關於LLM-as-a-judge範式,終於有綜述講明白了
AIxiv專欄是機器之心發佈學術、技術內容的欄目。過去數年,機器之心AIxiv專欄接收報導了2000多篇內容,覆蓋全球各大高校與企業的頂級實驗室,有效促進了學術交流與傳播。如果您有優秀的工作想要分享,歡迎投稿或者聯繫報導。投稿郵箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
本篇綜述的作者團隊包括亞利桑那州立大學的博士研究生李大衛,蔣博涵,Alimohammad Beigi, 趙成帥,譚箴,Amrita Bhattacharje, 指導老師劉歡教授,來自伊利諾伊大學芝加哥分校的黃良傑,程璐教授,來自馬里蘭大學巴爾的摩郡分校的江宇軒,來自伊利諾伊理工的陳燦宇,來自加州大學伯克利分校的吳天昊以及來自埃梅利大學的舒凱教授。
摘要:評估和評價長期以來一直是人工智能 (AI) 和自然語言處理 (NLP) 中的關鍵挑戰。然而,傳統方法,無論是基於匹配還是基於詞嵌入,往往無法判斷精妙的屬性並提供令人滿意的結果。大型語言模型 (LLM) 的最新進展啟發了 「LLM-as-a-judge」 範式,其中 LLM 被用於在各種任務和應用程序中執行評分、排名或選擇。本文對基於 LLM 的判斷和評估進行了全面的調查,為推動這一新興領域的發展提供了深入的概述。我們首先從輸入和輸出的角度給出詳細的定義。然後,我們介紹一個全面的分類法,從三個維度探索 LLM-as-a-judge:評判什麼(what to judge)、如何評判(how to judge)以及在哪裡評判(where to judge)。最後,我們歸納了評估 LLM 作為評判者的基準數據集,並強調了關鍵挑戰和有希望的方向,旨在提供有價值的見解並啟發這一有希望的研究領域的未來研究。

-
論文鏈接:https://arxiv.org/abs/2411.16594
-
網站鏈接:https://llm-as-a-judge.github.io/
-
論文列表:https://github.com/llm-as-a-judge/Awesome-LLM-as-a-judge
文章結構

圖 1:論文結構
LLM-as-a-judge 的定義

圖 2:LLM-as-a-judge 定義
在這篇工作中,我們提出根據輸入和輸出格式的區別對 LLM-as-a-judge 進行了定義。首先,根據輸入候選樣本個數的不同,在輸入的層面 LLM-as-a-judge 可以分為逐點和成對 / 列表輸入;另外,根據模型輸出格式的不同,在輸出的層面 LLM-as-a-judge 的目的可以分為評分,排序和選擇。
Attribute:評判什麼

圖 3:LLM 能夠評判各種屬性。
LLM-as-a-judge 已經被證明可以在多種不同類型的屬性上提供可靠的評判,在這個章節中,我們對他們進行了總結,它們包括:回覆的幫助性,無害性,可靠性,生成 / 檢索文檔的相關性,推理過程中每一步的可行性,以及生成文本的綜合質量。
Methodology:如何評判

表 1:LLM-as-a-judge 訓練方法
(1)微調:最近許多工作開始探索如何使用微調技術來訓練一個專門的評判大模型,我們在這一章節中對這些技術進行了總結歸納,包括它們的數據源,標註者,數據類型,數據規模,微調技術及技巧等(表 1)。其中我們根據數據來源(人工標註和模型反饋)和微調技術(有監督微調和偏好學習)對這些工作進行了詳細討論。

圖 4:LLM-as-a-judge prompting 方法
(2)提示:提示(prompting)技術可以有效提升 LLM-as-a-judge 的性能和效率。在這一章節中,我們總結了目前工作中常用到幾類提示策略,分別是:交換操作,規則增強,多智能體合作,演示增強,多輪動態交互和對比加速。
Application:何時評判
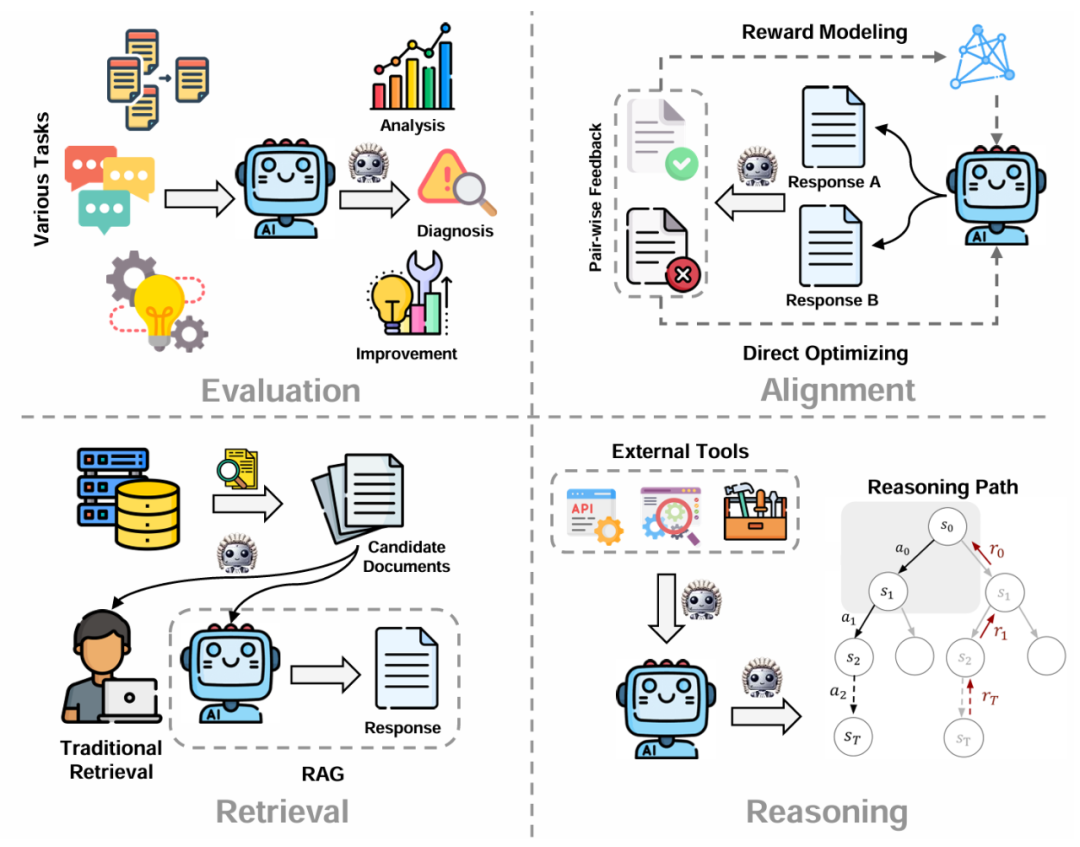
圖 5:LLM-as-a-judge 應用和場景
(1)評估:傳統 NLP 中的評估通常採用靜態的指標作為依據,然而它們常常不能夠很好的捕捉細粒度的語義信息。因此,LLM-as-a-judge 被廣泛引入到模型評估的場景中,進行開放式生成,推理過程以及各種新興 NLP 任務的評測。
(2)對齊:對齊技術通常需要大量人工標註的成對偏好數據來訓練獎勵或者策略模型,通過引入 LLM-as-a-judge 技術,採用更大的模型或者策略模型本身作為評估者,這一標註過程的時間和人力成本被大大優化。
(3)檢索:檢索場景同樣得益於 LLM-as-a-judge 對於文本相關性和幫助性強大的判別能力。其中對於傳統的檢索應用,LLM-as-a-judge 通過判斷文檔和用戶請求的相關性來選擇最符合用戶喜好的一組文檔。另外,LLM-as-a-judge 還被應用於檢索增強生成(RAG)的過程中,通過 LLM 自己來選擇對後續生成最有幫助的輔助文檔。
(4)推理:在推理過程中,LLM 在很多場景下會被賦予使用工具,API 或者搜索引擎的權限。在這些任務中,LLM-as-a-judge 可以依據當前的上下文和狀態選擇最合理可行的外部工具。另外,LLM-as-a-judge 還被廣泛引用於推理路徑的選擇,通過過程獎勵指導模型進行狀態步驟轉移。
基準:評判 LLM-as-a-judge
如表 2 所示,我們總結了不同針對 LLM-as-a-judge 的基準測試集,並從數據 / 任務類型,數據規模,參考文本來源,指標等多個方面對這些數據集做了總結歸納。其中,根據基準測試集目的的不同,大致可以分為:偏見量化基準,挑戰性任務基準,領域特定基準,以及其他多語言,多模態,指令跟隨基準等等。

表 2:LLM-as-a-judge 數據集和基線
展望:挑戰和機遇
(1)偏見與脆弱性:大模型作為評判者,一直受困擾於各種各樣影響評價公平性的偏見,例如順序偏見,自我偏好偏見,長度偏見等。同時,基於大模型的評價系統在面對外部攻擊時的魯棒性也存在一定不足。因此,LLM-as-a-judge 未來工作的一個方向是研究如何揭露和改善這些偏見,並提升系統面對攻擊的魯棒性。
(2)更動態,複雜的評判:早期的 LLM-as-a-judge 通常只採用比較簡單的指令來 prompt 大模型。隨著技術的發展,越來越多複雜且動態的 LLM-as-a-judge 框架被開發出來,例如多智能體判斷和 LLM-as-a-examiner。在未來,一個有前景的研究方向是開發具有人類評判思維的大模型智能體;另外,開發一個基於大模型自適應難度的評判系統也很重要。
(3)自我判斷:LLM-as-a-judge 長期以來一直受困擾於 「先有雞還是先有蛋」 的困境:強大的評估者對於訓練強大的 LLM 至關重要,但通過偏好學習提升 LLM 則需要公正的評估者。理想狀況下,我們希望最強大的大模型能夠進行公正的自我判斷,從而不斷優化它自身。然而,大模型具有的各種判斷偏見偏好使得它們往往不能夠客觀的評價自己輸出的內容。在未來,開發能夠進行自我評判的(一組)大模型對於模型自我進化至關重要。
(4)人類協同大模型共同判斷:直覺上,人工的參與和校對可以緩解 LLM-as-a-judge 存在偏見和脆弱性。然而,只有少數幾篇工作關注這個方向。未來的工作可以關注如何用 LLM 來進行數據選擇,通過選擇一個很小但很具有代表性的測試子集來進行人工評測;同時,LLM-as-a-judge 也可以從其他具有成熟的人機協同方案的領域受益。
總結
本文探討了 LLM-as-a-judge 的驚喜微妙之處。我們首先根據輸入格式(逐點、成對和列表)和輸出格式(包括評分、排名和選擇)對現有的基於 LLM-as-a-judge 進行定義。然後,我們提出了一個全面的 LLM-as-a-judge 的分類法,涵蓋了判斷屬性、方法和應用。此後,我們介紹了 LLM-as-a-judge 的詳細基準集合,並結合了對當前挑戰和未來方向的深思熟慮的分析,旨在為這一新興領域的未來工作提供更多資源和見解。