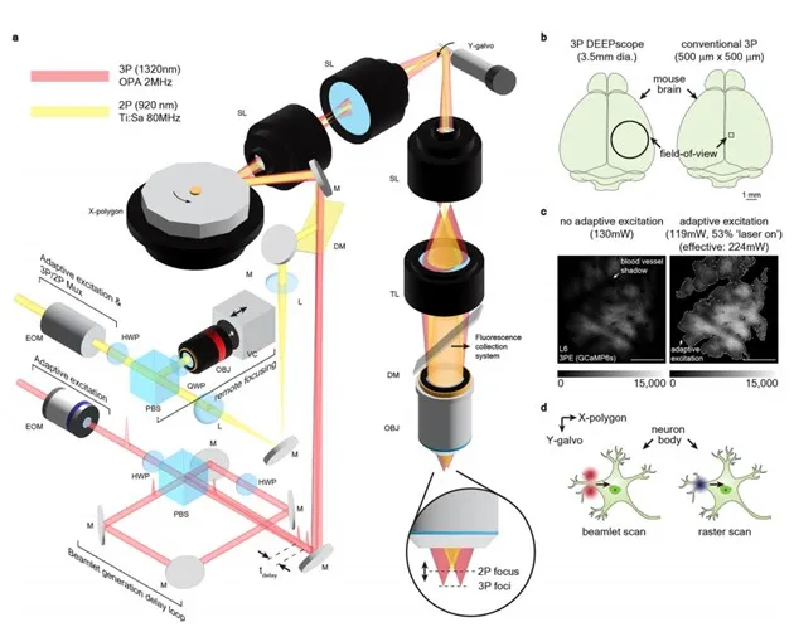
我從頂級的提示詞工程團隊那裡學到了什麼?
我有一個很好的學習習慣,養成好多年了,它也讓我受益好多年。這個習慣叫「追本溯源」。
所謂「追本」就是追問本質。為什麼要追問?因為問題是思考的起點。為什麼要追問本質?因為枝葉都是表象,知識在接近根的地方相連通。
所謂「溯源」就是回溯源頭。為什麼要溯源?因為信息在傳播過程中會有損失,會損失準確性、完整性。「溯源」這個能力在我們當下這個糟糕的信息環境中變得尤為重要。你可以環顧一下你所處的媒體環境,檢視一下你的各種信息源,其中能做到本本分分轉述信息的媒體已經是鳳毛麟角了。誇大、扭曲是媒體的常態,更惡劣者還會在信息中投毒。長期通過這種媒體接收信息,腦子會壞掉的。
如何在提示詞里控制任務流程?
Anthropic 官方有一個提示詞工程指南[1],如果你還沒有任何提示詞編程的基礎,可以看一下。
最起碼,要掌握這三個最基本的提示詞策略:
1. 使用例子[2]
2. 讓模型思考[3]
3. 設定系統角色[4]
在第 2 篇教程中,Anthropic 團隊分享了三種控制任務流程的方法:
第一種就是最簡單的「Think step by step」,大家應該都會用了。
第二種就是我們在提示詞中製定好思考步驟,第一步幹嘛,第二步幹嘛,第三步幹嘛……這種方法相比於第一種方法會更可控,同時也更加局限,因為它限制了大模型做其他探索的可能。
第三種方法,比較有意思。你可以用
Think step by step
我最近寫提示詞有一個感受:「Think step by step」 這句提示詞的價值被低估了(至少被我低估了)。這是一句元提示詞(meta prompt),這類提示詞的強大首先在於它的通用性,它並不局限於某一類具體問題。使用這類提示詞不是為了「教」 大語言模型解決某個具體問題,而是為了「教」大語言模型如何思考。
「Think step by step」 這句提示詞會引導大模型去定位到合適當前任務的流程性知識,然後應用它。所以這句提示詞有效需要一個前提,就是在大模型的訓練語料中一定是有「一步一步思考」相關的例子。在意識到「一步一步思考」的重要性之後,各大模型廠商在訓練模型的時候,必然會增加流程性知識語料。目前做得最極致的就是 OpenAI 的 o1 系列模型,OpenAI 想要把這種「一步一步思考」的能力內化到模型內部。
也就是說,我們目前接觸的大部分模型,除了具有豐富的事實性知識(是什麼)以外,它們的程序性知識(怎麼做)也被豐富了,甚至說策略性知識(在什麼情況下應用什麼知識)也被增強了。因此我們在寫提示詞的時候,要盡一切可能利用好大模型的這個能力。
Think before acting
第三種任務流程控制方法乍看上去很簡單,好像沒什麼稀奇的。但我個人認為,它是一個比思維鏈(CoT)更通用、更實用、也更重要的提示詞技巧。它是在讓大模型踐行一條更一般性的認知原則:思而後行(think-before-acting)。
如果你不顯式地讓大模型思而後行,它會傾向於先直接給出答案,然後再給出理由(合理化)。它給出的答案可以看作是一種「快思考」的結果,也就是我們常說的「沒過腦子」。
Anthropic 團隊為我們提供了一個非常好的應用示例,而且是應用在一個非常重要的場景中——Claude 的 Artifacts 功能。在 Claude 的系統提示詞[6]中有這樣一段:
…
1. Immediately before invoking an artifact, think for one sentence in tags about how it evaluates against the criteria for a good and bad artifact. Consider if the content would work just fine without an artifact. If it’s artifact-worthy, in another sentence determine if it’s a new artifact or an update to an existing one (most common). For updates, reuse the prior identifier.
2. Wrap the content in opening and closing “ tags.
…
中第一條就是告訴 Claude 在調用 Artifact 能力之前,用 標籤先思考一下,然後再使用 標籤去生成 Artifact 的內容。這就是
這段提示詞中讓 Claude 思考了三件事,我覺得第二件事比較有意思。Artifact 本質上是 Claude 的一個工具(或者叫功能/能力),要讓 Claude 能熟練地「使用」這個工具就需要利用大模型的 tool use(或者叫 function calling)能力,而大模型的 tool use 能力普遍是很差的,現在也沒好到哪裡去。「Consider if the content would work just fine without an artifact」 這句提示詞的作用就是讓 Claude 在調用 Artifact 功能之前,先思考一下有沒有這個必要,以減少 false positive 情況發生的概率。
上面只是 think-before-acting 的一個應用案例,這個提示詞技巧比你想像的更加通用。在上面這個示例中, 相當於 Artifact 這個功能的一個自適應接口(adaptive interface)。你可以在工作流的任何一個重要的 Action(Function calling、大步驟、小步驟)之前加入這樣一個接口,去做一些智能適配工作。
讓大模型在
激發出大模型的最佳表現

Amanda Askell 是 Anthropic 的 AI 研究員,負責「調教「 Claude 個性和價值觀。據說她可能是 Anthropic 內部跟 Claude 聊得最多的人類。
Amanda 在與 Lex Fridman 的訪談中說道[7],一般情況下你只需要跟大模型正常交流就可以了,「只有當你真正想要搾取出模型性能的最後 2% 的潛力時,提示詞工程才變得特別重要」。但我覺得,在用大模型很好地完成日常任務與激發出大模型的最佳表現之間,好像還有一個讓人很難受的障礙需要跨越。
我有一種很深切的感受:大語言模型似乎有一股很強的奔向平庸的勢能,就像重力會將所有河流引向地心一樣。尤其是你在讓大模型完成一些創造性任務的時候,你會有很明顯的感受。比如 Amanda 提到,如果你讓 Claude 寫一首關於「太陽」的詩,Claude 生成的內容可能乍一看感覺都還不錯,但大概率你得到的就是一個平均水準的(average)東西。我有類似的體驗,所以非常能共鳴這一點。
大語言模型的這種趨向平均的特性似乎是與生俱來的局限,這是由它的自監督和自回歸的學習機制導致的:一個 token 與另一個 token 共現的頻率就是最具引導性的 KPI,那些容易「造成不和的」(divisive)token 難逃被平均化的命運。你需要通過各種提示詞手段,去鼓勵大模型發揮創造性,「讓它們擺脫那種標準的、即時的反應(這種反應可能只是大多數人認為還不錯的想法的集合)」。所有創造性的工作都有這個特質,「如果你創作的作品只是為了讓儘可能多的人喜歡,可能就不會有太多真正熱愛它的人」。

從一個」平庸的初始版本」開始,嘗試改進到「偶有驚豔的表現」的版本,然後繼續迭代,期望它最終能到達一個「能持續穩定地給我驚喜」的狀態,要完成這種從平凡(vanilla)到不平凡(non-vanilla)的質變,絕對不是一件輕易的事。因為大模型天然具有趨向平庸的慣性,我甚至認為提示詞編程的最大功用和目的就是要抵抗這股平庸之勢。不過說抵抗可能不太準確,因為它很難抵抗。準確說,我們所能做的只是因勢利導,想盡辦法避開一個又一個均值化的深潭,同時期望能順帶在途中採擷一些邏輯之種、想像之花與創造之果。
挑戰艱難的任務

在另一個訪談中[8],Anthropic 的工程師 David Hershey 的這段話也引起了我的共鳴。如果你想提升提示詞編程技能,你應該去嘗試「讓模型做一些你認為它可能做不到的事情」。如果你只是想用大模型完成一些日常任務,比如寫寫郵件,其實不需要提示詞編程。
當你讓大模型去挑戰「最難的事情」的時候,你肯定就需要想盡一切辦法,做各種可能的實驗,這時候也是你經驗增長最快的時候。另外,即使你失敗了,你也能學到很多關於模型如何工作的知識,你會比其他人更理解大模型。
如果你在摸索的過程中,能持續收穫一些發現的喜悅和攻克難點的成就感,你就會獲得心流,進入一種深度投入的(deeply engaged)狀態。這種體驗是你在用大模型完成簡單任務的時候不可能獲得的。
追求極致的清晰

Amanda 是學哲學的,她的哲學寫作經驗為她寫提示詞帶來很大幫助。Amanda 講到,寫提示詞和寫哲學文章類似,都是要遵循同樣的原則:追求極致的清晰(desire for extreme clarity)。你可以想像你的讀者是一位受過教育的門外漢(educated layperson),TA 並不熟悉你要講的話題,但 TA 也不是傻瓜,TA 有智力,有知識儲備,而你要做的就是把你腦袋里的想法、那些複雜的概念,以極致清晰的方式傳遞給讀者。無論這個「讀者」是人還是大模型,這條經驗都同樣適用。
為什麼要追求極致的清晰?道理很容易理解,因為寫提示詞實際上就是在跟大模型交流,所以把意思傳達清楚是第一要義。
雖然交流看似只是一個外化的過程,但要清晰地表達,前提是表達者要有清晰的內在思考。要讓大模型理解你的意圖,首先你自己要明確你想要什麼。當你理清了自己的想法,任務就已經完成了一半。
壓縮還不夠,還需要展開
AI 領域有一個說法:壓縮即智能。
的確,壓縮是智能的一個核心特徵。對於人類智能來講,壓縮是發生在經驗內化以及內在思考的過程中。如前文所述,清晰的表達依賴於清晰的內在思考。清晰的內在思考會表現出壓縮的特性,比如更精準的概念使用。但是要注意,這些內在思考都是屬於你個人的,別人不知道你想了什麼,大模型更不知道你想了什麼。
前文也講過,編寫提示詞實際上是一個跟大模型交流的過程。在你跟人的交流過程中,對方可以通過內在思考來理解你所說的內容,這個過程可以看作是一個意義展開的過程。
但是,大模型沒有內在思考,你必須讓它輸出 token 才能模擬人的內在思考。在 Anthropic 的官方提示詞教程中[3]清楚地寫著這樣一條提示:「始終讓 Claude 輸出它的思考過程。如果不輸出思考過程,就等於沒有思考!」
從這個視角看,第一部分講到的「think step by step」、「think-before-action」這些提示詞技巧,都是在引導大模型做展開。你可以讓大模型自主展開,也可以控制它的展開過程。重要的是要展開,要顯式地展開,要高質量地展開。
提示詞編程是工程?是藝術?是巫術?
一個計算過程確實很像一種神靈的巫術,它看不見也摸不到,根本就不是由物質組成的。然而它卻又是非常真實的,可以完成某些智力性的工作。它可以回答提問,可以通過在銀行里支付現金或者在工廠里操縱機器人等等方式影響這個世界。我們用於指揮這種過程的程序就像是巫師的咒語,它們是用一些詭秘而深奧的程序設計語言,通過符號表達式的形式精心編排而成,它們描述了我們希望相應的計算過程去完成的工作。
——計算機程序的構造和解釋(第2版)
SICP[9] 的作者把計算機程序比喻成「巫師的咒語」(sorcerer’s spells),這些咒語是由「詭秘而深奧」的編程語言(programming languages)編排而成。巫師通過這些咒語可以喚起寄宿在計算機內的靈能(spirit)——計算過程(computational process),從而利用這種靈能去完成一些智力性的工作或者影響改造這個世界。我們知道這是一種比喻修辭。實際上計算機程序沒那麼神秘,理論上它的構造和執行過程是完全可解釋的。
或許「巫師的咒語」用來比喻提示詞更合適?因為大語言模型內部的計算過程神秘而充滿未知,而且我們不知道它還有哪些潛在的靈能可以被激發出來。雖然目前在與大語言模型相關的所有領域中,從底層模型到上層應用,我們都還處於一個經驗大於科學、實踐大於理論的狀態,但是我不想把提示詞編程這件事給過分神秘化了。
提示詞編程使用的並不是另外一種神秘難懂的語言,它就是我們人類言說所使用的語言。它是可見、可聽、可感的,它可以被記錄、被閱讀、被編輯。從出生起,只要我們還活著,還在思考,我們就一直不停地在跟它打交道,我們富於經驗。它很普通,完全不神秘,但比任何咒語都強大。
我也不想把提示詞編程這件事完全理解成是一種工程技術。即使是最傳統的編程活動,也有其藝術性的部分存在。大模型充滿未知,我們需要一些更加有想像力的思維方式和不一樣的實驗風格去探索它的潛力。
如果把提示詞編程看作一種藝術,它應該是語言的藝術。按照最樸素的方式理解,大語言模型即「大」、「語言」、「模型」,它是人類利用計算機程序對人類語言現象建立起的一個模型。大語言模型最強大的地方就在於它對人類語言的駕馭,它對語言具有超高的敏感性。
語言在提示詞編程中起到了什麼作用?語言對於大模型與對人類有一個共同的關鍵作用,按照維特根史丹的說法,語言符號相當於路標,指引著大語言模型不要在關鍵路口轉錯彎兒。又或者如陳嘉映老師所言,語言作為一種道路系統,同時支持著也規範著語義的傳輸和流動。
提示詞編程會不會被幹掉?
經常碰到朋友會有這樣的疑問:等模型足夠強大了,提示詞編程會不會被幹掉?類似的問題還有:「等模型足夠強大了,Workflow 會不會被幹掉「、」等模型足夠強大了,Agent 會不會被幹掉」等等。
剛開始聽到這類問題我還會想一想。現在慢慢意識到了,我好像哪裡做得不太對:我為什麼要浪費時間去考慮這些完全沒有意義的問題?
從某種意義上講,大語言模型的誕生相當於計算機又重新被發明出來。Anthropic CEO 的這句話送給大家:

參考資料
[1]提示詞工程指南: https://docs.anthropic.com/en/docs/build-with-claude/prompt-engineering/overview
[2]使用例子: https://docs.anthropic.com/en/docs/build-with-claude/prompt-engineering/multishot-prompting
[3]讓模型思考: https://docs.anthropic.com/en/docs/build-with-claude/prompt-engineering/chain-of-thought
[4]設定系統角色: https://docs.anthropic.com/en/docs/build-with-claude/prompt-engineering/system-prompts
[5]如何在提示詞里控制任務流程: https://xiaobot.net/post/db068c8a-d3be-4152-95d0-2497d0065c0c
[6]Claude 的系統提示詞: https://gist.github.com/dedlim/6bf6d81f77c19e20cd40594aa09e3ecd
[7]Amanda 在與 Lex Fridman 的訪談中說道: https://www.youtube.com/watch?v=ugvHCXCOmm4
[8]在另一個訪談中: https://www.youtube.com/watch?v=T9aRN5JkmL8
[9]SICP: https://book.douban.com/subject/1148282/
本文來自微信公眾號:Mindstorms,作者:艾木三號