科學家用知識圖譜增強大模型新範式,提升大模型的推理能力和效率
近年來,大模型在處理複雜任務時展現出強大的推理能力。中國科學技術大學熊輝教授團隊與合作者注意到,儘管其在眾多實際應用中取得了成功,它們仍存在一些明顯的問題:比如知識的滯後性、生成信息的可靠性,以及決策過程的不透明性。
相比之下,作為一種大規模結構化的知識庫,知識圖譜則可以提供大量的顯式和可編輯的現實世界知識的描述,這些特性使得知識圖譜能夠彌補大模型的缺點。
儘管目前的知識圖譜增強大模型範式能夠為更全面地融合知識圖譜和大模型二者的知識提供機會,但是在面臨許多複雜問題時,可能仍然無法正確規劃推理路徑的探索。
 圖丨陳力以(來源:陳力以)
圖丨陳力以(來源:陳力以)日前,在熊輝教授的帶領和指導下,陳力以博士和課題組其他成員共同完成了以《圖上規劃:知識圖譜上大語言模型的自我糾正自適應規劃》(Plan-on-Graph: Self-Correcting Adaptive Planning of Large Language Model on Knowledge Graphs)為題的相關論文,該論文已被人工智能領域頂級會議神經信息處理系統大會(NeurIPS 2024, the 38th Annual Conference on Neural Information Processing Systems)接收,並公開在預印本網站 arXiv 上 [1]。
中國科學技術大學陳力以博士是第一作者,熊輝教授擔任通訊作者。
 圖丨相關論文(來源:NeurIPS)
圖丨相關論文(來源:NeurIPS)
克服現有知識圖譜增強大模型範式的局限性
為了更深入地理解現有大模型範式的局限性,該團隊挑選了一些典型的推理錯誤的案例,並進行了定量和定性的分析。該課題組通過這些分析發現,現有的知識圖譜增強大模型範式的局限性主要在以下幾個方面:
-
探索廣度受限。現有範式通常設定固定的探索廣度,這導致不能在面對複雜問題時對探索範圍調整,使其探索的靈活性和正確性受限。
-
沒有自糾正機制。現有範式中的路徑探索是單向的,沒有對錯誤路徑進行自我糾正的能力,容易導致推理失敗。
-
大模型「失憶」。在需要滿足多個條件的情況下,大模型容易出現「失憶」現象,無法同時滿足多個條件的答案。
因此,複雜問題的推理可能嚴重依賴於自適應探索和錯誤推理路徑的自我糾正。
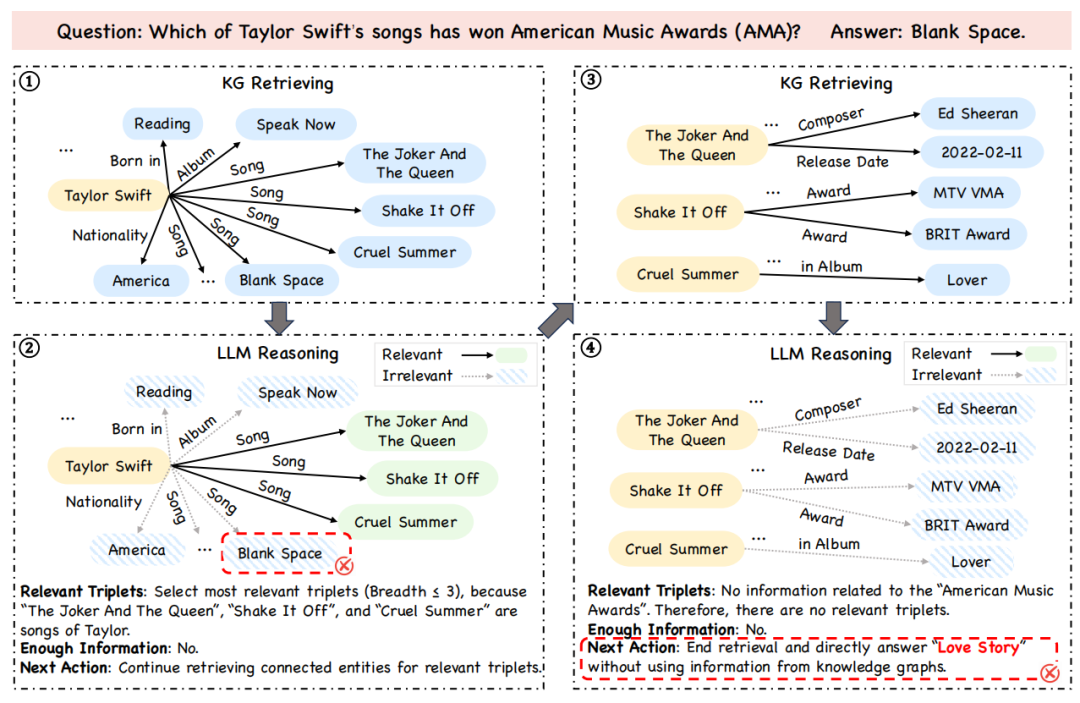
圖丨上圖反映了現有的知識圖譜增強大模型範式的局限性。以問題「泰萊·斯威夫特哪首歌曾獲得過全美音樂獎?」為例,首先,受限於固定的探索寬度,模型只能選取 3 首歌曲,忽略了正確答案《Blank Space》。另外由於探索方向不可逆,即使這 3 首歌都是錯誤的,模型也不能自己進行修正。到最後一步,模型「失憶」,忽略了問題中的條件「獲得過全美音樂獎」,而得出了錯誤的結論《Love Story》(來源:NeurIPS)
針對上述問題,該團隊設計了一種新的自我糾正自適應規劃的知識圖譜增強大模型範式,稱為 Plan-on-Graph(PoG),它能夠自適應地規劃圖上遊走的探索範圍,並且具備糾正錯誤推理路徑的能力。
通過以下的具體設計,有效緩解了上述問題造成的瓶頸:
-
自適應探索範圍。讓大模型能夠根據實際情況動態調整探索範圍的廣度,而不是固定在一個預設的值上。
-
反思機制。設計一個反思機制,使大模型能夠根據已有信息判斷是否需要進行糾正,並在哪個步驟進行糾正。
-
引導和記憶機制。引入引導和記憶機制,幫助大模型記住所有的條件和歷史信息,避免在推理過程中遺忘關鍵信息。
該研究首次將自我糾正機制和自適應知識圖譜探索設計到知識圖譜增強大模型中,這一新型範式不僅提升了知識圖譜與大模型結合的靈活性和準確性,還極大地優化了信息檢索和決策製定的效率。

PoG 的自適應自我糾正規劃機制
在具體的模型設計上,PoG 首先將問題分解為多個子目標,將其作為規劃探索的指導。然後,PoG 會重覆自適應地探索推理路徑,以訪問相關的知識圖譜數據,更新記憶以提供動態證據進行反思,並評估是否需要自我糾正推理路徑,這一過程會持續進行直到推理出答案。
在 PoG 中,研究人員設計了三種機制以實現自適應的自我糾正規劃:
1.Guidance(引導):為了更好地利用問題中的條件引導自適應探索,他們利用大模型將問題分解為包含條件的子目標,從而有助於靈活地識別與每個條件相關的路徑。
2.Memory(記憶):存儲在記憶中的信息提供了歷史檢索和推理信息以供反思。他們記錄並更新子圖,為大模型提供所有檢索到的實體,以初始化新的探索和自我糾正路徑。
記錄推理路徑,以保留實體之間的關係,供大模型推理並允許路徑糾正。此外,還記錄子目標狀態,使大模型能夠識別每個條件的已知信息,並在反思階段減輕其遺忘。
3.Reflection(反思):為了確定是否繼續或自我糾正當前的推理路徑,他們設計了一種反思機制,利用大模型根據記憶中的信息判斷是否考慮其他實體進行新的探索,並決定回溯到哪個實體以進行自我糾正。
並且,研究人員選擇了一些公開的真實世界知識圖譜問答數據集進行實驗,以驗證 PoG 的有效性和效率。
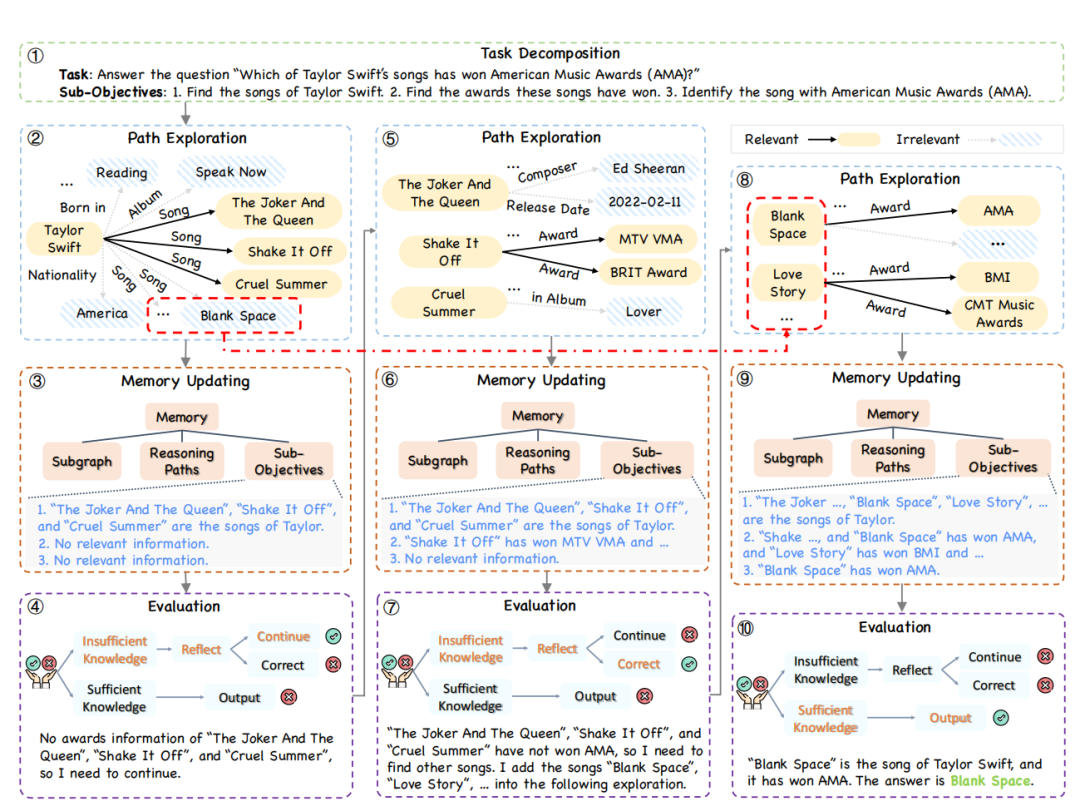
圖丨 PoG 的推算過程。仍然以問題「泰萊·斯威夫特哪首歌曾獲得過全美音樂獎?」為例,首先 PoG 將其拆解為 3 個子目標:1. 找到泰萊·斯威夫特的歌曲;2. 找到這些歌曲獲得的獎項;3. 找到獲得全美音樂獎的歌曲。然後將這些子目標進行路徑探索和反思,在不斷自我糾正的過程中得出正確答案(來源:NeurIPS)
實驗結果表明,PoG 不僅在性能上能夠顯著提升,還在效率上取得了重大突破,成為了當前最 SOTA(State-of-the-Art)的知識圖譜增強大模型的方法。
在性能方面,對於不同的底層大模型,PoG 均大幅超過最先進的基準,可以實現 11.4% 的性能提升。
並且 PoG 還證明,結合知識圖譜能夠有效提升大模型性能的價值,提升的程度依靠於方法的設計,最多能夠提升 201.4%。
在效率方面,相較於之前的範式,PoG 的自適應探索範圍減少了不必要的探索,而有效的糾正避免了錯誤路徑的擴展。不僅在時間上能夠實現 4 倍的加速,而且能夠節約 26.1% 的 Token 資源消耗。

引領多領域智能化升級
PoG 作為一種新型的自我糾正自適應規劃範式,通過結合大型語言模型和知識圖譜的優勢,解決了現有方法中存在的問題,具有廣泛的應用前景。
無論是在智能問答系統、推薦系統、自動文本生成、醫療診斷輔助還是法律諮詢等領域,PoG 都能夠顯著提升系統的性能和用戶體驗,為實際應用帶來巨大的價值。
最直接的應用就是智能問答系統,不論是通用的問答還是面向特定領域的問答,都可以使用外部的知識圖譜來實現大模型的增強推理。
傳統的問答系統往往依賴於預定義的知識庫和規則,對於複雜和長尾問題的處理能力有限。
PoG 通過自適應地探索知識圖譜中的推理路徑,並能夠自我糾正錯誤的推理路徑,大大提高了系統的準確性和響應速度。
另一方面,PoG 在推薦系統中也可以實現更加精準和高效的推薦。傳統的推薦系統主要依賴於用戶的歷史行為數據,對於冷啟動問題和長尾物品推薦效果不佳。
PoG 通過知識圖譜中的豐富信息,為用戶提供更加個性化和精準的推薦。
例如,在電商領域,PoG 可以根據用戶的購買歷史和瀏覽行為,結合商品的知識圖譜信息,推薦與其興趣和需求高度匹配的商品。
並且,在日常輔助的材料撰寫等文本生成應用中,PoG 可以顯著提升生成內容的質量和多樣性。
傳統的文本生成模型往往依賴於預訓練的語料庫,生成的文本可能存在邏輯不連貫、信息不準確等問題。
PoG 通過自適應地探索知識圖譜中的相關信息,可以在生成文本時確保內容的準確性和邏輯性。
此外,PoG 在一些特定的領域中也可以得到應用,比如在醫療診斷輔助中的應用可以顯著提高診斷的準確性和效率,在法律諮詢領域的應用可以為用戶提供更加專業和準確的法律建議。
未來,隨著技術的不斷髮展和完善,PoG 的應用範圍也可以進一步擴大,為各行各業的發展提供強有力的支持。
儘管在增強大模型推理能力的研究中取得了一些進展,但這項技術在處理更加複雜的問題時,仍存在一些局限性。
為了進一步提升 PoG 的性能和應用範圍,該課題組已經製定了幾個後續研究計劃:
1. 提升大模型的置信度
目前,大模型在確定所需信息、提取信息所需的步驟數、何時進行動態更新,以及當前信息是否足夠等方面仍然缺乏足夠的置信度。為瞭解決這一問題,他們計劃在未來的工作中專注於評估大模型的置信度。
2. 提高效率
處理複雜問題通常需要多個步驟,這會增加計算時間和資源消耗。為了提高任務執行的效率,特別是在大模型具有較高置信度的情況下,他們計劃設計新的策略來減少不必要的步驟。
3. 處理非標準化查詢
對於不太標準化的查詢,現有的大模型可能由於自身能力的限制而無法充分理解語義,從而導致效果下降。為瞭解決這個問題,研究人員將採用最先進的查詢重寫方法或與用戶進行交互來細化具體的查詢意圖。
他們希望通過這些後續研究,能夠進一步提升 PoG 的性能,從而應用在更廣泛的場景。
參考資料:
1.https://arxiv.org/html/2410.23875v1
運營/排版:何晨龍





















