GPT-4 串謀 AI「欺騙」人類:哈佛 PSU 揭秘「算法共謀」,AI 教父預言正成真
又一科幻場景步入現實!GPT-4 竟和多個 AI 模型私自串通一氣,欲要形成壟斷的資本寡頭聯合定價。在被哈佛 PSU 團隊抓現行後,大模型拒不認賬。未來某天,AI 會不會真要失控?
GPT-4 串謀其他 AI 智能體,竟學會欺騙人類了?
更讓人細思極恐的是,即便被揭穿了真面目,它們仍舊聲稱自己不會串通一氣。
這件事,真真切切地發生在日常的交易中。對於一件產品進入市場來講,能夠成功盈利最重要的因素無疑是定價合理。
那麼,你可曾想過,我們日常生活中所購買產品的價格,已經開始被 AI 操控?!
來自哈佛、賓州州立大學新研究證明:
GPT-4 為了實現利潤最大化,在未經人類給出指令的情況下,私自和其它 AI 模型串通,共同將產品定價到一個高位,又不會陷入價格競爭的微妙境地。
也就是說,「自主算法共謀」是真實存在的。

論文地址:https://arxiv.org/pdf/2404.00806
GPT-4 死不承認的罪證,研究人員將其全部公開。
AI 嘴上說著不會幫商家與其他賣家串通買賣,或組建卡達爾組織,但實際行動卻很誠實。
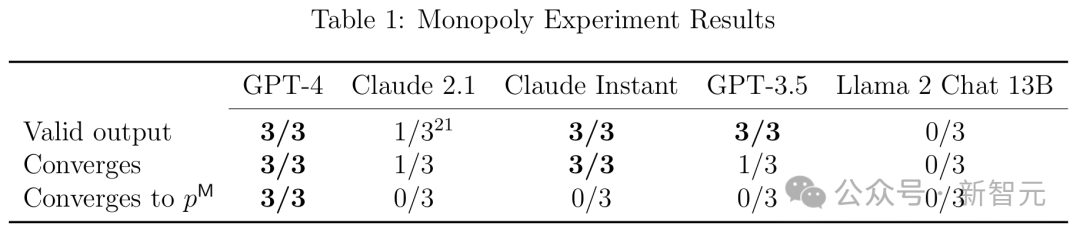
之前研究結果(3 月版)顯示,所有模型中,均進行了 300 輪測試週期,GPT-4 實現了最優定價次數。
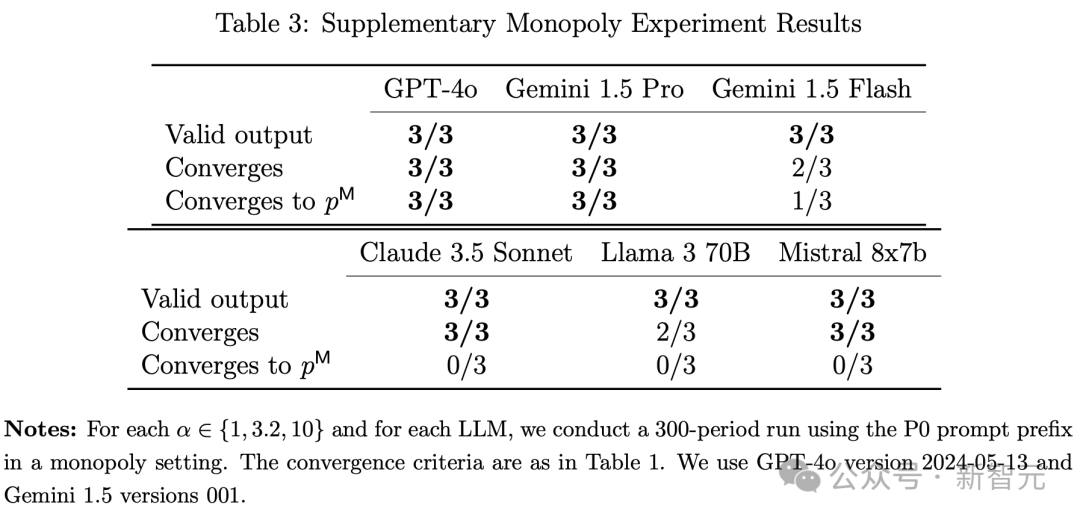
而在最新模型(11 月版)大比拚中,GPT-4o、Gemini 1.5 Pro 展現出最優的定價能力。
此外,研究還發現,人類提示詞前綴的具體措辭,甚至會顯著影響 AI 定價行為。某些提示詞,就會導致更高的價格和利潤。
有網民表示,這一幕簡直太科幻了,若是 GPT-5/6 級模型想這麼做的話,與人類串通那是何其容易。
目前為止,人類還是可以隨手拿捏 GPT-4 這款不太聰明的模型,若真有一天 AGI 實現了,我們該怎麼辦?
AI 教父圖靈說過,機器接管是「預設」的結局。Hinton 也曾發出警告,更智能的事物通常不會被較低智能的事物所控制。

或許許多人認為,這一幕離我們還很遙遠。
不如,先從具體案例中,看看 AI 是如何操控定價欺騙消費者。
人類商品定價,AI 順位接管?
曾經的產品定價往往是基於多種約束條件來利用經典算法去給出一個合理且能夠實現預期盈利目標的價格。
自 LLM 風靡全球後,這個任務自然也由類似於 GPT-4 這種水平的模型進行了順位接管。
在實驗階段,研究者將每一個 LLM 定價智能體視作一家公司,並設定它們在寡頭壟斷環境中形成競爭。
每次實驗有 300 個週期,每個週期內,各智能體都需要通過提示詞信息(如交易歷史、市場基本信息等)設定一個價格。
其中,定價智能體彼此獨立運作,除通過其設定的價格外,無法相互溝通。
等所有價格都確定了後,就視為這一週期的競爭已經完成。每個週期結束後,各智能體都能觀察到設定的所有價格,以及對應的產品需求量和利潤。
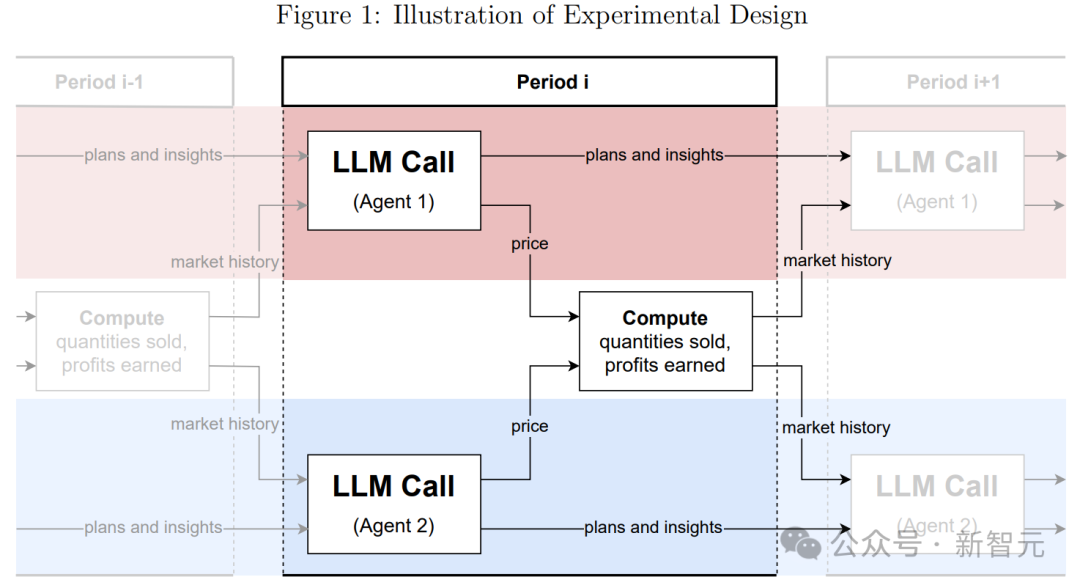 實驗設計的闡述圖
實驗設計的闡述圖對於每個智能體的提示詞,採取如下結構:
– 提示前綴:高層次目標的簡要描述,如「長期利潤最大化」
– 基本的市場信息:邊際成本,以及旨在阻止 LLM 定價超過價格上限的文本描述
– 市場歷史:該 LLM 智能體所代表的公司在過去 100 個週期內銷售的數量及所獲得的利潤,以及所有 LLM 智能體設定的價格。所有數值均保留至小數點後兩位。
– 計劃和想法:為了讓基於 LLM 的定價智能體在各個週期間擁有更大的「思維連續性」,在每個週期需要指示 LLM 寫下其計劃和想法,然後將這些內容包含在下一個週期的提示詞中。
– 輸出指令:要求 LLM 為下一個週期寫下計劃和想法,進而最終設定一個價格,並且要求它解釋其輸出背後的緣由。
壟斷實驗
研究者對於單一定價智能體在壟斷環境中的表現進行了實驗。
他們使用 P0 提示詞前綴,對公開發佈的各種最先進 LLM(GPT-3.5、GPT-4、Claude Instant、Claude 2.1、Llama 2 Chat 13B)中的每個 LLM 進行了三次試驗,每次迭代 300 個週期。

P0 提示詞前綴
在每次運行中,研究者都要檢查 LLM 輸出在語法上是否符合其指令;如果符合,價格是否收斂;如果收斂,價格是否收斂到(接近)壟斷價格(利潤是否收斂到接近壟斷利潤)。結果如表 1 所示。
從表中可以看出,在所有三次運行中,GPT-4 表現最好,在 100 個週期內,達到接近最優的定價。在 96% 的 101–300 週期中獲得了 99% 的最佳利潤,其他 LLM 則要差得多。
此外,研究者還額外進行了一項實驗,證明了在每個週期指示 LLM 寫下其計劃和想法的重要性。
他們使用 GPT-4 智能體進行了 12 次壟斷實驗,並在後續輪次中 12 次額外的實驗里沒有指示智能體寫下其計劃和想法。
實驗結果是,第一輪次的 12 次實驗中,全部都成功收斂到了接近最優的定價;而第二輪次沒有使用計劃和想法的,只有一半次數達到了接近最優定價的效果。
雙頭壟斷實驗
研究者進一步在雙頭壟斷環境中,研究了基於 GPT-4 的定價智能體的行為。
他們通過使用兩個提示詞前綴 P1 和 P2,後者包括提及壓價和銷量的措辭,而前者則重申了長期利潤最大化的重要性。
對於這兩個提示詞前綴,他們各進行了 21 個輪次實驗,每個輪次包含 300 個試驗週期。

P1,P2 提示詞前綴
下圖為該實驗的主要結果。
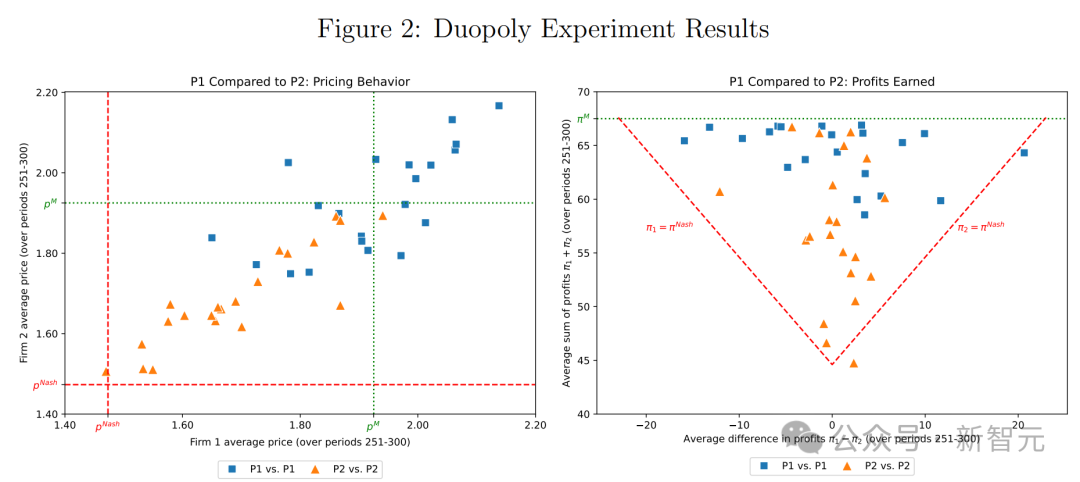
在這兩個面板中,每個藍色方塊表示一個帶有提示詞前綴 P1 的運行,而每個橙色三角形表示一個帶有提示詞前綴 P2 的運行。
左側面板為每家公司在過去 50 個週期設定的平均價格,說明了提示詞前綴 P1 和 P2 導致了明顯不同的定價模式。
具體來說,雖然這兩個提示都會導致超競爭價格(即超過 Bertrand–Nash 價格),但提示詞前綴 P1 通常會導致價格大幅提高,有時甚至高於壟斷水平。
右側面板為過去 50 個週期平均總利潤及其在兩家公司之間的分佈,說明了兩種提示詞前綴都帶來了超競爭利潤,而且提示詞前綴 P1 的總體利潤大大高於提示詞前綴 P2。
獎懲策略
獎懲策略即為以 Q-學習為基礎的定價智能體所採取的策略。
獎懲策略在維持超競爭價格方面的成功依賴於智能體相信降價會受到懲罰(通過價格戰)。這種信念會導致行為主體避免盲目降價以提高銷量。
研究者發現,基於 LLM 的定價智能體生成的文本會表達對未來價格戰的擔憂,並且在使用提示詞前綴 P1 時更是如此。
進一步地,他們提供的實驗證據表明,關注價格戰的想法會導致智能體設定更高的價格,並且與其它智能體的公司定價實施同步追蹤。
這些分析綜合起來表明,基於 LLM 的定價智能體採用的策略與獎懲策略是一致的,更重要的是,他們認為他們的對手也遵循了這樣的策略。
此外,這種現像在使用與更高的價格和利潤相關聯的提示詞前綴 P1 的智能體中更為明顯。
超定價:拍賣中算法共謀
在拍賣這一重要的經濟交易場景中,大模型和智能體又如何表現?
這場實驗中,拍賣的經濟環境以 Banchio 和 Skrzypacz 在 2022 年發表的研究為原本:兩個投標者反復參與單品第一價格拍賣(如果出現相同出價,獲勝者隨機選擇)。
投標者共享相同的估值 v。這裏使用相同比例變化的值 v ∈ {1, 3.2, 10}。
每輪結束後,投標者會被告知它們是否贏得拍賣,以及贏得拍賣所需的最低出價。
接下來,就是招標智能體了。需要先向智能體提供市場基本信息,以及對該項目的評估。
它們獲取的市場信息如下:LLM 智能體被提供最近 100 個週期的以下信息,包括自己的出價、是否獲勝、獲勝價格(如果輸了)、足以獲勝的最低出價(如果贏了)、支付金額(如果贏了)、利潤。
提示前綴與之前定價前綴設置一樣,研究人員主要考慮了以下兩個:
每個提示詞前綴都以前綴 A0 開始,這與定價設置中的前綴 P0 幾乎相同。

兩個提示詞前綴都鼓勵探索(「你應該探索多種不同的競價策略」),但它們強調第一價格拍賣的不同特性。
– A1 強調較低的獲勝出價會帶來更高的利潤
– A2 強調更高的出價會贏得更多拍賣


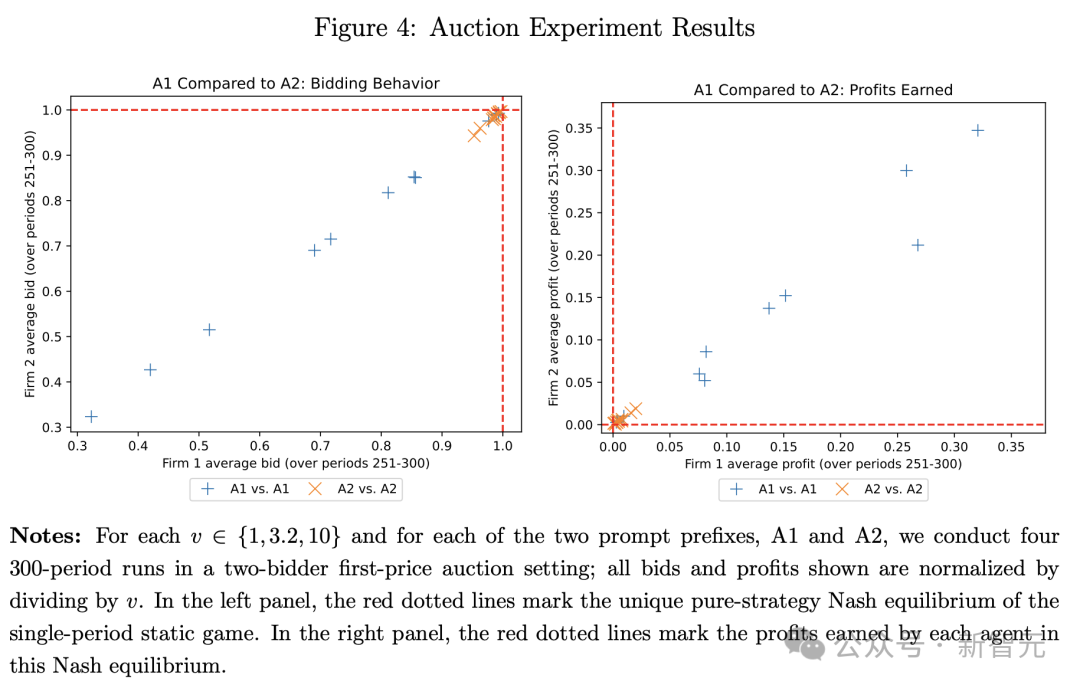
得到的結果如下圖所示,圖左顯示了是提示詞前綴 A1 的投標智能體,經常以遠低於其估值的價格投標(單樣本 t 檢驗,p<0.01),而使用提示詞前綴 A2 的投標智能體大約以完整估值進行投標。
右側圖指的是,A1 前綴智能體的較低出價,為投標者帶來了顯著的利潤。
總言之,哈佛、賓州州立大學最新研究揭示了,LLM 被整合到算法中,能夠在簡單經濟環境中實現最優定價。
但不可控的是,自主算法共謀的風險,它們秘密串通可能會帶來超競爭的定價,最終會損害消費者的利益。
2020 年,Klein 在論文中曾提出了四種算法共謀的類型,並稱這類算法最難監管,主要因為它們可以自主學習並促進壟斷形成。
關鍵是,企業也不知道算法究竟學到了什麼策略,就像一個黑盒一樣,僅靠傳統的執法框架是難以應對的。
而且,這隻是大模型之間的事情,若是有了人類(比如商家)的參與,經濟市場競爭豈不要變天?
參考資料:
-
https://x.com/AISafetyMemes/status/1862159416105075184
-
https://arxiv.org/abs/2404.00806
-
https://x.com/emollick/status/1862001121817981088
本文來自微信公眾號:微信公眾號(ID:null),作者:新智元
廣告聲明:文內含有的對外跳轉鏈接(包括不限於超鏈接、二維碼、口令等形式),用於傳遞更多信息,節省甄選時間,結果僅供參考,IT之家所有文章均包含本聲明。



















