指令跟隨大比拚!Meta發佈多輪多語言基準Multi-IF:覆蓋8種語言,超4500種任務

新智元報導
編輯:LRST 好睏
【新智元導讀】Meta全新發佈的基準Multi-IF涵蓋八種語言、4501個三輪對話任務,全面揭示了當前LLM在複雜多輪、多語言場景中的挑戰。所有模型在多輪對話中表現顯著衰減,表現最佳的o1-preview模型在三輪對話的準確率從87.7%下降到70.7%;在非拉丁文字語言上,所有模型的表現顯著弱於英語。
在大語言模型(LLMs)不斷髮展的背景下,如何評估這些模型在多輪對話和多語言環境下的指令遵循(instruction following)能力,成為一個重要的研究方向。
現有評估基準多集中於單輪對話和單語言任務,難以揭示複雜場景中的模型表現。
最近,Meta GenAI團隊發佈了一個全新基準Multi-IF,專門用於評估LLM在多輪對話和多語言指令遵循(instruction following)中的表現,包含了4501個三輪對話的多語言指令任務,覆蓋英語、中文、法語、俄語等八種語言,以全面測試模型在多輪、跨語言場景下的指令執行能力。
 論文鏈接:https://arxiv.org/abs/2410.15553
論文鏈接:https://arxiv.org/abs/2410.15553Multi-IF下載鏈接:https://huggingface.co/datasets/facebook/Multi-IF
實驗結果表明,多數LLM在多輪對話中表現出顯著的性能衰減。
例如,表現最佳的o1-preview模型在第一輪指令的平均準確率為87.7%,但到第三輪下降至70.7%
此外,非拉丁文字語言(如印地語、俄語和中文)的錯誤率明顯更高,反映出模型在多語言任務中的局限性。這些發現展示了當前LLM在處理複雜多輪和多語言指令任務上的挑戰和改進空間。
Multi-IF的發佈為研究人員提供了更具挑戰性的評估基準,有望推動LLM在全球化、多語言應用中的發展。
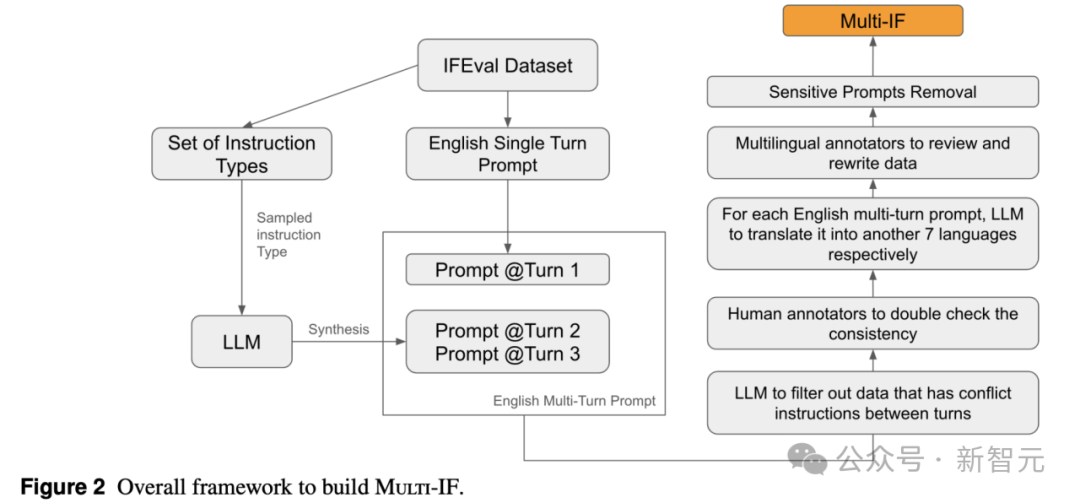
數據集構建
Multi-IF數據集的構建過程經過了多輪精細的設計和篩選,既有模型也有人類專家的參與。
多輪擴展
首先,研究團隊基於已有的單輪指令遵循數據集IFEval,將每個單輪指令擴展為多輪指令序列。通過隨機采樣和模型生成,研究團隊為每個初始指令增加了兩輪新指令,形成一個完整的三輪對話場景。
首先隨機采樣一個指令類型(Intruction Type)比如「字數限制」、「限制輸出格式為列表」、「添加特定關鍵短語」等等,然後將之前的指令和這個指令類型提供給語言模型,讓它生成一個符合上下文的指令,比如「旅行計劃不超過400詞」;隨機采樣可能導致指令之間存在衝突。
為了確保多輪指令的邏輯一致性和層次遞進性,研究團隊設計了一套兩步衝突過濾機制:
1. 模型過濾:使用Llama 3.1 405B模型自動檢測可能存在矛盾的指令組合。例如,如果第一輪要求生成詳細描述,而第二輪要求簡潔總結,這種衝突指令會被篩選出來。
2. 人工審核:在初步過濾後,團隊通過人工標註對指令進行細化和調整,以確保每一輪指令既具有挑戰性又保持邏輯連貫。
多語言擴展
為了提高數據集的多語言適用性,研究團隊採用了以下方法將數據集從英文擴展至多語言版本:
1. 自動翻譯:使用Llama 3.1 405B模型將原始英語指令翻譯為中文、法語、俄語、印地語、西班牙語、意大利語和葡萄牙語七種語言。
2. 人工校對:翻譯結果經過語言專家的人工審校,以確保在語義和語法上貼合各語言的自然使用習慣,同時消除因翻譯可能帶來的歧義或誤導。
這一多輪擴展和多語言適配的構建流程,使Multi-IF成為全面評估LLM指令遵循能力的強大工具。
總體實驗結果
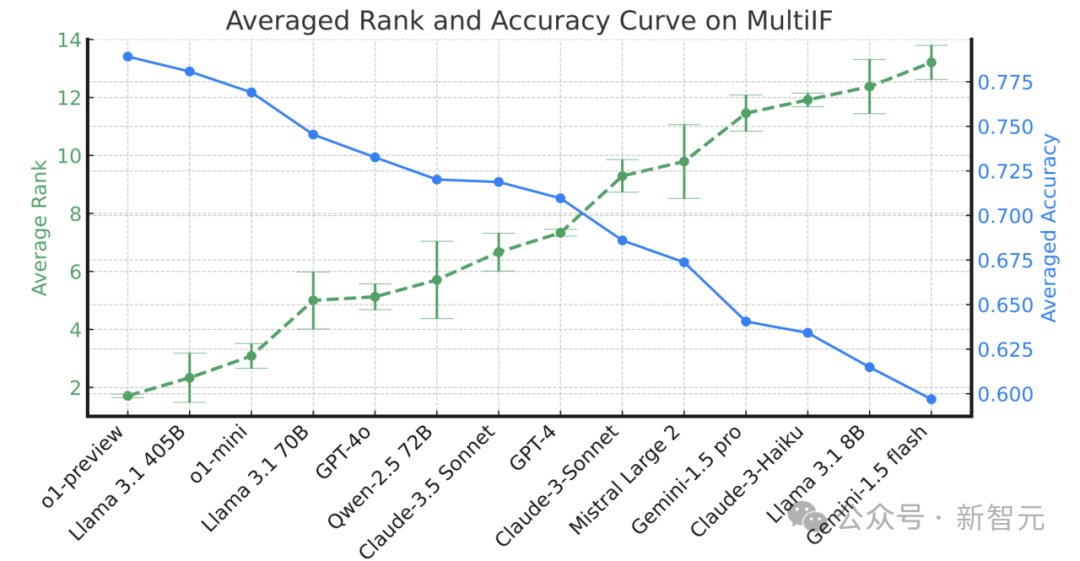
在Multi-IF基準上,Meta團隊對14種最先進的大語言模型(LLMs)進行了評估,涵蓋了OpenAI的o1-preview、o1-mini,GPT-4o,Llama 3.1(8B、70B和405B),Gemini 1.5系列,Claude 3系列,Qwen-2.5 72B,以及Mistral Large等。
實驗顯示,整體上o1-preview和Llama 3.1 405B表現最佳,在平均準確率上領先其他模型。特別是在多輪指令任務中,o1-preview和Llama 3.1 405B模型在三輪指令的平均準確率分別為78.9%和78.1%,展現了較高的指令遵循能力。
多輪對話中的指令遵循
實驗表明,所有模型在多輪對話中的指令遵循準確率隨著輪次增加而顯著下降。這種下降在某些模型中尤為明顯,如Qwen-2.5 72B在第一輪準確率較高,但在後續輪次中的表現迅速下滑。
相比之下,o1-preview和Llama 3.1 405B在多輪任務中的準確率相對穩定,展現出較強的持續指令遵循能力。總體而言,這些結果說明,多輪對話對當前LLM構成了較大挑戰,模型在多輪次中遵循指令的能力有待提高。
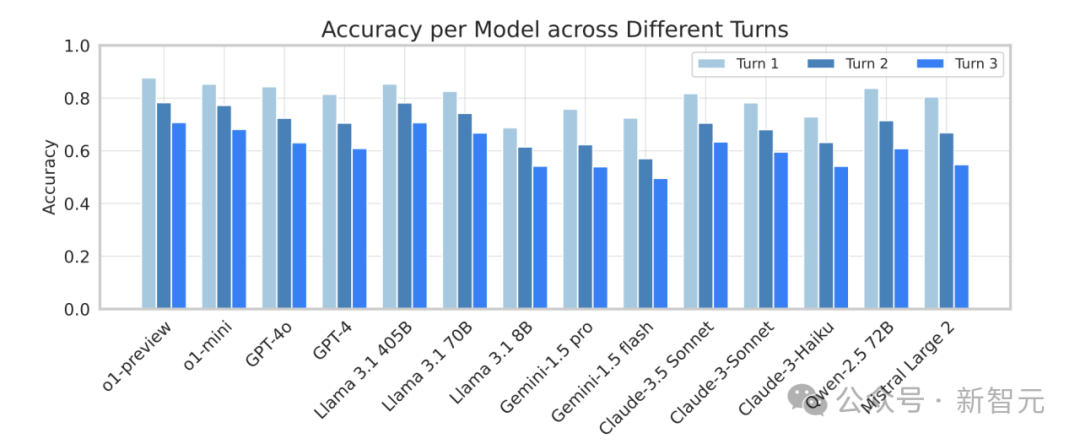
多輪對話中的指令遺忘
在多輪對話中,模型往往出現「指令遺忘」現象,即在後續輪次中未能遵循前一輪成功執行的指令,研究團隊引入了「指令遺忘率」(Instruction Forgetting Ratio, IFR)來量化這種現象。
IFR值表明,高性能模型如o1-preview和Llama 3.1 405B在多輪對話中的遺忘率相對較低,而有些模型比如Gemini在IFR值上明顯偏高,表現出較高的指令遺忘傾向。
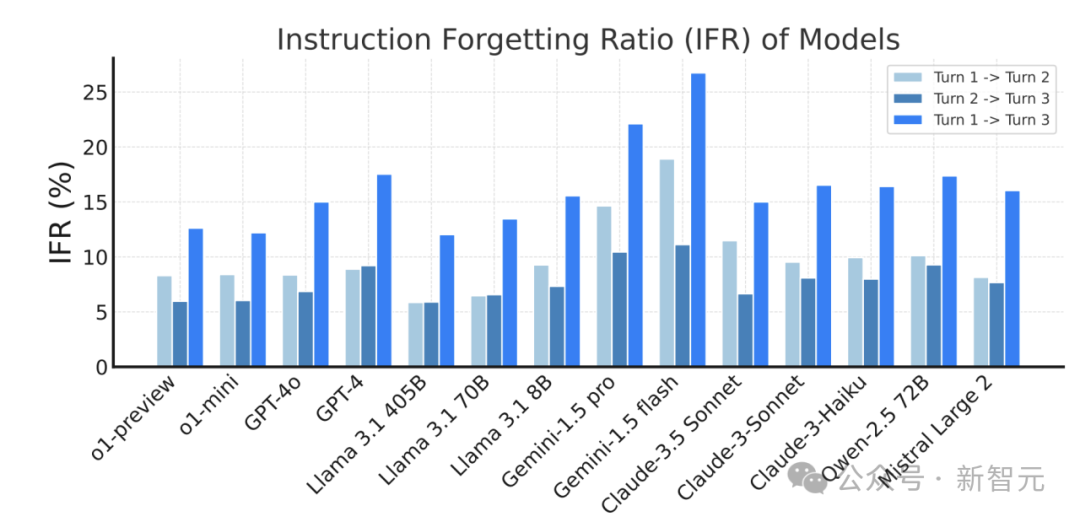
此外,對於Llama 3.1系列模型,隨著模型規模從8B擴展到405B,其指令遺忘率(即IFR)逐漸降低。這表明,增大模型規模可以有效提升其在多輪對話中保持指令一致性的能力。
多輪對話中的自我糾正
模型在多輪任務中是否能夠糾正之前的錯誤也是一個重要的性能衡量標準,實驗通過計算「錯誤自我修正率」(Error Correction Ratio, ECR)來評估這一能力。
結果顯示,o1-preview和o1-mini在錯誤自我修正方面表現突出,能夠在後續輪次中糾正約25%的之前未遵循的指令。這些模型似乎能夠利用某種「反思」能力來提高指令執行的水平。
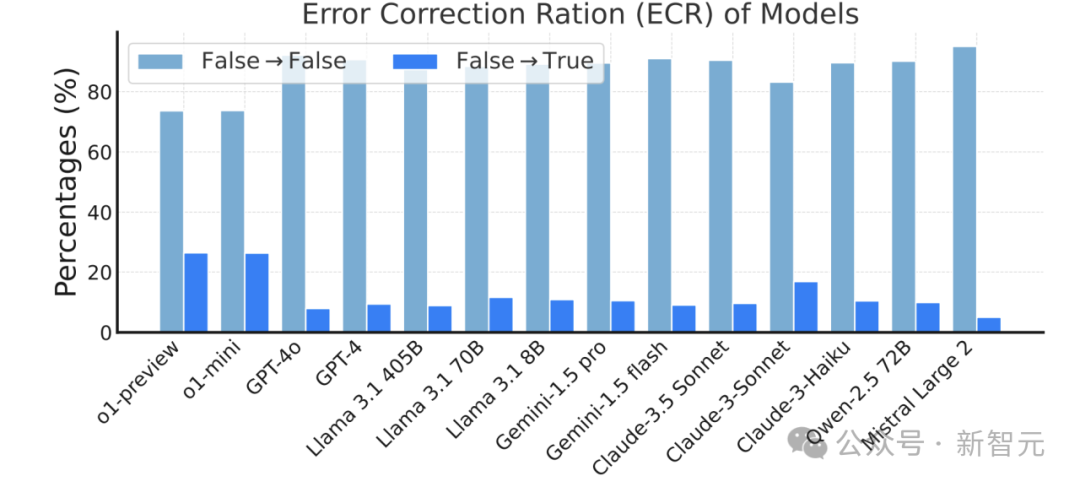
相比之下,其他模型在自我修正方面表現一般,這一結果表明,具備反思能力的模型在多輪任務中能夠更好地處理錯誤並提升指令遵循的穩定性。
多語言指令遵循
在多語言環境下,模型的指令遵循能力表現出顯著的語言差異。實驗顯示,英語的指令執行準確率普遍最高,尤其是在Llama 3.1 405B模型上,英語準確率接近0.85。法語和意大利語的表現也較為接近英語,而俄語、印地語和中文等非拉丁文字的準確率則明顯較低。
例如,o1-preview模型在俄語和印地語中的準確率低於其在英語、法語等語言中的表現。總體而言,非拉丁文字語言的錯誤率高於拉丁文字語言,這在多語言指令任務中尤為突出。
實驗結果還表明,不同模型在多語言指令遵循中的表現存在一定差異。o1-preview在所有語言中的表現相對穩定,並在中文、西班牙語、意大利語和印地語中稍勝Llama 3.1 405B,而GPT-4o的表現則略遜於前兩者。
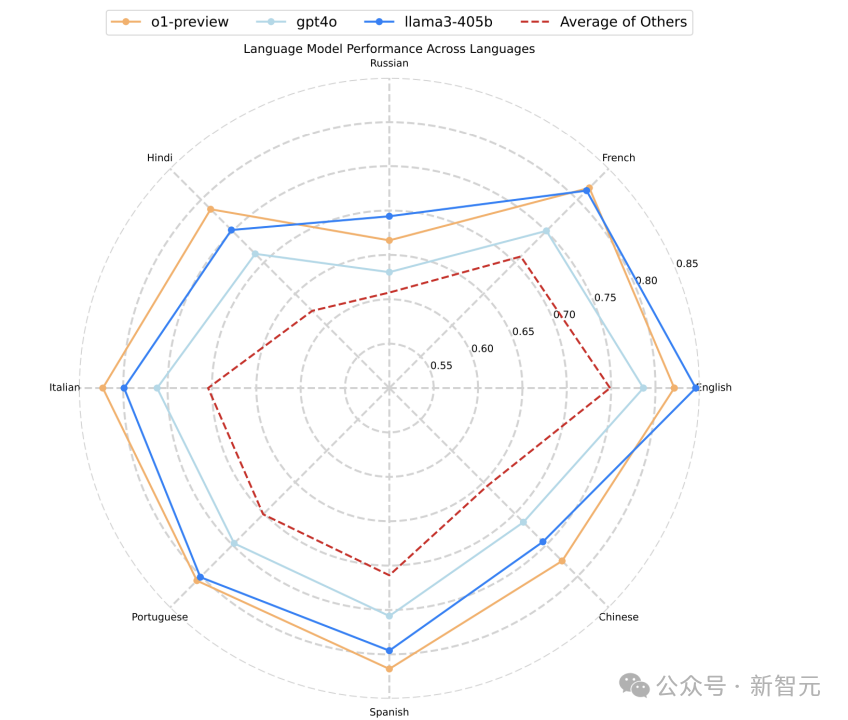
平均而言,非拉丁文字的語言往往會出現更高的指令遵循錯誤,表明當前模型在多語言環境,尤其是對非拉丁文字的支持方面,仍有提升空間。
這些結果反映出,儘管現有的先進LLM在多語言任務上已經展現出一定的能力,但在處理俄語、印地語和中文等非拉丁文字語言的指令遵循任務時仍存在明顯的局限性。這也為未來多語言模型的改進指出了明確的方向。
結論
綜上所述,Multi-IF基準通過多輪對話和多語言環境的複雜指令任務,揭示了當前大語言模型在指令遵循能力上的不足之處。
實驗結果表明,多數模型在多輪任務中存在準確率下降和指令遺忘的問題,且在非拉丁文字的多語言任務中表現較差。Multi-IF為進一步提升LLM的多輪對話和跨語言指令遵循能力提供了重要的參考。
作者介紹

通訊作者Yun He(賀贇)是Meta GenAI團隊的一名研究科學家,博士畢業於Texas A&M University,專注於大語言模型Post-training的研究和應用。
他的主要研究方向包括指令跟隨(instruction following)、推理能力(Reasoning)以及工具使用(tool usage),旨在推動大語音模型在複雜多輪對話中的表現。

共同一作金帝是Meta GenAI Senior Research Scientist,負責Meta AI Agentic Code Execution和Data Analysis方向,博士畢業於MIT。
主要研究方向為大模型後訓練對齊(RLHF,Alignment),模型推(Model Reasoning),和大模型智能體(Agent)方向。
參考資料:
https://arxiv.org/abs/2410.15553