研究大模型門檻太高?不妨看看小模型SLM,知識點都在這
AIxiv專欄是機器之心發佈學術、技術內容的欄目。過去數年,機器之心AIxiv專欄接收報導了2000多篇內容,覆蓋全球各大高校與企業的頂級實驗室,有效促進了學術交流與傳播。如果您有優秀的工作想要分享,歡迎投稿或者聯繫報導。投稿郵箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
本篇綜述的作者團隊包括賓州州立大學的博士研究生王發利,張智維,吳縱宇,張先仁,指導教師王蘇杭副教授,以及來自倫斯勒理工學院的馬耀副教授,亞馬遜湯先鋒、何奇,德克薩斯大學曉士頓健康科學中心黃明副教授團隊。
摘要:大型語言模型(LLMs)在多種任務中表現出色,但由於龐大的參數和高計算需求,面臨時間和計算成本挑戰。因此,小型語言模型(SLMs)因低延遲、成本效益及易於定製等優勢優點,適合資源有限環境和領域知識獲取,正變得越來越受歡迎。我們給出了小語言模型的定義來填補目前定義上的空白。我們對小型語言模型的增強方法、已存在的小模型、應用、與 LLMs 的協作、以及可信賴性方面進行了詳細調查。我們還探討了未來的研究方向,並在 GitHub 上發佈了相關模型及文章:https://github.com/FairyFali/SLMs-Survey。

論文鏈接:https://arxiv.org/abs/2411.03350
文章結構

圖 1 文章結構
LLMs 的挑戰
神經語言模型(LM)從 BERT 的預訓練微調到 T5 的預訓練提示,再到 GPT-3 的上下文學習,極大增強了 NLP。模型如 ChatGPT、Llama 等在擴展至大數據集和模型時顯示出 「湧現能力」。這些進步推動了 NLP 在多個領域的應用,如編程、推薦系統和醫學問答。
儘管大型語言模型(LLMs)在複雜任務中表現出色,但其龐大的參數和計算需求限制了部署本地或者限制在雲端調用。這帶來了一系列挑戰:
LLMs 的高 GPU 內存佔用和計算成本通常使得其只能通過雲 API 部署,用戶需上傳數據查詢,可能引起數據泄漏及隱私問題,特別是在醫療、金融和電商等敏感領域。
在移動設備上調用雲端 LLMs 時面臨雲延遲問題,而直接部署又面臨高參數和緩存需求超出普通設備能力的問題。
LLMs 龐大的參數數量可能導致幾秒至幾分鐘的推理延遲,不適合實時應用。
LLMs 在專業領域如醫療和法律的表現不佳,需要成本高的微調來提升性能。
雖然通用 LLMs 功能強大,但許多應用和任務只需特定功能和知識,部署 LLMs 可能浪費資源且性能不如專門模型。
SLMs 的優勢
最近,小型語言模型(SLMs)在處理特定領域問題時顯示出與大型語言模型(LLMs)相當的性能,同時在效率、成本、靈活性和定製方面具有優勢。由於參數較少,SLMs 在預訓練和推理過程中節約了大量計算資源,減少了內存和存儲需求,特別適合資源有限的環境和低功耗設備。因此,SLMs 作為 LLMs 的替代品越來越受到關注。如圖 2 所示,Hugging Face 社區中 SLMs 的下載頻率已超過大型模型,而圖 3 顯示了 SLMs 版本隨時間推移的日益流行。
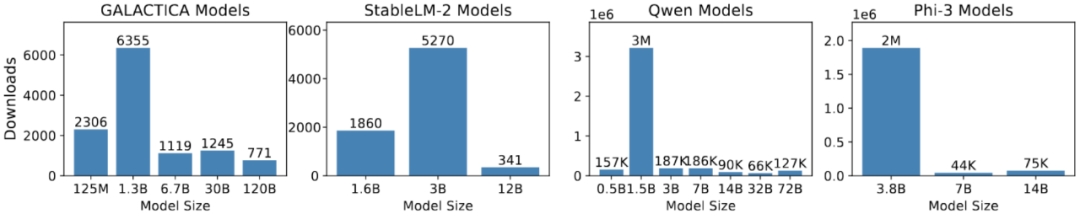
圖 2 Hugging Face 上個月下載量(數據獲取在 2024 年 10 月 7 日)
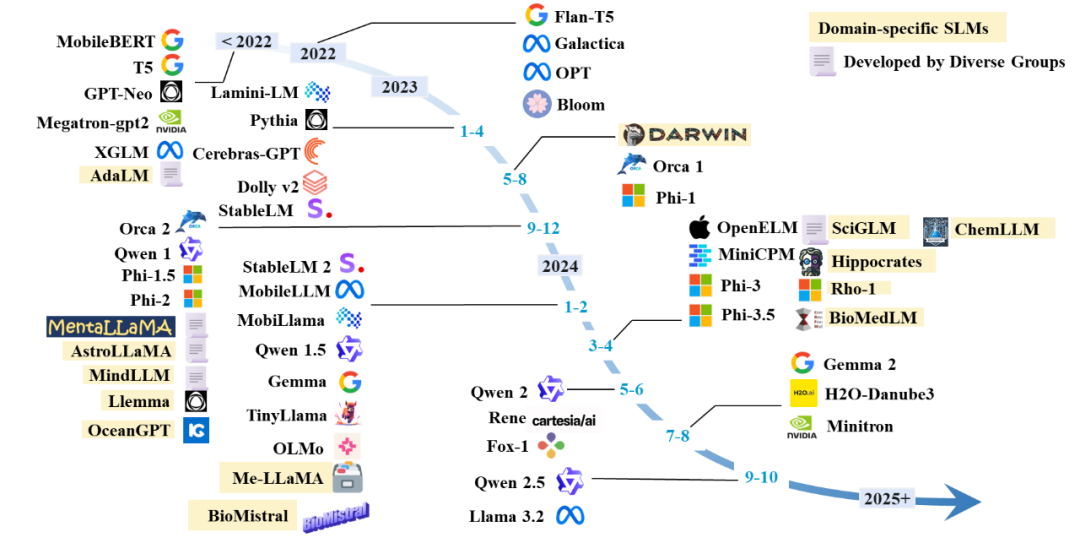
圖 3 SLMs 時間線
SLMs 的定義
通常,具有湧現能力的語言模型被歸類為大型語言模型(LLMs)。然而,小型語言模型(SLMs)的分類尚無統一標準。一些研究認為 SLMs 的參數少於 10 億,且在移動設備上通常配備約 6GB 的內存;而另一些研究則認為 SLMs 的參數可達到 100 億,但這些模型通常缺乏湧現能力。考慮到 SLMs 在資源受限的環境及特定任務中的應用,我們提出了一個廣義的定義:SLMs 的參數範圍應介於能展現專門任務湧現能力的最小規模和在資源限制條件下可管理的最大規模之間。這一定義旨在整合不同觀點,並考慮移動計算及能力閾值因素。
SLMs 的增強方法
在大語言模型時代小語言模型的增強方法會有不同,包括從頭開始訓練 SLMs 的訓練方法、使 SLMs 遵循指令的監督微調 (SFT)、先進的知識提煉和量化技術,以及 LLMs 中經常使用的技術,以增強 SLMs 針對特定應用的性能。我們詳細介紹了其中一些代表性方法,包括參數共享的模型架構(從頭開始訓練子章節 3.1)、從人類反饋中優化偏好(有監督微調子章節 3.2)、知識蒸餾的數據質量(3.3 章節)、蒸餾過程中的分佈一致性(3.4 章節)、訓練後量化和量化感知訓練技術(3.5 章節)、RAG 和 MoE 方法增強 SLMs(3.6 章節)。這一章節的未來方法是探索可提高性能同時降低計算需求的模型架構,比如 Mamba。
SLMs 的應用
由於 SLMs 能夠滿足增強隱私性和較低的內存需求,許多 NLP 任務已開始採用 SLMs,並通過專門技術提升其在特定任務上的性能(見 4.1 節),如問答、代碼執行、推薦系統以及移動設備上的自動化任務。典型應用包括在移動設備上自動執行任務,SLMs 可以作為代理智能調用必需的 API,或者根據智能手機 UI 頁面代碼自動完成給定的操作指令(見 4.1.5 節)。
此外,部署 SLMs 時通常需考慮內存使用和運行效率,這對預算有限的邊緣設備(特別是智能手機)上的資源尤為關鍵(見 4.2 節)。內存效率主要體現在 SLMs 及其緩存的空間佔用上,我們調研了如何壓縮 SLMs 本身及其緩存(見 4.2.1 節)。運行效率涉及 SLMs 參數量大及切換開銷,如內存緩存區與 GPU 內存之間的切換(見 4.2.2 節),因此我們探討了減少 MoE 切換時間和降低分佈式 SLMs 延遲等策略。
未來研究方向包括使用 LoRA 為不同用戶提供個性化服務、識別 SLMs 中的固有知識及確定有效微調所需的最少數據等(更多未來方向詳見第 8 章)。
已存在的 SLMs
我們總結了一些代表性的小型語言模型(詳見圖 3),這些模型包括適用於通用領域和特定領域的小型語言模型(參數少於 70 億)。本文詳細介紹了這些小型語言模型的獲取方法、使用的數據集和評估任務,並探討了通過壓縮、微調或從頭開始訓練等技術獲取 SLMs 的策略。通過統計分析一些技術,我們歸納出獲取通用 SLMs 的常用技術,包括 GQA、Gated FFN,SiLU 激活函數、RMS 正則化、深且窄的模型架構和 embedding 的優化等(見 5.1 章)。特定領域的 SLMs,如科學、醫療健康和法律領域的模型,通常是通過對大模型生成的有監督領域數據進行指令式微調或在領域數據上繼續訓練來獲取的(見 5.2 章)。未來的研究方向將包括在法律、金融、教育、電信和交通等關鍵領域開發專業化的小型語言模型。
SLMs 輔助 LLMs
由於 SLMs 在運行效率上表現出色且與 LLMs 的行為規律相似,SLMs 能夠作為代理輔助 LLMs 快速獲取一些先驗知識,進而增強 LLMs 的功能,例如減少推理過程中的延遲、縮短微調時間、改善檢索中的噪聲過濾問題、提升次優零樣本性能、降低版權侵權風險和優化評估難度。
在第 6 章中,我們探討了以下五個方面:
(i) 使用 SLMs 幫助 LLMs 生成可靠內容:例如,使用 SLMs 判斷 LLMs 輸入和輸出的真實置信度,或根據 LLMs 的中間狀態探索幻覺分數。詳細的可靠生成方法、增強 LLMs 的推理能力、改進 LLMs RAG 以及緩解 LLMs 輸出的版權和隱私問題,請參考原文。
(ii) SLMs 輔助提取 LLMs 提示:一些攻擊方法通過 SLMs 逆向生成 Prompts。
(iii) SLMs 輔助 LLMs 微調:SLMs 的微調參數差異可以模擬 LLMs 參數的演變,從而實現 LLMs 的高效微調。
(iv) SLMs 在特定任務上輔助 LLMs 表現:定製化的 SLMs 在某些特定任務上可能優於 LLMs,而在困難樣本上可能表現不佳,因此 SLMs 和 LLMs 的合作可以在特定任務上實現更優表現。
(v) 使用 SLMs 評估 LLMs:SLMs 在經過微調後可以作為評估器,評估 LLMs 生成的更加格式自由的內容。
未來的方向包括使用 SLMs 作為代理探索 LLMs 更多的行為模式,如優化 Prompts、判斷缺失知識和評估數據質量等,更多信息請參見原文第 8 章未來工作。
SLMs 的可信賴性
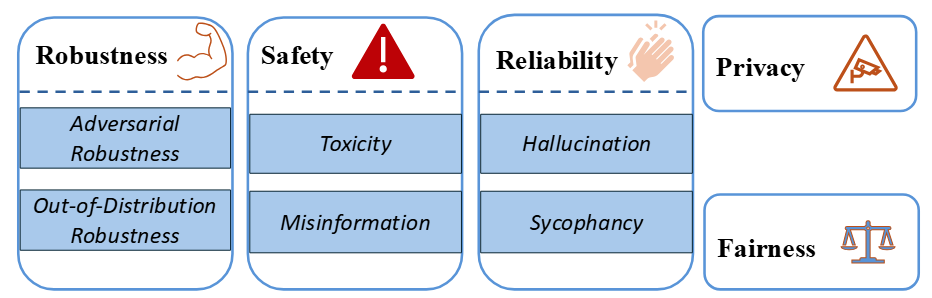
圖 4 Trustworthiness 分類
語言模型已成為我們日常生活中不可或缺的一部分,我們對它們的依賴日益增加。然而,它們在隱私、公平等信任維度上存在局限,帶來了一定風險。因此,許多研究致力於評估語言模型的可信賴性。儘管目前的研究主要集中在大型語言模型(LLMs)上,我們在第 7 章關注 7B 參數及以下的模型和五個關鍵的信任場景:魯棒性、隱私性、可靠性、安全性和公平性,詳見圖 4。在魯棒性方面,我們討論了對抗性魯棒性和分佈外魯棒性兩種情況;在安全性方面,我們重點分析了誤導信息和毒性問題;在可靠性方面,我們主要關注幻覺和諂媚現象。然而,大多數現有研究都集中在具有至少 7B 參數的模型上,這留下了對小型語言模型(SLMs)可信度全面分析的空白。因此,系統地評估 SLMs 的可信度並瞭解其在各種應用中的表現,是未來研究的重要方向。
總結
隨著對小型語言模型需求的增長,當下研究文獻涵蓋了 SLMs 的多個方面,例如針對特定應用優化的訓練技術如量化感知訓練和選擇性架構組件。儘管 SLMs 性能受到認可,但其潛在的可信度問題,如幻覺產生和隱私泄露風險,仍需注意。當前缺乏全面調查徹底探索 LLMs 時代 SLMs 的這些工作。本文旨在提供詳盡調查,分析 LLMs 時代 SLMs 的各個方面及未來發展。詳見我們的綜述原文。