超越 GPT-4o!開源科研神器登場
【導讀】Ai2和華盛頓大學聯合Meta、CMU、史丹福等機構發佈了最新的OpenScholar系統,使用檢索增強的方法幫助科學家進行文獻搜索和文獻綜述工作,而且做到了數據、代碼、模型權重的全方位開源。
LLM集成到搜索引擎中,可以說是當下AI產品的一個熱門落地方向。
前有Perplexity橫空出世,後有GoogleGemini和OpenAI的SearchGPT紛紛加入。
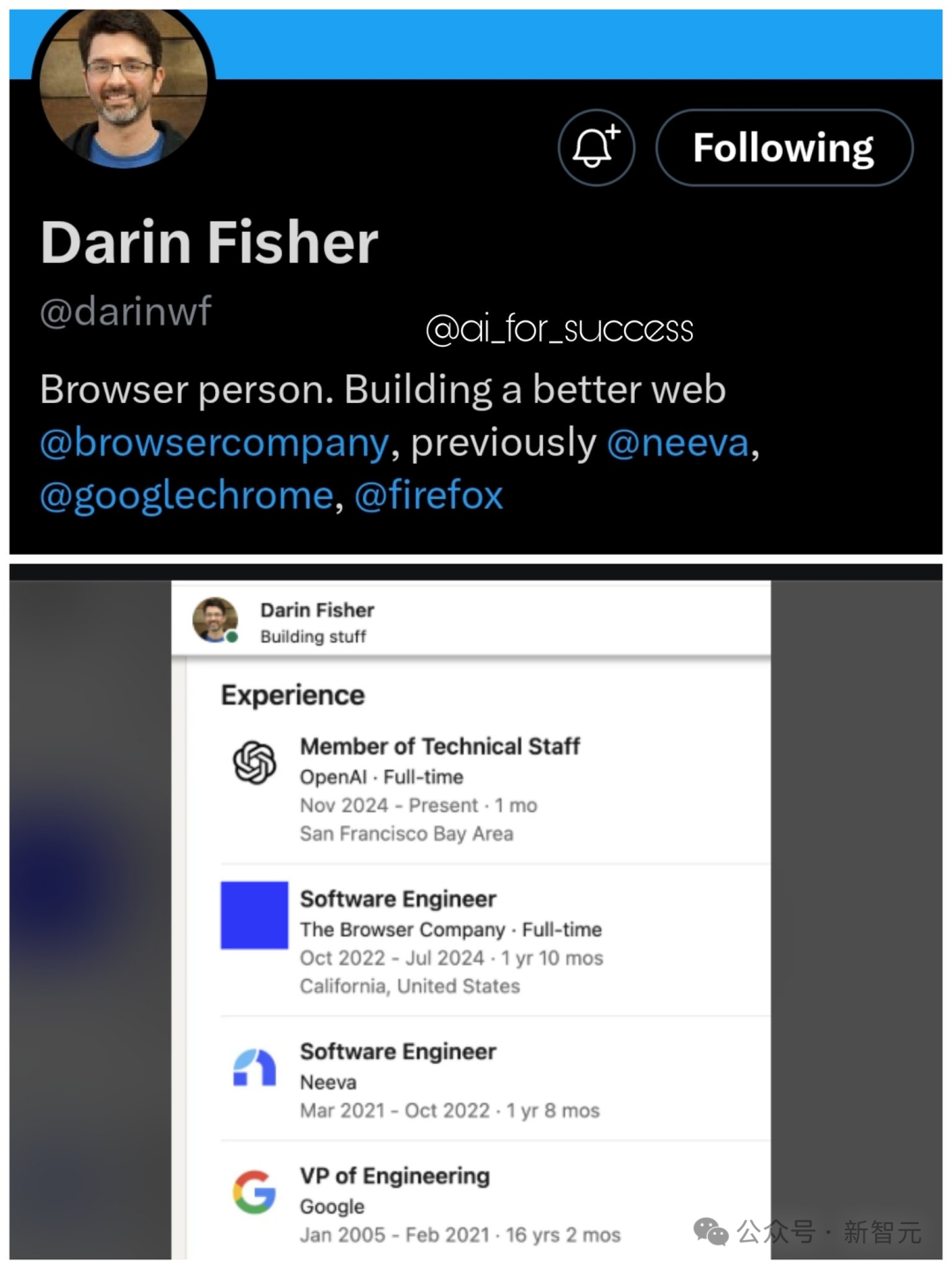
就在11月23日,有人發現搜索引擎大佬Darin Fisher正式加入OpenAI,這讓人更加確信:SearchGPT只是一個開始,OpenAI也許會正式打造以LLM為基礎的搜索引擎和瀏覽器,和Google展開一場正面battle。
雖然當下的LLM可以應付大多數場景下的常識問答,但在學術打工人眼中,用AI進行文獻搜索依舊缺陷重重,還是傳統的Google搜索和Google學術更好用。
為了填補這方面的空白,華盛頓大學NLP實驗室和Ai2、Meta等機構合作,開發了專門服務科研人的學術搜索工具OpenScholar。

本質上,OpenScholar是一個進行過檢索增強的語言模型,外接一個包含4500萬篇論文的數據庫,性能可以優於專有系統,甚至媲美人類專家。
為了方便自動化評估,團隊還一道推出了全新的大規模基準ScholarQABench,覆蓋了CS、生物、物理等多個學科,用於評價模型在引用準確性、涵蓋度和質量的等方面的表現。
由UWNLP和Ai2兩大頂流機構聯手,OpenScholar在開源方面幾乎做到了無懈可擊。不僅放出了訓練數據、代碼和模型檢查點,還有ScholarQABench的全部數據,以及用於專家評估的自動化腳本。
倉庫地址:https://huggingface.co/collections/OpenScholar/openscholar-v1-67376a89f6a80f448da411a6
 倉庫地址:https://github.com/AkariAsai/OpenScholar
倉庫地址:https://github.com/AkariAsai/OpenScholar論文開頭就給出了全部網址,此外團隊還構建了一個公開可用的搜索demo,基於一個參數量為8B的語言模型,綜合了超過100萬篇CS領域的專業文獻。

 demo傳送門:https://openscholar.allen.ai/
demo傳送門:https://openscholar.allen.ai/OpenScholar介紹
 論文地址:https://arxiv.org/abs/2411.14199
論文地址:https://arxiv.org/abs/2411.14199閱讀文獻是科研工作的重要部分,不僅能知道同行們的最前沿進展,也是構建自己創新idea的重要來源。科學的進步,依賴於研究者們綜合不斷增長的文獻的能力。
然而,隨著發表的文獻數量越來越多,全部通讀已經是不可能完成的任務,因此就需要依賴實時更新的搜索工具,並能給出信息的準確來源。
雖然LLM在成為科研助手方面非常有前景,但也面臨著重大挑戰,包括幻覺、過於依賴過時的預訓練數據,並且缺乏透明的信息出處,條條對科研領域都是重大弊病。
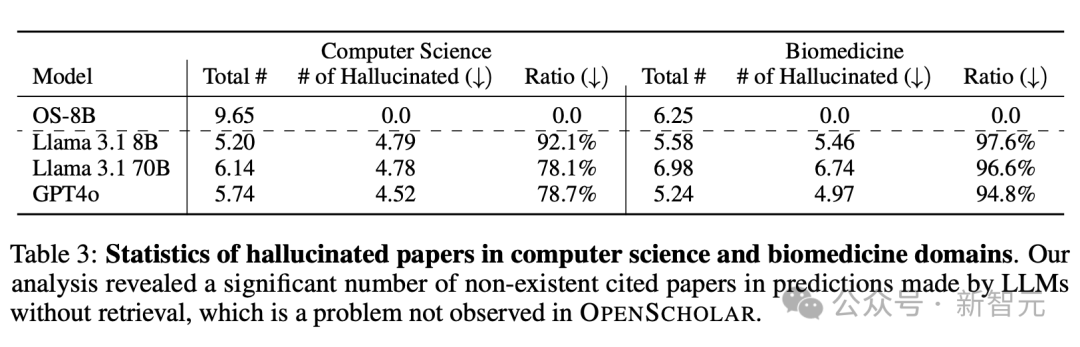
就拿幻覺來說,實驗中讓GPT-4引用最新文獻時,它在CS、生物醫學等領域偽造引用的情況達到了78%~90%。
檢索增強(retrieval-augmented)的語言模型可以在推理時檢索並集成外部知識源,從而緩解上述問題。然而,許多此類系統依賴於黑盒API或通用的LLM ,既沒有針對文獻綜合的任務進行優化,也沒有搭配適合科研的開放式、領域特定的檢索數據庫。
此外,LLM在科研文獻綜合任務上的評估也存在限制,現有的基準大多規模較小或只針對單個學科,或者使用了過於簡化的任務(如選擇題問答)。
OpenScholar的提出就是旨在解決上述問題。模型在推理時會檢索相關段落,並使用迭代式自反饋的生成方法來優化輸出;搭配的專門基準ScholarQABench旨在對開放式科學問答進行現實且可重覆的評估。
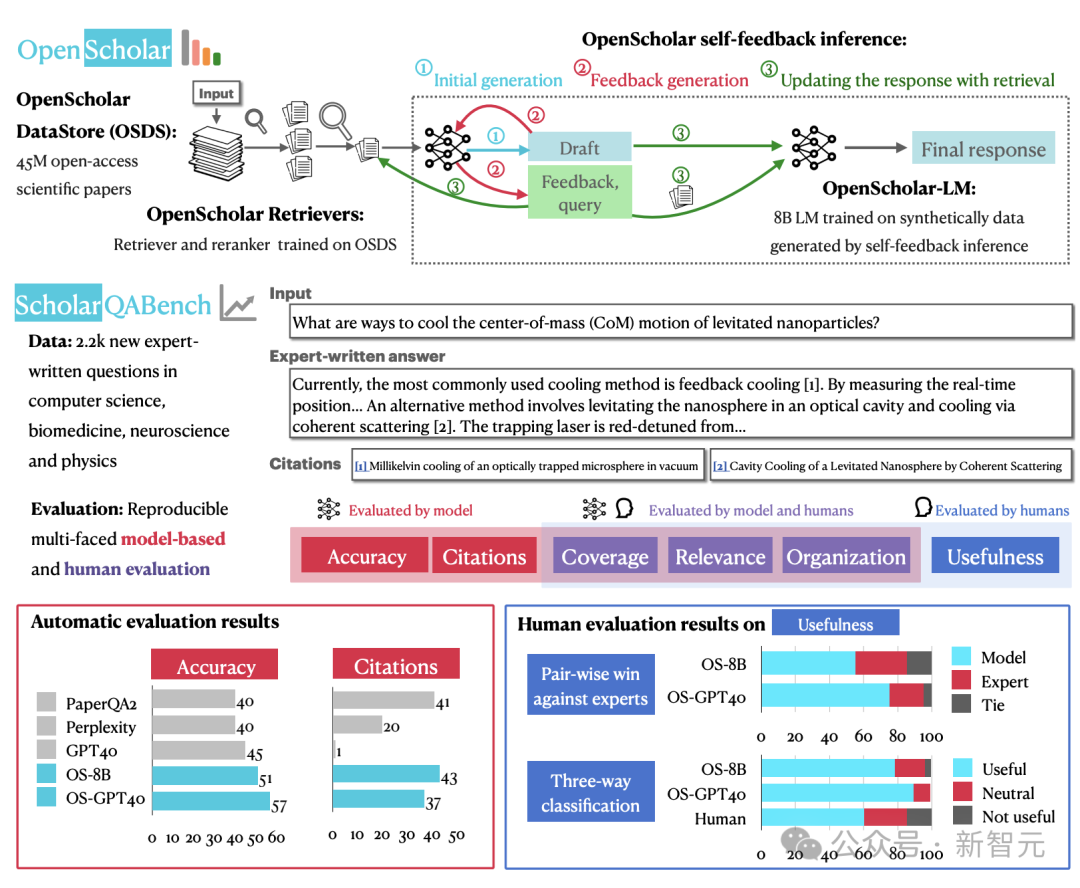 OpenScholar概述、ScholarQABench概述和自動化&人類專家評估結果
OpenScholar概述、ScholarQABench概述和自動化&人類專家評估結果模型概述
對於OpenScholar而言,問題定義如下:
給出一個科學查詢x ,任務是識別相關論文,綜合他們的發現,並生成響應y,其中應附有一組引文, 𝐂=c1, c2 ,…, cK。
為了遵循科學寫作的標準實踐 ,每個引用ci對應於現有科學文獻中的特定段落,並應作為內嵌引用提供,鏈接到相關文本範圍y。這些引文使研究人員能夠將輸出追溯到原始文獻,確保透明度和可驗證性。
為了確保能檢索到相關論文並生成高質量的輸出,OpenScholar由三個關鍵組件組成:數據庫𝐃 、檢索器ℛ ,和負責生成的語言模型𝒢 。
推理過程從檢索器ℛ開始 ,它從包含大量已發表文獻的數據庫𝐃中,根據與輸入查詢的語意相關性 x檢索到一組段落 𝐏={p1,p2,…,pN},作為下一步的上下文。
然後,負責生成的語言模型𝒢根據段落𝐏和輸入查詢x產生輸出y以及相應的引文𝐂, 這個過程可以形式化表示為:
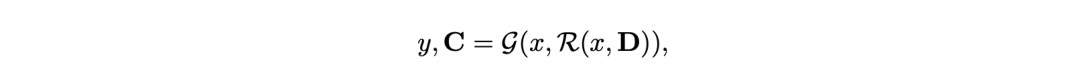
其中,𝐂中但每個ci對應檢索到的特定段落𝐏 ,負責生成的LM可以被靈活替換為各種縣城的模型,比如GPT-4o。
看起來,OpenScholar的檢索和推理流程基本複刻了經典RAG的流水線,但團隊做出了以下兩方面的貢獻:
– 新訓練出了小而高效的生成模型OpenScholar-LM
– 開發了自反饋檢索增強推理(elf-feedback retrieval-augmented inference),以提高可靠性和引用準確性
檢索與推理
檢索流程如下圖左半部分所示,由數據存儲𝐃、bi-encoder檢索器θb_i,以及cross-encoder重排序器 θcross組成。最終,從數據庫𝐃的4500萬篇論文中篩選出N個最相關的段落。
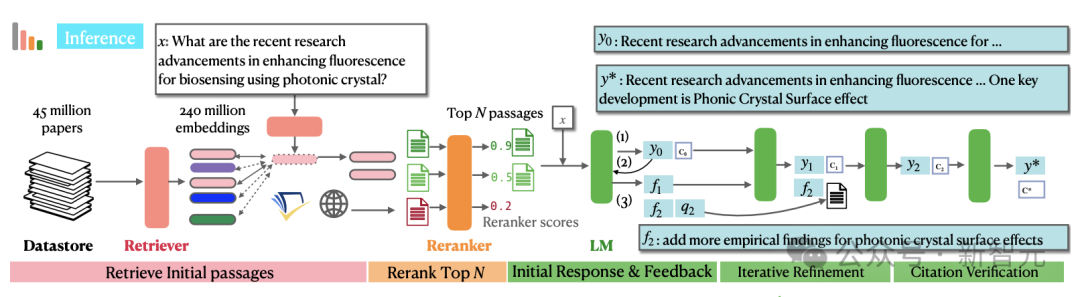
在標準的檢索增強生成(RAG)中,生成器LM接收原始輸入x和檢索到的N個最相關段落𝐏並生成輸出 y0 。雖然對於問答等任務有效,但這種「一步登天」的生成方式可能會產生不符合要求的答案,或由於信息缺失而導致輸出不完整 。
為了應對這些挑戰,OpenScholar引入了一種帶有自我反饋的迭代生成方法,包括三個步驟:(1)初始響應和反饋生成以輸出初始草稿y0以及一組反饋;(2)使用額外的搜索,根據上一步的反饋迭代改進y0,以及(3)引文驗證。
模型訓練
由於缺乏針對該問題的訓練數據,構建能夠有效綜合科學文獻的強大LM非常具有挑戰性,之前的大多數工作並沒有設置開放式檢索,而且是單論文任務,而且依賴於沒有開源的專有模型,這對複現性和推理成本提出了挑戰。
研究團隊想到了採用上述的推理pipeline,通過自反饋合成高質量的訓練數據,訓練出「小而美」的OpenScholar LM模型,具體訓練流程如下圖所示。
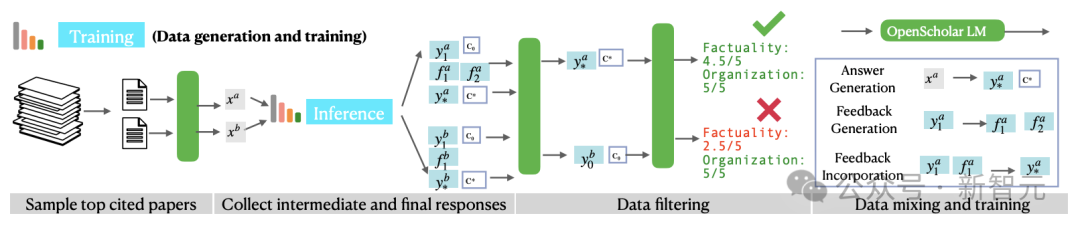
訓練數據的生成主要包括三個步驟:
– 從數據庫𝐃中篩選出最高引用量的論文
– 根據文章摘要生成一些有信息檢索目的的查詢
– 使用OpenScholar推理pipeline生成高質量響應
儘管合成數據是有效且可擴展的,但也可能包含幻覺、語句重覆、指令遵循有限等問題,因此在上述步驟之後,團隊還引入數據過濾步驟,包括「成對過濾」(pairwise-filtering)和標題過濾。判斷並篩選出較高質量的輸出。
從上述的合成管道中,可以得到三種類型的訓練數據:答案生成(x→y),反饋生成(y0→𝐅),以及反饋合併 (yt−1,ft→yt) 。論文指出,在訓練期間結合中間結果和最終輸出有助於較小的語言模型學習生成更有效的反饋。
最後,研究人員將上述的合成數據與現有的通用領域+科學領域的指令調優數據混合,並確保50%的訓練數據來自科學領域。在這些數據上,團隊將Llama 3.1 8B Instruct訓練成了OpenScholar LM。
全新基準ScholarQABench
ScholarQABench基準旨在評估模型理解和綜合現有研究的能力。之前的基準一般會預先劃定範圍,假設可以在某一篇論文中找到答案,但許多現實場景都需要識別多篇相關論文,並生成帶有準確引用的長文本輸出。
為了應對這些挑戰,研究人員整理了一個包含2967個文獻綜合問題的數據集,以及由專家撰寫的208個長篇回答,涵蓋計算機科學、物理、生物醫學和神經科學等4個學科。
此外,基準中引入了多方面的評估方案,結合了自動指標和人工評估,以衡量引文準確性、事實正確性、內容覆蓋率、連貫性和整體質量,確保評估的穩健和可重覆性。
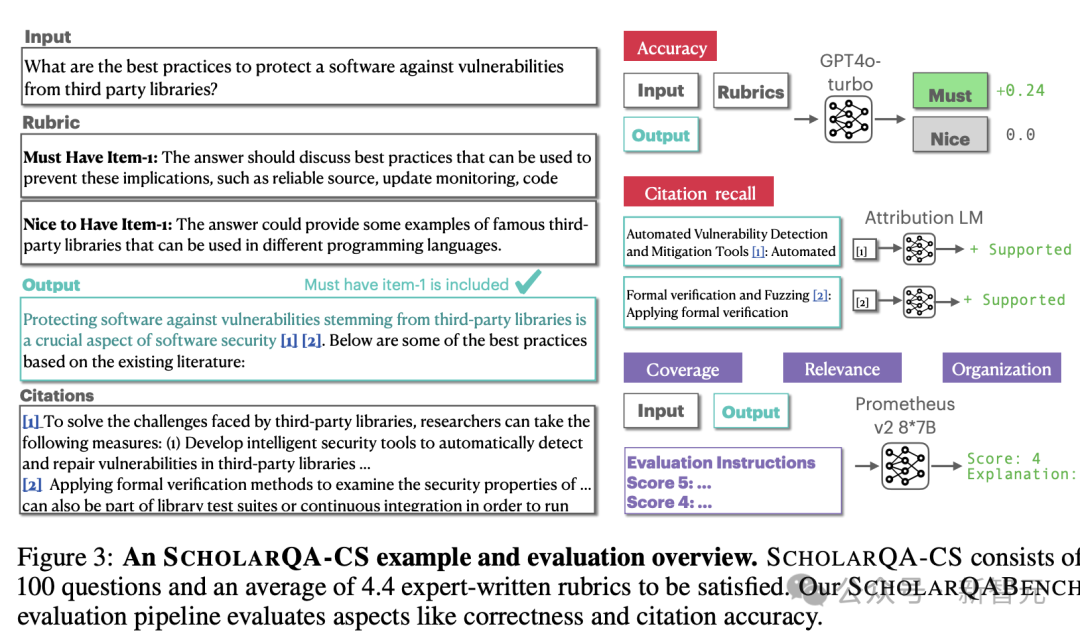 SchlarQA-CS的數據樣例和評估概述
SchlarQA-CS的數據樣例和評估概述評估結果
評估中使用了開放權重模型Llama 3.1(8B、70B)以及專有模型GPT-4o(gpt-4o-2024-05-13)。
首先,在單論文任務中,每個LM在不連接外部檢索的情況下獨立生成答案,並提供所有參考論文的標題。如果參考論文確實存在,則檢索相應摘要以用作引文。
對於多論文任務,團隊還進一步評估其他專有系統,包括Perplexity Pro和PaperQA2,後者是一個併發文獻綜述智能體系統,使用 GPT-4o進行重排、總結和答案生成。
具體的評估結果如下表所示,其中+OSDS表示外接了數據庫OpenScholar-DataStore並檢索到top N段落拚接到原始輸入中;OS-8B模型經過重新訓練,OS-70B和OS-GPT-4o僅僅使用了團隊自定義的推理pipeline。
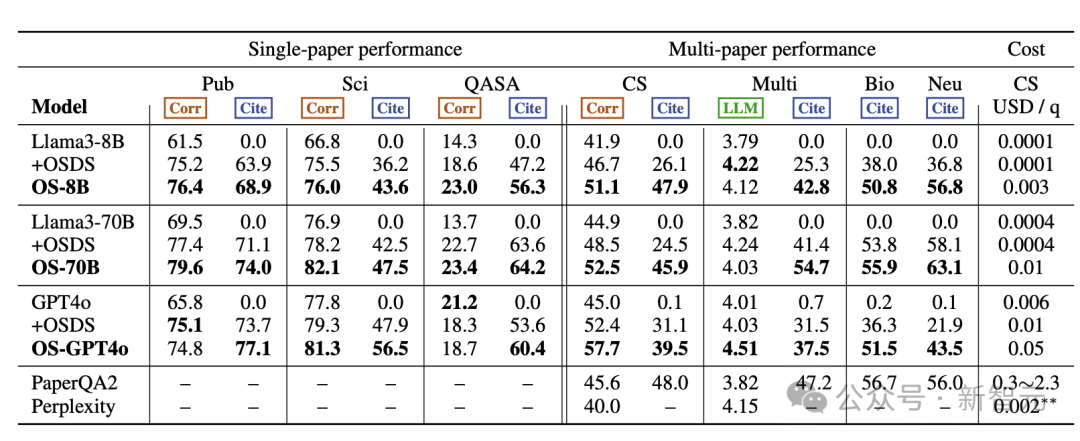
總體而言, OpenScholar實現了SOTA性能,大大優於GPT-4o和相應的標準RAG版本,以及PaperQA2等專用的文獻綜述系統。
在單篇論文任務中, OpenScholar始終優於其他模型。無論是否有檢索增強,OS-8B和OS-70B均優於原來的Llama 3.1模型,OS-70B在PubMedQA和QASA上甚至可以對打GPT-4o。
此外,OS-8B、OS-70B和OS-GPT4o在多論文任務中也表現出強大的性能,OS-GPT4o在Scholar-CS中比單獨的GPT-4o提高12.7%,比標準RAG版本提高了5.3 %。結合了重新訓練過的OS-8B, OpenScholar 的性能顯著優於使用現成的Llama 3.1 8B,說明了特定領域訓練的優勢。
甚至,在多論文任務的很多指標上,OpenScholar-8B的性能遠遠優於GPT-4o、Perplexity Pro和PaperQA2。值得注意的是,通過利用輕量的bi-encodeer、cross-encoder構建高效的檢索pipeline, OpenScholar-8B 和OpenScholar-GPT4o顯著降低了成本,在保持高性能的同時比PaperQA2便宜了幾個數量級。
無論是單論文還是多論文任務,沒有檢索增強的模型幾乎都表現的相當糟糕,難以生成正確的引用,甚至會產生嚴重的幻覺,而增加了檢索之後都能大幅提升性能。
如表3所示,在沒有檢索增強的情況下,雖然GPT-4o和Llama等模型可以生成看起來可靠的參考文獻列表,但其中78-98%的引文都是捏造的,而且這個問題在生物醫學領域更加嚴重。即使指向了真實論文,大多也沒有相應摘要的證實,導致引文準確性接近於零。
除了在ScholarQABench上進行自動評估外,團隊還與來自計算機科學、物理學和生物醫學等領域的16名科學家合作,進行了詳細的專家評估。
他們根據ScholarQABench中專家編寫108個對文獻綜述問題的答案,對OpenScholar的輸出進行了成對和細粒度的評估。結果發現,無論是使用GPT-4o還是經過訓練的8B模型,OpenScholar的表現始終優於專家編寫的答案,勝率分別為70%和51%。
相比之下,沒有檢索的單獨GPT-4o模型被認為不如人類專家有幫助,勝率僅為 31%。這表明OpenScholar生成的輸出更加全面、有條理,並且對於文獻綜述非常有用,不僅可以與專家撰寫的答案相媲美,而且在某些情況下甚至超過了專家。
消融實驗
為了研究OpenScholar各個組件的有效性,作者進行了詳細的消融實驗,涉及推理期的重排、反饋、查找文獻出處等步驟,並嘗試不進行任何訓練,直接使用原始的Llama3-8B模型。
如下圖所示,刪除這些組件會顯著影響模型輸出的整體正確性和引用準確性。值得注意的是,刪除重排會導致模型性能大幅下降;相比8B模型,GPT-4o對刪除反饋循環更加敏感,這表明更強大的模型可以從自反饋循環中受益更多。
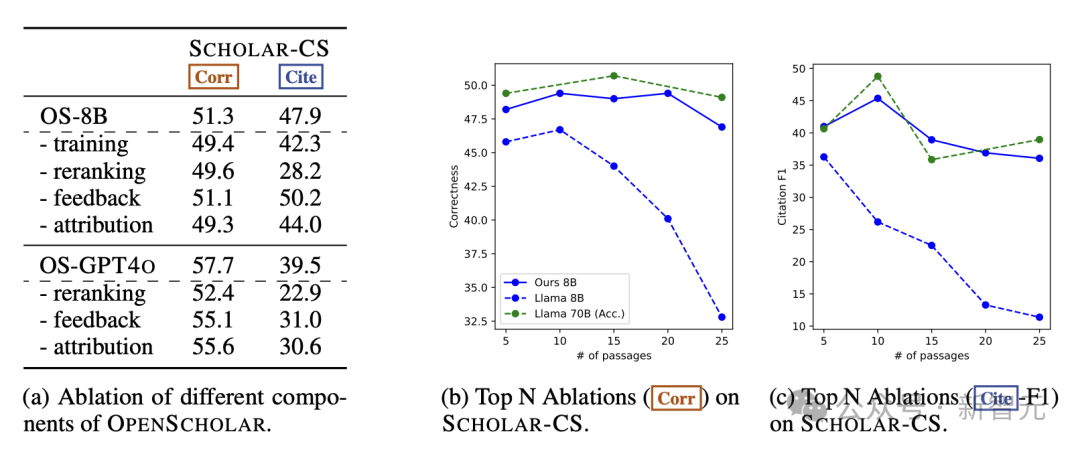
此外,取消論文出處的查找(attribution)會對引文準確性和最終輸出正確性產生負面影響;經過訓練的OS-8B 與原始模型之間也存在顯著性能差距,這表明,對高質量、特定領域數據的進一步訓練是構建高效的、針對專門任務的語言模型的關鍵。
結論與局限性
儘管OpenScholar在ScholarQABench在評估中表現出了強大的性能,能夠成為支持科研人的效率工具,但負責標註和評估的專家依舊發現了一些局限性。

首先,OpenScholar不能始終如一地檢索到最具代表性或相關性的論文,而且輸出總可能包含不準確的事實信息,特別是在基於8B模型的版本中,科學知識和指令遵循能力有限。
未來的工作可以進一步探索如何改進OpenScholar-8B的訓練。儘管OpenScholar-GPT4o具有競爭力,但依賴於OpenAI的專有黑盒API,無法保證之後仍能精確複現當下的結果。
此外,數據方面也存在諸多繁瑣且棘手的問題。
第一,ScholarQABench聘請了領域專家進行數據標註,他們都獲得了博士學位或正在從事相關研究。這種人工撰寫答案的方式成本很高,因此評估數據集相對較小,比如,CS-LFQA包括110條數據,專家編寫的答案有108個。
這種數據集由於規模較小,更容易被註釋者的專業知識所影響,從而引入統計方差和潛在偏差。未來的研究需要探索,如何擴大ScholarQABench的規模和範圍,實現更加自動化的數據收集和標註pipeline。
第二,最後, ScholarQABench主要關注計算機科學、生物醫學和物理學等領域,沒有社會科學和其他STEM學科的實例數據。因此,目前的研究結果可能無法完全推廣到其他領域,特別是在一些領域中,對論文數據的訪問會受到更多限制。
最後,雖然OpenScholar在推理期沒有使用版權保護的論文,但如何確保檢索增強型的語言模型在訓練和推理時做到對版權數據的公平使用,這方面的討論仍在進行,也只能留待學界和業界在之後的工作中解決。
參考資料:
https://allenai.org/blog/openscholar
https://x.com/AkariAsai/status/1858875730068738051