向量數據庫的半場戰事:長期主義者Zilliz如何全球突圍
機器之心發佈
機器之心編輯部
命運齒輪轉動的開始,源於 2023 年的 3 月 23 日的 OpenAI 一次日常更新。
這一天,OpenAI ChatGPT 發佈了一個名叫 chatgpt-retrieval-plugin 的插件功能。而在官方 plugin 給出的標準案例中,OpenAI 專門提到,向量數據庫是大模型產品形成長期記憶一個必不可少的組件。
無獨有偶,三天前的 NVIDIA GTC 2023 大會上,英偉達創始人黃仁勳也重點提及向量數據庫,一家過去名不見經傳的向量數據庫創業公司 Zilliz 在此期間,被三次邀請上台演講。向量數據庫與大語言模型,成為這一年的 GTC 上,除芯片之外討論度最高的關鍵詞。
也是自這一天起,海內外的各大開源社區以及創投市場,所有向量數據庫項目的關注度瞬間畫出了一條陡峭的增長曲線。
老牌玩家 Zilliz 旗下 Milvus 的 GitHub 的 Star 在接下來的兩年時間迅速從一萬增長至三萬。原本略顯荒蕪的賽道中,僅僅一個多月,就有 Pinecone,Weaviate 各種 「專用向量數據庫」 如雨後春筍冒了出來,數十億熱錢被打到創業公司的戶頭。
烈火烹油,鮮花著錦,與熱情一同狂奔而來的是粗放的管理:
Google開發專家兼 YouTube 頻道 Fireship 的創建者 Jeff Delaney,在 0 收入、0 商業計劃甚至 0 展示代碼的情況下,就能憑藉 Rektor 向量數據庫初創項目將公司估值推升至 4.2 億美元。明星創業公司公開承認產品只是在 ClickHouse 和 HNSWlib 基礎上,加上了向量檢索與 Python 封裝,就推向市場。
二級市場,哪怕傳統的數據庫運維公司,只要放出一個正在研發向量數據庫的消息,就立刻在被轉化為股票走勢中連續的 20cm 漲停。甚至有大廠,從立項到完成產品化僅用時三個月不到,就推出了自研的向量數據庫產品。
那時,所有人都相信,每個時代都有自己的代表性基礎設施:如果工業革命時期的水電煤;信息時代的 IOE+wintel;手機時代是高通 + 安卓 + Snowflake,那麼到了 AI 時代,為什麼不會是 GPU + 大模型 + 向量數據庫?
手握向量數據庫的源代碼,排入的是通往 AI 時代千億市值的繁華夢幻隊。
卻唯獨忘記了,殘暴的歡愉終將以殘暴收尾,就如同歷史上反復上演的數據庫戰爭一般 —— 在一個極具規模效應的市場里,二八原則早已為所有玩家的未來寫下結局的註腳。
一、一個新的千億藍海市場
在理解市場對向量數據庫的狂熱之前,我們需要先對其概念及其與大模型的關係,做一個清楚的闡釋。
所謂向量數據庫,顧名思義,用戶存儲、管理向量的數據庫。與之並列的概念,則是甲骨文、MySQL 為代表的傳統關係型數據庫,以及 Web 2.0 時期興起的 PostgreSQL、MongoDB 等為代表的 NoSQL 數據庫。
與後兩者相比,向量數據庫更擅長存儲、管理的數據類型,是我們常見的圖片,影片,音頻,文檔等無法用表格(結構化方式)進行精確描述的非結構化數據。
在傳統數據居里,我們對數據的管理和查找,類似於常見的 Excel,主要依靠對數據進行分門別類後,進行精確查找與運算,比如在超市貨架中找到所有的 「巧克力」,非常的容易。但如果要找到具有某一類型特徵的商品,比如 「可以快速補充血糖的商品」,那麼基於關鍵詞的精準搜索就幫不上忙了。
而向量數據庫對數據的存儲與管理,是基於其 「特徵」 的相似度,比如一張巧克力的照片,經過 AI 模型對其進行特徵提取,存儲在向量數據庫中,就會變成一系列獨特的如 「高脂肪」「零食」「高糖」「褐色」「原產中南美洲」 等 「特徵碼」,進而響應 「補充血糖」 這樣的特徵檢索需求。
也是因此,與傳統的數據庫相比,向量數據庫與時下大火的大模型的關係也更為密切。
一個典型的應用方向是 RAG。
RAG,全稱 Retrieval-Augmented Generation,中文可以理解為 「檢索增強生成」,一般被廣泛用於垂類知識庫的構建,用以解決大模型的幻覺、垂類知識缺乏,以及知識動態更新的困境。
過去幾年中,ChatGPT 為代表,大模型的出現讓人工智能的通識水平以及推理能力有了飛躍性的提升。然而大模型最大的缺陷在於,缺乏專業領域知識以及長期記憶,並且容易出現幻覺。因此,我們經常可以看到大模型可以寫複雜的程序,卻被小學生奧數題難倒,再比如,一些大模型在學習了錯誤、「有毒」 的數據素材後,會分不清 「南唐」 與 「唐朝」,也會對李白的作品有哪些等問題張冠李戴。
與此同時,在金融等領域,我們通常需要最新的一手數據與知識進行分析,然而大模型在訓練完成後,所擁有的知識就已經被固定,缺乏對行情為代表的知識與信息的動態補充能力。
通過向量數據庫,企業可以將自身的垂類知識、企業專屬知識等內容以 RAG 模式接入大模型,進而使其迅速掌握醫藥、法律、汽車等專業領域的知識之外,也能夠實時進行知識的動態更新。
也是因此,大模型撬動市場對向量數據庫的需求;向量數據庫成為大模型通往智能之路的催化劑。市場就像滾雪球一樣,在這個永動機式的擴張中越變越大。
但向量數據庫的潛力遠不止於此,大模型之外,個性化多模態內容搜索、推薦系統、精準營銷、風控、欺詐檢測、網絡安全、自動駕駛、虛擬藥物篩選同樣也是向量數據庫應用的核心場景。
下遊應用的爆髮帶來了市場規模的進一步擴張:DB-Engines 數據顯示,過去三年中,向量數據庫一直是最受歡迎的數據庫類別;Gartner 也預測,到 2026 年,30% 的企業將把向量數據庫集成到其生成式 AI 模型中。
東北證券則對市場規模做了進一步測算,到 2030 年,全球向量數據庫市場規模有望達到 500 億美元,國內向量數據庫市場規模有望超過 600 億人民幣。
歷史已經告訴我們,一切風口之中,賣鏟子才是最穩賺不賠的生意。
而向量數據庫,就是大模型時代那把通往未來的金鏟子。
二、向量數據庫的江湖派系
如果不出意外,在這個賽道中,誕生千億級別的企業,只是時間的早晚問題。
也正是在這種無法抗拒的誘惑下,市場隨之迅速被劃分為三大派別:
第一派玩家,獨立的向量數據庫創業公司。
其優勢在於產品化,相比傳統單機插件式數據庫,向量數據庫的檢索規模可以提升十倍,支持百萬級每秒查詢(QPS)的峰值能力,同時延遲控制在毫秒級。
不足則是由於部分創業公司成立時間較短,缺乏各種數據庫應該具備的基礎性能力,例如:備份 / 恢復 / 高可用、批量更新 / 查詢操作,事務 / ACID 等。此外,數據跨庫帶來的不同步也是個不容忽視的問題。比如如果用戶在最原始的 PostgreSQL 中刪除了某一條數據後,沒有在向量數據庫中實時同步,就會出現數據不一致,在生產環境中帶來影響。
第二派,傳統數據庫玩家:如甲骨文 和 MongoDB 等,通過在傳統數據庫上加上一個具備向量檢索能力的插件,從而使得傳統數據庫具備了向量的檢索能力。
其優勢在於數據不再需要在多個數據庫之間同步、流轉、處理。劣勢則在傳統數據庫對海量非結構化數據的處理與支持存在一定的缺陷。比如建一個圖庫類應用,對 10 億級別圖片進行以圖搜圖,每張圖片對應 128 維 Float 向量,需要的服務器內存將高達 480GB ,早已超出單機內存的極限。也就是說,百萬以及千萬級的數據中,傳統數據庫做加法,可以支撐一定的用戶的需求,如果要做到億級乃至 10 億的數據規模,就需要專業的企業級分佈式向量數據庫了。
第三派玩家,雲服務巨頭。以 AWS 和 Microsoft 為代表,他們會在雲服務的產品體系中,加入自研的向量數據庫產品,優勢在於 「買一贈一」、服務連續,缺點則在於雲服務巨頭們往往同時在做大模型、應用、雲服務、向量數據庫,既做球證又做運動員的情況下,企業如何放心將私密的知識庫放在雲上,就成了新的問題。
至此,天下三分。傳統數據庫玩家在 noSQL、圖數據庫、關係型數據庫、向量數據庫多個戰場四面開花;雲服務巨頭爭位流量端,讓向量數據庫成為整體業務上運中買一贈一中的贈品;而創業公司則以產品與壓強式投入見長,在性能與服務上獨領風騷。
三、向量數據庫的半場戰報
就在各大玩家還在低著頭蒙眼狂奔同期,今年三季度,Forrester 已經通過一張 「Forrester Wave™ 向量數據庫報告」,從產品能力、商業策略、市場表現三大方向的 25 大維度,為 14 家頭部向量數據庫排好了彼此的身家位次。
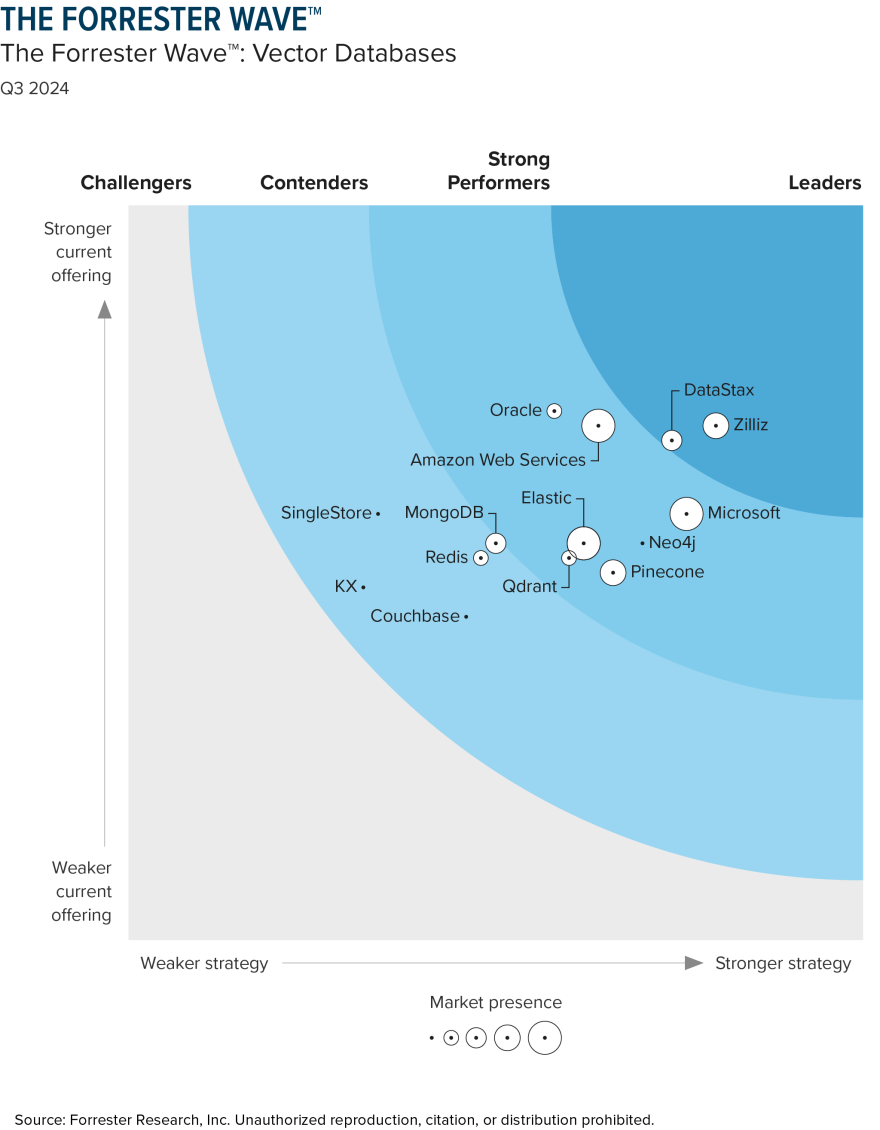
在 Forrester 的座次表中,進入領導者象限的,是第一派玩家 —— 向量數據庫創業公司的代表 Zilliz;第二梯隊,則以 Oracle、Microsoft、AWS、Pinecone 為代表;第三梯隊,則是 MongoDB 等玩家。
整體來說,向量數據庫創業公司的整體座次與入圍數量最為佔優;第二派傳統數據庫玩家以及第三派雲服務巨頭的表現各有千秋。
如何對不同玩家進行座次排布,Forrester 也表述的很直白:優秀的向量數據庫供應商,應當具備以下能力:1、向量索引、元數據管理、向量檢索和混合搜索等各種完整的向量數據庫功能;2、完整的數據管理功能,包括向量存儲、實時數據更新、數據集成、資源優化、數據完整性和一致性、併發控制和彈性可擴展性;3、用戶友好的 UI 設計以及全面好用的 API;4、面對億級數據規模的可擴展性,對 GPU 集成的支持。

以此次進入領導者象限的老牌玩家,也是向量數據庫的開創者 Zilliz 為例。Forrester 對其作出的評價是,Zilliz 整體在管理海量向量數據方面表現突出。尤其在向量維度、向量索引、性能和可擴展性上表現出色,因此尤其適合那些優先考慮高性能和低延遲訪問大量向量數據以用於高級 AI 應用程序的客戶。
具體展開來說,在 Forrester 最關心的向量索引層面,以 Zilliz 為代表的原生向量數據庫相比在普通數據庫上做加法的產品,在基礎的向量索引、元數據管理、向量檢索和混合搜索方面,具備先天的優勢。
完整的數據管理功能方面,Milvus 與 Zilliz Cloud 更是市面上為數不多可以提供(向量存儲、實時數據更新、數據集成、資源優化、數據完整性和一致性、併發控制和彈性可擴展性)等功能的產品,與之形成鮮明對比的是部分市面上宣傳的向量數據庫產品,在相當長一段時間里,連最基本的備份恢復功能都不具備。
UI 與 API 等用戶使用體驗方面,Zilliz Cloud 可以提供開箱即用的向量數據庫服務。
可擴展性上,Milvus 能夠處理數百萬乃至數十億級的向量數據,是最受歡迎的開源向量數據數據庫之一;而 Zilliz Cloud 能為用戶提供百億級向量數據毫秒級檢索能力。與此同時,GPU 集成上,GTC 2024 上,Zilliz 還與英偉達聯手發佈了全球首個 GPU 加速向量數據庫,由英偉達 CUDA 加持,性能實現 50 倍提升。
產業側,Zilliz 除了是 OpenAI 官方首批 plugin 合作的向量數據庫之外,全球的客戶與合作夥伴數量也已經超過萬家,並在圖片檢索、影片分析、自然語言理解、推薦系統、定向廣告、個性化搜索、智能客服、欺詐檢測、網絡安全和新藥發現等領域實現落地。
總結來說,Milvus 與 Zilliz Cloud 是市面上為數不多,做到了向量管理等基礎功能之外,能夠對海量數據支持、完整數據庫功能做好產品級支持的玩家。
而對另外兩派玩家的點評,可以從其對 AWS 以及 Oracle 的點評中一窺 Forrester 的態度。
對於 Oracle,產品能力、商業策略上的優勢不必多提,但報告開篇,Forrester 也直白指出,傳統數據庫在向量維度和相似性搜索方面存在局限性。
關於 AWS,Forrester 則認為其在向量維度、數據庫管理、API 支持、數據安全性和向量搜索等方面頗有建樹,而最大的不足則在於,這些服務僅限於 AWS 雲。
沒有人會不喜歡一個完整的生態,但是如果選擇生態的代價是將最核心的數據資源與之綁定,那麼決策的天秤也會就此傾斜。
尾聲
一個被低估的市場
在向量數據庫的割據暗流湧動之時,一個時間鎖已經清晰出現在眼前。
歷史上,圍繞數據庫發生的戰爭,這已經是第三次。
上世紀八十年代,以美國軍方的需求為牽引,數據庫的老牌玩家甲骨文就此在 IBM 的銅牆鐵壁包圍下誕生,使用關係型數據庫處理結構化數據成為此後三十年間數據庫產業的主流。
到了 2010 年前後,互聯網的成熟,使得人類歷史所產生的數據量飛速膨脹,與此同時,我們對數據的需求,也在關係型數據庫的 「行列」 運算的基礎上演變,存儲、讀取,高併發成為這一時期的典型特色,由此,非關係型數據庫(簡稱 NoSQL)誕生,MongoDB 成為這一時期的代表性玩家。
再到 2022 年底,大模型技術成熟,傳統的基於字段的精準搜索之外,基於向量的相似性搜索需求瞬間爆發,向量數據庫一時之間炙手可熱。過程中,一大批新的 「大衛」 開始向巨人歌利亞發起挑戰,淘汰與玩家梯隊也在兩年間迅速產生階段性成果。
為什麼階段性的勝出者會是 Zilliz 為代表創業公司?
答案很簡單 —— 尊重市場。
尊重的第一層,是尊重時代的機遇。與過去的任何一次技術浪潮都不同,站在開源的肩膀上,大模型的誕生與普及,讓全世界所有企業都站在了同一起跑線。也是因此,全球化成為了這一批企業的共同代名詞 —— 在 Zilliz 成立之初,所有的新品與技術發佈,是面向全球的,團隊的構成也同樣遍佈中國、美國、歐洲、日本、新加坡全球各處。
尊重的第二層,是尊重客觀的用戶需求,以及非結構化數據的差異性和巨大潛力。面對用戶的需求,Zilliz 既有在 GitHub 上 3W 星的開源項鏈數據庫 Milvus,同樣有主打開箱即用的 Zilliz Cloud 。敢於從 0 做起,構建全新的產品以及服務,而不是簡單的成熟產品做加法。
這種尊重的第三層,也是最重要的一環則是堅持。作為最早一批向量數據庫企業,Zilliz 早在大模型尚未成為顯學的 2019 年,就敲下了全世界範圍內向量數據庫的第一行代碼,即是市場的開創者,也是長期的布道者,這也為後來 Zilliz 登上英偉達與 OpenAI 的生態大船,埋下伏筆。
未來,誰會是下一個從大風大浪里走出來的 IOE,市場還需要時間驗證,但天秤已經在慢慢向長期主義選手傾斜。