世界模型挑戰賽,單項獎金10000美元!英偉達全新分詞器助力下一幀預測

新智元報導
編輯:alan
【新智元導讀】近日,人形機器人公司1X公佈了世界模型挑戰賽的二階段:Sampling。一同登場的還有合作夥伴英偉達新發佈的Cosmos影片分詞器,超高質量和壓縮率助力構建虛擬世界。
AI時代的機器人怎麼訓練?
去年3月,挪威人形機器人公司1X拿到了OpenAI領投的2350萬美元,今年初又完成了1億美元的B輪融資。
作為OpenAI投資的第一家硬件公司,1X給出的答案是:世界模型(World Model)。

在這個時代,世界模型將成為解決通用仿真和評估問題,實現安全、可靠、智能機器人的有效途徑。
英偉達也表示,影片AI模型有望徹底改變機器人、汽車和零售等行業。
今年9月,1X介紹了自己的世界模型、新的高解像度機器人數據集,並開啟了一個三階段的世界模型挑戰賽。
10000美元挑戰賽

第一個挑戰是Compression,關於在極其多樣化的機器人數據集上如何最大限度地減少訓練損失。損失越低,模型就越能理解訓練數據。
本階段獎金10000美元,勝者為在給定的測試集實現損失8.0的第一個提交者。
截至小編碼字的時刻,挑戰依然有效。
第二個挑戰Sampling於近日公佈,側重於通過給定前一幀序列來預測下一幀,從而產生連貫且合理的影片延續,準確反映場景的動態。

1X鼓勵參賽者探索傳統next-logit預測之外的各種未來預測方法。比如Generative Adversarial Networks(GAN)、Diffusion Models和MaskGIT等技術都可用於生成下一幀。
本階段獎金同樣為10000美元,要求提交的PSNR應達到26.5左右或更高,評估服務器將於2025年3月開放。
為了助力此方向的研究,1X發佈了一個包含100小時原始機器人影片的新數據集,以及支持世界模型訓練的機器人狀態序列。
 數據集地址:https://huggingface.co/datasets/1x-technologies
數據集地址:https://huggingface.co/datasets/1x-technologies除此之外,1X還與英偉達的World Models團隊合作,使用他們新發佈的Cosmos影片分詞器進一步處理影片序列,為機器人數據創建了高度壓縮的時間表示。

1X World Model
在機器學習中,世界模型是一種計算機程序,可以想像世界如何響應智能體的行為而演變。
自動駕駛領域的發展,使影片生成和影片模型的研究獲得了巨大進步。
下一步,便是用於訓練機器人的世界模擬器。

從相同的起始圖像序列開始,世界模型可以預測不同機器人動作導致的多個未來。
 向左,向右,向前看~
向左,向右,向前看~它還可以預測重要的對象交互,比如剛體、對象掉落的效果、部分可觀察性:

可變形對象(窗簾、衣物):

鉸接對象(門、抽屜、窗簾、椅子):

世界模型解決了在構建通用機器人時一個非常實用但經常被忽視的挑戰:評估。
如果你訓練一個機器人執行1000項任務,怎樣才能確定與以前的模型相比,新模型使機器人在所有1000項任務中都做得更好?
另外,由於環境背景或環境照明的細微變化,即使是相同的模型權重,也可能在幾天內性能迅速下降。
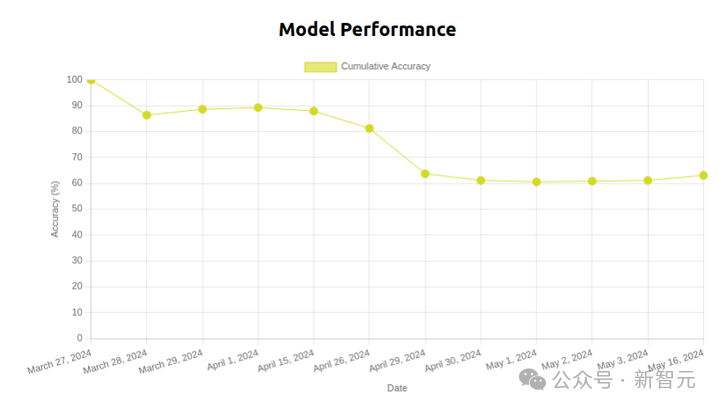 一個疊T恤模型在50天內的性能下降情況
一個疊T恤模型在50天內的性能下降情況如果環境隨著時間的推移而不斷變化,那麼舊實驗將不再可重現,尤其在家庭或辦公室等不斷變化的環境中,評估多任務系統將非常困難。
而如果沒有辦法進行嚴謹的評估,就無法預測增加數據、計算和參數量時,模型的能力將如何變化。
——機器人想要擁有自己的「ChatGPT時刻」, Scaling law必不可少。
基於物理的模擬
基於物理的模擬(Bullet、Mujoco、Isaac Sim、Drake)是快速測試機器人策略的合理方法,可重置、可重現。
但是,這些模擬器大多是為剛體動力學而設計的,
——如何模擬機器人手打開裝有咖啡過濾器的紙板箱、用刀切水果、擰開雪藏的蜜餞罐或者與人類交互?

眾所周知,家庭環境中遇到的日常物體和動物很難模擬,這些模擬器也缺乏現實世界用例的多樣性,對real或sim中有限數量的任務進行小規模評估,並不能預測現實世界中的大規模評估。
正確的打開方式
直接從原始傳感器數據中學習模擬器,並使用它來評估數百萬個場景中的策略,無需手動創建即可吸收現實世界的全部複雜性。
——世界模型閃亮登場。

在過去的一年里,1X的研究人員收集了數千小時的EVE人形機器人數據(在家中和辦公室執行各種移動操作任務,並與人互動),

將影片和動作數據相結合,訓練了一個新的世界模型。

世界模型能夠根據不同的動作命令生成不同的結果。
世界模型能夠根據不同的動作命令生成不同的結果,其主要價值來自模擬對象交互。
比如下面這個例子,為模型提供相同的初始幀和三組不同的抓取操作。在每種情況下,被抓取的箱子都會根據抓手的運動被抬起和移動,而其他箱子則不受干擾。

即使沒有提供操作,世界模型也會生成合理的影片,例如駕駛時應避開人和障礙物:

世界模型還可以生成長視距影片,比如完整的T恤摺疊演示(T恤和可變形物體往往很難在剛體模擬器中實現)。
英偉達Cosmos分詞器
分詞器(Tokenizer)將冗餘和隱式視覺數據映射到緊湊的語義token中,從而能夠高效訓練大規模生成模型,並在有限的計算資源上實現推理。
目前的一些開源影片和圖像分詞器經常產生糟糕的數據表示,導致有損重建、圖像失真和影片時間不穩定,並限制了建立在分詞器之上的生成模型的能力。
低效的分詞過程還會導致編碼和解碼速度變慢,訓練和推理時間變長,從而對開發人員的工作效率和用戶體驗產生負面影響。
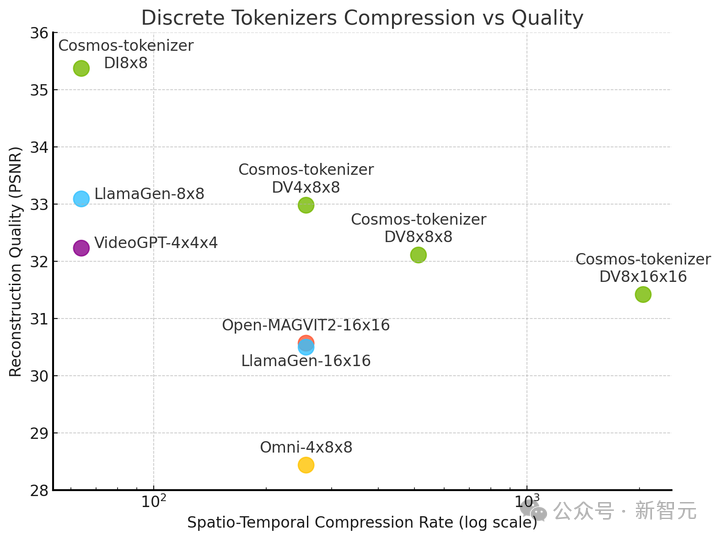
英偉達於近日開源了全新的分詞器Cosmos,在各種圖像和影片類別中提供了極高的壓縮率和極高的重建質量。

Cosmos支持具有離散潛在代碼的視覺語言模型(VLM)、具有連續潛在嵌入的擴散模型,以及各種縱橫比和解像度。
分詞器架構
Cosmos分詞器使用複雜的編碼器-解碼器結構,核心是一個3D因果卷積塊,用於同時處理時空信息,並使用因果時間注意力來捕獲數據中的長期依賴關係。
因果結構確保模型在執行分詞時僅使用過去和現在的幀,避免將來的幀。這對於與許多現實世界系統的因果性質保持一致至關重要,例如物理AI或多模態LLM。
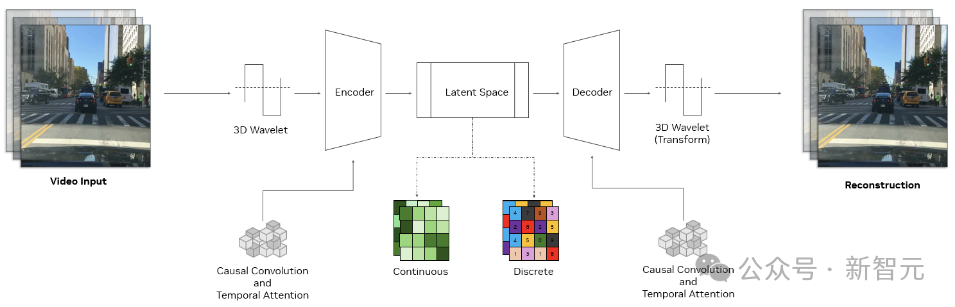
使用3D小波(可以更高效地表示像素信息的信號處理技術)對輸入進行下采樣,處理完數據後,逆小波變換會重建原始輸入。
這種方法提高了學習效率,使分詞器的可學習模塊能夠專注於有意義的特徵,忽略多餘的像素細節。
在推理測試中,與領先的開源分詞器相比,Cosmos分詞器的重建速度提高了12倍,顯著降低了模型的運行成本。
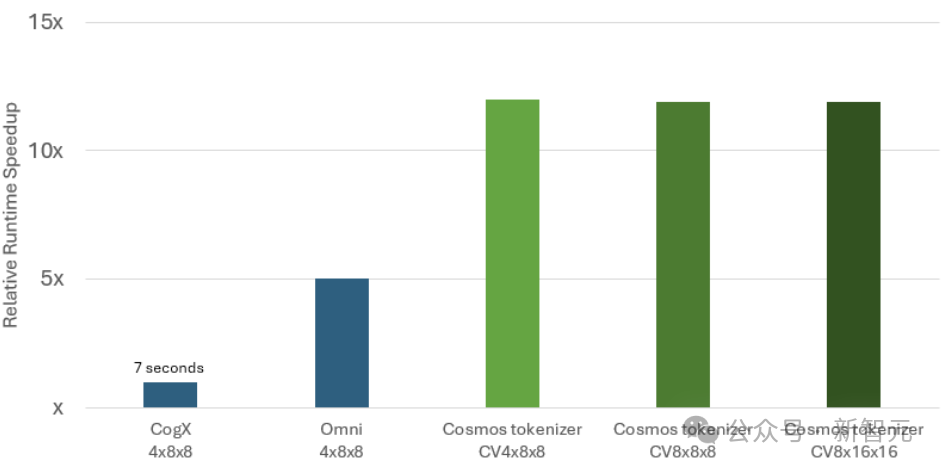
與連續型分詞器PK:
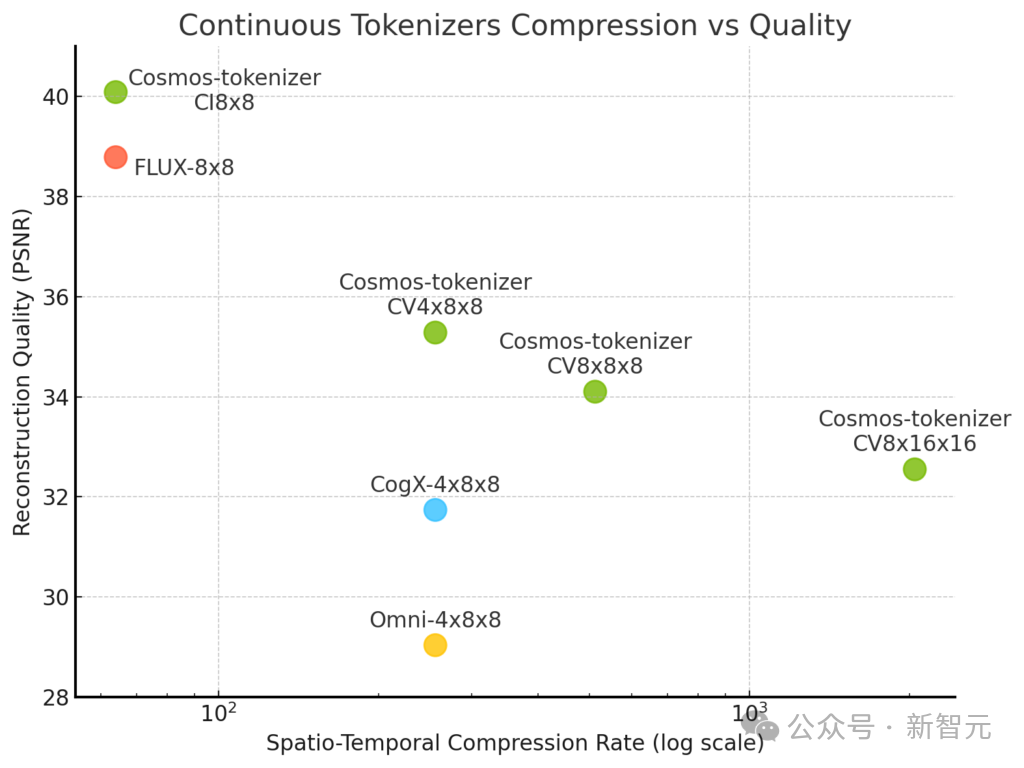
與離散型分詞器PK:
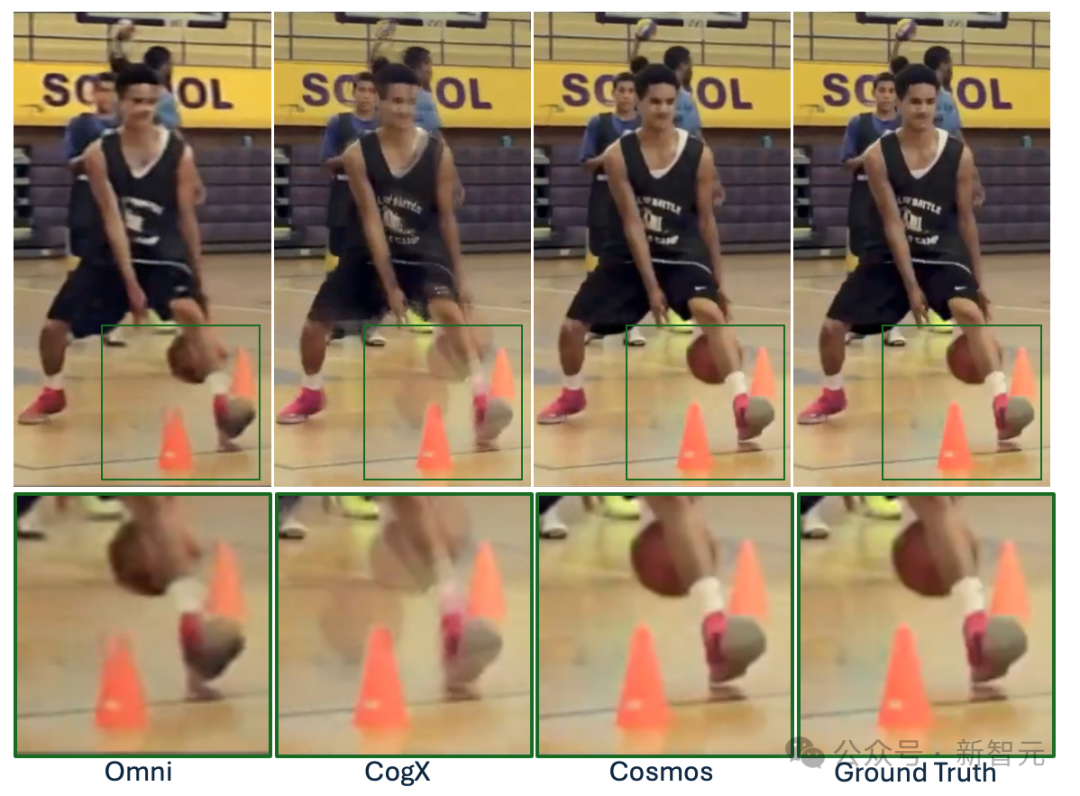
有圖有真相:
 參考資料:
參考資料:https://x.com/ericjang11/status/1854226268763644148
https://www.1x.tech/discover/1x-world-model-sampling-challenge
https://github.com/NVIDIA/Cosmos-Tokenizer



















