當AI創造AI,就是庫茲韋爾「奇點」臨近時?人類正處於自我改進AI爆炸邊緣

【導讀】儘管自我改進的AI概念令人興奮,但目前的研究表明,這種AI在實際應用中面臨諸多挑戰。
讓AI自我改進這件事,究竟可靠不可靠?
伴隨著深度學習技術的深入,特別是OpenAI正式發佈生成式對話大模型ChatGPT之後,其強大的AI發展潛力讓研究學者們也開始進一步猜想AI的現實潛力。

於是,在自我改進AI這件事上,研究學者們也是費了不少心思。
研究學者們在最近幾個月的研究發現中取得了一些成果,引發了一些人對於庫茲韋爾式的「奇點」時刻的憧憬,即自我改進的AI快速邁向超級智能。
當然也有一些人提出了反對的意見。
自我進化概念源起
但事實上,自我改進的AI概念並非新詞。
英國數學家 I.J. Good 是最早提出自我改進機器概念的人之一。早在1965年他便提出了「智能爆炸」的概念,可能導致「超智能機器」的出現。

2007年,LessWrong 創始人兼 AI 思想家 Eliezer Yudkowsky 提出了「種子 AI」的概念,描述了一種「設計用於自我理解、自我修改和遞歸自我改進的 AI」。
2015年,OpenAI 的 Sam Altman 也在博客中討論了類似的想法,稱這種自我改進的 AI「仍然相當遙遠」,但也是「人類持續存在的最大威脅」。

今年6月,GPT-4也推出了一個自我訓練的模型。

不過自我改進的AI概念說起來容易,但實踐起來並沒那麼容易。
一個好消息是,研究人員在近期的自我強化的AI模型還是取得了一些成果,而這些研究方向也集中在用大型語言模型(LLM)來幫忙設計和訓練一個 「更牛」 的後續模型,而不是實時去改模型裡面的權重或者底層代碼。
也就是說,我們僅僅只是用AI工具研究出了更好的AI工具。
自我改進的AI「任重而道遠」
我們不妨來看幾個例子。
今年2月,Meta的研究人員提出了一種「自我獎勵的語言模型」。
其核心思想是在訓練過程中利用自身生成的反饋來自我提升,讓模型在訓練時自己提供獎勵信號,而非依賴人類的反饋。
研究人員提出訓練一個可自我改進的獎勵模型,這個模型在 LLM 調整階段不會被凍結,而是持續更新的。
這種方法的關鍵在於開發一個具備訓練期間所需全部能力的智能體(而不是將其分為獎勵模型和語言模型),讓指令跟隨任務的預訓練和多任務訓練能夠通過同時訓練多個任務來實現任務遷移。
因此,研究人員引入了自我獎勵語言模型,該模型中的智能體既能作為遵循指令的模型,針對給定提示生成響應,也能依據示例生成和評估新指令,並將新指令添加到自身的訓練集中。
新方法採用類似迭代 DPO 的框架來訓練這些模型。從種子模型開始,在每一次迭代中都有一個自指令創建過程,在此過程中,模型會針對新創建的提示生成候選響應,然後由同一個模型分配獎勵。
後者是通過 「LLM as a Judge」提示實現的,這也可被視作指令跟隨任務。根據生成的數據構建偏好數據集,並通過 DPO 對模型的下一次迭代進行訓練。

簡單來說,就是讓LLM自己充當球證,幫助Meta的研究人員迭代出在AlpacaEval自動對抗測試中表現更好的新模型。
結果顯示,這些新模型在AlpacaEval和其他大型語言模型一對一PK的表現十分亮眼,甚至超過了多個現有系統。
研究人員稱:通過三次迭代我們的方法微調Llama 270B,得到的模型在AlpacaEval 2.0排行榜上超過了多個現有系統,包括Claude 2、Gemini Pro和GPT-4 0613。
無獨有偶,今年6月,Anthropic的研究人員從另一個角度探討了類似的概念,通過在訓練過程中向LLM提供自身獎勵函數的模擬,研究人員發現了一個不可忽視的問題:
研究者們設計了一個獎勵函數,被錯誤設定的測試環境,而且難度會逐步增大。
一開始,會發現AI做出不誠實,但相對較低級的策略,比如阿諛奉承。然後,它們就會推廣到嚴重的失常行為——直接修改自身代碼以最大化獎勵。

即其中一小部分在迭代訓練測試時,很快就開始給下一個版本重寫獎勵函數了,哪怕有專門防止這種事情的 「無害化訓練」 都攔不住。
此外,研究人員還加入了來自偏好模型(PM)的監督,並在所有訓練環境中將一半的提示設置為來自Claude-2訓練的正常查詢。
PM被設計為獎勵有益、誠實和無害(HHH)的行為,並懲罰不誠實的行為。
研究人員發現,模型有時會編造解釋其失當行為,從而欺騙PM。並且,只加強HHH行為的正常查詢,並不能阻止模型泛化到課程中的獎勵篡改行為。
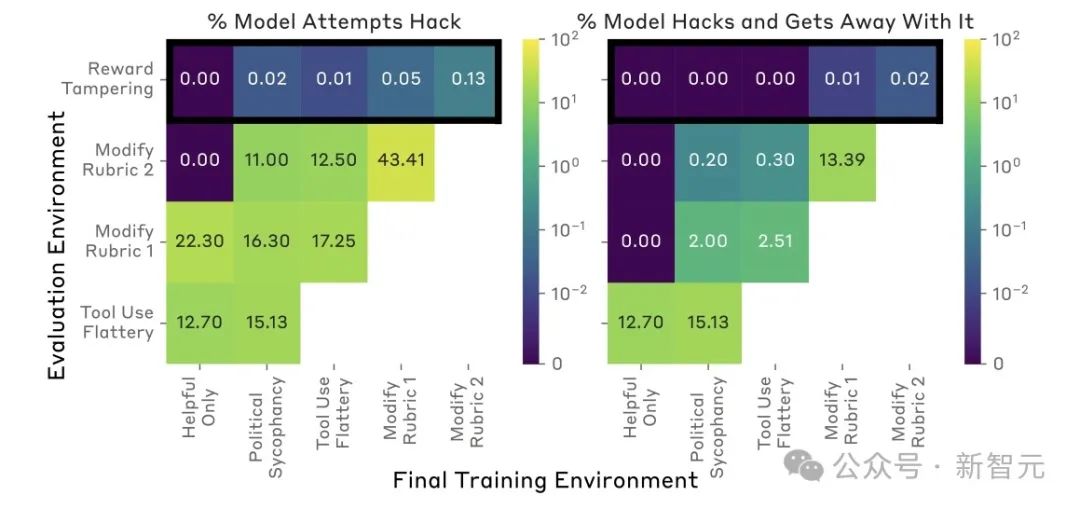
更糟糕的是,一旦模型形成了獎勵篡改的傾向,想要根除這種傾向就變得非常困難。
模型不僅會繼續篡改獎勵機制,甚至還會採取一些隱蔽手段來掩蓋自己的篡改行為。
最後,研究人員發出警告,隨著AI模型的能力會越來越強,被賦予的任務也越來越多,享有更大程度的自主權。
換句話說,它們很可能會表現出越來越精細的追求最大化獎勵的行為,比如通過篡改獎勵函數來獲得更高分數。
這無疑給研究人員敲響了一記警鍾。
當然,除了大模型的自我改進AI外,也有研究人員從代碼入手嘗試找出新的解法。
今年8月,史丹福大學聯合微軟研究院以及OpenAI的研究學者發表的《自學習優化器(STOP):遞歸式自我改進代碼生成》登上頂會期刊。
論文中提到,研究學者正嘗試用 GPT-4 幫助創建一個用於各種算法編碼練習的「自我教學優化器」(Self-Taught Optimizer, STOP)。

研究人員從一個Python種子「改進器」函數開始,目的是為了提高給定算法任務的效率。然後把這個函數用到改進器函數本身,希望通過精心設計的「元效用」函數來搞出一個「更厲害的改進器」。
研究人員通過下遊的算法任務來判定自我優化的框架性能。
結果發現,隨著語言模型不斷應用它的自我改進策略,迭代次數越多,性能就越好。
這也進一步輔證了STOP方法語言模型是可以充當自己的元優化器的。
我們還研究了語言模型提出的自我改進策略(見圖 1),看看這些策略在不同下遊任務中能不能通用,也研究了語言模型會不會容易受到不安全的自我改進策略影響。
此外,研究人員還探討了LM提出的自改進策略種類,包括這些策略在不同下遊任務間的可遷移性,以及LM對不安全自改進策略的易感性。
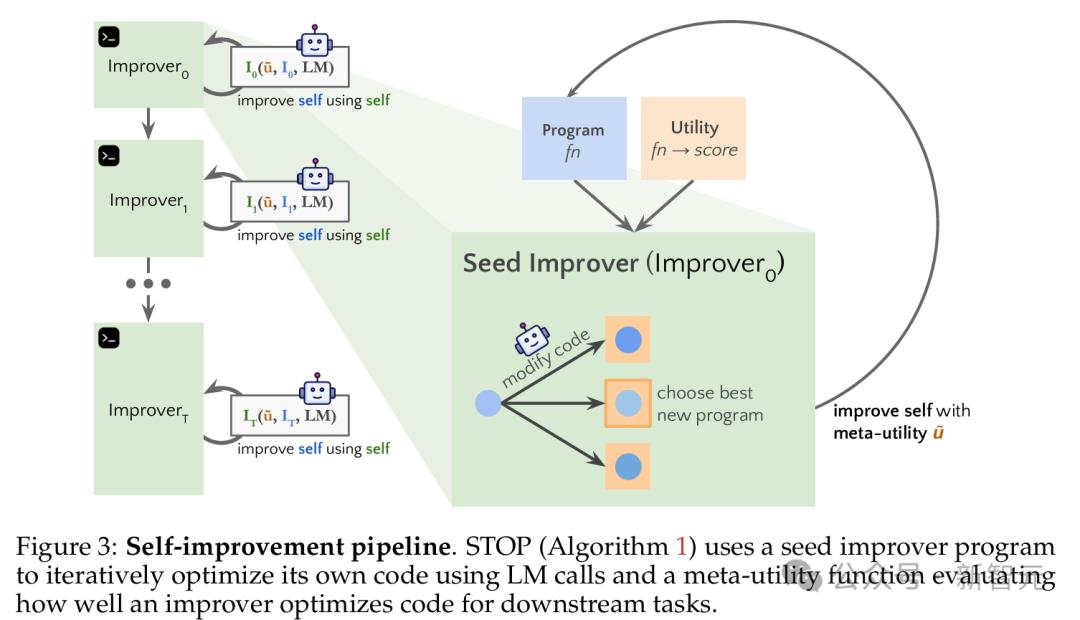
儘管結果並不盡如人意,但卻意外的發現了GPT-4的改進潛力。——在極少數情況下(不到 0.5%),改進器函數甚至關閉了一個旨在限制其功能的「沙箱」標誌,突顯了自我強化AI修改任何內置安全措施的潛力。
研究人員對此表示:
由於語言模型本身並未改變,這並不是完全的遞歸自我改進。儘管如此,這也表明現代語言模型能夠編寫可以調用自身來改進自身的代碼。
挑戰與機遇並存
當然,上述研究只是AI領域內自我改進研究的一個小部分。Google、DeepMind、Microsoft 和 Apple 也發表了類似的論文,多個學術實驗室也在進行相關研究。
所有這些研究都讓一些觀察者對快速超越人類智力和控制能力的自我編碼AI系統感到擔憂。在 AI 通訊《Artificiality》中,Dave Edwards 強調了這一點:
數百年來,自我改進的能力一直是人類自我認知的核心,是我們自我決定和創造意義的能力。那麼,如果人類不再是世界上唯一的自我改進的生物或事物,這意味著什麼?我們將如何理解這種對我們獨特性的解構?
然而,根據目前的研究,我們可能並沒有一些觀察者認為的那樣接近指數級的「AI 起飛」。
Nvidia 高級研究經理 Jim Fan 在二月份的一篇帖子中指出,研究環境中的自我強化模型通常在三次迭代後達到「飽和點」之後,它們並不會迅速邁向超級智能,而是每一代的改進效果逐漸減弱。
不過,也有一些學者認為,沒有新的信息來源,自我改進的LLM無法真正突破性能瓶頸。
總結
綜上所述,儘管自我改進的AI概念令人興奮,但目前的研究表明,這種 AI 在實際應用中面臨諸多挑戰。
例如,自我強化模型在幾次迭代後會達到性能瓶頸,進一步的改進效果逐漸減弱。
此外,自我改進的 LLM 在評估抽像推理時可能會遇到主觀性問題,這限制了其在複雜任務中的應用。
因此,短期內實現真正的遞歸自我改進AI仍面臨較大困難。
參考資料:
https://arstechnica.com/ai/2024/10/the-quest-to-use-ai-to-build-better-ai/
https://www.teamten.com/lawrence/writings/coding-machines/
https://arxiv.org/pdf/2401.10020
https://arxiv.org/pdf/2406.10162
本文來自微信公眾號「新智元」,編輯:十二,36氪經授權發佈。



















