懂你情緒,多語言、多方言實時語音對話!清華、智譜團隊打造 GLM-4-Voice,已開源
文 | 學術頭條
今年 10 月,智譜在 CNCC2024 大會上推出了他們在多模態領域的最新成果——端到端情感語音模型 GLM-4-Voice,讓人和機器的交流能夠以自然聊天的狀態進行。
據介紹,GLM-4-Voice 能夠直接理解和生成中英文語音,進行實時語音對話,在情緒感知、情感共鳴、情緒表達、多語言、多方言等方面實現突破,且延時更低,可隨時打斷。
日前,智譜團隊發佈了 GLM-4-Voice 的研究論文,對這一端到端語音模型的核心技術與評估結果進行了詳細論述。

論文鏈接:
https://arxiv.org/abs/2412.02612
GitHub 地址:
GLM-4-Voice 是如何練成的?
與傳統的 ASR + LLM + 湯臣S 的級聯方案相比,端到端模型以音頻 token 的形式直接建模語音,在一個模型裡面同時完成語音的理解和生成,避免了級聯方案「語音轉文字再轉語音」 的中間過程中帶來的信息損失,也解鎖了更高的能力上限。
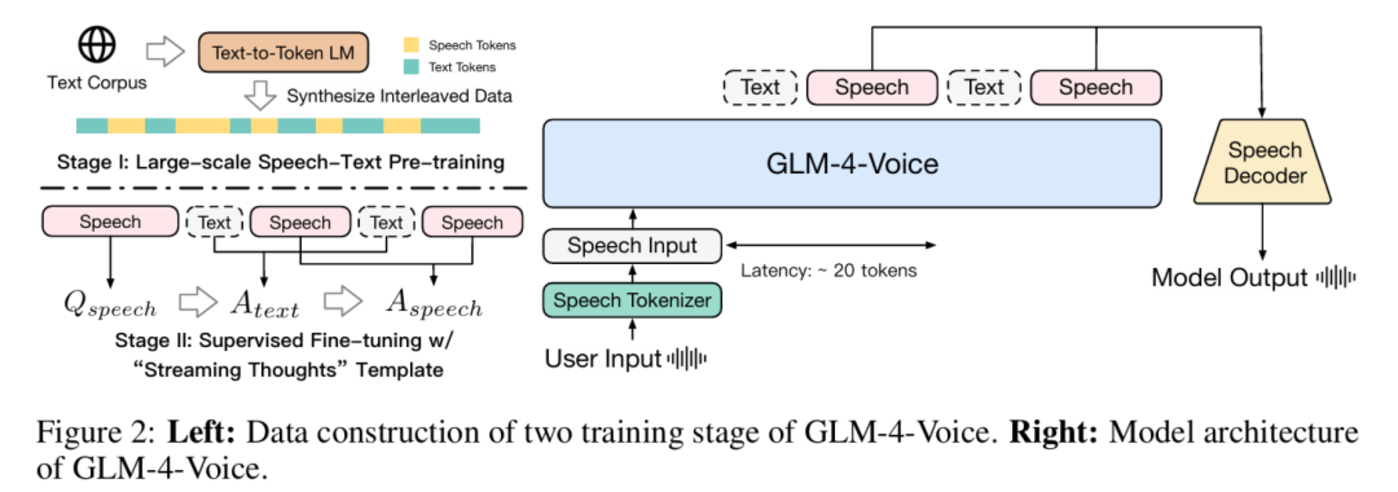 圖|GLM-4-Voice 模型架構圖。
圖|GLM-4-Voice 模型架構圖。GLM-4-Voice 由三個部分組成:
- GLM-4-Voice-Tokenizer:通過在 Whisper 的 Encoder 部分增加 Vector Quantization 並在 ASR 數據上有監督訓練,將連續的語音輸入轉化為離散的 token。每秒音頻平均只需要用 12.5 個離散 token 表示。
- GLM-4-Voice-Decoder:基於 CosyVoice 的 Flow Matching 模型結構訓練的支持流式推理的語音解碼器,將離散化的語音 token 轉化為連續的語音輸出。最少只需要 10 個語音 token 即可開始生成,降低端到端對話延遲。
- GLM-4-Voice-9B:在 GLM-4-9B 的基礎上進行語音模態的預訓練和對齊,從而能夠理解和生成離散化的語音 token。
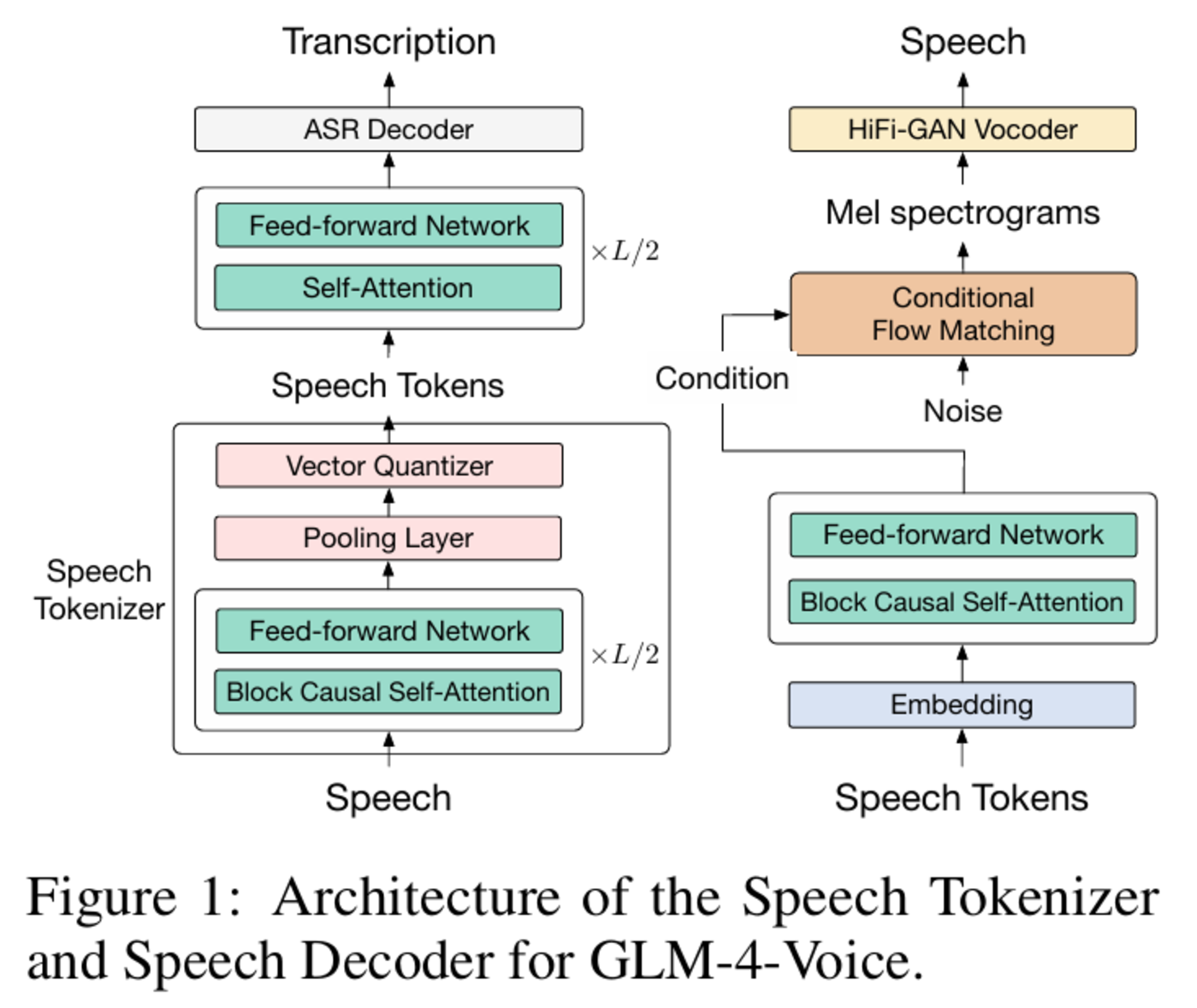 圖|GLM-4-Voice-Tokenizer 和 GLM-4-Voice-Decoder 的架構。
圖|GLM-4-Voice-Tokenizer 和 GLM-4-Voice-Decoder 的架構。預訓練方面,為了攻克模型在語音模態下的智商和合成表現力兩個難關,他們將 Speech2Speech 任務解耦合為「根據用戶音頻做出文本回覆」和「根據文本回覆和用戶語音合成回覆語音」兩個任務,並設計兩種預訓練目標,分別基於文本預訓練數據和無監督音頻數據合成語音-文本交錯數據以適配這兩種任務形式。
具體而言,模型的預訓練包括 2 個階段。
第一階段為大規模語音-文本聯合預訓練,在該階段中 GLM-4-Voice 採用了三種類型的語音數據:語音-文本交錯數據、無監督語音數據和有監督語音-文本數據,實現了促進文本和語音模態之間知識遷移、幫助模型學習真實世界語音特徵以及提升模型基本任務方面性能方面的效果。尤其,GLM-4-Voice-9B 在 GLM-4-9B 的基座模型基礎之上,經過了數百萬小時音頻和數千億 token 的音頻文本交錯數據預訓練,擁有很強的音頻理解和建模能力。
第二階段為監督微調階段,旨在進一步提高 GLM-4-Voice 的對話能力。研究人員使用了兩種類型的對話數據,包括多輪對話數據與語音風格控制對話數據。前者主要來自文本數據,經過精心篩選和語音合成,確保對話內容的質量和多樣性。而後者包含高質量的對話數據,用於訓練模型生成不同風格和語調的語音輸出。
此外,在對齊方面,為了支持高質量的語音對話,降低語音生成的延遲,研究團隊設計了一套流式思考架構:根據用戶語音,GLM-4-Voice 可以流式交替輸出文本和語音兩個模態的內容,其中語音模態以文本作為參照保證回覆內容的高質量,並根據用戶的語音指令要求做出相應的聲音變化,在最大程度保留語言模型智商的情況下仍然具有端到端建模的能力,同時具備低延遲性,最低只需要輸出 20 個 token 便可以合成語音。
效果怎麼樣?
研究團隊在基礎模型評估與聊天模型評估兩方面對 GLM-4-Voice 進行了性能評估。
他們首先通過語音語言建模、語音問答以及 ASR 和 湯臣S 這三項任務對基礎模型進行了評估。
在語音語言建模任務中,GLM-4-Voice 在 Topic-StoryCloze 和 StoryCloze 等數據集上的準確率顯著領先同類模型。在從語音到文本生成(S→T)的任務中,GLM-4-Voice 的準確率達到 93.6%(Topic-StoryCloze),遠高於其他模型。同時,在語音到語音生成(S→S)的任務中,GLM-4-Voice 依然在 Topic-StoryCloze 數據集中獲得了與 Spirit-LM 相近的高分(82.9%)。
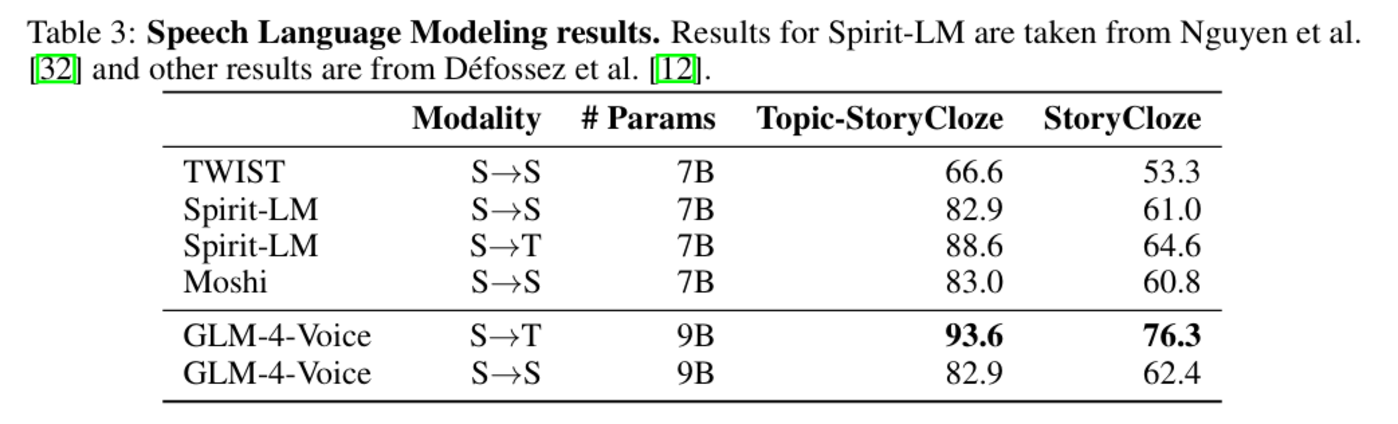 圖|語音語言建模結果。
圖|語音語言建模結果。在語音問答任務中,GLM-4-Voice 在 Web Questions、Llama Questions 和 TriviaQA 等數據集上全面領先,進一步提升了模型在長上下文交互場景中的適應性。
- S→T 模態:在所有數據集中,GLM-4-Voice 均顯著超過基線模型,TriviaQA 數據集中準確率達到 39.1%,相比Moshi提升了 16.3%。
- S→S 模態:在語音到語音的問答任務中,GLM-4-Voice 同樣表現優異,尤其是在 Llama Questions 中準確率達到 50.7%,大幅領先其餘模型。
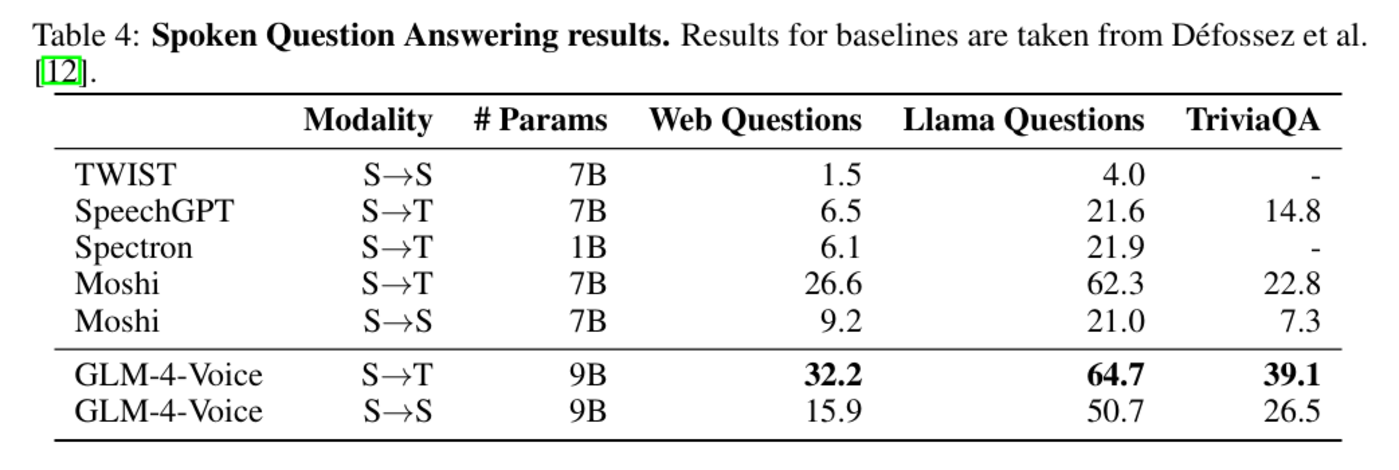 圖|語音問答結果。
圖|語音問答結果。在 ASR 和 湯臣S 任務中,GLM-4-Voice 的性能也同樣接近或超越專門設計的語音處理模型。
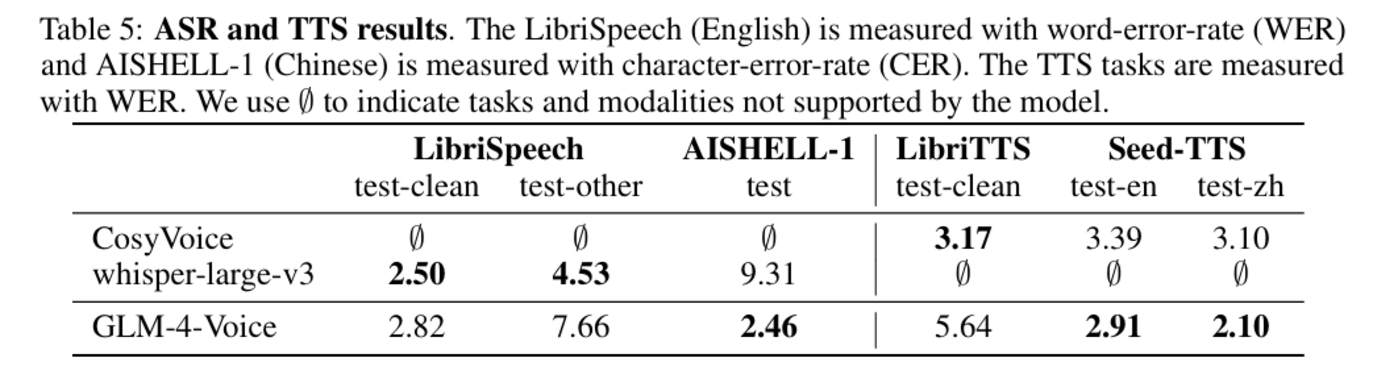 圖|ASR 和 湯臣S 結果。
圖|ASR 和 湯臣S 結果。之後,研究團隊對聊天模型進行了評估。
為評估對話質量,研究團隊引入 ChatGPT 作為自動評分工具,對模型的回答進行多維度評價。GLM-4-Voice 在常見問題(General QA)和知識問答(Knowledge QA)兩類任務中得分遙遙領先:在 General QA 中 GLM-4-Voice 得分為 5.40,相比 Llama-Omni(3.50)和 Moshi(2.42)提升顯著。在 Knowledge QA 中 GLM-4-Voice 的得分同樣超過其他模型。
GLM-4-Voice 在語音生成質量方面也實現了新突破。模型主觀評價指標(MOS)的評分中達到 4.45,超越現有基線模型,表明 GLM-4-Voice 生成的語音更加自然流暢,能夠滿足用戶對高質量語音交互的需求。
同時,在文本與語音對齊性測試中,GLM-4-Voice 的語音轉文本誤差率(ASR-WER)降至 5.74%,顯示出優異的文本-語音一致性。這種能力進一步提升了模型在多模態交互中的應用潛力。
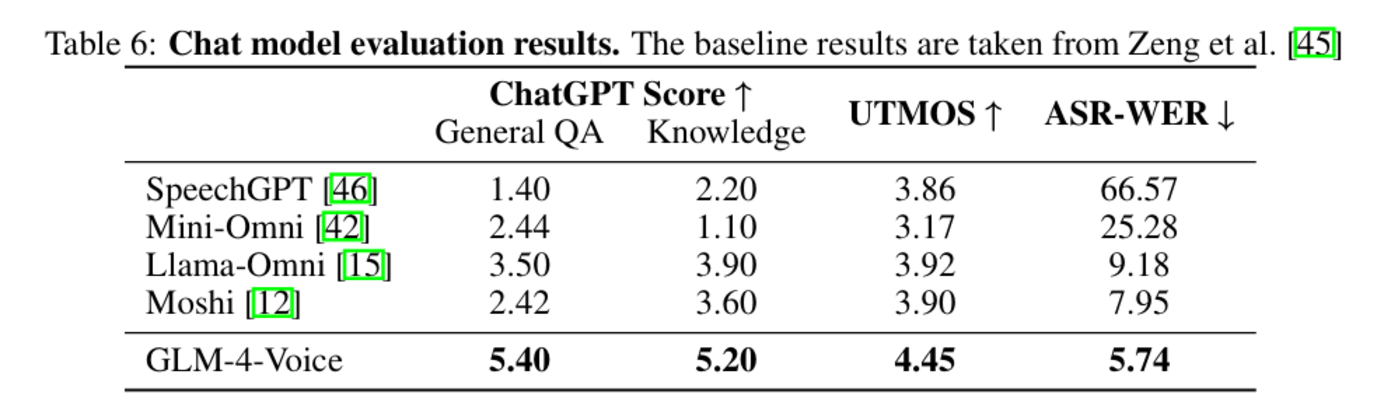 圖|聊天模型評估結果。
圖|聊天模型評估結果。評估結果顯示,GLM-4-Voice 在語音語言建模、語音問答等任務上表現卓越,同時大幅降低了延遲,並顯著提升了語音質量和對話能力,性能超過現有基線模型。這一創新為構建高性能語音交互系統提供了全新路徑,開拓了更廣泛的應用可能性。
目前,GLM-4-Voice 已開源,目前已有 2.4k stars。研究團隊表示,這將鼓勵人們進一步探索建立實用、易用的語音人工智能系統。



















