大模型接入數據有了「統一插頭」,Agent平台慌了?
現在你可以通過Claude直接控制和訪問本地數據庫,以及Google Drive、Slack、GitHub等平台的數據了。
近日,Anthropic開源了「模型上下文協議」(MCP),該協議將大模型直接連接至數據源,簡單來說,現在企業和開發者要把不同的數據接入AI系統,都得單獨開發對接方案,而MCP要做的,就是提供一個「通用」協議來解決這個問題。
Anthropic在博客中解釋說:「即便是最先進的模型,也受困於無法獲取數據的限制,它們被困在信息孤島和老舊系統之中。每接入一個新的數據源,就得重新開發一套對接方案,這讓真正互聯的系統很難大規模推廣。」
MCP架構包含以下幾個部分:
-
MCP主機:包括Claude Desktop、IDE等需要通過MCP訪問資源的AI工具
-
MCP客戶端:與服務器保持一對一連接的協議客戶端
-
MCP服務器:一個輕量級程序,通過標準化的MCP協議開放特定功能
-
本地資源:計算機上的數據庫、文件和服務等資源,MCP服務器可以安全地訪問這些內容
-
遠程資源:通過互聯網訪問的API等資源,MCP服務器可以與之建立連接
Anthropic提到,美國金融服務公司Block Inc.已經把MCP整合進了他們的系統。Zed、Replit、Codium和Sourcegraph這些開發工具公司也在和Anthropic合作,準備接入這套協議。
Anthropic在解釋這個協議的實用性時表示:「隨著生態系統逐漸成熟,AI系統在不同工具和數據集之間切換時能夠保持上下文連續性,這樣就能用一個更可持續的架構,來取代現在這種零零散散的集成方式。」
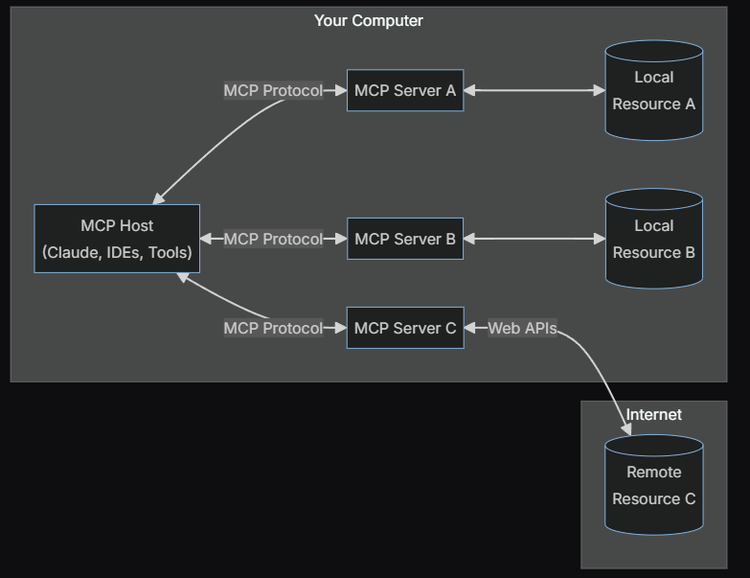 模型上下文協議(MCP)讓AI系統能靈活調用不同的數據源
模型上下文協議(MCP)讓AI系統能靈活調用不同的數據源Claude關係負責人Alex Albert表示,「MCP之所以強大,部分原因在於它通過同一協議處理本地資源(如數據庫、文件、服務)和遠程資源(如Slack或GitHub的API)」。
 Anthropic官方為MCP提供了一個開源的Servers的貢獻庫
Anthropic官方為MCP提供了一個開源的Servers的貢獻庫和Anthropic一樣,OpenAI也在試圖用更簡單的方法把各種數據源接入到模型中。今年11月初,OpenAI推出了一個「Work with Apps」的新功能。這個功能目前只支持MacOS,它讓ChatGPT能讀取VS Code、Xcode、Terminal和iTerm2這些平台上的內容,從而給出更準確的回答。
這些都是開發工具,接入ChatGPT後,開發者就能直接問ChatGPT關於代碼的問題,也能獲取相關建議。
OpenAI還提到,ChatGPT會把這些內容存到用戶的聊天記錄里,這樣OpenAI就能把它當作訓練數據來用。如果用戶不想讓ChatGPT接觸自己的代碼數據,可以通過數據控制功能來阻止,或者使用臨時聊天窗口。
相比之下,Anthropic似乎正試圖通過MCP建立一個更加開放和標準化的AI數據接入生態系統。
為數據集成建立標準
目前還沒有一個統一的方式來連接數據源和模型,主要靠企業用戶、模型提供商和數據庫供應商自己拿主意。開發者一般會寫特定的Python代碼或者用LangChain來讓大模型連接數據庫。由於每個大模型的運作方式都不一樣,開發者需要給每個模型寫不同的代碼來連接特定的數據源。這就導致不同的模型雖然都在調用同一個數據庫,卻沒法很好地協同工作。
從大模型行業從業者osmboy從接口標準化的角度看待MCP,MCP可以類比為Mac筆記本的接口:「只不過充電,外接顯示器以及插本地U盤什麼的都用一個接口統一起來了」。
他認為該協議的核心價值在於為大模型數據集成提供了統一標準,不僅能提高開發和使用效率,還能增強大模型的實際應用能力。
從技術演進來看,在MCP出現之前,業界主要依賴RAG和微調等方案,以及各類Agent應用來實現數據集成,「但比較常用的方案是基於langchain和llamaindex做應用以及數據集成,總體來說各做各的,比較繁雜,不統一」,
像Dify、Coze這些平台,都是借助llamaindex和langchain構建,雖然這些方案能夠滿足需求,但整體來說比較零散,缺乏統一標準。「Cozy和Dify都可能會支持MCP協議來做數據集成。」
他告訴矽星人,MCP的長期潛力在於建立一個統一的生態系統,從而降低開發門檻。隨著這個開源協議的推廣,未來大模型的數據集成可能都會採用這個標準接口,從而降低開發門檻,提高生產力。
也有用戶持更為謹慎的態度,對MCP這類標準的價值提出了質疑:MCP想要標準化數據訪問、提升性能,但這解決不了Claude的根本問題,比如它沒法從錯誤中學習,也沒法穩定地執行指令。「連Claude自己都承認它不能從反饋中學習,這就讓所謂的智能體發展聽起來很不可靠。一個連基本任務都做不好的工具,就算數據訪問再怎麼流暢,也支撐不了自主系統。」
另外一位開發者認為,相較於從頭開始做協議,OpenAI嘗試通過與一家已將業務API化的現有公司合作來解決這一問題,這種方法看起來更為可行。
邁向Agent的下一步?
Anthropic在上個月推出了Compute Use之後,這次又發佈了幫助大模型接入外部數據和工具的MCP,這兩者都是在向Agentic工作流的方向邁進。
AIGCLINK發起人佔冰強告訴矽星人,MCP相當於一個萬能的數據插頭,實際上打通了Agent構建的最後一公里,並且MCP是開源的,這就意味著未來每個公司都可以構建一個像扣子、Dify那樣的平台。
「基本上可以說如果你還在做agent的中間件,我覺得基本上可以歇菜了。Anthropic把MCP這套東西完全開放,我相信後面全球的大模型公司都會跟進。」
他認為,原來的Agent的中間件是區別於扣子、GPTstore這一類的平台,為開發者解決隱私安全、知識產權的問題。「以前你用扣子這類的平台,比如有人複製了你的智能體的工作流,你也不可能去打官司,所以有很多的問題在裡面。」
現在有的MCP之後,「工作流基本上都可以完全在本地,而且沒有任何的商業授權的問題。」因此,模型方和應用方的分工會越來越明確。使得中間件平台的空間被壓縮了。

在AI領域,Anthropic一直以穩健謹慎的作風著稱,主要通過發表研究論文的方式對外分享其技術進展,與Meta等競爭對手相比,這家公司極少開源,主要產品Claude及其底層模型都處於嚴格管控之下。MCP的開源或許反映了Anthropic在數據接入標準化領域的野心,希望通過建立行業通用標準來擴大影響力。
總的來看,MCP的出現確實為AI系統接入數據源提供了一個新思路,但要真正普及還面臨不少挑戰。首先是生態建設問題,能否吸引足夠多的開發者和企業採用仍是未知數。
不過作為一次標準化的嘗試,MCP的意義在於它可能幫助簡化目前較為混亂的數據接入現狀。接下來的關鍵是看市場的反應,開發者是否會覺得這個方案足夠實用,以及其他AI公司會採取什麼樣的應對策略。畢竟在技術標準的競爭中,市場的選擇往往比技術本身更重要。
本文來自微信公眾號:矽星人Pro (ID:gh_c0bb185caa8d),作者:週一笑



















