跨模態大升級!少量數據高效微調,LLM教會CLIP玩轉複雜文本
機器之心報導
機器之心編輯部
在當今多模態領域,CLIP 模型憑藉其卓越的視覺與文本對齊能力,推動了視覺基礎模型的發展。CLIP 通過對大規模圖文對的對比學習,將視覺與語言信號嵌入到同一特徵空間中,受到了廣泛應用。
然而,CLIP 的文本處理能力被廣為詬病,難以充分理解長文本和複雜的知識表達。隨著大語言模型的發展,新的可能性逐漸顯現:LLM 可以引入更豐富的開放時間知識、更強的文本理解力,極大提升 CLIP 的多模態表示學習能力。
在此背景下,來自同濟大學和微軟的研究團隊提出了 LLM2CLIP。這一創新方法將 LLM 作為 CLIP 的強力 「私教」,以少量數據的高效微調為 CLIP 注入開放世界知識,讓它能真正構建一個的跨模態空間。在零樣本檢索任務上,CLIP 也達成了前所未有的性能提升。

-
論文標題:LLM2CLIP: POWERFUL LANGUAGE MODEL UNLOCKS RICHER VISUAL REPRESENTATION
-
論文鏈接:https://arxiv.org/pdf/2411.04997
-
代碼倉庫:https://github.com/microsoft/LLM2CLIP
-
模型下載:https://huggingface.co/collections/microsoft/llm2clip-672323a266173cfa40b32d4c
在實際應用中,LLM2CLIP 的效果得到了廣泛認可,迅速吸引了社區的關注和支持。
HuggingFace 一週內的下載量就破了兩萬,GitHub 也突破了 200+ stars!
值得注意的是, LLM2CLIP 可以讓完全用英文訓練的 CLIP 模型,在中文檢索任務中超越中文 CLIP。
此外,LLM2CLIP 也能夠在多模態大模型(如 LLaVA)的訓練中顯著提升複雜視覺推理的表現。
代碼與模型均已公開,歡迎訪問 https://aka.ms/llm2clip 瞭解詳情和試用。
LLM2CLIP 目前已被 NeurIPS 2024 Workshop: Self-Supervised Learning – Theory and Practice 接收。
研究背景
CLIP 的橫空出世標誌著視覺與語言領域的一次革命。不同於傳統的視覺模型(如 ImageNet 預訓練的 ResNet 和 ViT)依賴簡單的分類標籤,CLIP 基於圖文對的對比學習,通過自然語言的描述獲得了更豐富的視覺特徵,更加符合人類對於視覺信號的定義。
這種監督信號不僅僅是一個標籤,而是一個富有層次的信息集合,從而讓 CLIP 擁有更加細膩的視覺理解能力,適應零樣本分類、檢測、分割等多種任務。可以說,CLIP 的成功奠基於自然語言的監督,是一種新時代的 「ImageNet 預訓練」。
雖然 CLIP 在視覺表示學習中取得了成功,但其在處理長文本和複雜描述上存在明顯限制。而大語言模型(LLM)例如 GPT-4 和 Llama,通過預訓練掌握了豐富的開放世界知識,擁有更強的文本理解和生成能力。
將 LLM 的這些能力引入到 CLIP 中,可以大大拓寬 CLIP 的性能上限,增強其處理長文本、複雜知識的能力。借助 LLM 的知識擴展,CLIP 在圖文對齊任務中的學習效率也得以提升。
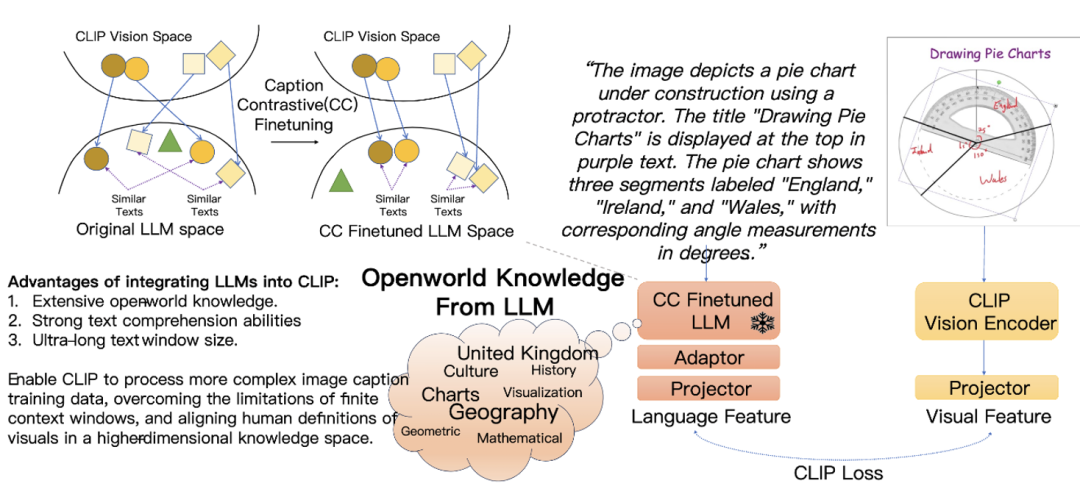
原始的 LLM 無法給 CLIP 帶來有意義的監督
事實上,將 LLM 與 CLIP 結合看似簡單粗暴,實際並非易事。直接將 LLM 集成到 CLIP 中會引發「災難」,CLIP 無法產生有效的表示。
這是由於 LLM 的文本理解能力隱藏在內部,它的輸出特徵空間並不具備很好的特徵可分性。
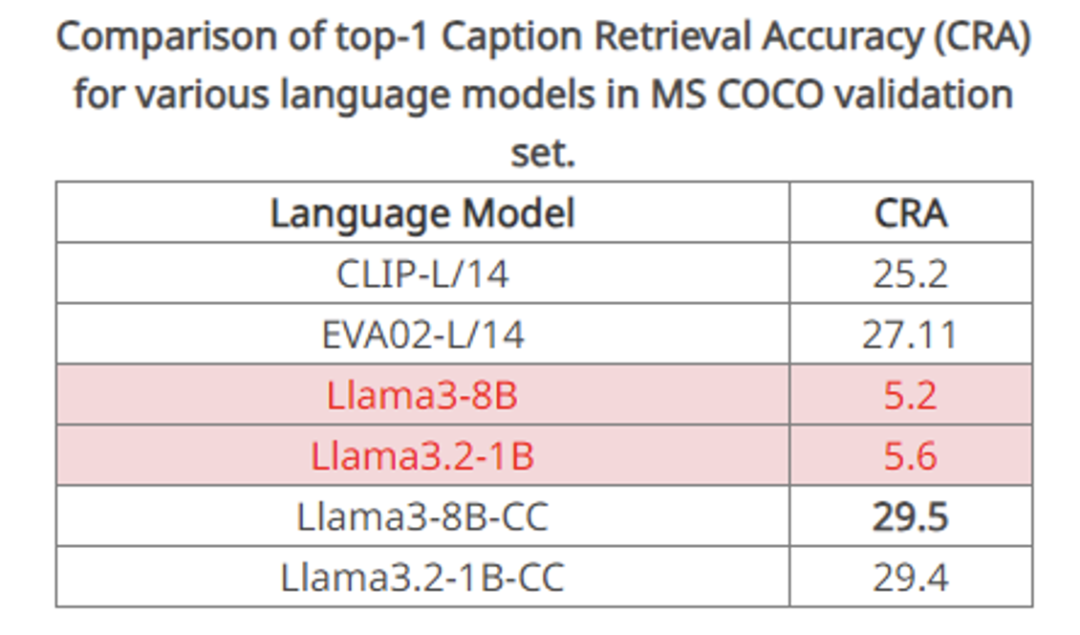
於是,該團隊設計了一個圖像 caption 到 caption 的檢索實驗,使用 COCO 數據集上同一張圖像的兩個不同 caption 互相作為正樣本進行文本檢索。
他們發現原生的 llama3 8B 甚至無法找到十分匹配的 caption,例如 plane 和 bat 的距離更近,但是離 airplane 的距離更遠,這有點離譜了,因此它只取得了 18.4% 的召回率。
顯然,這樣的輸出空間無法給 CLIP 的 vision encoder 一個有意義的監督,LLM 無法幫助 CLIP 的進行有意義的特徵學習。
圖像描述對比微調是融合 LLM 與 CLIP 的秘訣
從上述觀察,研究團隊意識到必須對提升 LLM 輸出空間對圖像表述的可分性,才有可能取得突破。
為了讓 LLM 能夠讓相似的 caption 接近,讓不同圖像的 caption 遠離,他們設計了一個新的圖像描述對比微調 ——Caption-Contrastive(CC)finetuning。
該團隊對訓練集中每張圖像都標註了兩個以上 caption,再採用同一個圖像的 caption 作為正樣本,不同圖像的 caption 作為負樣本來進行對比學習,來提升 LLM 對於不同畫面的描述的區分度。

實驗證明,這個設計可以輕易的提升上述 caption2caption 檢索的準確率,從上述 cases 也可以看出召回的例子開始變得有意義。
高效訓練範式 LLM2CLIP
讓 SOTA 更加 SOTA
LLM2CLIP 這一高效的訓練範式具體是怎麼生效的呢?
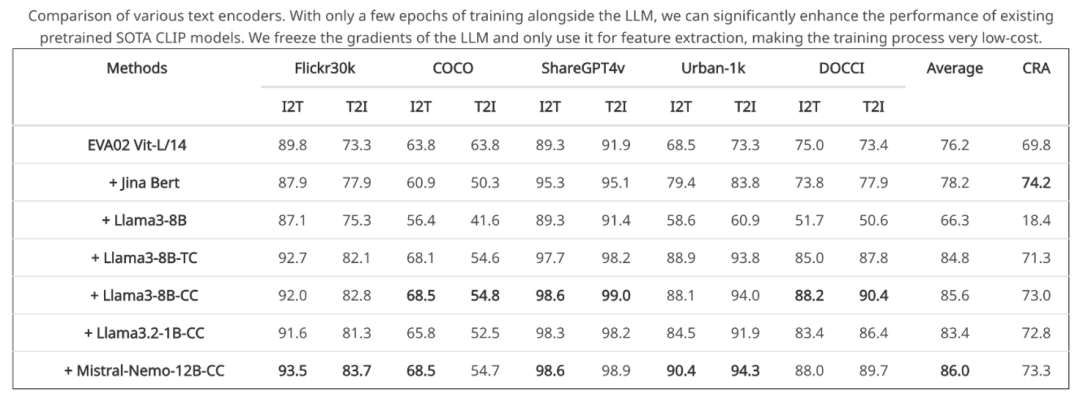
首先,要先使用少量數據對 LLM 進行微調,增強文本特徵更具區分力,進而作為 CLIP 視覺編碼器的強力 「教師」。這種設計讓 LLM 中的文本理解力被有效提取,CLIP 在各種跨模態任務中獲得顯著性能提升。
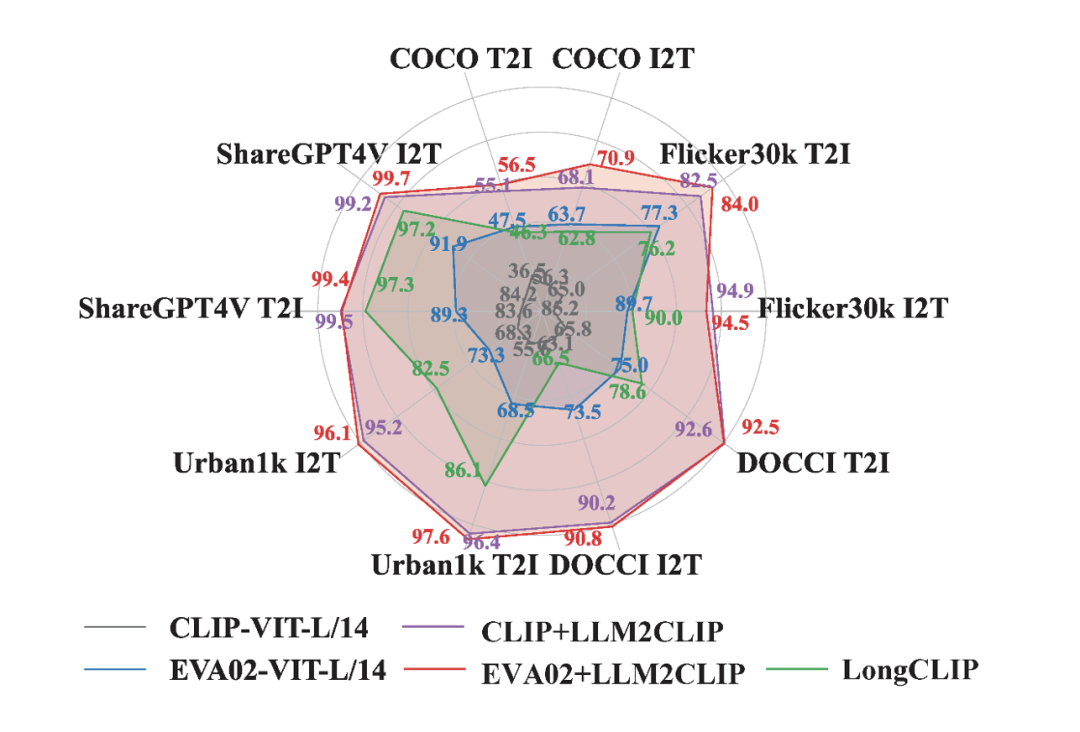
實驗結果表明,LLM2CLIP 甚至能在不增加大規模訓練數據的情況下,將當前 SOTA 的 CLIP 性能提升超過 16%。
英文訓練,中文超越,CLIP 的語言能力再拓展
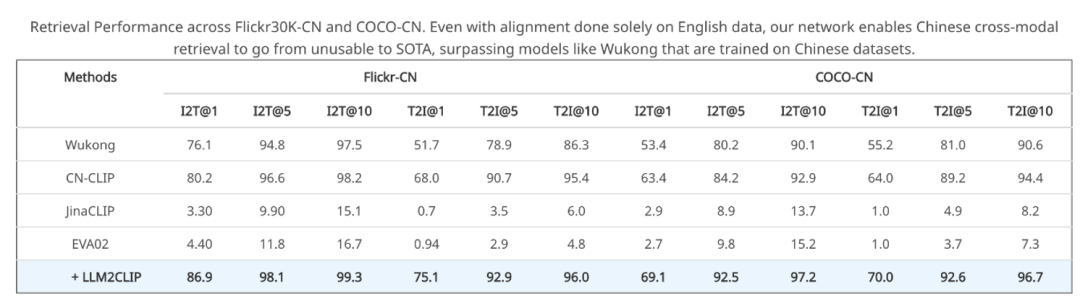
一個令人驚喜的發現是,LLM2CLIP 的開放世界知識不僅提升了 CLIP 在英文任務中的表現,還能賦予其多語言理解能力。
儘管 LLM2CLIP 僅在英文數據上進行了訓練,但在中文圖文檢索任務上卻超越了中文 CLIP 模型。這一突破讓 CLIP 不僅在英文數據上達到領先水平,同時在跨語言任務中也展現了前所未有的優勢。
提升多模態大模型的複雜視覺推理性能
LLM2CLIP 的優勢還不止於此。當該團隊將 LLM2CLIP 應用於多模態大模型 LLaVA 的訓練時,顯著提升了 LLaVA 在複雜視覺推理任務中的表現。
LLaVA 的視覺編碼器通過 LLM2CLIP 微調後的 CLIP 增強了對細節和語義的理解能力,使其在視覺問答、場景描述等任務中取得了全面的性能提升。
總之,該團隊希望通過 LLM2CLIP 技術,推動大模型的能力反哺多模態社區,同時為基礎模型的預訓練方法帶來新的突破。
LLM2CLIP 的目標是讓現有的預訓練基礎模型更加強大,為多模態研究提供更高效的工具。
除了完整的訓練代碼,他們也逐步發佈了經過 LLM2CLIP 微調的主流跨模態基礎模型,期待這些模型能被應用到更多有價值的場景中,挖掘出更豐富的能力。



















