算法系統協同優化,vivo與港中文推出BlueLM-V-3B,手機秒變多模態AI專家
AIxiv專欄是機器之心發佈學術、技術內容的欄目。過去數年,機器之心AIxiv專欄接收報導了2000多篇內容,覆蓋全球各大高校與企業的頂級實驗室,有效促進了學術交流與傳播。如果您有優秀的工作想要分享,歡迎投稿或者聯繫報導。投稿郵箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
BlueLM-V-3B 是一款由 vivo AI 研究院與香港中文大學聯合研發的端側多模態模型。該模型現已完成對天璣 9300 和 9400 芯片的初步適配,未來將逐步推出手機端應用,為用戶帶來更智能、更便捷的體驗。
近年來,多模態大語言模型(MLLM)的迅猛發展,為我們的日常生活帶來了無限可能。手機作為我們形影不離的「智能伴侶」,無疑是 MLLM 最理想的落地平台。它能夠將強大的 AI 能力,無縫融入我們的日常任務,讓科技真正服務於生活。
然而,要將 MLLM 部署到手機上,並非易事。內存大小和計算能力的限制,就像兩座大山,橫亙在 MLLM 與手機之間。未經優化的模型,難以在手機上實現流暢、實時的處理,更遑論為用戶帶來良好的體驗。

-
論文地址:https://arxiv.org/abs/2411.10640
為了攻克這一難題,vivo AI 全球研究院和香港中文大學多媒體實驗室共同推出了 BlueLM-V-3B。這是一款專為移動平台量身打造的 MLLM,採用了算法與系統協同設計的創新理念,重新設計了主流 MLLM 的動態解像度方案,並針對手機硬件特性進行了深度系統優化,從而實現了在手機上高效、流暢地運行 MLLM。
BlueLM-V-3B 具有以下幾個顯著特點:
算法與系統協同優化
研究團隊分析了經典 MLLM 使用的動態解像度方案,發現了圖像過度放大的問題,並提出了針對性的解決方案。
此外,他們還針對硬件感知部署進行了一系列系統設計和優化,使 MLLM 在移動設備上能夠更高效地進行推理,充分發揮硬件潛力。
卓越的模型性能
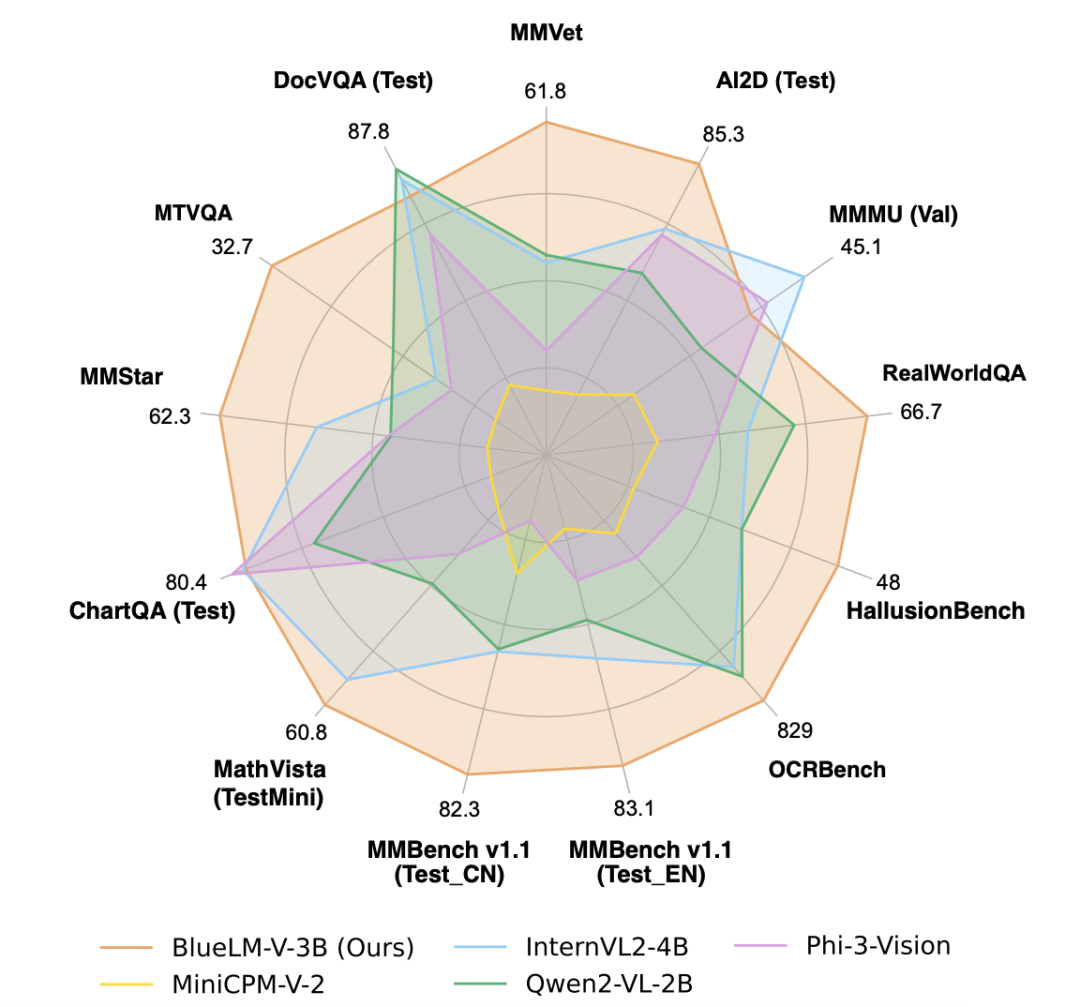
BlueLM-V-3B 在性能上表現出色,在參數規模相似的模型中達到了 SOTA 水平(例如,在 OpenCompass 基準測試中取得了 66.1 的高分)。
更令人驚喜的是,BlueLM-V-3B 甚至超越了一系列參數規模更大的 MLLM(例如,MiniCPM-V-2.6、InternVL2-8B),展現了其強大的實力。
高效的移動端部署
BlueLM-V-3B 在移動端部署方面同樣表現優異。以聯發科天璣 9300 處理器為例,其內存需求僅為 2.2GB,能夠在約 2.1 秒內完成對 768×1536 解像度圖像的編碼,並實現 24.4token/s 的 token 輸出速度。
這意味著,用戶可以在手機上享受到流暢、高效的 MLLM 體驗,而無需擔心算力瓶頸。
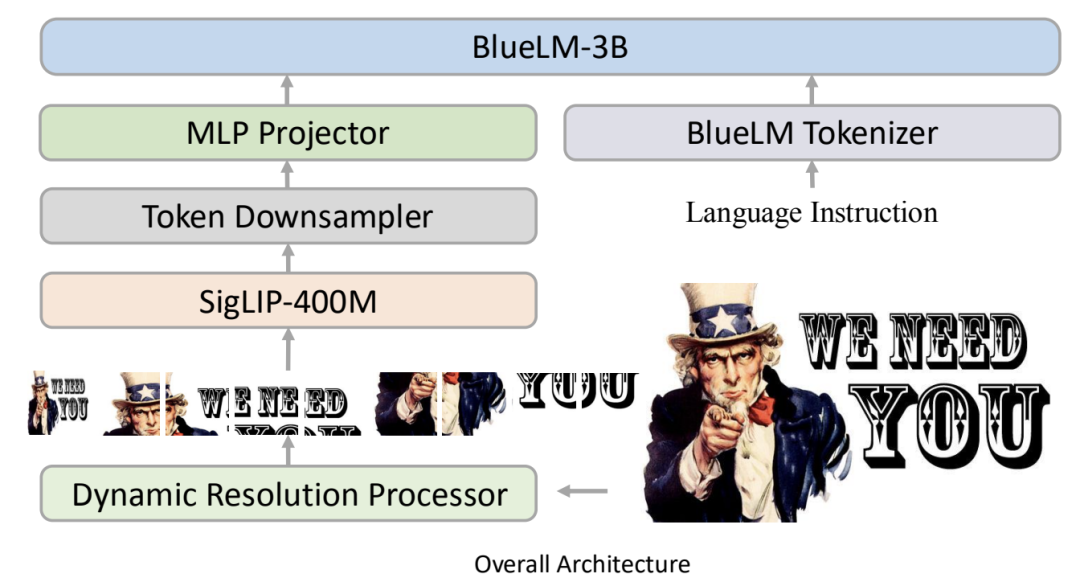
BlueLM-V-3B 設計思路
模型主體結構
BlueLM-V-3B 延續了傳統的 LLaVA 架構,包括視覺編碼器 SigLIP-400M,MLP 線性映射層,以及大語言模型 BlueLM-3B。
為了更好地處理高解像度圖片,和主流 MLLM 一樣,BlueLM-V-3B 採用了動態解像度方案,並針對 InternVL 1.5 和 LLaVA-NeXT 中存在的圖像過度放大問題進行了改進。
此外,為了應對手機 NPU 在處理長輸入 token 時的性能限制,BlueLM-V-3B 還引入了 token 降采樣的方案,以確保模型在移動設備上的順利部署。
動態解像度
-
算法改進:
為了提升多模態模型應對高解像度圖片的能力,主流的 MLLM 往往採用動態解像度的方案進行圖片的放縮和裁切。該團隊發現主流動態解像度方案,如 LLaVA-NeXT 和 InternVL 1.5 往往伴隨圖片過度放大。
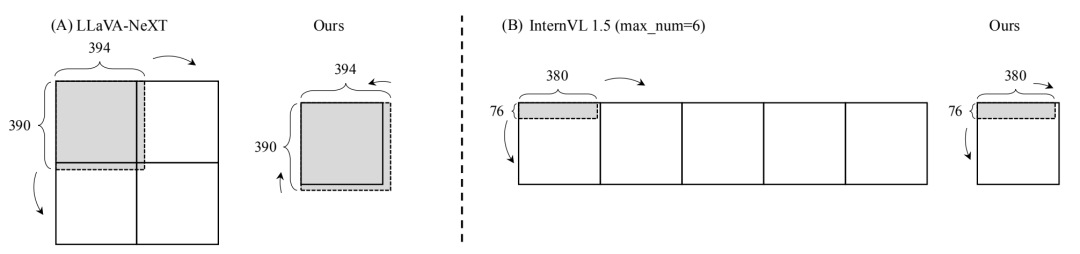
傳統的動態解像度方案往往會選擇一個解像度(如 384×384)作為基準尺寸,並選擇合適的長寬比對圖像進行縮放。
對於 LLaVA-NeXT,給定一個解像度為 394×390 的圖像,它會選擇 2:2 的圖片比例,然後將原始圖像調整併填充至 768×768(放大 4 倍)。
對於 InternVL1.5,給定一個解像度為 380×76 的圖像,它會選擇 5:1 的比例,直接將原始圖像調整至 1920×384(放大 25 倍)。
這種放大並不一定豐富了圖像信息,但會導致更多的圖像切塊,從而增加圖像 token 的數量,增加移動設備上的部署難度。
鑒於此,BlueLM-V-3B 基於 LLaVA-NeXT 設計了一種寬鬆的長寬比選擇算法,綜合考慮了放縮後圖片的有效信息解像度以及浪費的空間,有效提高了圖片信息的利用率,減少了部署時的圖片 token 長度,降低圖片的處理延時。

-
硬件感知的系統設計
圖像並行編碼:經過動態解像度處理後,圖像被分為多個局部切塊以及一張全局縮略圖切塊。為了加速部署推理,BlueLM-V-3B 採用並行策略來利用 NPU 的計算能力。
與高級語言(例如 Python)不同,硬件加速設計需要對計算資源進行底層控制,例如內存佈局和基於寄存器大小的計算優化。
由於 NPU 的計算能力有限,所有圖片切塊無法同時有效處理;相反,BlueLM-V-3B 一次處理固定數量的切塊,以獲得並行處理和硬件性能的平衡。
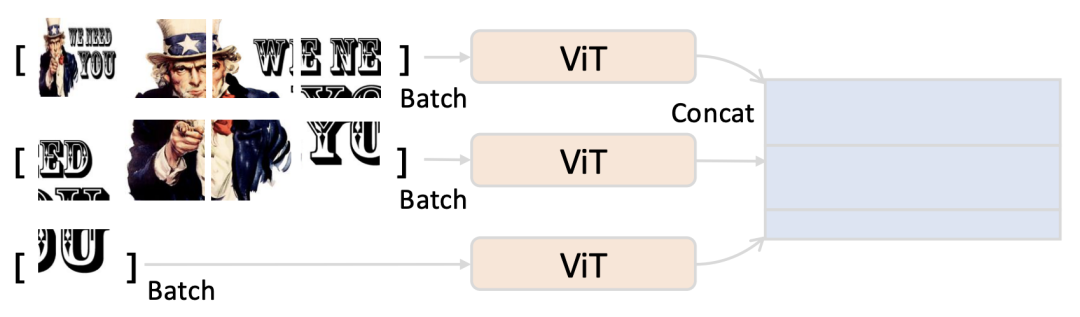
流水線並行處理:在模型推理過程中,BlueLM-V-3B 實現了流水線並行方案,以優化圖像切塊的編碼效率。
具體而言,對於從單個圖像中提取的不同切塊,BlueLM-V-3B 為 SigLIP 視覺嵌入模塊的 Conv2D 層和 ViT 層設計了流水線並行方案。這種方法有效地隱藏了 Conv2D 操作的執行延遲,提升了整體處理速度。

Token 降采樣
-
基礎算法:
雖然 BlueLM-V-3B 設計了一種寬鬆的長寬比選擇算法來降低部署過程中圖片 token 的數量,但動態解像度帶來的圖片 token 數量依然很多。
為此,BlueLM-V-3B 採用了 VILA 提出的 token 數量下采樣方案,將每 2×2 個圖像 token 合併為一個 token,並採用一個線性層做信息融合,降低了部署難度。
-
系統設計:
分塊計算輸入 token:在 LLM 推理過程中,傳統 GPU 通過並行計算技術同時處理所有輸入 token 以加速計算。然而,由於圖像 token 長度較長、上下文信息複雜以及 NPU 計算能力有限,導致並行處理效率低下。逐個 token 的順序處理也不是最佳選擇。
因此,BlueLM-V-3B 在移動設備上採用了分塊策略,每次迭代並行處理 128 個輸入 token(t128),然後合併結果,以在並行處理與 NPU 計算資源之間實現平衡。
模型量化和總體推理框架
-
模型量化:
混合參數精度:BlueLM-V-3B 通過混合精度量化降低內存使用並提升推理速度。權重方面,SigLIP 和 MLP 線性映射層採用 INT8 精度,LLM 則使用 INT4 精度,平衡了計算效率與模型精度。
由於激活值對量化更敏感,LLM 的激活使用 INT16 精度,SigLIP 及映射層的激活則使用 FP16,以確保模型性能。推理過程中,KV 緩存採用 INT8 精度存儲。
-
解耦圖像編碼與指令處理:
為了提高部署效率,BlueLM-V-3B 將圖像處理與用戶輸入解耦。在模型初始化時,ViT 和 LLM 模型同時加載到內存中。用戶上傳圖像時,由於 MLLM 在本地部署,上傳幾乎沒有延遲。圖像上傳後,ViT 立即開始處理,用戶可以同時輸入指令;對於音頻指令,BlueLM-V-3B 會先將其轉換為文本。
圖像處理完成後,用戶的命令提交給 LLM 生成響應,ViT 可以從內存中釋放。這種並行處理減少了第一個 token 生成的等待時間,提高了響應速度,並將 BlueLM-V-3B 的峰值內存使用限制在 2.2GB。

BlueLM-V-3B 的訓練過程
訓練流程
BlueLM-V-3B 從 BlueLM-3B 語言模型開始分兩個階段進行訓練。在第一階段,預訓練線性映射層,同時保持 ViT 和 LLM 凍結。在第二階段,使用大量的圖像 – 文本對對模型進行全面微調。
訓練數據
-
第一階段:
第一階段旨在賦予模型基本的多模態能力。在這一階段,該團隊利用開源數據集,創建了一個由 250 萬條圖像 – 文本對組成的綜合預訓練數據集,這些數據集來自 LLaVA、ShareGPT4V 和 ALLaVA。
-
第二階段:
在這一階段,研究團隊精心構建了一個包含 6億+ 條圖像 – 文本對的數據集,其中包括開源數據集和內部數據集。該數據集涵蓋了各種下遊任務和多樣化的數據類型,如圖像描述、視覺問答、文本圖片識別和純文本數據。
除了開源數據集,他們還加入了大量內部數據以增強模型的能力。比如,從各種網站上爬取了大量的純文本數據和圖像 – 文本對。對於不同的數據類別,如 PDF、公式、圖表、解題數據、多語種數據,團隊還手動渲染並創建了大量的圖像-文本對,以豐富訓練數據的多樣性。
除了進行圖像渲染外,研究團隊還使用 GPT-4o 和 Gemini Pro 構造和修改圖片描述及視覺問答對。開源與專有數據的結合顯著提升了模型的能力,使其能從多樣化的示例中學習,並在多種任務和模態上提升性能。
實驗結果
寬鬆的長寬比選擇算法
-
部署效率:
該團隊在 LLaVA 665k 訓練集上驗證了改進方案是否能降低部署成本。為公平對比,他們將 LLaVA-NeXT、InternVL 1.5 和改進方案的最大分塊數均設置為 9。
與 LLaVA-NeXT 相比,提出的方法在 2.9 萬個樣例中選擇了更小的長寬比;而在與 InternVL 1.5 的比較中,在 52.3 萬個樣例中採用了更小的長寬比,在 2.5 萬個樣例中選擇了更大的長寬比。這顯著提升了 NPU 上的推理效率。
-
測評集性能:
研究團隊在 MiniCPM-2B 和 BlueLM-3B(均為 2.7B 參數量)兩個模型上進行實驗,利用 LLaVA 558k 進行第一階段訓練,用 LLaVA 665k 進行第二階段訓練。比較 LLaVA-NeXT、InternVL 1.5 和改進方案在測評集上的性能表現。
由於 3B 模型的學習速度較慢,每個階段訓兩輪。該團隊統計了在多個常用測評集上的結果。
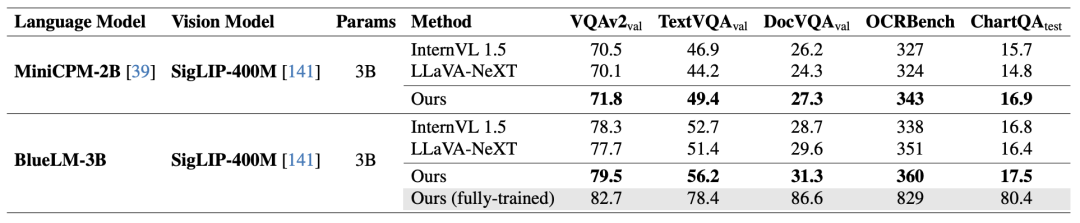
可以看到新設計的動態解像度方案不僅降低了部署成本,還提升了測評集上的準確率。
不同測評集上的準確率比較
-
OpenCompass 測評集:
下圖展示了全量微調完的 BlueLM-V-3B 模型在 OpenCompass 測評集上的精度表現,並和總參數量小於等於 10B 的模型進行比較。

可以看到,BlueLM-V-3B 模型在 4 個測試項目中取得最高分,並在均分上排名第二。這展示了 BlueLM-V-3B 模型的強勁性能。
-
文本數據集 / OCR 能力:
下圖是 BlueLM-V-3B 與參數量相近的多模態模型在 TextVQA,DocVQA 以及多語種多模態數據集 MTVQA 上的評測結果。
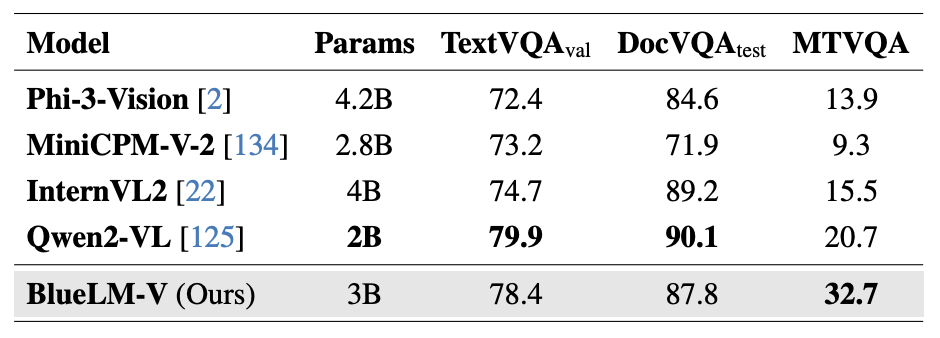
可以看到,在 OCR 相關任務上,BlueLM-V-3B 取得了非常有競爭力的成績,並在多語言測評中遠超主流的多模態模型。
BlueLM-V-3B 部署效率
團隊彙報了在搭載天璣 9300 處理器的 vivo X100 手機上的部署結果。
-
圖像並行編碼:
實驗中,採用了 2:4 的分塊方案(對手機屏幕的處理採用 2:4 方案),共有 2×4=8 個局部分塊和一個全局分塊。該團隊測試了同時處理 1 塊、2 塊、4 塊、6 塊圖像切塊的 NPU 處理延時。
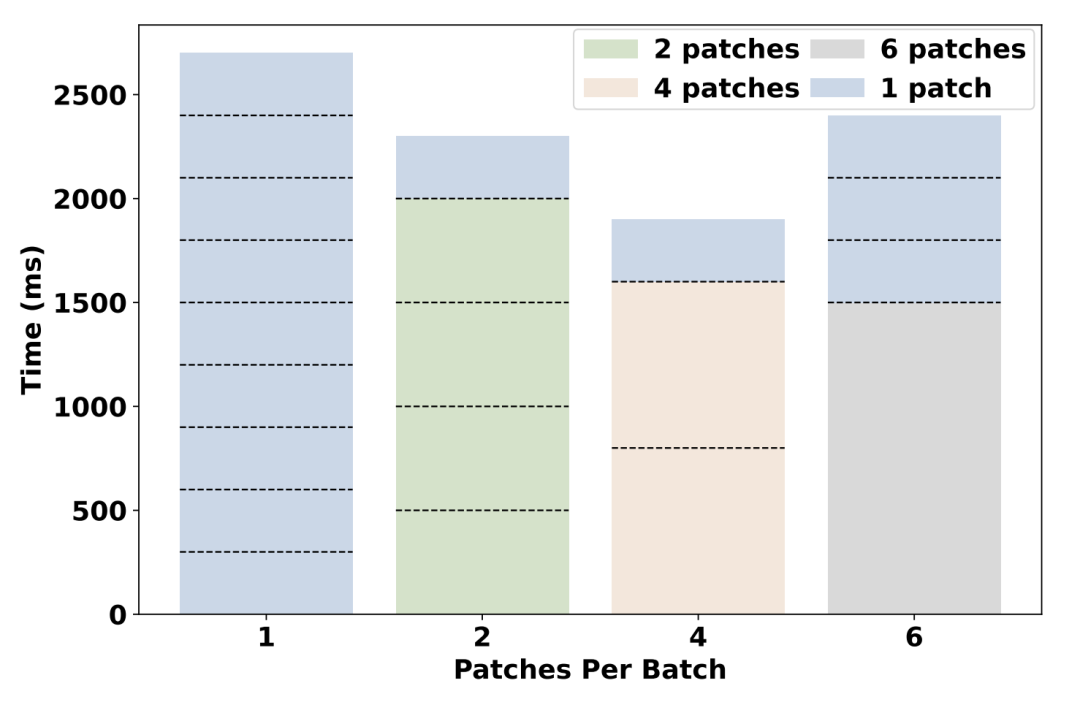
可以看到,同時處理 4 個切塊的總延時最低,僅為 1.9 秒。
-
流水線並行處理:
該團隊設計了對 SigLIP 模型的 Conv2D 和 ViT 部分在 CPU 和 NPU 上的流水線並行,並測試了 2:4 分塊方案下的部署效率。如上文流水線管線所示,可以掩蓋 200 毫秒的 Conv2D 的處理延時。
-
分塊計算輸入 token:
該團隊在 NPU 上採用了一種分塊處理策略,每次迭代並行處理 128 個輸入 token(t128),以平衡並行處理與 NPU 性能。在此展示並行處理不同數量輸入 token 時的 LLM 首詞延時:t32、t128、t512 和 t2048。
論文中還列出了輸出 token 的生成速度,其中僅顯示了 t1 的情況,因為 LLM 在輸出時一次處理一個 token。輸入 token 長度被固定為 2048,KV 緩存長度被設置為 2048。
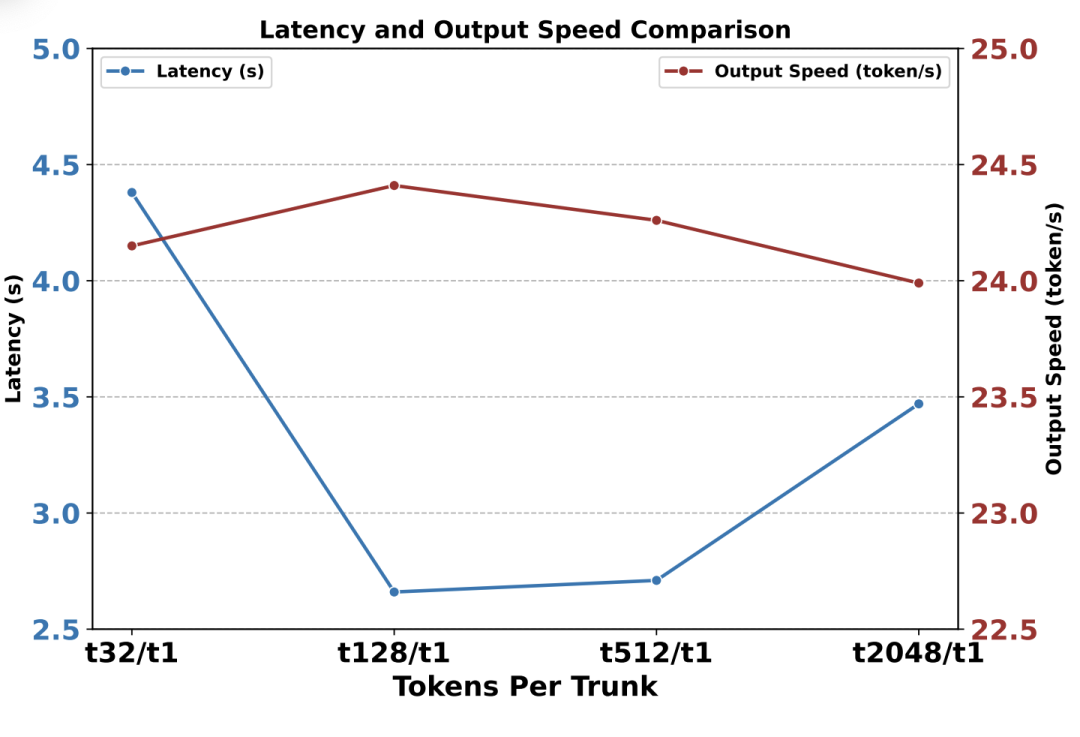
可以看到,t128/t1 實現了最低的延遲和最快的生成速度。
-
和 MiniCPM-V 對比:
該團隊對 BlueLM-V-3B 與 MiniCPM-V 論文中提供的統計數據進行了直接比較。MiniCPM-V 論文僅報告了 8B 參數量的 MiniCPM-V 2.5 模型在天璣 9300 芯片的 CPU 上使用 llama.cpp 部署的情況。BlueLM-V-3B 團隊使用解像度為 768×1536 的圖像,固定輸入 token 長度為 2048,並將 KV 緩存長度設為 2048。

MiniCPM-V 將模型加載時間也計入了延遲。對於 BlueLM-V-3B,在系統初始化階段,同時加載 ViT 和 LLM 的時間僅為 0.47 秒。結果顯示,BlueLM-V-3B 因其較小的參數量和優秀的系統設計,在延遲和 token 吞吐量上更具優勢。
總結
在 BlueLM-V-3B 的開發過程中,vivo 和港中文團隊在確保良好用戶體驗的同時,注重算法 – 系統協同設計和硬件感知優化。據實驗與統計分析顯示,BlueLM-V-3B 在移動設備上表現出色,性能強勁且部署高效。
未來,該團隊將繼續致力於提升端側模型的可擴展性,並探索先進算法,持續優化性能與可用性,以適應更多的手機設備。























