寫給小白的大模型應用科普:RAG 篇 | 留言贈書
前面小棗君給大家普及了大模型的基礎,但是缺乏應用的大模型是沒有價值的。當然你可能使用過Kimi Chat、豆包這樣的大模型工具,它們可能已經在生活中充當了我們的創作助手、諮詢專家、甚至情感陪護等,但這樣的應用還遠遠不能發揮出大模型的真正價值,我們期望大模型在更專業的生產領域發揮作用,提升生產力,引領真正的科技變革。
當前大模型被普遍看好的兩個專業應用方向是RAG(Retrieval-Augmented Agenerated,檢索增強生成)與Agent(AI智能體)。本篇小棗君首先嘗試用通俗易懂的語言幫助大家認識RAG這一重要應用形式。

01
瞭解大模型的「幻覺」
在瞭解為什麼出現RAG之前,我們首先需要瞭解大模型著名的「幻覺」問題。
「幻覺」指的是大模型在試圖生成內容或回答問題時,輸出的結果不完全正確甚至錯誤,即通常所說的「一本正經地胡說八道」。這種「幻覺」可以體現為對事實的錯誤陳述與編造、錯誤的複雜推理或者在複雜語境下處理能力不足等。其主要原因來自於:
(1)訓練知識存在偏差:老師教錯了,學生自然對不了。
在訓練大模型時輸入的海量知識可能包含錯誤、過時,甚至帶有偏見的信息。這些信息在被大模型學習後,就可能在未來的輸出中被重現。
(2)過度泛化地推理:自作聰明,以偏概全了。
大模型嘗試通過大量的語料來學習人類語言的普遍規律與模式,這可能導致「過度泛化」的現象,即把普通的模式推理用到某些特定場景,就會產生不準確的輸出。
(3)理解存在局限性:死記硬背,加上問題太難了。
大模型並沒有真正「理解」訓練知識的深層含義,也不具備人類普遍的常識與經驗,因此可能會在一些需要深入理解與複雜推理的任務中出錯。
(4)缺乏特定領域的知識:沒學過,瞎編個答案蒙一下。
通用大模型就像一個掌握了大量人類通用知識且具備超強記憶與推理能力的優秀學生,但可能不是某個垂直領域的專家(比如醫學或者法律專家)。當面臨一些複雜度較高的領域性問題或私有知識相關的問題時(比如介紹企業的某個新產品),它就可能會編造信息並將其輸出。
當然,除了「幻覺」問題,大模型還存在知識落後、輸出難以解釋、輸出不確定等一些問題。這也決定了大模型在大規模商業生產應用中會面臨著挑戰:很多時候我們不僅需要理解力和創造力,還需要極高的準確性(不僅要會寫作文,還要會準確解答數學題)。
02
RAG如何優化「幻覺」問題
RAG,正是為了儘可能地解決大模型在實際應用中面臨的一些問題,特別是「幻覺」問題而誕生的,也是最重要的一種優化方案。其基本思想可以簡單表述如下:
將傳統的生成式大模型與實時信息檢索技術相結合,為大模型補充來自外部的相關數據與上下文,以幫助大模型生成更豐富、更準確、更可靠的內容。這允許大模型在生成內容時可以依賴實時與個性化的數據和知識,而不只是依賴訓練知識。簡單的說:RAG給大模型增加了一個可以快速查找的知識外掛。
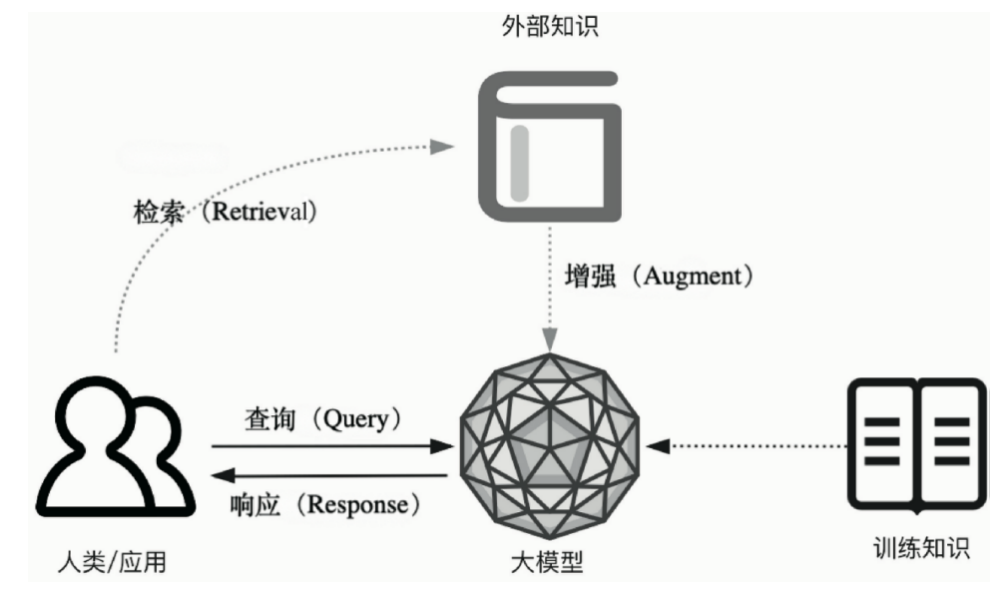
用一個例子幫助理解RAG的概念:
如果把大模型比喻成一個經過大量知識與技能訓練的優秀學生,把大模型響應的過程比喻成考試,那麼這個優秀學生在考試時仍然可能會遇到沒有掌握的知識,從而編造答案(幻覺)。
RAG就是在這個學生考試時臨時給他的一本參考書。我們可以要求他在考試時儘量參考這本書作答,那麼在遇到與這本書中的知識相關的問題時,他的得分是不是就高多了呢?
03
模擬簡單的RAG場景
假如你需要開發一個在線的自助產品諮詢工具,允許客戶使用自然語言進行交互式的產品問答,比如「請介紹一下您公司這款產品與××產品的不同之處」。為了讓客戶有更好的體驗,你決定使用大模型來構造這樣的諮詢功能並將其嵌入公司的官方網站。如果你直接使用通用大模型,那麼結果很可能如圖1-10所示。
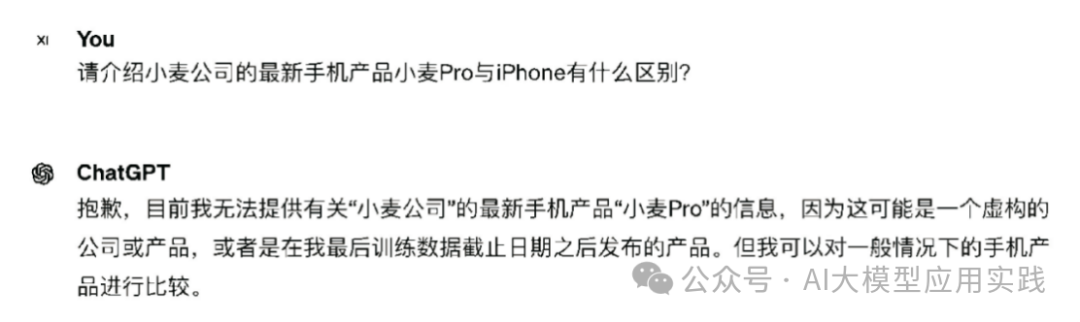
不出意外,大模型顯然不具備貴公司的最新手機產品知識,因此無法回答客戶的問題(有時候可能會嘗試編造答案)。現在,如果你使用RAG的思想,那麼可以先從企業私有的知識庫中檢索出下面一段相關的補充知識。

你把檢索出的補充知識組裝到提示詞中,將其輸入大模型,並要求大模型基於提供的知識來回答你的問題。大模型很聰明地「吸收」了補充的外部知識,並結合自己已經掌握的知識,成功推理並給出了答案:

是的,RAG本質上就是一種借助「外掛」的提示工程,但絕不僅限於此。因為在這裏簡化了很多細節,只是為了展示RAG最核心的思想:給大模型補充外部知識以提高輸出答案的質量。
04
RAG與模型微調
要想提高大模型在特定行業與場景中輸出的適應性與準確性,除了使用RAG,還可以使用自己的數據對大模型進行微調。簡單地說,微調就是對基礎模型在少量(相對於預訓練的數據量來說)的、已標註的數據上進行再次訓練與強化學習,以使得模型更好地適應特定的場景與下遊任務。顯然,微調是另外一種給大模型「灌輸」新知識的方法。兩者的主要差異在於:
-
RAG無需額外的訓練,隨時可以提供補充的知識,調試簡單。缺點是受到上下文空間的限制,且回答時性能略差(畢竟要現學現用)
-
微調需要專門的數據準備和訓練時間,技術要求相對較高,效果較難預測,不太適合更新頻繁的知識。好處是應用層面會更簡單
以前面的例子來說明微調和RAG的區別:
如果大模型是一個優秀學生,正在參加一門考試,但是這門考試中有很多知識是這位學生沒有學習過的,現在使用RAG和微調兩種方法對這位學生提供幫助。
* RAG:在考試時給他提供某個領域的參考書,要求他現學現用,自己翻書理解後給出答案。
* 模型微調:在考試前一天對他進行突擊輔導,使他掌握了新的領域知識,然後讓他參加考試。
無法確切地說在什麼場景中必須使用RAG、在什麼場景中必須使用微調。結合當前的一些研究及普遍的測試結果,可以認為在以下場景中更適合考慮微調的方案(在不考慮成本的前提下):
(1)需要注入較大數據量且相對穩定、迭代週期較長的領域知識;需要形成一個相對通用的領域大模型用於對外服務或者運營。
(2)執行需要極高準確率的部分關鍵任務,且其他手段無法滿足要求,此時需要通過高效微調甚至全量微調來提高對這些任務的輸出精度,比如醫療診斷。
(3)在採用提示工程、RAG等技術後,無法達到需要的指令理解準確、輸出穩定或其他業務目標。
在除此之外的很多場景中,可以優先考慮使用RAG來增強大模型生成。當然,在實際條件允許的前提下,兩者的融合應用或許是未來更佳的選擇。
05
初步認識RAG架構
最後,我們從技術層來看一個最基礎、最常見的RAG應用的邏輯架構與流程。
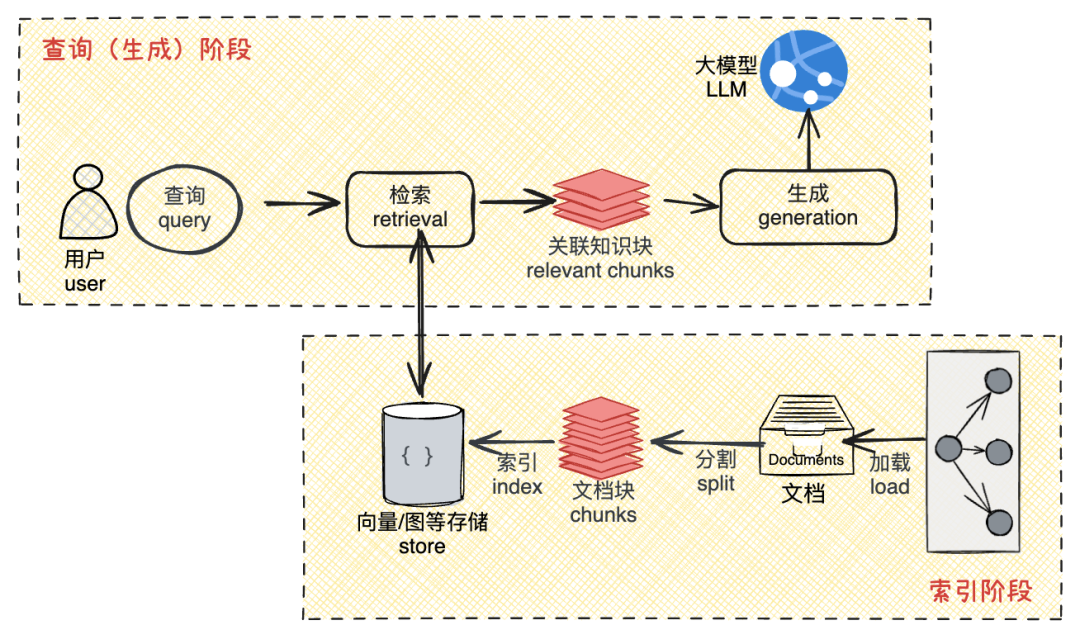
注意:在這張圖中僅展示了一個最小粒度的RAG應用的基礎原理。通常情況下,可以把一個簡單的RAG應用從整體上分為數據索引(Indexing)與數據查詢(Query)兩個大的階段,而在每個階段都包含不同的處理環節。以上面的舉例來解釋:
-
索引階段就是編寫考試時需要的參考書,這本書要容易快速查找特定知識。
-
查詢階段就是考試時使用這本書的過程,先查找參考資料,然後解答問題。
在實際RAG應用中,對於不同的應用場景、客觀條件、工程要求,會有更多的模塊、架構與流程的優化設計,以應對眾多的技術細節與挑戰。比如,自然語言表達的輸入問題可能千變萬化,你從哪裡檢索對應的外部知識?你需要用怎樣的索引來查詢外部知識?你怎樣確保補充的外部知識是回答這個問題最需要的呢?就像上面例子中的學生,如果考試的知識點是英語語法,你卻給他一本《微積分》,那顯然是於事無補的。
諸如這一類的問題都屬於更深入的高級RAG模塊與優化的範疇,感興趣的同學可以自行學習,這裏我們推薦一本非常全面的RAG應用的學習書籍:
福利來了
關於大模型、RAG你有什麼看法或者理解?歡迎在評論區留言,我將挑選留言點讚最高的4位讀者贈送這本《基於大模型的RAG應用開發與優化》,到12月3日中午12:00截止。