論文鏈接:
https://arxiv.org/abs/2411.07975
項目主頁:https://github.com/deepseek-ai/Janus
模型下載:https://huggingface.co/deepseek-ai/JanusFlow-1.3B
在線 Demo:https://huggingface.co/spaces/deepseek-ai/JanusFlow-1.3B
相關文獻:
[1] Show-o: One Single Transformer to Unify Multimodal Understanding and Generation
[2] Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model
[3] Janus: Decoupling Visual Encoding for Unified Multimodal Understanding and Generation
[4] Representation Alignment for Generation: Training Diffusion Transformers Is Easier Than You Think