輕量級神經網絡模型,嵌入式微小設備也能實時檢測 !
轉自 | 集智書僮

輕量級神經網絡的進步已經徹底改變了計算機視覺在各種物聯網(IoT)應用中的使用,涵蓋了遠程監控和過程自動化。
然而,對於許多這些應用來說,檢測小型物體,這是至關重要的,目前在計算機視覺研究中仍然是一個未探索的領域,尤其是在資源受限的嵌入式設備上,這些設備擁有處理器。
為瞭解決這一問題,本文提出了一種適應性的分塊方法,用於輕量級和節能的目標檢測網絡,包括YOLO基礎模型和流行的更快地找到更多物體(FOMO)網絡。
所提出的分塊方法可以在低功耗微控製器單元(MCUs)上實現目標檢測,同時與大型檢測模型相比不妥協準確性。通過將該方法應用於內置機器學習(ML)加速器的基於 RISC-V 的新型MCU上的 FOMO 和 TinyShimyOLO 網絡,證明了所提出方法的優勢。
大量的實驗結果表明,所提出的分塊方法在FOMO和TinyShimyOLO網絡上的F1分數提高了225%,同時將平均目標計數錯誤減少了76%(FOMO)和89%(TinyShimyOLO)。
此外,本工作的發現表明,在FOMO網絡中使用軟F1損失可以作為隱式非最大抑制。
為了評估實際性能,將這些網絡部署在 RISC-V 基礎的GAP9微控製器上,從 GreenWaves Technologies 公司,展示了所提出的在MCU上使用高解像度圖像進行多個預測,實現檢測性能(F1分數58%-95%)、低延遲(0.6ms/推理 – 16.2ms/推理)和節能(31µJ/推理 – 1.27mJ/推理)之間的平衡。
1 Introduction
低功耗物聯網(IoT)設備與先進傳感器以及尖端機器學習(ML)算法的整合正在推動各行業發生變革,包括健康監測[1],家居自動化[2]和工業過程優化[3]。這些邊緣計算設備通過利用設備上的ML算法,提高了數據隱私保護,增強了帶寬效率,並實現了成本降低。這些算法在本地處理隱私關鍵的感知信息,並提取元數據,然後將元數據傳輸到雲進行進一步分析或操作。對於許多場景,精確目標檢測[4, 5]是關鍵應用。目前,最先進的目標檢測器通常使用卷積神經網絡(CNN)架構來預測圖像中的物體位置和類別。值得注意的是,基於 Transformer 的網絡架構[7, 10]已經出現,並展示出在提高目標檢測系統能力方面具有巨大的潛力。
然而,這些網絡雖然具有深度上下文理解,但計算要求非常高,因此需要消耗數百瓦特功率的強效和昂貴硬件,使其不適合大多數IoT處理器。這促使學者們提出使用模型量化方法來實現移動和低功耗嵌入式設備上的微機器學習(TinyML)。雖然輕量級神經網絡的進步使得在圖像分類等任務上取得了很大的進展[11],最近開始在簡化目標檢測任務上獲得良好的檢測精度,但檢測小物體仍然是一個挑戰,尤其是在內存受限的設備上,如微控製器單元(MCUs)。這些嵌入式處理器的計算預算有限,導致一個圖像的執行延遲在幾秒鍾[21]。
檢測圖像中小目標的挑戰主要歸因於這些目標具有有限的像素覆蓋,這極大地抑制了目標檢測器生成獨特特徵的能力,這是準確識別的至關重要的一步[21]。高解像度圖像提高了信噪比,然而,具有8位顏色深度和像素解像度的RGB圖像已經超過了低功耗MCU通常可用的的閃存存儲。有限的賸餘內存限制了可以部署的模型的大小[11]。另一個因素是CNN基礎算法中的步進操作導致小目標在特徵圖中被完全消失。
這篇論文是對作者之前的工作《”增強物聯網應用中小型目標檢測的輕量級神經網絡方法”》中的方法和發現進行全面闡述和擴展。作者之前研究的核心是開發一種自適應分塊技術,如圖1所示為所提出方法的總覽,專門用於增強輕量級神經網絡的能力,例如更快地檢測更多目標(FOMO)[16],以準確識別小型目標。該技術的有效性通過在低功耗的Sony Spresense MCU平台上的實現進行實證。儘管實現了令人稱讚的檢測準確性,但該方法受到顯著的延遲懲罰。此外,作者之前的調查還揭示了FOMO物體預測能力的一種固有局限性,即分塊粒度和輸入解像度的提升在檢測性能方面不再產生成比例的改善。

在這些基礎見解的基礎上,本研究的擴展部分引入了重大進步和新的貢獻,具體體現在以下幾個方面:
增強方法論深度:本文擴展為引入了自適應鑲嵌方法[21]提供深入解釋,展示了其在顯著提高信噪比的同時,無需相應增加網絡輸入解像度的能力。
網絡修改和集成:本文詳細描述了針對原始FOMO架構所進行的修改,以及與作者的自適應拚圖方法相結合時所產生的協同效應。進行了一項消融研究,以證明它們在提高作者之前研究中所設立的 Baseline 之外的目標檢測能力方面的作用。
擴展至作者最初發佈的範圍之外,這項擴展通過以下實驗改進,拓寬了作者方法的實際驗證:
應用於TinyissimoYOLO:通過將自適應鑲嵌技術應用到TinyissimoYOLO網絡,相較於CARPK [22]數據集上的最新基準,實現了最先進的檢測準確率。這一成就證明了作者的方法在不同網絡架構下的通用性和有效性。
在GAP9上部署:FOMO和TinyissimoYOLO網絡都在GAP9微控製器(MCU)上部署,這是一種基於 RISC-V 的並行處理器,具有硬件加速器。這個平台實現了最先進的推理延遲,這是在物聯網應用中追求高效實時目標檢測的一個重要里程碑。
開源代碼1:與TinyissimoYOLO一起發佈了提出的瓷磚方法的開放式版本。(https://github.com/ETH-PBL/TinyissimoYOLO)
通過這些貢獻,本文不僅擴展了在物聯網範式下小目標檢測的理論與實踐理解,還為新發佈的低功耗MCU上神經網絡的部署設立了新的基準,從而為該領域的未來創新鋪平了道路。
2 Related Work
檢測小型物體仍然是一個研究挑戰,因為從小型物體所覆蓋的相對有限的像素中生成特徵具有固有的困難。大多數廣泛使用的目標檢測模型並未針對這一挑戰進行優化。表1 顯示了像YOLOv4 [23]和Faster R-CNN [25]這樣的流行目標檢測模型在小型物體上的表現顯著較差。這一限制部分可以歸因於網絡架構。例如,YOLO [27]使用網格方法進行預測,其中位於同一網格單元的小型物體可能不會被正確檢測。另一個問題是與用於開發這些模型的訓練數據相關。大多數目標檢測模型需要大量的訓練數據,對於只有有限數據的專用場景構成了挑戰。
因此,實踐者可能需要依賴可以針對其使用場景進行微調的預訓練模型。然而,用於預訓練模型的通用訓練數據集通常傾向於包含佔據圖像較大比例的目標[28]。因此,在主要包含小型物體的目標使用場景下,它們的可用性受到限制。

為解決這些問題,所採取的努力可以廣泛地分為兩類:
一類是試圖為給定目標提供更多的信息;
另一類是試圖在小型目標上生成更豐富的特徵。劉等人[8]的工作是利用CNN的層疊結構在多個尺度上進行預測的最早嘗試。他們在其網絡的末端添加了多個特徵層,這些特徵層的解像度逐漸減小。每個特徵層都進行自己的預測,最後,非極大值抑制步驟選擇最可能的預測。
然而,在初始特徵提取器中發生的下采樣限制了該網絡檢測小型物體的能力。這一局限性在林等人[9]的工作中得到解決,他們提出將早期層的高解像度特徵與後期層的更成熟特徵相結合。為此,他們將多個解像度下的特徵圖拚接在一起,並採用一個可以接受這種多尺度特徵向量作為輸入的單一預測器。這些發現決定了本工作的選擇,即採用TinyissimoYOLOv1.3[30],這是一個輕量級網絡,使用了YOLOv3[31]中引入的檢測Head,該檢測Head將不同尺度的特徵組合在一起。
雖然這些方法試圖通過改變網絡架構來最大化小目標特徵的表達能力,但其他研究行人試圖通過增加可用的信息量來達到這個目標。一個明顯的途徑是增加網絡的輸入解像度,這在劉等人[8]的工作中有提及。不幸的是,增加圖像解像度並非總是可行的。許多網絡具有固定的輸入大小,而增加圖像尺寸會極大地增加內存和計算負載。
Cagatay等人[32]提出了一種名為Slicing Aided Hyper Inference的框架,將圖像分割成子圖像。他們展示了如何使用這個框架來提高現成目標檢測器的推理性能,同時在使用框架微調預訓練模型時獲得更好的結果。他們的方法將輸入圖像分割成固定數量的小塊,並在後處理階段將每個塊的預測與全圖像的預測相結合。為了抵消圖像分塊引入的增加處理時間,Plastiras等人[33]提出了一種選擇性分塊方法。他們的方法為每個塊分配一個重要性分數,對於給定的迭代,只處理具有最高分數的塊。受到選擇性分塊方法啟發,之前的工作引入了一種適應性分塊方法[21],以最小化推理次數,同時優化目標大小以確保最大的檢測準確性。
CNNs的部署在MCU類設備上主要是內存約束問題,需要採用應對_量化技術_的方法[34],以降低隨機訪問內存(RAM)和閃存(FLASH)的使用,同時保持精度不變[35],_(ii)_減小網絡大小,例如FOMO方法[16]或TinyissimoYOLO[12],_(iii)_或者在執行網絡前向傳播時減少所需的RAM,例如不同版本的MCUNet[14],[15]。
例如PP-PicoDet[36]或NanoDet[37]等目標檢測模型具有前景,但它們的最小版本在1MB的FLASH上 barely fit,並且超過了MCU中通常可用的RAM。因此,這些網絡在Snapdragon類系統芯片(SoCs)上進行基準測試,這些芯片的功耗處於等待狀態。
文獻報告了一些用於MCU上的目標檢測網絡,如XiNet [13]和PhiNet [17],這些網絡優化了RAM消耗。然而,這些網絡使用了諸如注意力機制或壓縮和激勵塊等層操作,這些操作在商用的MCU內置加速器中並不常見[20]。大多數ML加速器,如實現到Marsellus SoC [38]中的可配置二進製引擎(RBE)加速器,只加速少數簡單的層操作,例如3D卷積層。利用這些加速操作,TinyissimoYOLO可以實現與最佳類模型相當的檢測精度,同時支持實時推理。
雖然邊緣設備上的目標檢測領域已經得到了一定程度的探索,尤其是在MCU的有限功耗範圍內,但是將小型目標檢測器部署在這些設備上仍然是一個相對較少研究的領域。以前的研究主要集中在為邊緣部署優化現有神經網絡架構,或者減少目標檢測算法的計算複雜性。然而,在MCU上檢測小型物體的兩倍挑戰,即需要高檢測準確率和低計算開銷,至今尚未得到全面解決。
本文做出了幾個新穎的貢獻,不僅填補了本節中描述的差距,而且在微控製器的推理速度和檢測精度方面,也突破了目前的可行性界限:
高速推理:本文擴展展示了使用FOMO網絡在低功耗MCU上實現每秒>30幀的推理速度。這一顯著成就進一步證實了作者的方法在效率方面的優勢,使其在實時應用中具有可行性,在這些應用中,快速目標檢測至關重要。
當前最先進的檢測準確率:將TinyissimoYOLO網絡部署在GAP9 MCU上,本工作實現了小目標檢測的當前最先進平均物體誤差計數。這一成就是在保持接近3 FPS的運行速度的同時實現的,這在一個資源受限的目標部署平台中是值得注意的成就。
創新解決方案:在MCU上實現小目標檢測:本文提出的該方法擴展解決了在MCU上檢測小型目標未得到解決的問題。通過優化網絡架構和推理流水線,本文擴展提出了一種可行的解決方案,該解決方案滿足了邊緣應用對高精度和低延遲的嚴格要求。
3 Method
Detection Networks
3.1.1 Fomo
恐失(Fomo)[16] 是一種輕量級的目標檢測網絡,它預測目標中心而不是邊界框。Fomo 使用 MobileNetV2 [24] 網絡的早期層作為特徵提取器,從而形成一個 的特徵網格,其中 的尺寸取決於特徵提取器的深度。在本工作中使用的 Fomo 實現具有三個下采樣階段,導致從輸入到輸出的整體下采樣因子為 8。特徵網格隨後被輸入到一個小的檢測Head中,該檢測Head通過將屬於同一目標的 特徵分類並進行聚類來預測目標中心。原始 Fomo 網絡,由 Edge Impulse 實現,使用了粗糙的聚類技術,即鄰域網格單元上的所有預測都被合併在一起。
該架構有兩個主要局限性。首先,它對每個 特徵只做出一次預測,與其他單次檢測器(如 You Only Look Once,YOLO)不同。這意味著在同一網格單元中定位的小物體將算作一次預測。其次,它無法區分相鄰網格單元中預測的附近物體,因為聚類步驟會將它們錯誤地融合在一起。
根據在FOMO應用中採用對比監測,對標準FOMO實現進行了兩項修改。由於圖像中的物體與背景的比例可能劇烈變化,因此替換了加權二進製交叉熵損失,採用了由Maiza等人引入的軟F1損失[39],無需手動調整每個目標類損失成分的權重。此外,在對比監測中,通常許多車輛都位於非常接近的位置。這使得相鄰車輛的預測很可能位於FOMO輸出的相鄰網格單元中,然後由FOMO融合機制錯誤地合併。在3.3節中,作者提出了一種最小化不同目標預測意外合併的方法。
3.1.2 TinyissimoYOLO
[21] 中的工作表明,FOMO的檢測性能在輸入解像度達到192×192時會停滯。因此,可以合理地假設FOMO的小參數數量是這一限制的原因。本工作通過研究更複雜的網絡,擴展了[21]的結果。
微小的YOLOv1.3 [30]是一種目標檢測網絡,它基於TinyissimoYOLO [12],但使用了YOLOv3的檢測Head,使其能夠基於提取的多尺度特徵預測邊界框。由於該網絡結構簡單且大量使用了3D卷積層,因此可以使用具有ML加速器的SoC進行高度加速,這一點由TinyissimoYOLO的後續出版物所證明 [20]。這種網絡預測邊界框的能力允許使用更複雜的算法來融合相鄰塊的預測,這一點將在第3.3節中詳細說明。
Adaptive Tiling
為瞭解決小型物體像素信息不足以及來自FOMO架構的目標大小限制問題,作者提出了一種自適應分塊的方法,將圖像分割成較小的子圖像。這種方法具有多個優點。首先,它增加了物體的相對大小,從而在假設輸入解像度保持不變的情況下提高了信噪比。其次,增加物體的尺寸會降低多個物體位於同一網格單元的概率,這對基於 Anchor 點目標檢測器(如FOMO和TinyissimoYOLO)非常重要。作者遵循Akyon等人[32]的工作,將圖像分割成重疊塊,確保在某一塊中僅部分可見的目標在相鄰塊中完全可見。圖2顯示了所提出的方法如何將圖像分割成較小的塊進行單獨處理。
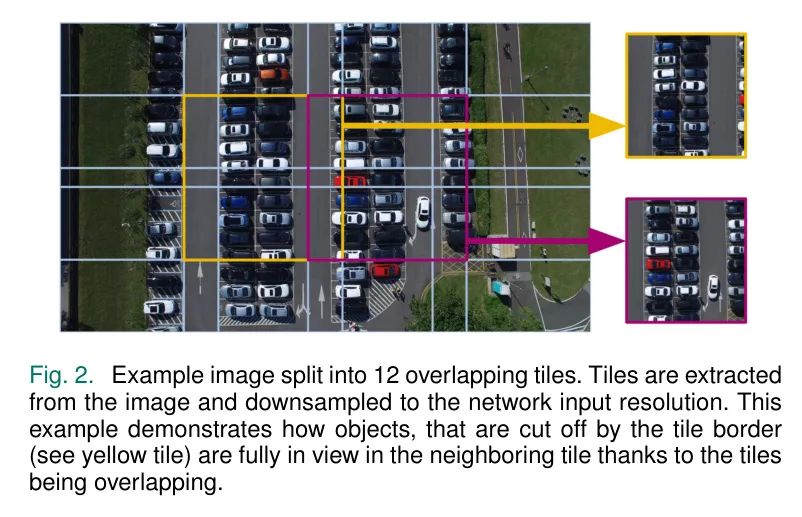
將圖像分割成瓷磚進行逐個處理的一個缺點是處理時間的增加,且物體越小,需要使用的瓷磚越多才能獲得良好的檢測結果。在這項工作中,定義了一個目標物體大小,該大小通過歸一化邊界框面積(NBA)進行量化,以調整瓷磚的數量。NBA是邊界框的像素面積,通過將像素總面積除以像素總面積進行歸一化。對於拍攝在物體附近的照片,只需要使用幾塊瓷磚就能達到目標物體大小,而對於拍攝在物體較遠位置的照片,需要使用更多的瓷磚。這樣可以在最小化需要處理瓷磚數量的同時,確保最佳可能的檢測性能。
為了確保拚貼圖像中的目標大小與目標目標大小匹配,作者為每張圖像定義了一個正方形拚貼塊。

其中 表示瓷磚的寬/高, 是平均物體大小, 是圖像中的區域(以像素為單位), 表示目標物體大小。最後,在 x 和 y 方向上的瓷磚數量選擇,使得瓷磚重疊至少為平均物體寬/高的 1.5 倍。
在訓練過程中,被標註物體的邊界框大小被用來計算最優的瓷磚尺寸。在實際應用中,例如使用GPS的高度測量,可以估算物體的尺寸。
Fusing Tiled Predictions
採用重疊的方格會導致網絡多次看到相同的圖像區域,因此網絡可能會對同一物體做出多次預測。為了確保準確的物體數量,來自多個方格的同一物體的預測必須正確融合。這通過比較所有方格預測的交集來實現,但是,實現方式會因網絡架構的差異而有所不同。
對於FOMO網絡做出的每個預測,都會創建一個「偽」邊界框,其大小等於相應的網格單元。當相鄰的瓷磚的交並比(IoU)大於特定閾值時,這些網格單元大小的邊界框預測會被融合在一起。
微小的YOLO(TinyissimoYOLO)也以網格形式進行預測,但並非預測質心位置,而是預測每個 Anchor 點對應的邊界框。人們仍然可以使用IoU指標來確定重疊預測之間的對應關係,然而,當物體在一個瓷磚中只部分可見,而在另一個瓷磚中完全可見時,同一物體的邊界框將具有非常不同的尺寸。如圖3所示的一個例子可以說明這一點。這個例子表明,即使一個瓷磚的邊界框完全重疊於另一個瓷磚中的第二個邊界框,IoU也可以很小。這使得在確保同一物體預測融合正確的同時,難以找到一個閾值,以防止附近物體意外融合。

為瞭解決這個問題,作者採用了一種稍微不同的匹配方法。作者不再基於IoU進行雙向匹配,而是使用作者稱之為「交點比率」的一向匹配。這個比率對於每個邊界框是通過將其交點區域除以另一個邊界框的面積來確定的。這種指標的優點是,幾乎完全被另一個邊界框包圍的邊界框,其交點比率將接近1。
如果至少有一個邊界框的交點比率大於閾值,那麼這對邊界框就被認為是匹配的。如圖3所示,黃色方塊只能部分看到物體,因此預測的邊界框比紫色方塊小,導致IoU小於50%。另一方面,黃色方塊的預測交點比率為98%,因此在使用作者的單向匹配時,這兩個預測可以被認為是高置信度的匹配。
IV Results
作者評估了標準FOMO實現[16]、作者的FOMO實現[12]以及TinyissimoYOLO [12]在CARPK [22]數據集上的檢測性能。
該數據集由無人機在約40米高度飛行,覆蓋了四個不同停車場的近1,500張圖像,其中包含超過90,000輛汽車。
Experimental Settings
除了將提出的方法與其他在CARPK[22]數據集上的工作進行比較外,作者還評估了由作者提出的瓦片方法的不同配置所帶來的小型目標檢測性能提升。具體而言,作者用三種不同的輸入解像度以及四個不同的目標NBA值訓練FOMO模型,同時用一個輸入解像度訓練TinyissimoYOLOv1.3,並用四個更大的目標NBA值訓練。在本論文中,作者使用配備了9個 RISC-V 核心的GAP9 MCU進行部署和評估。調查的模型通過使用NNTool2將其量化到Int8精度。NNTool用於優化計算圖,進行量化並驗證拓撲結構。
使用Autotiler3根據拓撲優化和量化圖自動生成C代碼。生成的代碼用於在設備上執行量化網絡。延遲和能量測量通過在GAP9評估套件上部署網絡並利用 Nordic Semiconductor 的 Power Profiler Kit 2 進行。將模型部署到GAP9使作者能夠觀察到提出的瓦片方法以及不同的輸入解像度如何影響到網絡的目標物體大小,從而影響檢測性能和內存消耗以及延遲。
部署的網絡通過參數數量、延遲和推理效率(這描述了設備上計算工作負載的並行化程度)以及根據Giordano等人[40]的建議的每推理能量進行評估和比較。
Fomo
在表2中,作者將使用作者開發的拚圖方法在CARPK數據集上與標準FOMO實現以及其他已發佈的結果進行了比較。與原始FOMO架構相比,作者的方法在物體計數誤差方面減少了76%,F1得分提高了225%。
YOLO的平均平均誤差(MAE)來自[22],YOLOv4的值來自[41]。對於YOLO和YOLOv4,作者分別根據[27]和[23]中的實現估計了參數數量。與YOLO[27]相比,作者的FOMO實現(帶有拚圖)減少了MAE的74%,而YOLOv4[23]實現了85%的減少。然而,YOLO和YOLOv4都不是為MCU設計的,並且不符合大多數低功耗嵌入式設備的內存要求。這清楚地體現在表2中,當比較模型參數數量時。

4.2.1 On Device Performance
在圖5中,作者展示了不同配置下作者方法的目標F1指標和設備端延遲。從圖5中的數據可以看出,無論是增加目標NBA(即使用更多瓷磚),還是使用更高的輸入解像度,都可以顯著提高F1指標。檢測性能的明顯改善表明,小型目標檢測中的主要障礙確實是小型物體可用的信息相對較少。
這些結果表明,當增加輸入解像度不是選項(因為受內存限制)時,所提出的瓷磚方法是一種有效的替代方法,可以提高小型物體的信噪比,從而提高檢測性能。作者還可以在這些結果中看到瓷磚方法帶來的額外延遲。例如,達到目標NBA的0.8%需要比目標NBA的0.2%多3.66倍的瓷磚,這導致在網絡輸入解像度為192×192的全圖像處理過程中,延遲從8.0ms增加到30.0ms。

TinyissimoYOLO
如圖5所示,本擴展的前期工作以及可以看到,FOMO的檢測性能在目標NBA為0.8%,輸入解像度為192×192時停滯不前。這種停滯可以歸因於FOMO網絡中參數數量極低,限制了其預測能力。因此,作者進行了使用TinyissimoYOLOv1.3 [30]網絡與作者的瓷磚方法相結合的實驗。這個網絡比之前的大得多,因此可以進行邊界框預測,而不僅僅是預測質心。
在表4中,作者報告了將Tiling方法與TinyissimoYOLOv1.3結合使用時,針對不同目標物體大小的結果。使用目標NBA為0.8%,即在精確率和召回率為93%和46%時,性能達到停滯,此時目標計數誤差為53.6,明顯優於FOMO的性能。然而,與FOMO不同,將目標物體大小增加至0.8%以上,將帶來顯著的改進。
當目標NBA為4%時,最佳FOMO模型的F1得分與匹配,同時實現了目標計數誤差為6.2,相較於作者最佳FOMO網絡實現了52%的降低。這甚至超過了大規模模型如YOLOv4 [23]的表現,如表2所示。
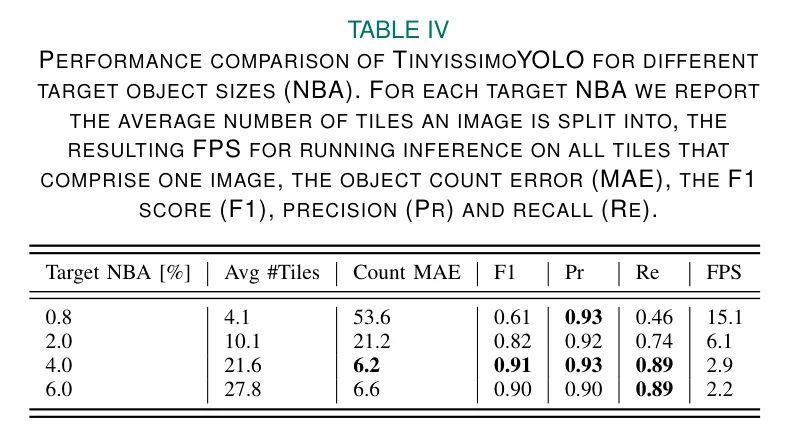
表4的最後一行說明了使用目標NBA為6%時獲得的檢測結果,除召回外,所有指標均略有下降。當目標NBA為6%時,圖像平均分為近30個塊,導致許多汽車被多個塊邊界吸引,從而降低了檢測性能。因此,作者認為這代表了在將物體尺寸增加的好處與被塊邊界交叉的許多物體相抵消時的實際極限。
Iii-C1 On Device Performance
通過在GAP9的NE16加速器上部署Int8量化FOMO網絡和TinyissimoYOLO,實現了實時推理。圖6比較了部署網絡在III節描述的指標方面的差異。在圖6a)中可以看出,與實現的FOMO網絡相比,TinyissimoYOLO大約大21倍。然而,GAP9將TinyissimoYOLOv1.3的工作負載並行化5倍優於FOMO的工作負載,參見圖6c),導致比FOMO大21倍的網絡執行時間增加了2.2倍。這種差異可以解釋為NE16加速器特別加速了3D卷積,這是TinyissimoYOLOv1.3網絡的核心層。由於加速器的能效,在GAP9上運行的TinyissimoYOLOv1.3的能量消耗僅比FOMO增加2.7倍,如圖6d)所示。
Ablation
除了增加自適應分塊步驟外,作者對標準FOMO實現進行了兩個修改,如第三部分A1節所述。
這些修改包括:(1)移除融合步驟,(2)在訓練過程中集成軟F1損失。在表3中,作者展示了這些修改對物體計數誤差以及F1指標的影響。此比較的基準是標準FOMO實現,作者使用所有網絡的輸入解像度均為192×192。

圖4比較了所有網絡對於同一輸入圖像的輸出。圖4a) 突出了FOMO融合方法帶來的負面影響。在這個場景中,車輛被緊密地停在一起,以至於相鄰車輛的邊界框甚至接觸在一起。這意味著大多數車輛位於FOMO特徵網格的相鄰網格單元中,這導致FOMO錯誤地將許多預測融合成跨多個車輛的大邊界框。如表3所示,去掉這個融合步驟可以顯著提高召回率以及目標計數誤差。這些結果在圖4b)中得到了視覺確認,可以明顯看到去掉這個融合步驟大大減少了假陰性數量。

圖4c)說明了提出的鑲嵌方法如何既增加了FOMO預測網格單元的數量,又減少了網格單元的大小。這個過程減少了同一網格單元被多個車輛覆蓋的可能性,同時增加了同一輛車被多個網格單元覆蓋的可能性。在III-A1節中描述的融合方法能夠融合重疊的預測,但在不重疊時,它不能將屬於同一輛車的預測進行融合,導致目標計數過多。這就是為什麼表3中的目標計數變得更糟,而F1指標保持相似水平的原因。
最後,圖4d)顯示了使用軟F1損失進行訓練的效果。使用這種損失,網絡被鼓勵在單個目標上只進行一次預測,即使它被多個網格單元覆蓋。這種看似「隱式」的非極大值抑制大大減少了每個目標的重覆預測,從而導致了目標計數誤差的重大降低。與標準FOMO實現相比,作者實現了F1分數增加225%,目標計數誤差減少76%。
V Conclusion
本文通過將作者之前提出的自適應鑲嵌方法應用於最新的TinyissimoYOLOv1.3網絡,擴展了該方法。TinyissimoYOLOv1.3生成的邊界框預測可以被自適應鑲嵌方法智能地融合相鄰瓷磚的預測。
新穎的瓷磚融合算法將之前實現的平均物體數量誤差從12.9 MAE降低到6.2 MAE,在作者的FOMO實現中,實現了在CARPK數據集[22]上的最先進檢測精度。
本工作在基於_RISC-V_的GAP9 MCU上進行了邊緣部署,該MCU內置了來自 GreenWaves Technologies_的ML加速器。
FOMO的最佳實現可以在單個瓷磚上運行推理,耗時7.31 ms,從而在33.4 FPS的全圖像上預測物體位置,而TinyissimoYOLOv1.3每個瓷磚的推理時間為16.2 ms,在全圖像上的預測速度為2.8 FPS。
作者展示了如何使用提出的鑲嵌方法實現高檢測性能,與CARPK數據集[22]上的最先進的大型網絡相媲美,同時滿足MCU嚴格的低內存和低功耗要求。這些結果是向MCU實時小目標檢測邁出的重大一步。
參考文獻
[0]. DSORT-MCU: Detecting Small Objects in Real-Time on Microcontroller Units.