一文看盡Meta開源大禮包,全面覆蓋圖像分割、語音、文本、表徵、材料發現、密碼安全性等
開源絕對是AI如今發展迅猛的助推劑,而其中的一股重要力量就是來自Meta
Meta在人工智能開源界可謂是碩果頗豐,從大模型LLama到圖像分割模型Segment Anything,覆蓋了各種模態、各種場景,甚至在AI以外的學科,如醫學等科學研究進展也都從Meta的開源模型中受益。

最近,Meta發佈了一系列新的開源工作,還對已有的開源工作進行了升級迭代,包括 SAM 2.1、句子表徵的細化等,開源社區將再迎來一場狂歡!
Segment Anything Model 2.1
SAM2模型開源以來,總下載量已經超過70萬次,在線可用的演示程序也已幫助用戶在圖像和影片數據中分割了數十萬個物體,並且在跨學科(包括醫學圖像、氣象學等研究)中產生了巨大的影響。
本次Meta更新了Meta Segment Anything Model 2.1 (SAM 2.1)權重,性能更強。
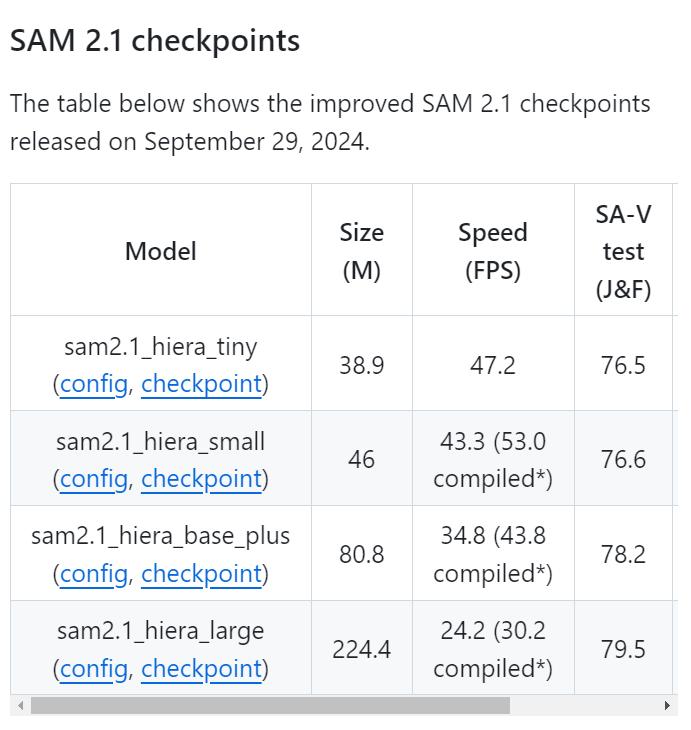 開源鏈接:https://github.com/facebookresearch/sam2
開源鏈接:https://github.com/facebookresearch/sam2相比SAM2,研究人員引入了額外的數據增強技術來模擬視覺相似物體和小物體,並且通過在較長的幀序列上訓練模型並對「空間」和「物體指向記憶」(object pointer memory)的位置編碼進行一些調整,提高了SAM 2的遮擋處理能力(occlusion handling capability)。
研究人員還開源了SAM 2開發者套件,基於SAM 2模型構建下遊應用會變得更容易,用戶現在也可以使用自己的數據來微調SAM 2的訓練代碼;頁面演示的前端和後端代碼也開源了。
Spirit LM:語音+文本的語言模型
大型語言模型經常被用來構建文本到語音的流程:首先通過自動語音識別(ASR)技術將語音轉寫成文本,然後由大型語言模型(LLM)合成文本,最終再通過文本到語音(湯臣S)技術將文本轉換為語音。
但這個過程可能會影響語音的表達性,使得模型在理解、生成帶表達的語音上有所欠缺。
為瞭解決這個限制,研究人員構建了Spirit LM,也是首個Meta開源的多模態語言模型,能夠自由地混合文本和語音;通過在語音和文本數據集上使用逐詞交錯的方法進行訓練,實現了跨模態生成。
 論文鏈接:https://arxiv.org/abs/2402.05755
論文鏈接:https://arxiv.org/abs/2402.05755研究人員開發了兩個版本的Spirit LM,以展示文本模型的生成語義能力和語音模型的表達能力:基礎版(Base)使用音素標記來模擬語音,而表達版(Expressive)使用音調和風格標記來捕捉關於語調的信息,比如是興奮、憤怒還是驚訝,然後生成反映這種語調的語音。
Spirit LM能夠生成聽起來更自然的語音,並且有能力跨模態學習新任務,比如自動語音識別、文本到語音和語音分類。
Layer Skip:加速生成時間
大型語言模型已經在各個行業和用例中得到了廣泛應用,但需要非常高的計算速度和內存量,運行成本非常高。
為了應對這些挑戰,Meta引入一種端到端的解決方案層跳過(Layer Skip),可以在不依賴專用硬件或軟件的情況下,加速新數據上的LLM生成時間:通過執行模型的部分層,並利用後續層進行驗證和修正,來加速LLMs的運行。

論文鏈接:https://arxiv.org/pdf/2404.16710
代碼鏈接:https://github.com/facebookresearch/LayerSkip
研究人員開源了層跳過的推理代碼和微調檢查點,包括Llama 3、Llama 2和Code Llama,這些模型已經通過層跳過訓練方法進行了優化,顯著提高了早期層退出的準確性,層跳過的推理實現可以提升1.7倍模型性能。
層跳過檢查點的一個主要特點是在早期層退出和跳過中間層時的魯棒性,以及各層之間激活的一致性,這種特性為優化和可解釋性方面的創新研究鋪平了道路。
Salsa:驗證後量子密碼標準的安全性
在保護數據的安全領域上,密碼學研究必須領先於攻擊手段。
Meta此次開源的方法Salsa,能夠攻擊和破解NIST標準中的稀疏秘密(sparse secrets)Krystals Kyber,使研究人員能夠對基於人工智能的攻擊進行基準測試,並將其與現在以及將來的新攻擊手段進行對比。

論文鏈接:https://arxiv.org/pdf/2408.00882v1
代碼鏈接:https://github.com/facebookresearch/LWE-benchmarking
國家標準技術研究所(NIST)採用的行業標準,「基於格(lattice)的密碼學」建立在「帶誤差的學習」(LWE)的難題之上。
這種難題假設,如果只提供與隨機向量有噪聲的內積,那麼學習一個秘密向量是非常困難的,此前已經有研究人員展示了針對這種方法的機器學習攻擊。
Meta Lingua:通過高效的模型訓練加速研究
Meta Lingua 是一個輕量級且自包含的代碼庫,可以大規模訓練語言模型。
該項目提供了一個研究友好的環境,使得將概念轉化為實際實驗變得更加容易,並強調簡單性和可重用性以加速研究,平台高效且可定製,研究人員能夠以最小的設置和技術負擔來快速測試想法。
 代碼鏈接:https://github.com/facebookresearch/lingua
代碼鏈接:https://github.com/facebookresearch/lingua為了實現這一點,研究人員做了幾個設計選擇,確保代碼既模塊化又自包含,同時保持高效,其中利用了PyTorch中的多個特性,在保持靈活性和性能的同時,使代碼更易於安裝和維護。
研究人員可以更專注於工作本身,讓Lingua平台來負責高效的模型訓練和可複現的研究。
Meta Open Materials 2024:促進無機材料發現
傳統上,發現推動技術進步的新材料可能需要數十年的時間,但人工智能輔助材料發現可能會徹底改變這一領域,並大大加快開現流程。
Meta最近開源了Open Materials 2024數據集和模型,在Matbench-Discovery排行榜上名列前茅,有望通過開放和可複現的研究進一步推動人工智能加速材料發現的突破。
代碼鏈接:https://github.com/FAIR-Chem/fairchem
模型鏈接:https://huggingface.co/fairchem/OMAT24
數據鏈接:https://huggingface.co/datasets/fairchem/OMAT24
目前最佳的材料發現模型是基於開源人工智能社區的基礎研究構建的封閉模型,而Open Materials 2024提供了基於1億個訓練樣本的開源模型和數據,也是最大的開放數據集之一,為材料發現和人工智能研究社區提供了一個有競爭力的開源選擇。
Meta Open Materials 2024現在公開可用,並將賦予人工智能和材料科學研究社區加速無機材料發現的能力,並縮小領域內開放和專有模型之間的差距。
Mexma:改進句子表徵的token級目標
目前,預訓練的跨語言句子編碼器通常只使用句子級別的目標進行訓練。這種做法可能會導致信息的丟失,特別是對於token級別的信息,這最終會降低句子表示的質量。
Mexma是一個預訓練的跨語言句子編碼器,通過在訓練過程中結合token和句子級別的目標,其性能也超越了以往的方法。
 論文鏈接:https://arxiv.org/pdf/2409.12737
論文鏈接:https://arxiv.org/pdf/2409.12737以前訓練跨語言句子編碼器的方法僅通過句子表示來更新編碼器,通過同時使用token級別的目標來更好地更新編碼器,從而在這方面進行了改進。
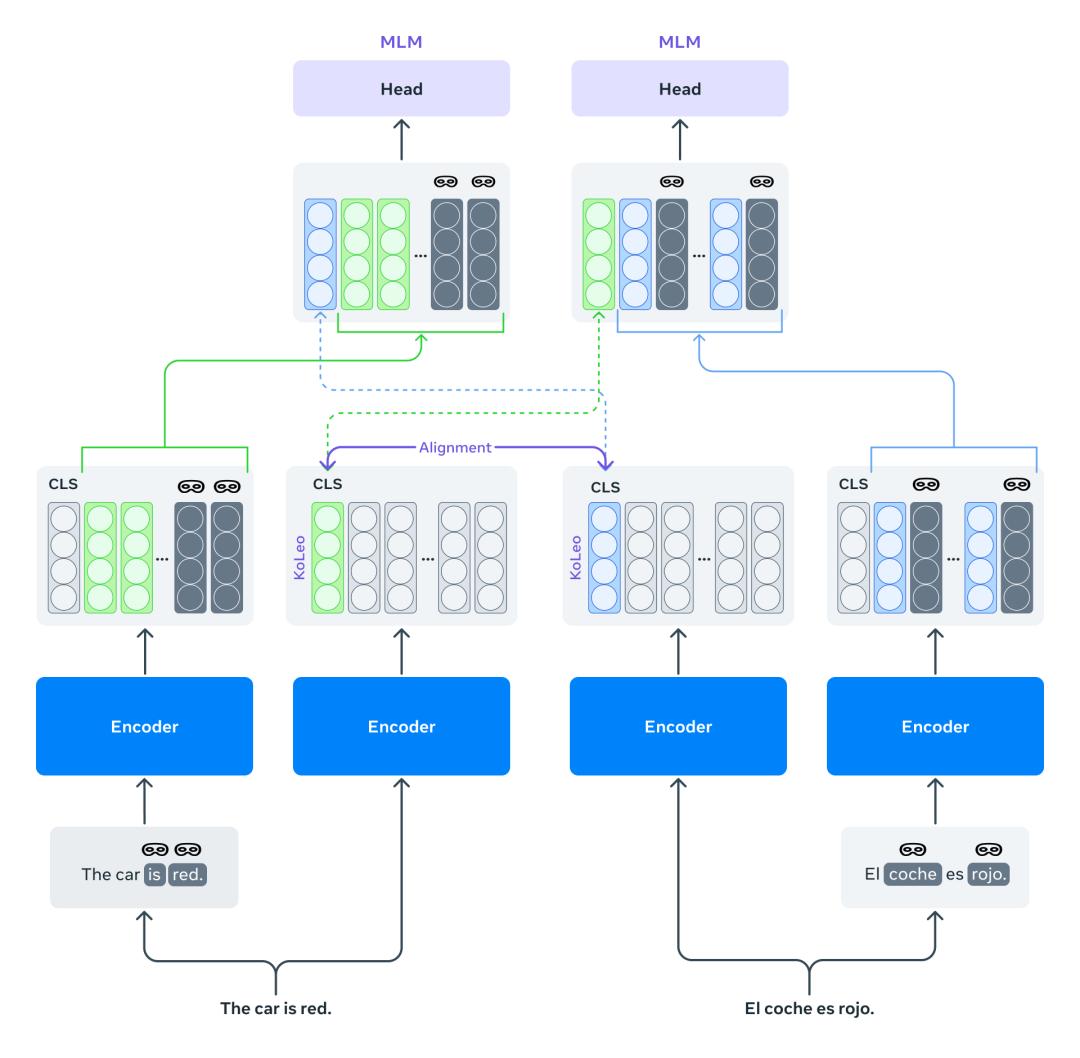
研究人員希望研究社區能夠從使用Mexma作為句子編碼器中受益,目前支持80種語言,所有語言的句子表示都經過對齊,在挖掘包含兩種文本的語言數據時,Mexma能夠更準確地識別和比較不同語言中的信息,並且在其他下遊任務,如句子分類上表現良好。
Self-Taught Evaluator:生成獎勵模型
研究人員推出了自學評估器(Self-Taught Evaluator),可以用於生成合成偏好數據以訓練獎勵模型,而無需依賴人工標註。
這種方法生成對比的模型輸出,並訓練一個作為評委的大型語言模型(LLM-as-a-Judge)以生成用於評估和最終判斷的推理痕跡,並通過迭代自我改進方案進行優化。
 論文鏈接:https://arxiv.org/abs/2408.02666
論文鏈接:https://arxiv.org/abs/2408.02666研究人員發佈了一個經過直接偏好優化訓練的模型,該生成式獎勵模型在RewardBench上表現強大,但在訓練數據創建中沒有使用任何人工標註。
其性能表現超越了更大的模型或使用人工標註標簽的模型,例如GPT-4、Llama-3.1-405B-Instruct和Gemini-Pro,也可作為AlpacaEval排行榜上的評估器之一,在人類一致率方面名列前茅,同時比預設的GPT-4評估器快約7到10倍。
自從發佈以來,人工智能社區已經接受了這種合成數據方法,並用來訓練表現優異的獎勵模型。
參考資料:
https://ai.meta.com/blog/fair-news-segment-anything-2-1-meta-spirit-lm-layer-skip-salsa-lingua/
本文來自微信公眾號「新智元」,作者:新智元,編輯:LRS,36氪經授權發佈。



















