全自動組裝傢俱! 史丹福發佈IKEA Video Manuals數據集:首次實現「組裝指令」真實場景4D對齊

新智元報導
編輯:LRST 好睏
【新智元導讀】史丹福大學推出的IKEA Video Manuals數據集,通過4D對齊組裝影片和說明書,為AI理解和執行複雜空間任務提供了新的挑戰和研究基準,讓機器人或AR眼鏡指導傢俱組裝不再是夢。
隨著人工智能技術的快速發展,讓機器理解並執行複雜的空間任務成為一個重要研究方向。
在複雜的3D結構組裝中,理解和執行說明書是一個多層次的挑戰:從高層的任務規劃,到中層的視覺對應,再到底層的動作執行,每一步都需要精確的空間理解能力。
史丹福Vision Lab最新推出的IKEA Video Manuals數據集,首次實現了組裝指令在真實場景中的4D對齊,為研究這一複雜問題提供了重要基準。

論文地址:https://arxiv.org/pdf/2411.11409
項目主頁:https://yunongliu1.github.io/ikea-video-manual/
開源代碼: https://github.com/yunongLiu1/IKEA-Manuals-at-Work
合作者指出了這項工作在空間智能研究中的重要地位:「這項工作將組裝規劃從2D推進到3D空間,通過理解底層視覺細節(如部件如何連接),解決了空間智能研究中的一個主要瓶頸。這是首個全面評估模型在真實場景中對精細3D細節理解能力的基準。」

知名科技博主、前微軟策略研究者Robert Scoble:「有了這項工作,機器人將能夠自主組裝IKEA傢俱,或者通過AI驅動的AR眼鏡。」


突破性的多模態對齊
組裝一件IKEA傢俱需要理解多種形式的指令:說明書提供了任務的整體分解和關鍵步驟;影片展示了詳細的組裝過程;而3D模型則定義了部件之間的精確空間關係。
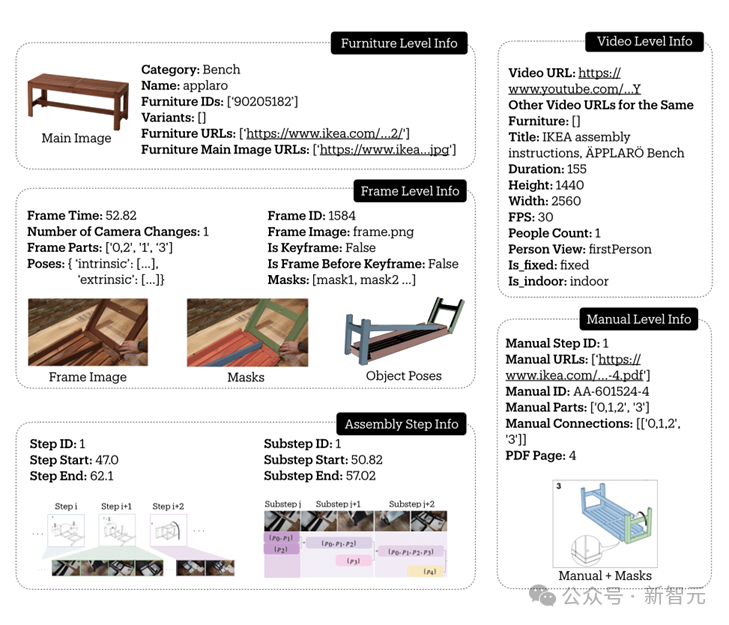
IKEA Video Manuals首次將這三種模態進行了細粒度的對齊:
-
137個手冊步驟被根據安裝影片細分為1120個具體子步驟,捕捉了完整的組裝過程;
-
通過6D Pose追蹤,精確記錄每個部件的空間軌跡;
-
在影片幀、傢俱組裝說明書和3D模型之間建立密集對應關係。

豐富的傢俱類型與場景
數據集涵蓋了6大類36種IKEA傢俱,從簡單的凳子到複雜的櫃子,呈現了不同難度的組裝任務。每種傢俱都包含完整的3D模型、組裝說明書和實際組裝影片。

這些影片來自90多個不同的環境,包括室內外場景、不同光照條件,真實反映了傢俱組裝的多樣性。

真實世界的複雜性
與在實驗室環境下採集的數據相比,來自互聯網的真實影片呈現了更豐富的挑戰:
-
部件經常被手或其他物體遮擋
-
相似部件識別(想像一下四條一模一樣的桌子腿!)
-
攝像機頻繁移動、變焦,帶來參數估計的困難
-
室內外場景、不同光照條件下的多樣性
這些真實場景下的複雜性,讓數據集更能反映實際應用中的難點。

有趣的是,研究團隊發現25%的傢俱存在多種有效的組裝順序。比如Laiva架子就有8種不同的組裝方式!這種多樣性真實地反映了現實世界中組裝任務的靈活性。
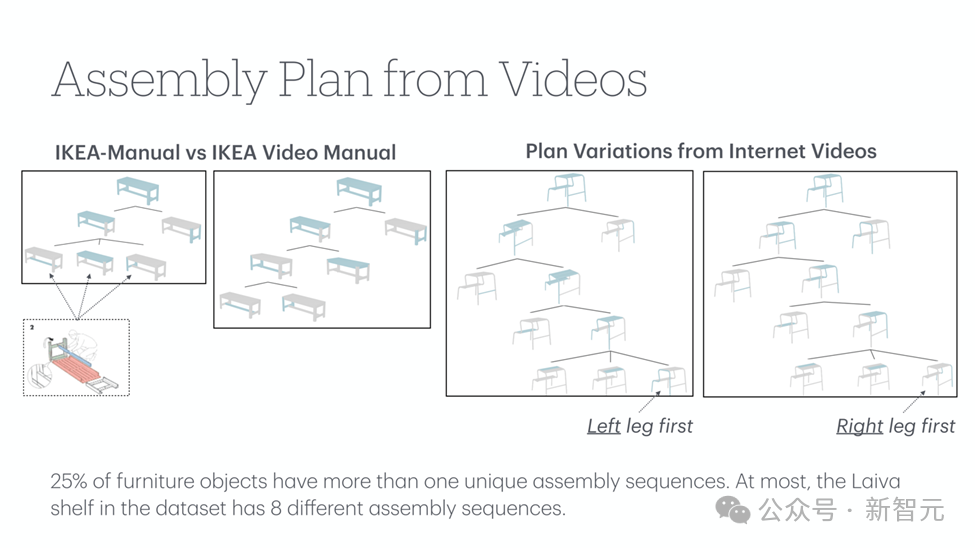
系統的標註流程
為了獲得高質量的標註, 應對真實影片帶來的挑戰,研究團隊建立了一套可靠的標註系統:
-
識別並標註相機參數變化的關鍵幀,確保片段內的一致性
-
結合2D-3D對應點和RANSAC算法進行相機參數估計
-
通過多視角驗證和時序約束保證標註質量

核心任務實驗評估
基於IKEA Video Manuals數據集,團隊設計了多個核心任務來評估當前AI系統在理解和執行傢俱組裝,以及空間推理(spatial reasoning)方面的能力:
1. 在基於3D模型的分割(Segmentation)與姿態估計 (Pose Estimation)
輸入3D模型和影片幀,要求AI完成兩個任務:準確分割出特定部件區域,並估計其在影片中的6自由度姿態。實驗測試了最新的分割模型(CNOS, SAM-6D)和姿態估計模型(MegaPose)。
基於3D模型的分割

基於3D模型的姿態估計
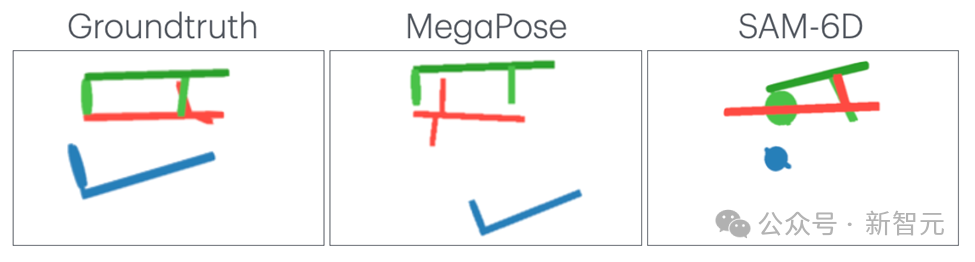
分析發現它們在以下場景表現不佳:
– 遮擋問題:手部遮擋、近距離拍攝導致部分可見、遮擋引起的深度估計誤差


– 特徵缺失:缺乏紋理的部件難以分割、對稱部件的方向難以判斷

– 特殊拍攝角度(如俯視)導致的尺度誤判

2. 影片目標分割Mask Trackin
評估了SAM2和Cutie兩個最新的影片追蹤模型。與其他基準數據集相比,它們在IKEA Video Manuals數據集上表現顯著下降:
•SAM2: 從其他數據集的85-90%降至73.6%
•Cutie: 從85-87%降至54.7%
主要挑戰包括:
– 相機運動導致目標丟失

– 難以區分外觀相似的部件(如多個相同的桌腿)

– 長時間追蹤的準確度難以保持
3. 基於影片的形狀組裝
團隊提出了一個創新的組裝系統,包含關鍵幀檢測、部件識別、姿態估計和迭代組裝四個步驟。實驗採用兩種設置:
使用GPT-4V自動檢測關鍵幀:結果不理想,Chamfer Distance達0.55,且1/3的測試影片未能完成組裝,反映GPT-4V對組裝關鍵時刻的識別能力有限;
使用人工標註的關鍵幀:即便如此,由於姿態估計模型的局限性,最終Chamfer Distance仍達0.33

這些實驗結果揭示了當前AI模型的兩個關鍵局限:
1、影片理解能力不足:當前的影片模型對時序信息的分析仍然較弱,往往停留在單幀圖像分析的層面
2、空間推理受限:在真實場景的複雜條件下(如光照變化、視角改變、部件遮擋等),現有模型的空間推理能力仍顯不足
未來展望
IKEA Video Manuals的推出,通過研究如何將組裝指令對齊到真實場景,為空間智能研究提供了一個重要的評估基準。
想像一下,未來你戴上AR眼鏡,就能看到IKEA傢俱的每個組裝步驟被清晰地投影在眼前,系統還能實時提醒你是否安裝正確;;或者,機器人能夠像人類一樣,僅通過觀看影片就學會組裝複雜的傢俱。IKEA Video Manuals的推出讓這些設想離現實更近了一步。
通過提供真實場景下的多模態數據,這個數據集為空間智能研究提供了重要的評估基準。我們期待看到更多突破性的進展,讓AI系統真正理解和執行複雜的空間任務。
作者介紹

第一作者劉雨濃,史丹福大學計算機科學碩士生,隸屬於史丹福SVL實驗室(Vision and Learning Lab),由吳佳俊教授指導。本科畢業於愛丁堡大學電子與計算機科學專業(榮譽學位)。曾在德克薩斯大學奧史甸分校從事研究實習。目前正在尋找2025年秋季入學的博士機會。

吳佳俊,史丹福大學助理教授,隸屬於SVL和SAIL實驗室。麻省理工博士,清華姚班本科。作為項目指導教授。

Juan Carlos Niebles,Salesforce AI Research研究主任,史丹福大學計算機科學系兼職教授,史丹福視覺與學習實驗室(SVL)聯合主任。在計算機視覺和機器學習領域有傑出貢獻,曾獲多項重要獎項

劉蔚宇,史丹福大學博士後研究員,在CogAI組和SVL實驗室從事研究。專注於機器人感知、建模和交互領域,致力於開發能通過簡單語言命令完成長期任務的機器人系統。作為項目共同指導。

李曼玲,西北大學計算機科學系助理教授,曾為史丹福大學博士後,現為史丹福訪問學者。研究興趣集中在語言、視覺、機器人及其社會影響等交叉領域,致力於開發可信且真實的多模態系統。
參考資料:
https://yunongliu1.github.io/ikea-video-manual/