大模型創業太累大牛逃回大廠:融資1億美金捉襟見肘,沒日沒夜加班胖了30斤
小牛馬 發自 凹非寺
量子位 | 公眾號 QbitAI
大模型創業太累,又一大牛決定重回大廠。
Yi Tay,曾是Reka AI聯合創始人,也曾是Google大模型PaLM、UL2、Flan-2、Bard的重要參與者。

本週是他回到Google的第一週,也是他離職創業一年半之後,選擇回歸老身份的開始。
他將繼續擔任GoogleDeepMind高級研究員,向Google大神、也是他之前的老闆Quoc Le彙報。
回顧過去這段創業經歷,他表示學到了很多,比如基礎設施方面的知識、如何從頭開始訓練大模型等等。
但與此同時,他也經歷了一些不那麼好的時刻:
公司費勁籌集的一億多美金,對於一個不到15個人的團隊仍然緊張,還差點賣身自救。
個人層面,他的身心健康受到了很大影響。由於工作強度大和不健康的生活方式,他還長胖了15公斤。
為此他表示:
放棄舒適區並創業對我個人來說真的很可怕。
大牛重回Google大廠
去年三月末,他官宣離職Google參與創業RekaAI,並擔任該公司的首席科學家。
在此之前,他在Google大腦工作了3.3年,參與諸多大模型的研究,撰寫累計約45篇論文,其中16篇一作,包括UL2、U-PaLM、DSI、Synthesizer、Charformer和Long Range Arena等,約20次產品發佈,妥妥大牛一位。

從技術角度上講,他坦言學到了很多關於在Google沒法學到的知識。
比如學會使用Pytorch/GPU 和其他外部基礎設施,以成本最優的方式從頭構建非常好的模型。
為此他還在個人網站上分享了相關經驗:訓練模型的首要條件是獲取計算能力,但這一過程就好像買彩票。
並非所有硬件都是一樣的。不同算力提供商的集群質量差異非常大,以至於要想訓練出好的模型需要付出多大的代價,這簡直就是在抽籤。簡而言之,LLM 時代的硬件彩票。
這與在Google使用TPU相比,這些GPU的故障率讓他大吃一驚。
此外他還「抽水」外部代碼庫的質量遠遠落後Google的質量,這些代碼庫對大規模編碼器-解碼器訓練的支持非常少。
但這種持續遇到問題持續解決的經驗, 並非痛苦反而很有趣,並且最終憑藉著自身技術實力也挺了過來。
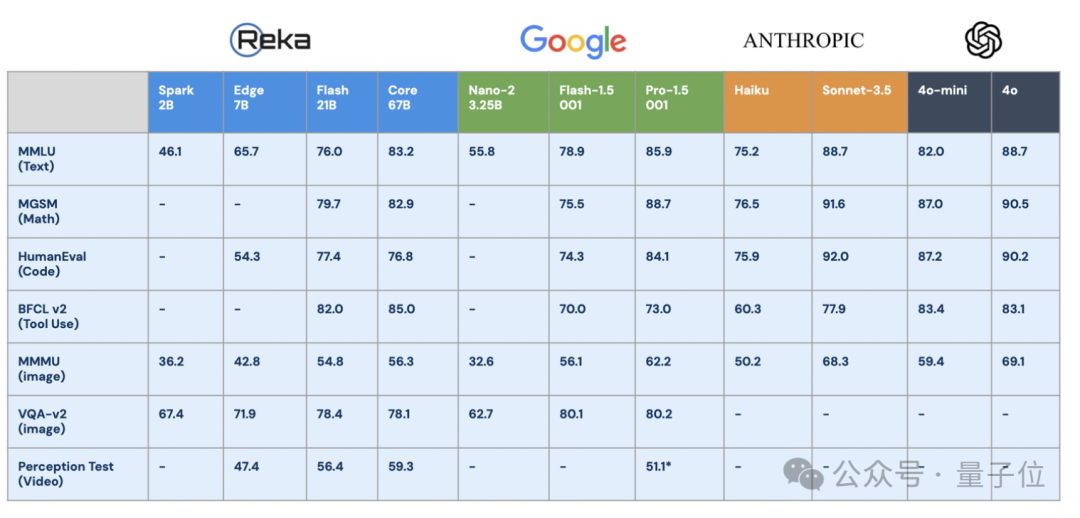
在創業初期,他們的旗艦模型Reka Core在Lmsys首次亮相,就躋身第7位,公司排名前五,實現了對GPT-4早期版本的超越。
目前他們主要有四個模型,適用於不同的應用場景。
而真正「打倒」他驅使他離職的,是更為現實的原因。
就公司層面來說,作為初創企業,其資金、算力和人力跟其他實驗室相比都要少得多。
就算他們分批籌集了一億多美金,對於一個不到15人的團隊仍然不夠。
今年5月Reka AI還被曝出賣身自救,Snowflake正就以超過 10 億美元收購Reka AI的事宜談判。
不過現在來看,收購事宜還沒有談成。在Yi Tay宣佈新動向後,他們緊急發聲,現在公司還在積極招人ing。

而就他個人來說,這是段非常緊張的時期。尤其剛開始創業的時候妻子懷孕,他不得不同時兼顧兩邊,由此身心健康受到很大的損害。
並且由於高強度的工作和不健康的生活方式,他長胖了15公斤。
不過他自己也曾透露過自己有睡眠障礙。

種種原因,他決定重回Google,回歸到一個研究者的身份。

在初創企業世界探索了一年半之後,我決定回歸我的研究根基。
在分享經歷的開始,他寫下了這樣一句話。
回到Google之後,他將探索與大模型相關的研究方向,以高級研究員的身份,向大神Quoc Le彙報。
在博客的最後,他感謝了創業這段時間始終聯繫的Google老朋友。
並且還特地感謝了在新加坡同他共進晚餐的Jeff Dean,並且提醒他Google 很棒。(Doge)

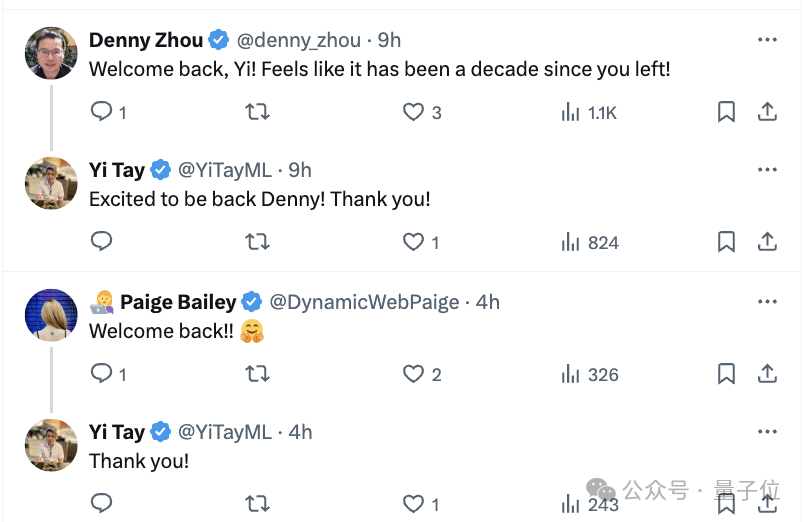
Google老同事:歡迎回來
一些Google老同事在底下紛紛表示:Welcome back!感覺像是過了十年。
值得一提的是,像這種大牛重返大廠並非個例。
今年8月Google以25億美元打包帶走了明星AI獨角獸Character.AI的核心技術團隊,遠高於Character.AI 10億美元的估值。
其中包括兩位創始人——Transformer「貢獻最大」作者Noam Shazeer和Daniel De Freitas。其中Noam Shazeer出任Gemini聯合技術主管。
這樣看起來,對於這些大牛來說,大模型創業確實不易,重返大廠確實是個不錯的選擇,至少錢夠算力夠、安安心心做研究。
而隨著新一輪的洗牌期到來,更多技術大牛朝著科技巨頭聚攏,也已經初見端倪。
參考鏈接:
[1]https://x.com/YiTayML
[2]https://www.yitay.net/?author=636616684c5e64780328eece
[3]https://www.yitay.net/blog/training-great-llms-entirely-from-ground-zero-in-the-wilderness
[4]https://www.yitay.net/blog/leaving-google-brain