這才是真・開源模型!公開「後訓練」一切,性能超越Llama 3.1 Instruct
機器之心報導
編輯:Panda、張倩
開源模型陣營又迎來一員猛將:Tülu 3。它來自艾倫人工智能研究所(Ai2),目前包含 8B 和 70B 兩個版本(未來還會有 405B 版本),並且其性能超過了 Llama 3.1 Instruct 的相應版本!長達 73 的技術報告詳細介紹了後訓練的細節。

在最近關於「Scaling Law 是否撞牆」的討論中,後訓練(post-training)被寄予厚望。
眾所周知,近期發佈的 OpenAI o1 在數學、 代碼、長程規劃等問題上取得了顯著提升,而背後的成功離不開後訓練階段強化學習訓練和推理階段思考計算量的增大。基於此,有人認為,新的擴展律 —— 後訓練擴展律(Post-Training Scaling Laws) 已經出現,並可能引發社區對於算力分配、後訓練能力的重新思考。
不過,對於後訓練到底要怎麼做,哪些細節對模型性能影響較大,目前還沒有太多系統的資料可以參考,因為這都是各家的商業機密。
剛剛,曾經重新定義「開源」並發佈了史上首個 100% 開源大模型的艾倫人工智能研究所(Ai2)站出來打破了沉默。他們不僅開源了兩個性能超過 Llama 3.1 Instruct 相應版本的新模型 ——Tülu 3 8B 和 70B(未來還會有 405B 版本),還在技術報告中公佈了詳細的後訓練方法。

Ai2 研究科學家 Nathan Lambert(論文一作)的推文
這份 70 多頁的技術報告可以說誠意滿滿,非常值得詳細閱讀:

Tülu 3 發佈後,社區反響熱烈,甚至有用戶表示測試後發現其表現比 GPT-4o 還好。

另外,Nathan Lambert 還暗示未來可能基於 Qwen 來訓練 Tülu 模型。

機器之心也簡單測試了下 Tülu。首先,數 Strawberry 中 r 數量的問題毫無意外地出錯了,至於其編寫的笑話嘛,好像也不好笑。
本地部署 AI 模型的工具 Ollama 也第一時間宣佈已經支持該模型。

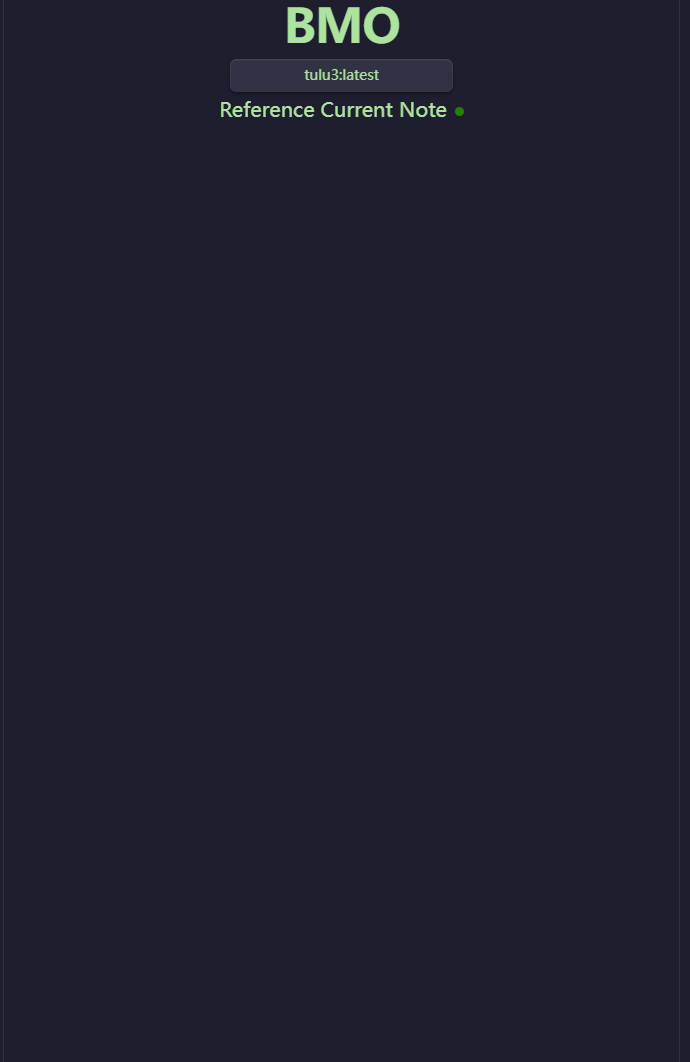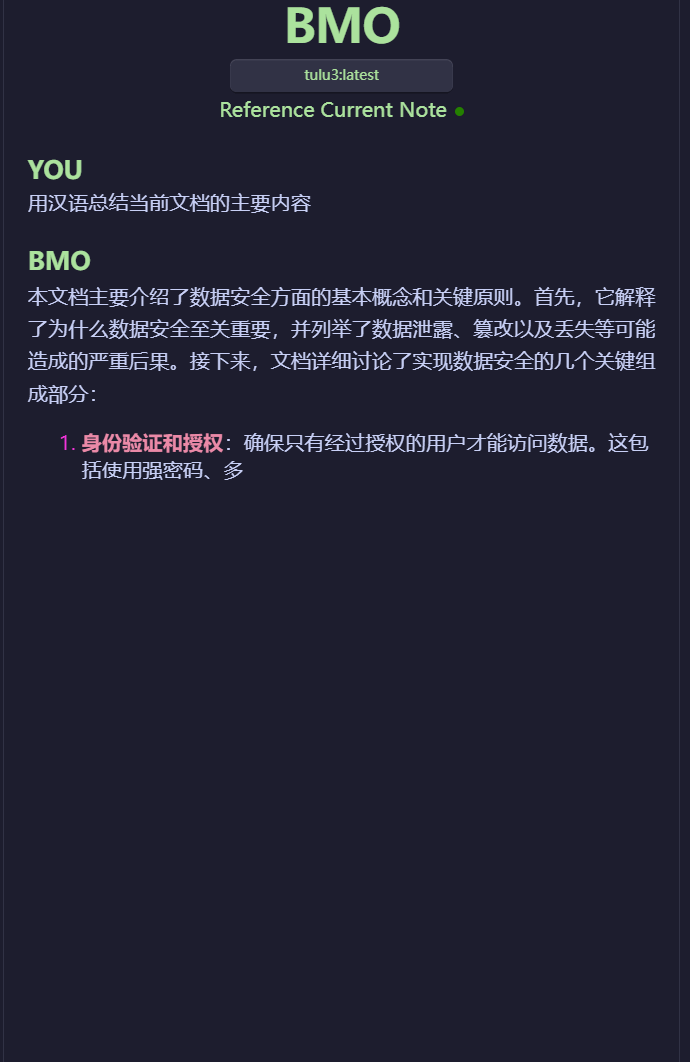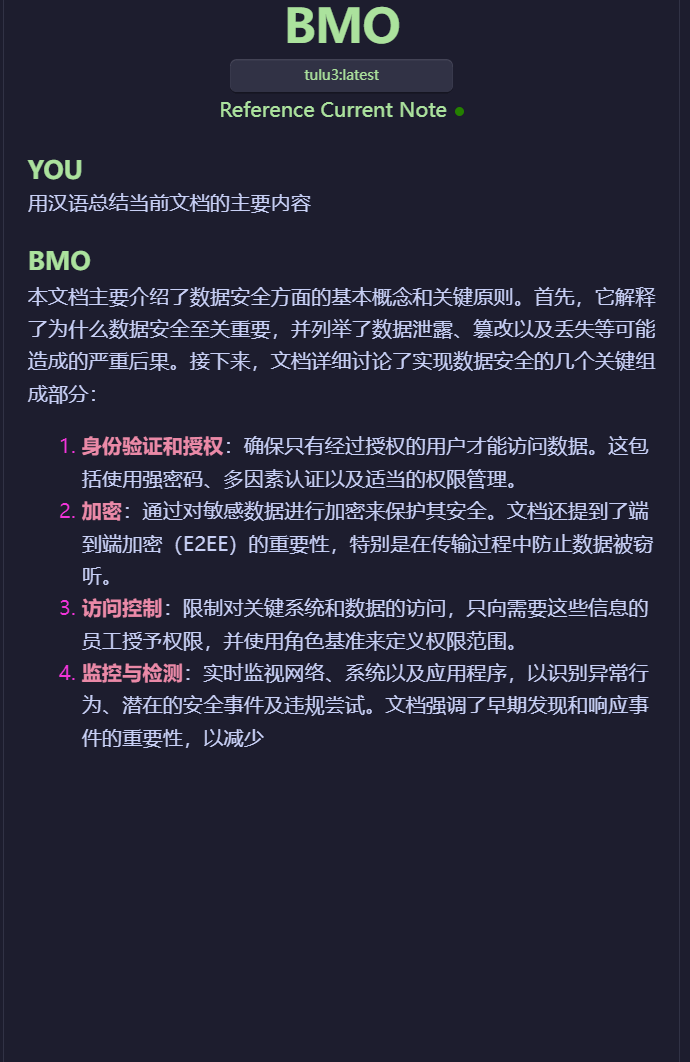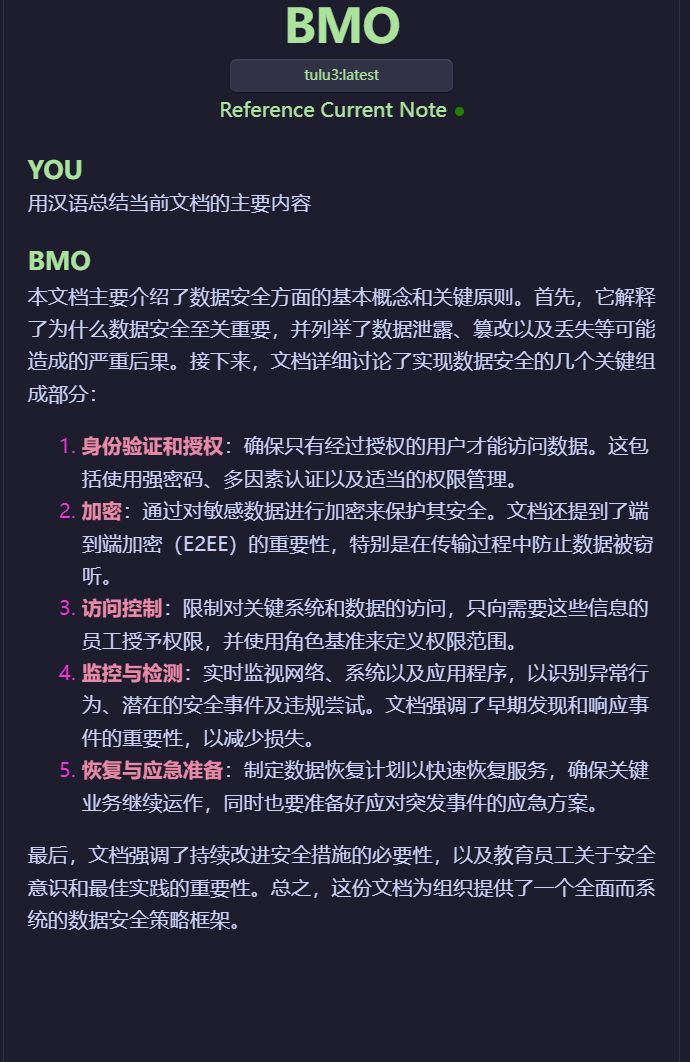
機器之心也簡單通過 Ollama 和 Obsidian 的插件簡單體驗了一下 8B 的本地版本,看起來效果還不錯,速度也很快。
不過,比模型性能更值得關注的或許還是 Tülu 3 的後訓練方案。在這套方案的啟發下,眾多研究者有望在大模型的後訓練階段進行更多嘗試,延續大模型的 Scaling Law。
首個發佈後訓練詳情的開源模型
在提升模型性能方面,後訓練的作用越來越大,具體包括微調和 RLHF 等。此前,OpenAI、 Anthropic、Meta 和Google等大公司已經大幅提升了其後訓練方法的複雜度,具體包括採用多輪訓練範式、使用人類數據 + 合成數據、使用多個訓練算法和訓練目標。也正因為此,這些模型的通用性能和專業能力都非常強。但遺憾的是,他們都沒有透明地公開他們的訓練數據和訓練配方。
到目前為止,開源後訓練一直落後於封閉模型。在 LMSYS 的 ChatBotArena 排行榜上,前 50 名(截至 2024 年 11 月 20 日)中沒有任何一個模型發佈了其後訓練數據。即使是主要的開放權重模型也不會發佈任何數據或用於實現這種後訓練的配方細節。
於是,Ai2 似乎看不下去了,決定開源一切!
Tülu 3 模型之外,Ai2 還發佈了所有的數據、數據混合方法、配方、代碼、基礎設施和評估框架!

-
模型:https://huggingface.co/allenai
-
技術報告:https://allenai.org/papers/tulu-3-report.pdf
-
數據集:https://huggingface.co/collections/allenai/tulu-3-datasets-673b8df14442393f7213f372
-
GitHub:https://github.com/allenai/open-instruct
-
Demo:https://playground.allenai.org/
下表展示了 Ai2 開源的模型、數據集和代碼:

Ai2 表示,Tülu 3 突破了後訓練研究的界限,縮小了開放和封閉微調配方之間的性能差距。
為此,他們創建了新的數據集和新的訓練流程。他們還提出了直接使用強化學習在可驗證問題上訓練的新方法,以及使用模型自己的生成結果創建高性能偏好數據的新方法。
加上更多優化細節,得到的 Tülu 3 系列模型明顯優於同等規模的其它模型。

8B 模型在各基準上的表現

70B 模型在各基準上的表現
Tülu 3 是如何煉成的?
Ai2 在預訓練語言模型的基礎上,通過四個階段的後訓練方法生成 Tülu 3 模型(見圖 1)。這套訓練流程結合了強化學習中的新算法改進、尖端基礎設施和嚴格的實驗,以便在各個訓練階段整理數據並優化數據組合、方法和參數。

這些階段如下:
-
階段一:數據整理。Ai2 整理了各種提示(prompt)信息,並將其分配到多個優化階段。他們創建了新的合成提示,或在可用的情況下,從現有數據集中獲取提示,以針對特定能力。他們確保了提示不受評估套件 Tülu 3 EVAL 的汙染。

-
階段二:監督微調。Ai2 利用精心挑選的提示和回答結果進行監督微調(SFT)。在評估框架指導下,他們通過全面的實驗,確定最終的 SFT 數據和訓練超參數,以增強目標核心技能,同時不對其他技能的性能產生重大影響。

-
階段三:偏好微調。Ai2 將偏好微調 —— 特別是 DPO(直接偏好優化)—— 應用於根據選定的提示和 off-policy 數據構建的新 on-policy 合成偏好數據。與 SFT 階段一樣,他們通過全面的實驗來確定最佳偏好數據組合,從而發現哪些數據格式、方法或超參數可帶來改進。

-
階段四:具有可驗證獎勵的強化學習。Ai2 引入了一個新的基於強化學習的後訓練階段,該階段通過可驗證獎勵(而不是傳統 RLHF PPO 訓練中常見的獎勵模型)來訓練模型。他們選擇了結果可驗證的任務,例如數學問題,並且只有當模型的生成被驗證為正確時才提供獎勵。然後,他們基於這些獎勵進行強化學習訓練。

Tülu 3 pipeline 的主要貢獻在於數據、方法、基礎設施的改進和嚴格的評估。其中的關鍵要素包括:
-
數據質量、出處和規模:Ai2 通過仔細調查可用的開源數據集、分析其出處、淨化來獲取提示,並針對核心技能策劃合成提示。為確保有效性,他們進行了全面的實驗,研究它們對評估套件的影響。他們發現有針對性的提示對提高核心技能很有影響,而真實世界的查詢(如 WildChat)對提高通用聊天能力很重要。利用 Tülu 3 EVAL 淨化工具,他們可以確保提示不會汙染評估套件。
-
創建多技能 SFT 數據集。通過利用不同數據混合結果進行幾輪有監督微調,Ai2 優化了「通用」和「特定技能」類別中提示的分佈。例如,為了提高數學推理能力,Ai2 首先通過創建數學專業模型在評估套件中建立一個上限,然後混合數據,使通用模型更接近這個上限。
-
編排一個 On-Policy 偏好數據集。Ai2 開發了一個 on-policy 數據編排 pipeline,以擴展偏好數據集生成。具體來說,他們根據給定的提示從 Tülu 3-SFT 和其他模型中生成完成結果,並通過成對比較獲得偏好標籤。他們的方法擴展並改進了 Cui et al. [2023] 提出的 off-policy 偏好數據生成方法。通過對偏好數據進行精心的多技能選擇,他們獲得了 354192 個用於偏好調整的實例,展示了一系列任務的顯著改進。
-
偏好調整算法設計。Ai2 對幾種偏好調整算法進行了實驗,觀察到使用長度歸一化( length-normalized)直接偏好優化的性能有所提高。他們在實驗中優先考慮了簡單性和效率,並在整個開發過程和最終模型訓練中使用了長度歸一化直接偏好優化算法,而不是對基於 PPO 的方法進行成本更高的研究。
-
具有可驗證獎勵的特定技能強化學習。Ai2 採用了一種新方法,利用標準強化學習範式,針對可以對照真實結果(如數學)進行評估的技能進行強化學習。他們將這種算法稱為「可驗證獎勵強化學習」(RLVR)。結果表明,RLVR 可以提高模型在 GSM8K、MATH 和 IFEval 上的性能。

-
用於強化學習的訓練基礎設施。Ai2 實現了一種異步式強化學習設置:通過 vLLM 高效地運行 LLM 推理,而學習器還會同時執行梯度更新。並且 Ai2 還表示他們的強化學習代碼庫的擴展性能非常好,可用於訓練 70B RLVR 策略模型。

Tülu 3 的表現如何?
為了評估 Tülu 3 以及其它模型,Ai2 設計了一套評估框架,其中包含一個用於可重覆評估的開放評估工具包、一套用於評估指令微調模型的核心技能的套件(具有分立的開發和留存評估),以及一組推薦設置(基於 Ai2 對各種模型的實驗)——Ai2 稱之為 Tülu 3 Evaluation Regime。
除了評估最終模型,該框架還是一個開放的評估工具套件,旨在通過精心挑選的評估套件和淨化工具來引導開發進度。

下面展示了一些主要的評估結果。可以看到,同等規模性,在這些基準上,Tülu 3 的表現非常出色,其中 70B 版本的平均性能甚至可與 Claude 3.5 Haiku 比肩。

此外,Ai2 還提出了兩個新的評估基準:IFEval-OOD 和 HREF。
IFEval-OOD 的目標是測試 LLM 遵從精確指令的能力,以及它們是否能夠遵從超出 IFEval 中包含的 25 個約束的指令約束。IFEval-OOD 包含 6 大類 52 個約束。
HREF 的全稱是 Human Reference-guided Evaluation of instruction Following,即人類偏好指導的指令遵從評估,其目標是自動評估語言模型遵從指令的能力。HREF 專注於語言模型通常訓練的 11 個指令遵從任務,即頭腦風暴、開放式 QA、封閉式 QA、提取、生成、重寫、總結、分類、數值推理、多文檔合成和事實核查。
下表給出了 Tülu 3 與對比模型在這兩個新基準以及其它已有基準上的表現,具體涉及的領域包括知識調用、推理、數學、編程和指令遵從。需要注意,這些都是 Unseen 基準,即這些任務是模型訓練過程中未見過的。

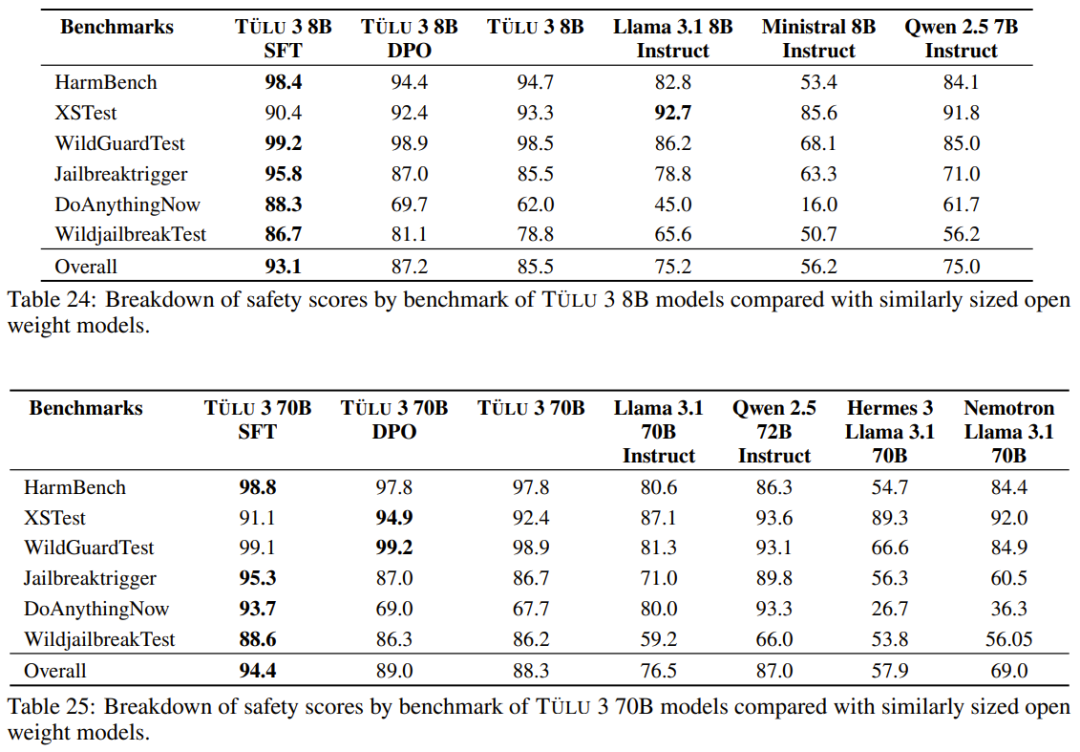
安全性方面,以下兩表展示了 Tülu 3 與對比模型在兩個基準上的安全分數。整體而言,同等規模下,Tülu 3 相較於其它開源模型更有優勢。
最後必須說明,長達 73 頁的 Tülu 3 技術報告中還包含大量本文並未提及的細節,感興趣的讀者千萬不要錯過。
參考鏈接:
https://allenai.org/blog/tulu-3?includeDrafts
https://x.com/natolambert/status/1859643351441535345
https://www.interconnects.ai/p/tulu-3



















