揭秘注意力機制真正起源,10年前3項研究幾乎同時獨立提出,背後故事細節被Karpathy曬郵件公開了
大模型的核心組件注意力機制,究竟如何誕生的?
可能已經有人知道,它並非2017年Transformer開山論文《Attention is all you need》首創,而是來自2014年Bengio實驗室的另一篇論文。
現在,這項研究背後更多細節被公開了!來自Karpathy與真正作者兩年前的郵件往來,引起了很多討論。
到現在已有整10年歷史。

一作Dzmitry Bahdanau,當時是Bengio實驗室的一位實習生,在實習只剩5周時靈光一現提出了一個簡化方案,相當於實現了對角注意力。
Pytorch等經典代碼中,正是把注意力稱為Bahdanau Attention,還保留著他貢獻的痕跡。
Karpathy之所以現在提起這段往事,是因為最近社區中流傳著一些誤解,認為Transformer作者受到科幻電影《降臨》中外星人交流方式的啟發。
但其實Transformer作者中的Illia Polosukhin只是很久以後接受採訪時用《降臨》來類比。
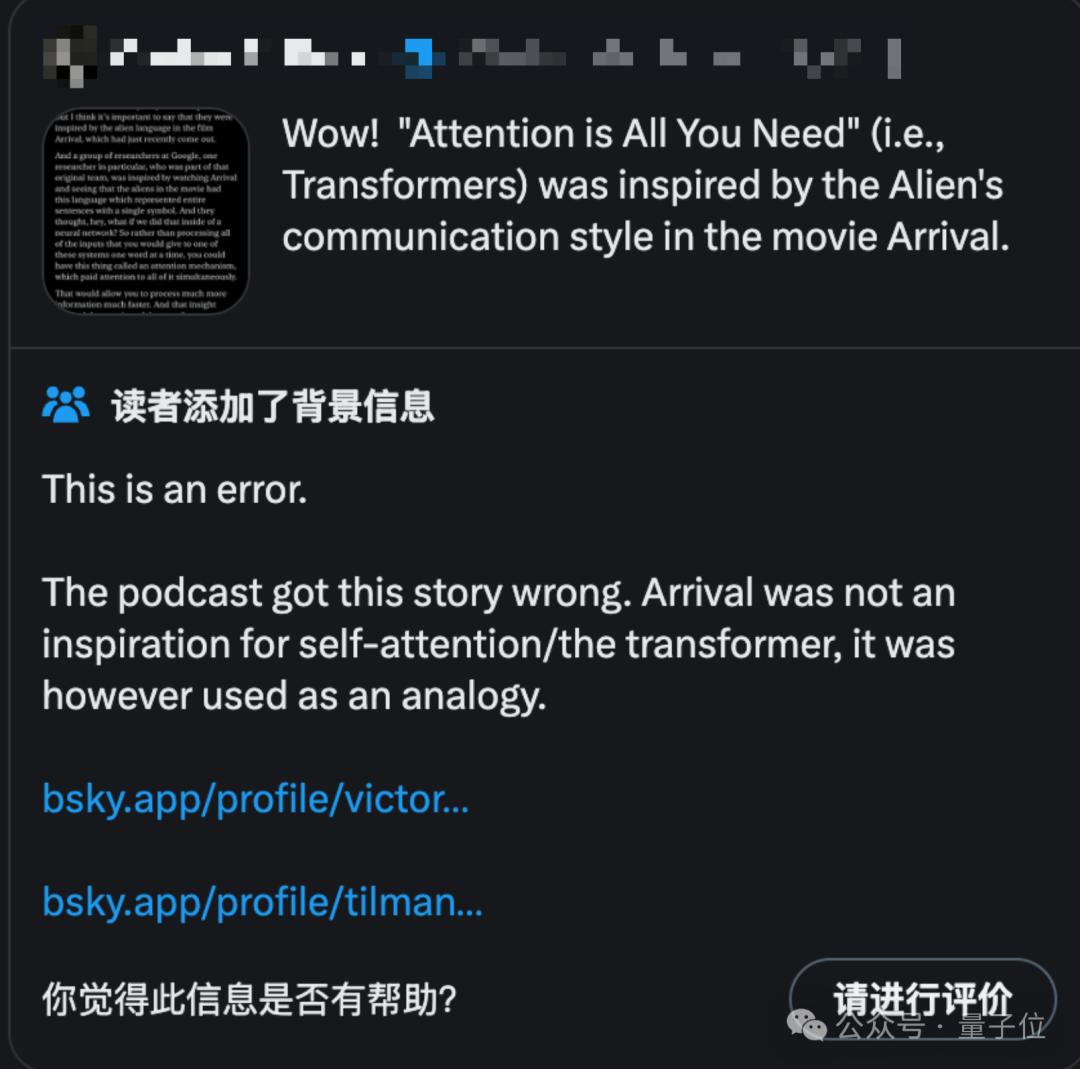
真正2014年Attention機制的靈感,其實來自人類翻譯文字過程中來回看材料的行為。
除了澄清這一點之外,這段真實故事中還有更多亮點,對今天的研究仍有很多啟發。
2014年的Attention,與同期Alex Graves論文Neural Turing Machines,和Jason Weston論文Memory Networks有類似之處,但這些研究出發點和動機不同。
說明在技術積累的臨界點上,不同研究者常會獨立地提出相似的創新。
原本的名字「RNNSearch」不夠直觀,後來在Yoshua Bengio的建議下改為「注意力」,更能抓住核心概念。
原來起個好名字,真的可以提升技術的傳播和影響力。
有網民看過這個故事之後,感歎這封郵件「應該放在計算機科學博物館」。
給這些改變世界的發現幾乎總是從實驗開始的,而且沒有人真正提前知道它們的結局。

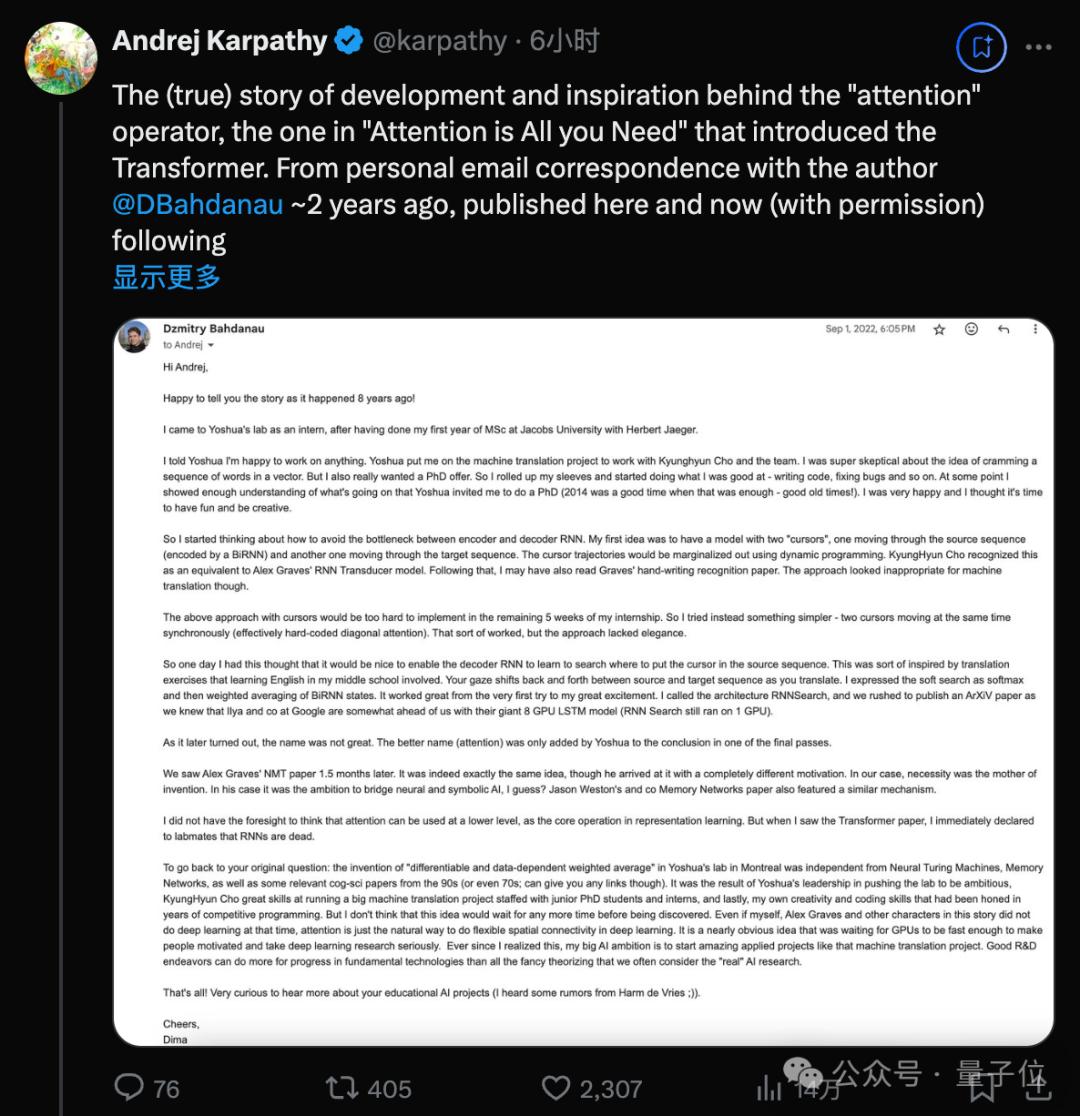
以下為Dzmitry Bahdanau發給Karpathy的原始郵件全文翻譯,郵件寫於2022年。
10年前,Attention真正的誕生
嗨,Andrej。
很高興為您講述8年前發生的故事!
我在Jakobs University(德國耶高比大學)跟隨Herbert Jaeger完成了碩士一年級的學業後,來到Yoshua(圖靈獎得主Yoshua Bengio)的實驗室實習。
我向Yoshua表示我願意從事任何工作,他便讓我參與機器翻譯項目,與Kyunghyun Cho及團隊展開合作。
我對將一系列單詞塞進向量的想法非常懷疑,但我也真的很想要一個博士學位的offer,所以我捲起袖子,開始做我擅長的事情——編寫代碼、修復Bug等等。
在某個時候,我對團隊正在進行的工作有了足夠的瞭解,Yoshua邀請我攻讀博士學位。2014年是個好時代,只需這些工作就足以讓我讀博了——美好的舊時光!
我很高興,我覺得是時候享受樂趣併發揮創造力了。
於是我開始思考如何避免Encoder-Decoder RNN之間的信息瓶頸。
我的第一個想法是建立一個帶有兩個「光標」的模型:一個在源序列中移動,由BiRNN編碼;另一個在目標序列中移動。光標軌跡將使用動態規劃邊際化。
Kyunghyun Cho認為這相當於Alex Graves的RNN Transducer模型。之後,我可能也讀了Graves的手寫識別論文,但這種方法對於機器翻譯來說似乎不太合適。
上述帶有光標的方法在我實習的賸餘5周內很難實現,所以我嘗試了更簡單的方法——兩個光標同時同步移動,實際上相當於硬編碼的對角注意力。
這種方法有點效果,但缺乏優雅。
所以有一天我有了新的想法,讓Decorder RNN學會在源序列中搜索放置光標的位置。這在一定程度上受到了我中學英語學習中翻譯練習的啟發。
在翻譯時,你的目光會在源序列和目標序列之間來回移動,我將軟搜索表示為softmax,然後對BiRNN 狀態進行加權平均。從第一次嘗試就效果很好,我非常興奮。
我將這個架構稱為RNNSearch,在1個GPU上運行。由於我們知道Google的Ilya(OpenAI前首席科學家Ilya Sutskever)團隊使用8個GPU的LSTM模型在某些方面領先於我們,所以我們趕緊在ArXiV上發表了一篇論文。
後來發現,這個名字並不好。更好的名字(注意力)是Yoshua在最後的一次修改中添加到結論中的。
直觀地說,這在解碼器中實現了一種注意力機制,解碼器決定源語句的哪些部分需要關注。通過讓解碼器具有注意力機制,我們減輕了編碼器將源語句中的所有信息編碼為固定長度向量的負擔。通過這種新方法,信息可以分佈在整個註釋序列中,解碼器可以相應地有選擇地檢索。

一個半月後,我們看到了Alex Graves的論文。確實是完全相同的想法,儘管他的動機完全不同。

在我們這邊,發明新算法是需求驅動的。我猜在他那邊,是連接神經學派和符號學派的雄心?Jason Weston團隊的Memory Networks論文也有類似的機制。

我沒有預見到注意力可以在更低的層次上使用,作為表示學習的核心算法。
但當我看到Transformer論文時,我立即向實驗室的同事宣佈:RNN已死。
回到您最初的問題:在蒙特利爾Yoshua的實驗室中「可微且數據依賴的加權平均」的發明與神經圖靈機、Memory Networks以及90年代(甚至 70 年代;但我無法提供鏈接)的一些相關認知科學論文無關。
這是Yoshua推動實驗室追求雄心壯誌的領導成果,Kyunghyun Cho在管理由初級博士生和實習生組成的大型機器翻譯項目方面的出色技能,以及我自己多年來在編程競賽中磨練出的創造力和編程技能的結果。
即使我自己、Alex Graves和這個故事中的其他角色當時沒有從事深度學習工作,離這個想法出現也不會太遠了。
注意力只是深度學習中實現靈活空間連接的自然方式,這幾乎是一個顯而易見的想法,一直在等待GPU足夠快,讓人們有動力並認真對待深度學習研究。
自從我意識到這一點,我對AI的大誌向就是啟動像機器翻譯那樣令人驚歎的應用項目。
良好的研發工作可以為基礎技術的進步做出更多貢獻,而不是我們通常認為「真正的」人工智能研究的所有花哨的理論。
就醬!非常好奇聽到更多關於您的AI教育項目的消息(我從 Harm de Vries 那裡聽到了一些傳聞)。
乾杯,Dima
One More Thing
Karpathy感歎,有點驚訝這篇真正的注意力起源論文沒有獲得足夠多的
自從Attention is all you need一飛衝天之後,大家意識到給論文起一個好名字對技術傳播的影響,後面的論文標題就放飛了。
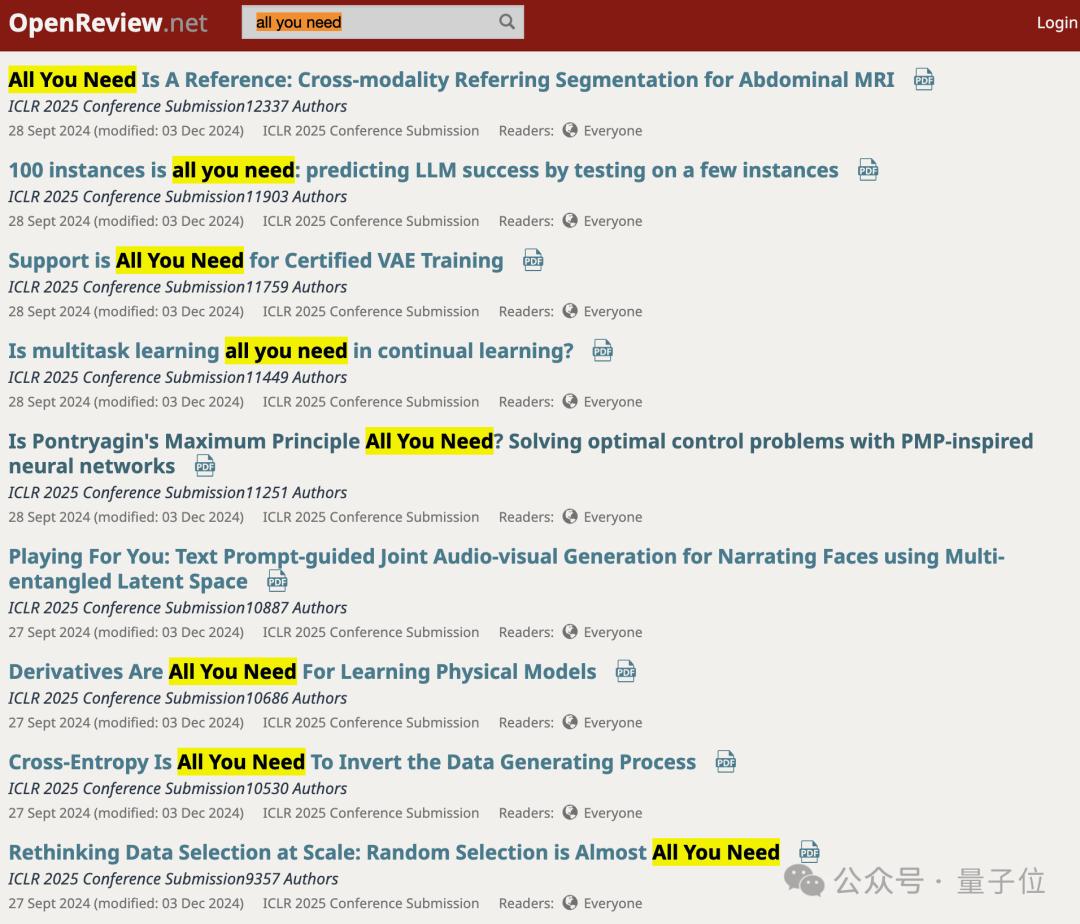
除了紮堆模仿xx is all you need之外,最近甚至還出現了Taylor Unswift。
講的是把模型權重轉換成泰萊級數的參數,來保護已發佈模型的擁有權並防止被濫用。

就,emmm……

提到的論文:
Neural Machine Translation by Jointly Learning to Align and Translate
https://arxiv.org/abs/1409.0473
Attention is All You Need
https://arxiv.org/abs/1706.03762
Neural Turing Machines
https://arxiv.org/abs/1410.5401
Generating Sequences With Recurrent Neural Networks
https://arxiv.org/abs/1308.0850
Memory Networks
https://arxiv.org/abs/1410.3916
Sequence to Sequence Learning with Neural Networks
https://arxiv.org/abs/1409.3215
Taylor Unswift:
https://arxiv.org/abs/2410.05331
參考鏈接:
[1]https://x.com/karpathy/status/1864028921664319735
本文來自微信公眾號「量子位」,作者:夢晨,36氪經授權發佈。