智能體零樣本解決未見過人類設計環境!全靠這個開放式物理RL環境空間
機器之心報導
機器之心編輯部
當物理推理能力進化後,通用強化學習智能體能在2D物理環境中執行多樣化任務了。
在機器學習領域,開發一個在未見過領域表現出色的通用智能體一直是長期目標之一。一種觀點認為,在大量離線文本和影片數據上訓練的大型 transformer 最終可以實現這一目標。
不過,在離線強化學習(RL)設置中應用這些技術往往會將智能體能力限制在數據集內。另一種方法是使用在線 RL,其中智能體通過環境交互自己收集數據。
然而,除了一些明顯的特例外,大多數 RL 環境都是一些狹窄且同質化的場景,限制了訓練所得智能體的泛化能力。
近日,牛津大學的研究者提出了 Kinetix 框架,它可以表徵 2D 物理環境中廣闊的開放式空間,並用來訓練通用智能體。

-
論文地址:https://arxiv.org/pdf/2410.23208
-
項目主頁:https://kinetix-env.github.io/
-
論文標題:Kinetix: Investigating the Training of General Agents through Open-Ended Physics-Based Control Tasks
Kinetix 涵蓋的範圍足夠廣,可以表徵機器人任務(如抓取和移動)、經典的 RL 環境(如 Cartpole、Acrobot 和 Lunar)、電子遊戲(Pinball)和其他很多任務,如下圖 1 所示。
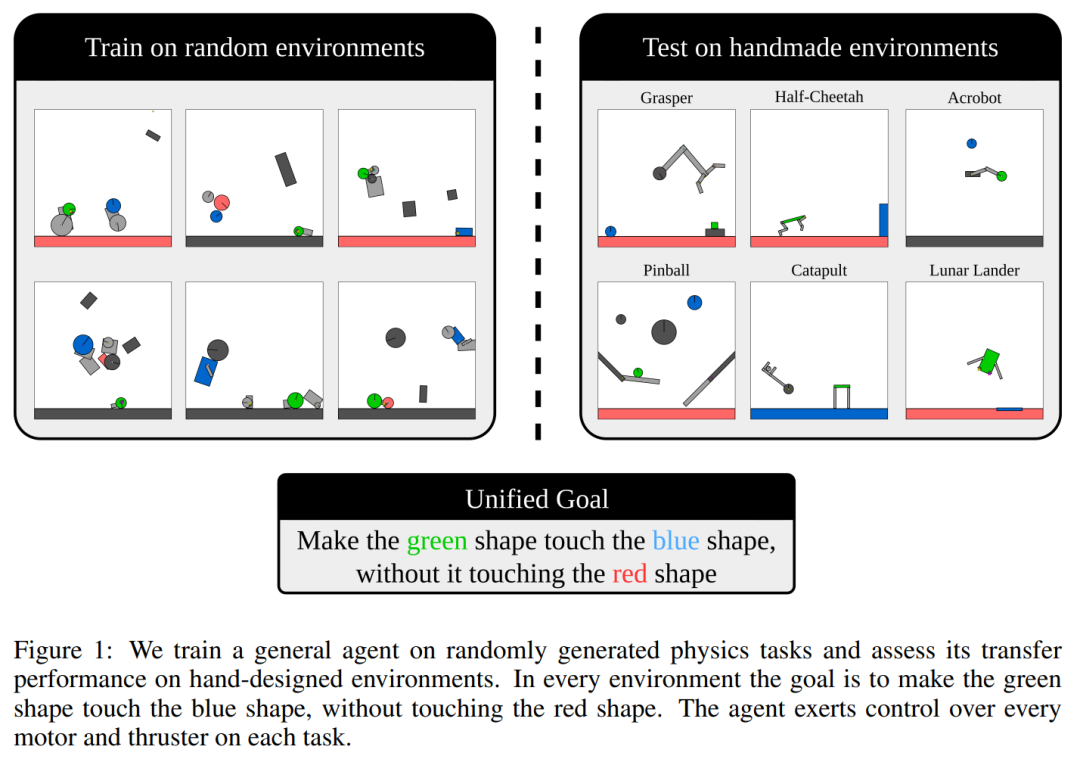
此外,為了後端運行 Kinetix,研究者開發了一種硬件加速物理引擎 Jax2D,它能夠高效地模擬訓練智能體所需的數十億次環境交互。他們表示,通過從可表徵的 2D 物理問題空間中隨機采樣 Kinetix 環境,可以幾乎無限地生成有意義的多樣化訓練任務。
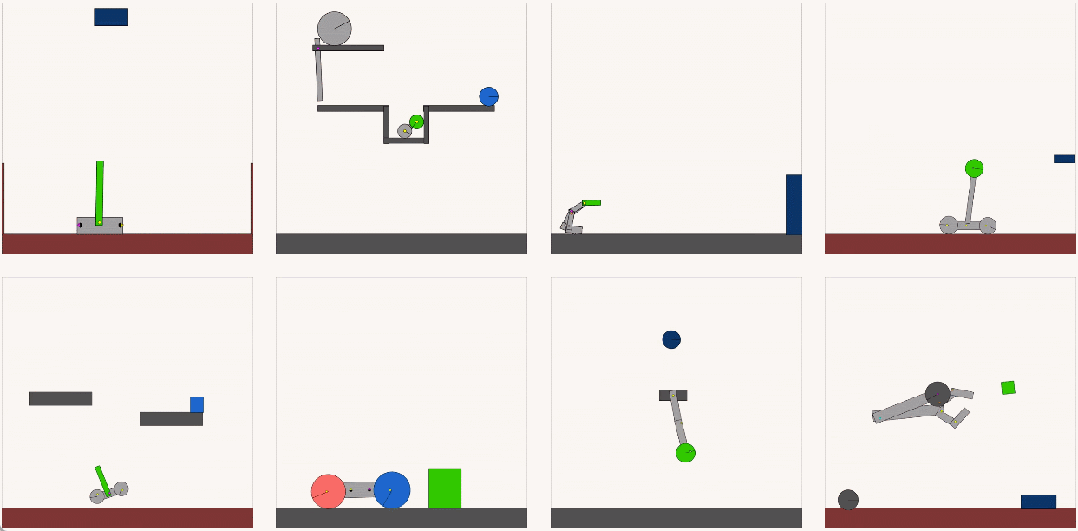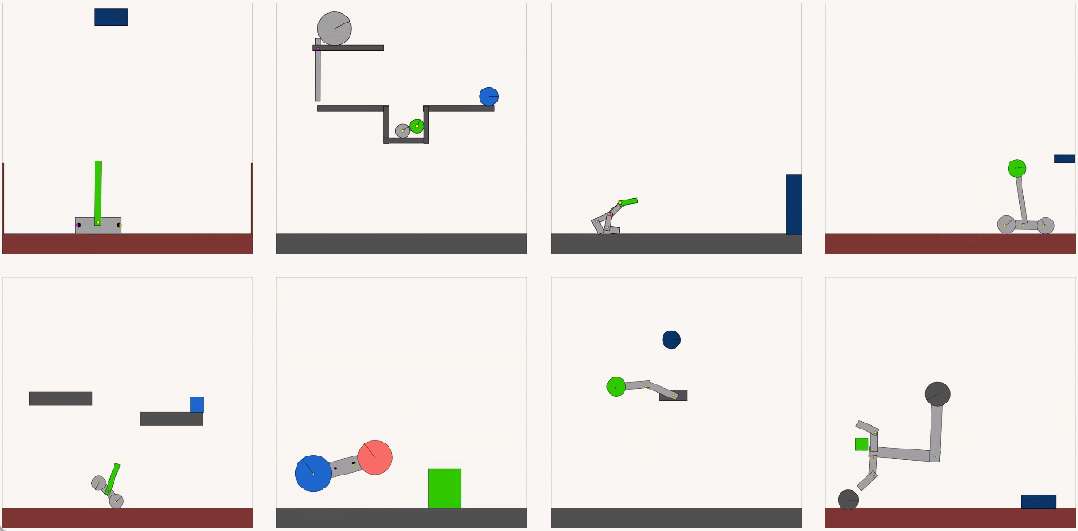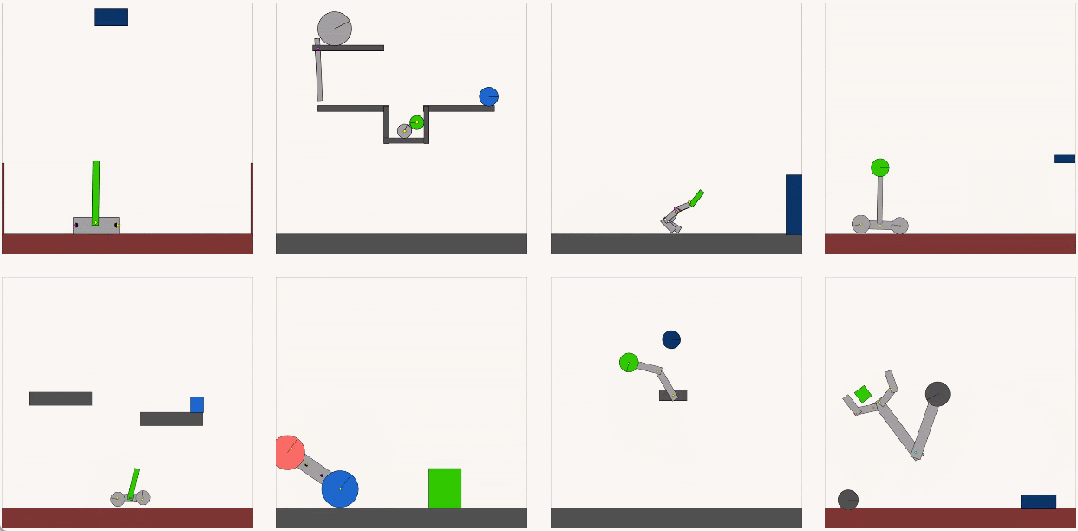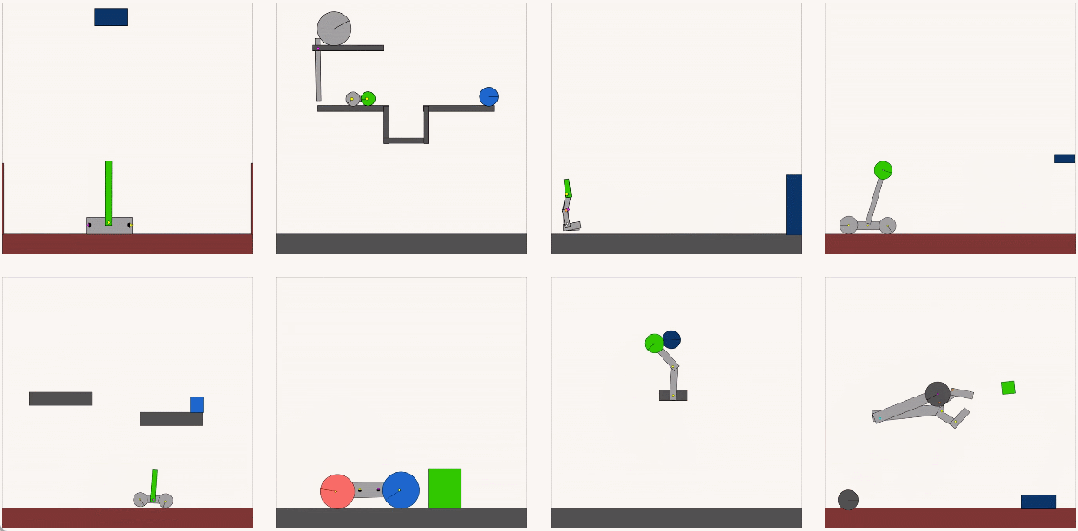
研究者發現,在這些環境中訓練的 RL 智能體表現出了對一般機械特性的理解,並能夠零樣本地解決未見過的手工環境。
他們進一步分析了在特定困難環境中微調該通用智能體能帶來哪些好處,結果發現與白板智能體相比,這樣做能夠大大減少學習特定任務所需的樣本數量。
同時,微調還帶來了一些新能力,包括解決專門訓練過的智能體無法取得進展的任務。
Kinetix 詳解
Kinetix 是一個大型開放式 RL 環境,完全在 JAX 中實現。
Jax2D
為了支持 Kinetix,研究團隊開發了基於脈衝的 2D 剛體物理引擎 ——Jax2D,完全用 JAX 編寫,構成了 Kinetix 基準測試的基礎。研究團隊通過僅模擬幾個基本組件來將 Jax2D 設計得儘可能具有表達能力。
為此,Jax2D 場景僅包含 4 個獨特的實體:圓形、(凸)多邊形、關節和推進器。從這些簡單的構建塊中,可以表徵出多種多樣的不同物理任務。
Jax2D 與 Brax 等其他基於 JAX 的物理模擬器的主要區別在於 Jax2D 場景幾乎完全是動態指定的,這意味著每次模擬都會運行相同的底層計算圖,使得能夠通過 JAX vmap 操作並行處理不同任務,這是在多任務 RL 環境中利用硬件加速功能的關鍵組成部分。相比之下,Brax 幾乎完全是靜態指定的。
Kinetix:RL 環境規範
動作空間 Kinetix 支持多離散和連續動作空間。在多離散動作空間中,每個電機和推進器可以不活動,也可以在每個時間步以最大功率激活,電機可以向前或向後運行。
-
觀察空間
使用符號觀察,其中每個實體(形狀、關節或推進器)由一系列物理屬性值(包括位置、旋轉和速度)定義。然後將觀察定義為這些實體的集合,允許使用排列不變的網絡架構,例如 transformer。這種觀察空間使環境完全可觀察,從而無需具有記憶的策略。還提供基於像素的觀察和符號觀察的選項,它可以簡單地連接和展平實體信息。
-
獎勵
為了實現通用智能體的目標,該研究選擇了一個簡單但具有高度表達力的獎勵函數,該函數在所有環境中保持固定。每個場景必須包含一個綠色形狀和一個藍色形狀 – 目標只是使這兩個形狀發生碰撞,此時該情節以 + 1 獎勵結束。場景還可以包含紅色形狀,如果它們與綠色形狀碰撞,將會以 -1 獎勵終止該情節。如圖 1 所示,這些簡單且可解釋的規則允許表示大量語義上不同的環境。
Kinetix 的表現力、多樣性和速度使其成為研究開放性的理想環境,包括通用智能體、UED 和終身學習。為了使其對智能體訓練和評估發揮最大作用,該研究提供了一個啟髮式環境生成器、一組手工設計的級別以及描述環境複雜性的環境分類法。
環境生成器 Kinetix 的優勢在於它可以表示環境的多樣性。然而,這個環境集包含許多退化的情況,如果簡單地采樣,它們可能會主導分佈。因此,該研究提供了一個隨機級別生成器,旨在最大程度地提高表達能力,同時最大限度地減少簡並級別的數量。確保每個關卡都具有完全相同的綠色和藍色形狀,以及至少一個可控方面(電機或推進器)。
實驗結果
研究者在程序生成的 Kinetix 關卡上進行訓練,後者從靜態定義分佈中抽取。他們將來自該分佈的采樣關卡上的訓練稱為 DR。主要評估指標是在手動 holdout 關卡的解決率。智能體不會在這些關卡上訓練,但它們確實存在於該訓練分佈的支持範圍內。由於所有關卡都遵循相同的底層結構並完全可觀察,因此理論上可以學習一種在分佈內所有關卡上表現最佳的策略。
為了選擇要訓練的關卡,研究者使用了 SOTA UED 算法 SFL,它定期在隨機生成的關卡上執行大量 rollout,然後選擇具有高學習能力的子集,並在固定時間內對它進行訓練,最後再次選擇新的關卡。同時,研究者使用 PLR 和 ACCEL 進行了初步實驗,但發現這些方法相較於 DR 沒有任何改進。
架構
下圖 2 是訓練所用的基於 transforme r 的架構。可以看到,一個場景被分解為它的組成實體,然後通過網絡傳遞。該網絡由 L 層的自注意力和消息傳遞組成,K 個完全連接層緊隨其後。
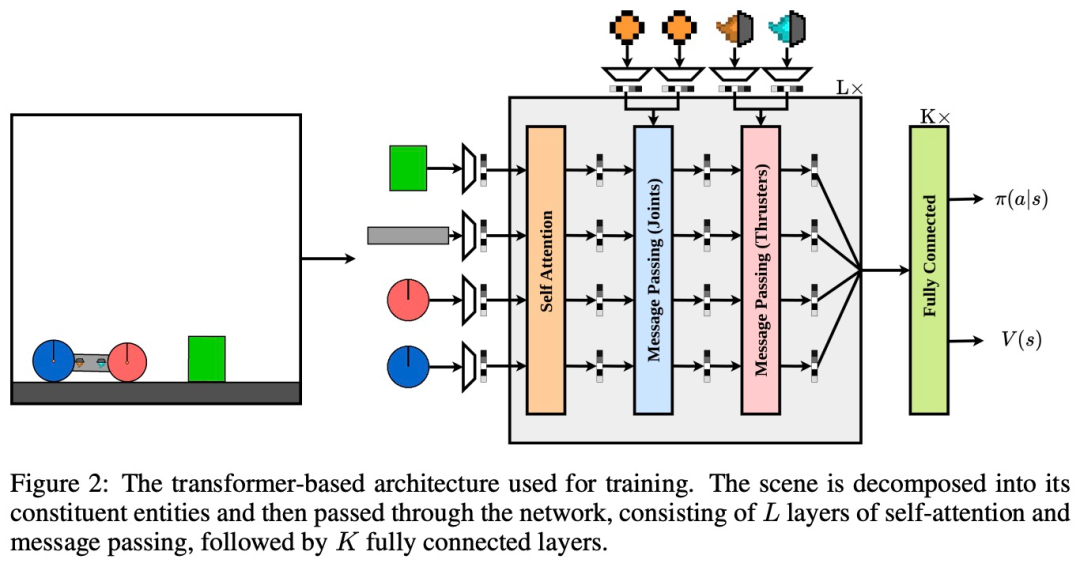
其中為了以置換不變的方式處理觀察結果,研究者將每個實體表徵為向量 v,其中包含物理屬性,比如摩擦、質量和旋轉。
零樣本結果
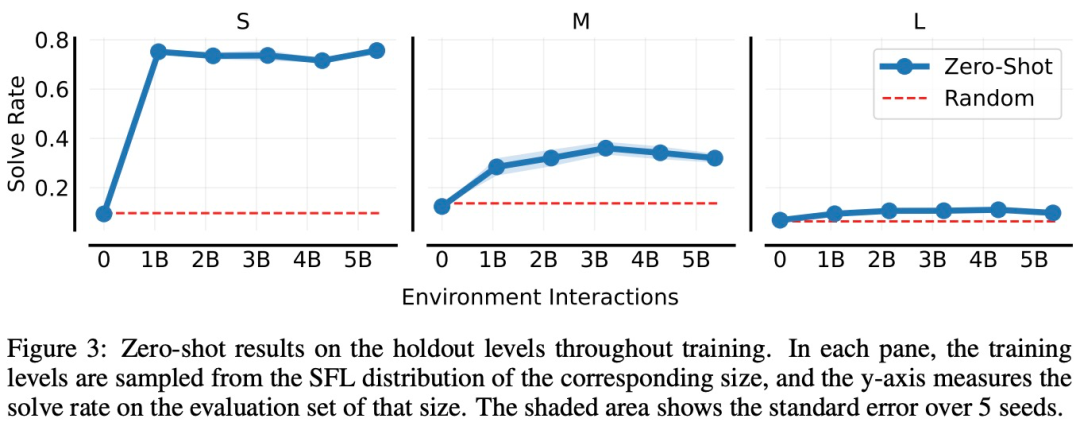
在下圖 3 中,研究者分別在 S、M 和 L 大小的環境中訓練 SFL。在每種情況下,訓練環境(隨機)具有相應的大小,而研究者使用相應的 holdout 集來評估智能體的泛化能力。
可以看到,在每種情況下,智能體的性能都會在訓練過程中提高,這表明它正在學習一種可以應用於未見過環境的通用策略。
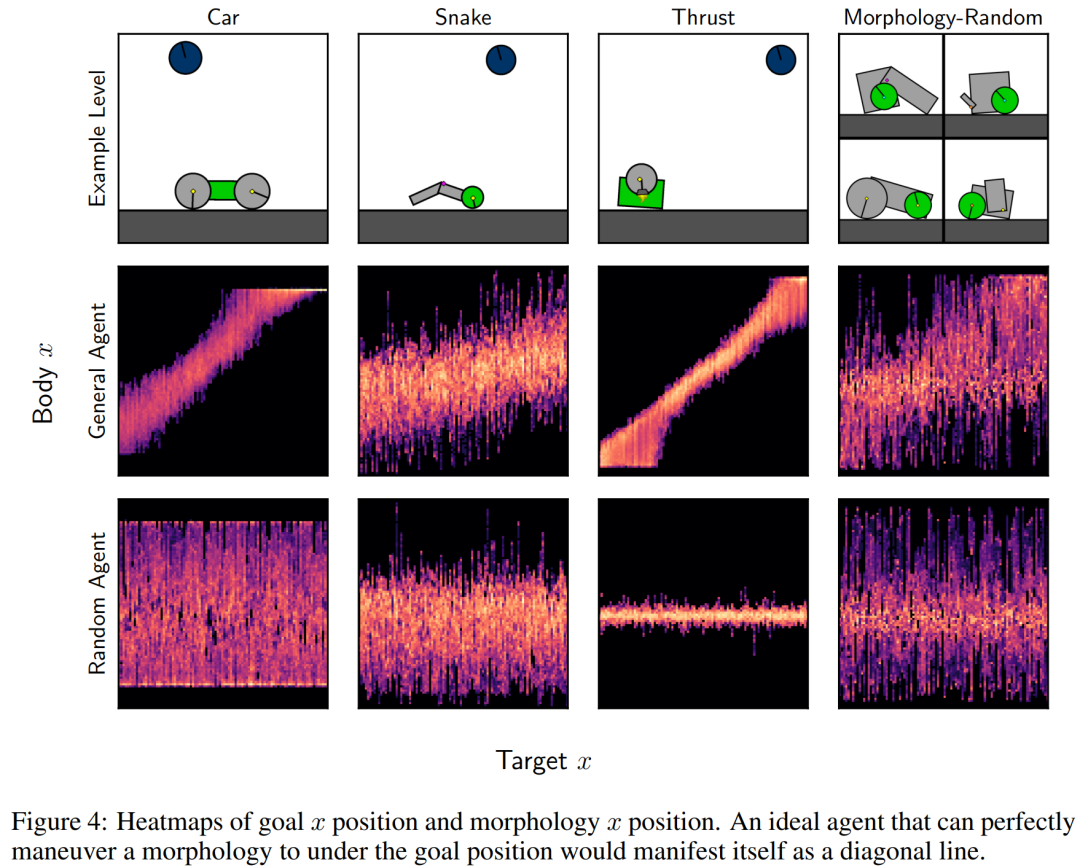
接下來,研究者通過探索學得的通用智能體在受限目標遵循設置中的行為,仔細探究了它的零樣本性能。具體來講,他們創建的關卡在其中心具有單一形態(一組與電機連接并包含綠色形狀的形狀),目標(藍色形狀)固定在關卡頂部,並且位置 x 是隨機的。
研究者測量了目標位置 x 與可控形態位置 x 之間的關聯,如下圖 4 所示。其中最佳智能體的行為表現為高相關性,因此會在對角線上表現出高發生率。他們還評估了在隨機 M 關卡上訓練 50 億時間步的隨機智能體和通用智能體。
正如預期的那樣,隨機智能體在可控形態和目標位置之間沒有表現出相關性,而經過訓練的智能體表現出了正相關性,表明它可以將操縱形態到目標位置。
微調結果
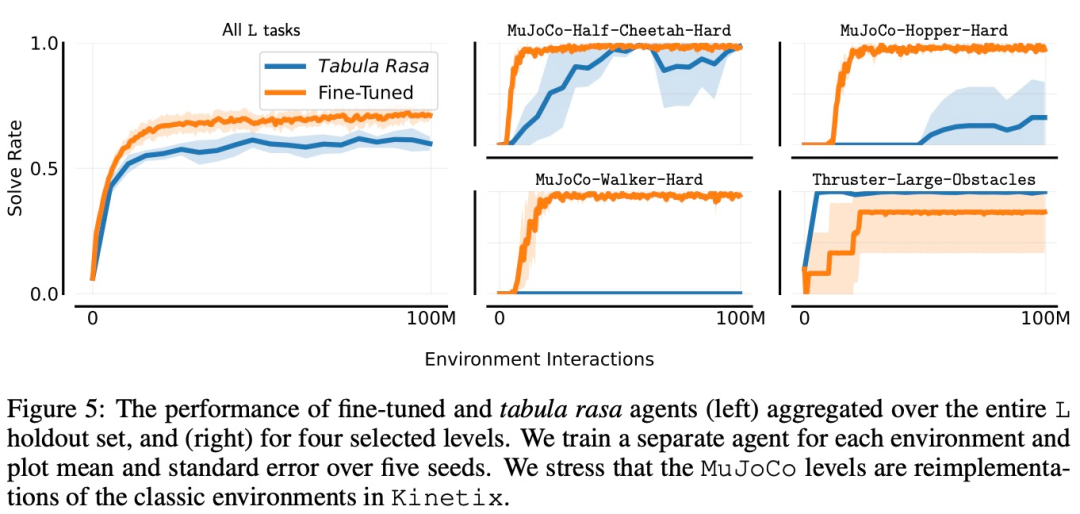
本節中,研究者探究了在使用給定有限樣本數量來微調 holdout 任務時,通用智能體的性能。在下圖 5 中,他們為 L holdout 集中的每個關卡訓練了單獨的專用智能體,並將它們與微調通用智能體進行比較。
研究者繪製了四個選定環境的學習曲線,以及整個 holdout 集的總體性能曲線。在其中三個關卡上,微調智能體的表現遠遠優於從頭開始訓練,尤其是對於 Mujoco-Hopper-Hard 和 Mujoco-Walker-Hard,微調智能體能夠完全勝任這些關卡,而白板智能體無法始終如一地做到這一點。
更多技術細節和實驗結果請參考原論文。



















