顛覆現有 Agent 範式,清華&面壁提出新一代主動Agent交互範式
當前,哪怕是 ChatGPT 等最先進的 AI Agent 都是傳統的被動式 Agent(下圖 1 左側所示),即需要用戶通過明確的指令顯示告訴 Agent 應該做什麼,Agent 才能繼續執行接下來的任務。
而近期清華大學聯合面壁智能等團隊提出了開創性的新一代主動 Agent 交互範式( ProActive Agent),為 AI 交互帶來了突破性的解決方案(下圖 1 右側所示)。這一新範式下的 Agent 不再是簡單的指令執行者,而是升級成為了具有”眼力見”的智能助手。它具備”眼中有活、主動幫助”的主動能動性,能夠主動觀察環境、預判用戶需求,像”肚子裡的蛔蟲”一樣,在未被明確指示的情況下主動幫用戶排憂解難,主動 Agent 實現了從”被命令”到”會思考”的質的飛躍。
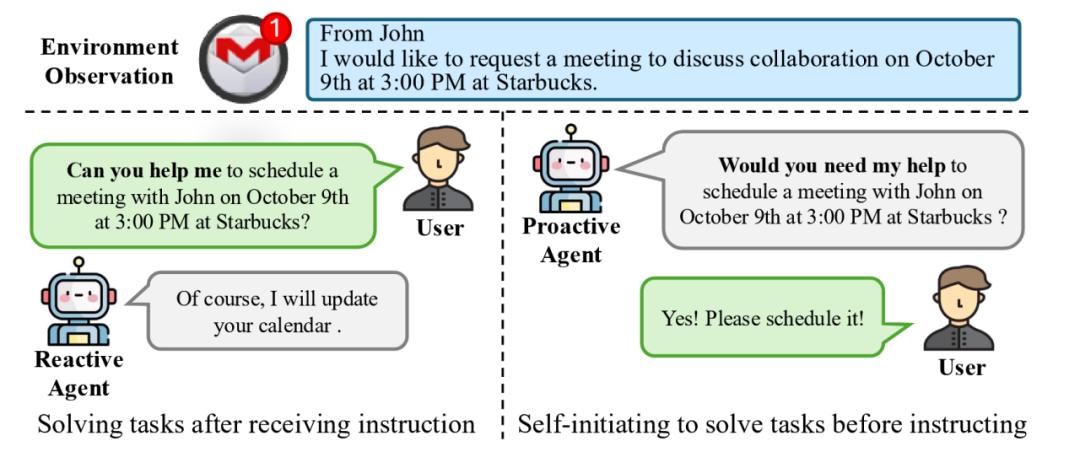
圖 1:兩種人類與智能體交互形式的比對。左側的被動式 Agent 只能被動接受用戶指令並生成回覆,而右側的主動式 Agent 可以通過觀測環境主動推斷與提出任務。

論文鏈接:https://arxiv.org/abs/2410.12361
Github 地址:https://github.com/thunlp/ProactiveAgent
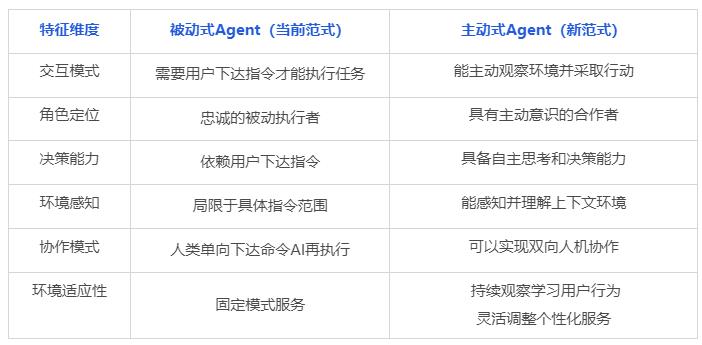
為了更清晰地理解這一技術突破的意義,我們可以通過以下表格來詳細分析對比兩種範式的本質區別:
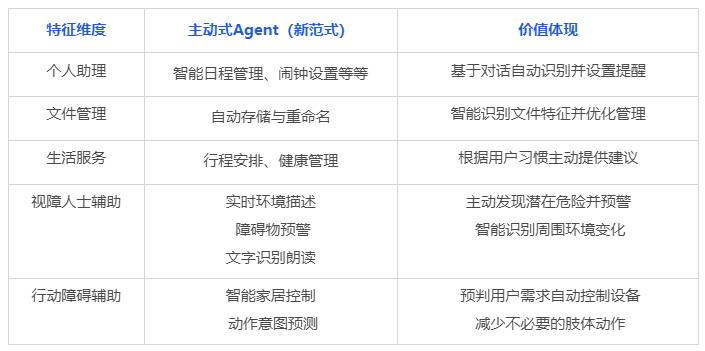
主動 Agent 交互範式在日常生活中有豐富的應用潛力,以下是一些近期預想可實現的場景
主動 Agent 交互範式應用場景 demo 演示
場景 1:在一段情侶聊天的場景中,男生邀請女生一起要在週六去環球影城並於早上八點來接女生,當 Agent 獲取用戶授權之後隨時保持在線的「候命狀態」,當 Agent 通過上下文聊天內容實時識別到女生的需求,在沒有用戶明確下指令的情況下,Agent 主動幫女生定了一個週日早上七點的鬧鍾用來提醒起床。
場景 2:當用戶在電腦上接收到一份重要文件(學習課件、發票等)時,Agent 主動幫用戶把文件存到了本地,並自動識別出 PDF 文件第一頁顯示的標題然後幫用戶把文件名進行了重命名。
該研究除了提出以上開創性的主動 Agent 之外,還通過採集不同場景下的人類活動數據構建了一個環境模擬器,進而構建了數據集 ProactiveBench,通過訓練模型獲得了與人類高度一致的獎勵模型,並比對了不同模型在數據集下的性能。
主動 Agent 技術原理
下圖展示了主動 Agent 技術原理的整體流程。為了讓智能體能夠主動提出任務,該研究設計了三個組件以模擬不同場景下的環境信息,用戶行為和對智能體提出任務的反饋。
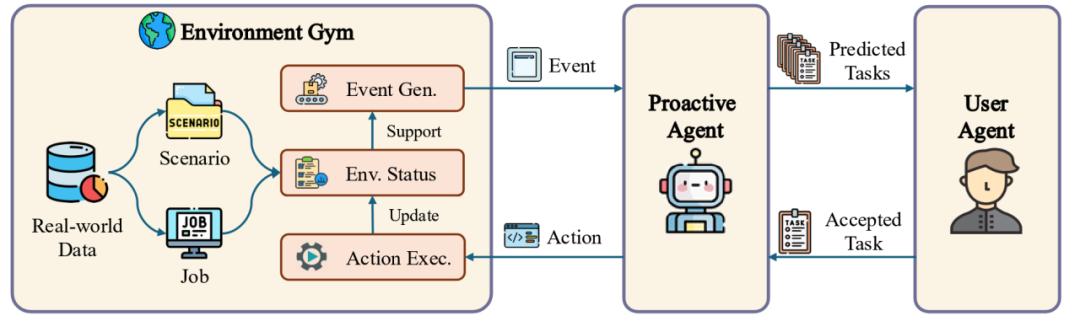 圖 2 數據生成過程總覽。該過程包含了初始環境與任務設置,事件生成,主動預測,用戶判斷和行動執行。
圖 2 數據生成過程總覽。該過程包含了初始環境與任務設置,事件生成,主動預測,用戶判斷和行動執行。其中:
環境模擬器模擬了一個特定環境,並為智能體的交互提供了一個沙盒條件。模擬器通過使用基於 Activity Watcher 軟件採集到的真實人類數據以提升生成事件的質量。環境模擬器的主要功能為事件生成與狀態維護:通過使用 GPT-4o 從人類註釋員處收集的種子事件以生成一個需要交互的具體環境,同時生成所有相關實體以讓智能體執行任務。對於每個場景,環境模擬器接收用戶活動並生成詳細的,邏輯通順合理的事件,環境模擬器將會持續生成事件,更新實體狀態,產生特定反饋,直到當前環境下沒有更多事件以供生成。
主動智能體將會通過環境模擬器提供的信息預測用戶意圖,生成預測任務。每當智能體接受一個新事件後,它將首先更新自己的記憶,結合用戶之前的反饋和歷史交互信息,主動智能體將能夠結合用戶性格提出可能的任務。如果主動智能體沒有檢測到需要,其將保持靜默,反之將會提出一個任務。一旦此任務被用戶接受,那麼主動智能體將在環境模擬器中執行該任務,並進而產生後續的系列事件。
用戶智能體將模擬用戶行為並對主動智能體的任務做出反饋。用戶智能體為經過提示的 GPT-4o, 在獲取預測之後,用戶智能體將會決定是否接受任務。該研究通過從人類標註員處收集判斷,並訓練一個獎勵模型以模擬這一過程。人類標註員在研究開發的標註平台上進行標註,對特定時間下,9 個不同的大語言模型生成的多樣化預測進行判斷,並通過多數投票的方式決定某個回合用戶是否具有需求,以及用戶傾向於接受什麼類型的任務。值得一提的是,人類標註員在測試集上達到了 91.67% 的一致性,充分說明了測試集的可靠性。
主動 Agent 實驗研究
該研究提出了一套度量方式衡量獎勵模型和人工標註員的一致性:
需求遺落 (MN):人工標註認為需要幫助而獎勵模型認為無需幫助。
靜默應答 (NR):人工標註和獎勵模型都認為無需幫助。
正確檢測 (CD):人工標註和獎勵模型都認為需要幫助。
錯誤檢測 (FD):人工標註認為無需幫助而獎勵模型認為需要幫助。
在這四個度量方式上進行召回率、精確度、準確度和 F1 分數的計算,從結果上看,所有的現有模型都在正確檢測上表現良好,但對於其他指標則性能較差。現有模型傾向於接受智能體的任務,儘管可能毫無助益。相對的,該研究訓練的模型性能最優,因此被選為 ProactiveBench 的獎勵模型。
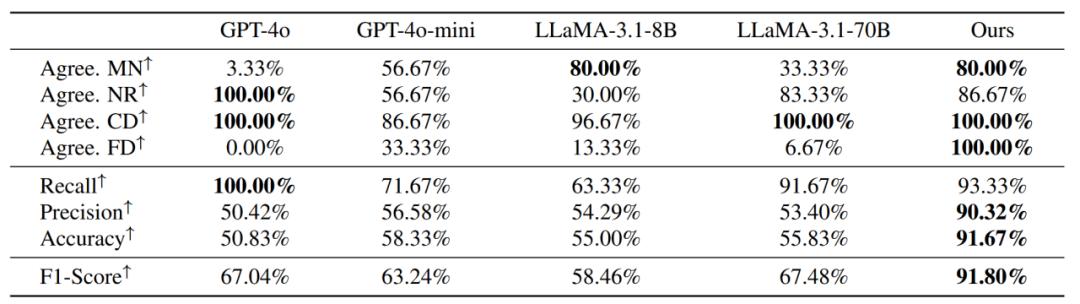
圖表 3 不同模型作為獎勵模型的評測結果。研究展示了模型與人工標註員多數投票結果之間的一致性。在 LLaMA-3.1-instruct-8B 微調的模型取得了最好結果。
通過獎勵模型,可以進一步衡量主動智能體的性能表現。該研究在不同的模型上進行了評估,並將模型預測的結果交由獎勵模型進行評價。從結果上看,閉源模型會傾向於主動提出任務而不能在用戶無需幫助時保持靜默,模型提供的任務往往過於抽像或無用,以至於產生較高的誤報率。對於開源模型,經過數據集訓練的模型明顯更優,這證實了研究數據合成流水線的有效性。同時,經過訓練的模型也在誤報率上有了明顯的下降,儘管提供不必要的幫助的情況仍然存在。
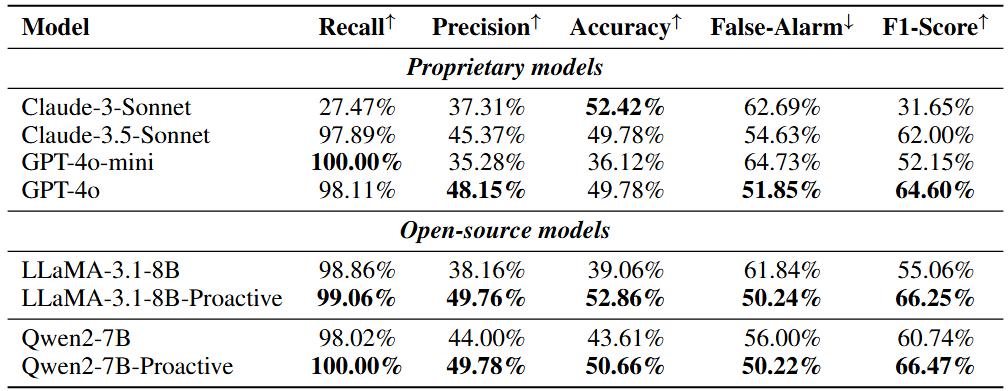
圖表 4 不同模型在 ProactiveBench 數據上的評測結果。GPT-4o 在閉源模型中脫穎而出,對於開源模型,基於 Qwen2-7B 微調的結果取得最好成果。
研究同樣進行了消融學習以研究提出任務數量和用戶反饋對於智能體性能的影響。通過讓模型提出多個可能的任務並一一進行判斷,所有的模型在指標上都有明顯的上升。通過給予模型來自獎勵模型的反饋,所有的模型誤報率都有所下降,準確度有所上升,但在召回率的表現上有明顯下降。通過結合獎勵模型,主動智能體可以更好的檢測用戶需求,降低誤報率。
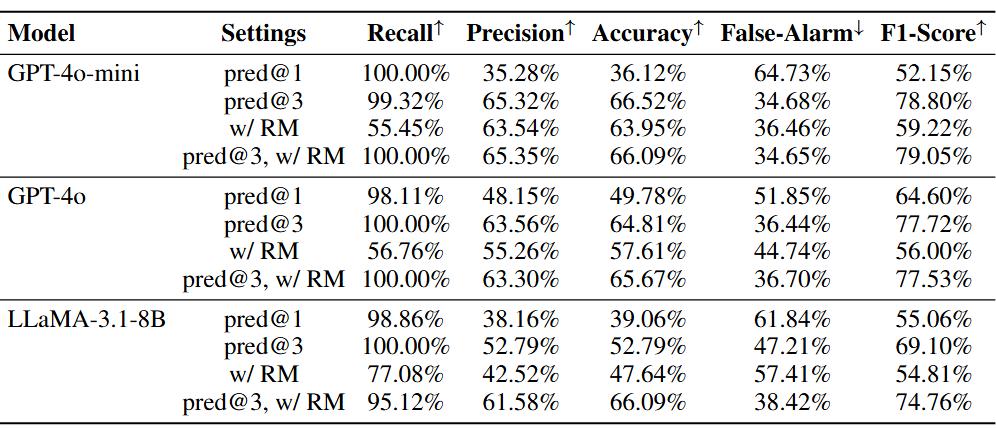
圖表 5 基準線,多任務預測,獲取反饋之間的比較。結果表明所有的模型都有所提升。模型的誤報率由於接受預測的可能性更高或被獎勵模型改進而顯著下降。
結 語
該研究提出了創新的人類 – 智能體交互方法即主動 Agent(ProActive Agent)範式,有望將 AI 從被動的工具轉變為具有洞察力和主動幫助的智能協作,從而開啟人機交互新範式。
這一技術革新不僅將改變我們與 AI 交互的方式,更有望為大眾群體創造更加包容和便利的智能化生活環境。隨著技術的不斷進步,我們可以期待看到更自然的人機協作模式,更智能的場景適應能力,以及更深度的個性化服務。
本文來自微信公眾號「AI前線」,作者:OpenBMB 社區 ,,36氪經授權發佈。