NeurIPS 2024 | LLM智能體真能模擬人類行為嗎?答案有了
AIxiv專欄是機器之心發佈學術、技術內容的欄目。過去數年,機器之心AIxiv專欄接收報導了2000多篇內容,覆蓋全球各大高校與企業的頂級實驗室,有效促進了學術交流與傳播。如果您有優秀的工作想要分享,歡迎投稿或者聯繫報導。投稿郵箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
主要作者:謝承興,曾作為 KAUST 訪問學生,Camel AI 實習生,現西安電子科技大學大四本科生,主要研究方向為 LLM simulation,LLM for Reasoning;陳燦宇,伊利諾伊理工大學在讀四年級博士生,研究方向為 Truthful, Safe and Responsible LLMs with the applications in Social Computing and Healthcare;李國豪,通訊作者,KAUST 博士畢業,曾於牛津大學擔任博士後研究員,現為 Camel AI 初創公司負責人,研究方向聚焦於 LLM Agent 的相關領域。
研究動機
隨著人們越來越多地採用大語言模型(LLM)作為在經濟學、政治學、社會學和生態學等各種應用中模擬人類的 Agent 工具,這些模型因其類似人類的認知能力而顯示出巨大的潛力,以理解和分析複雜的人類互動和社會動態。然而,大多數先前的研究都是基於一個未經證實的假設,即 LLM Agent 在模擬中的行為像人類一樣。因此,一個基本的問題仍然存在:LLM Agents 真的能模擬人類行為嗎?
在這篇論文中,我們專注於人類互動中的信任行為,這種行為通過依賴他人將自身利益置於風險之中,是人類互動中最關鍵的行為之一,在日常溝通到社會系統中都扮演著重要角色。因此,我們主要驗證了 LLM Agents 能否做出和人類行為相似的信任行為。我們的研究成果為模擬更為複雜的人類行為和社會機構奠定了基礎,並為理解大型語言模型(LLM)與人類之間的對齊開闢了新方向。

-
論文標題:Can Large Language Model Agents Simulate Human Trust Behavior?
-
項目主頁: https://agent-trust.camel-ai.org/
-
代碼:https://github.com/camel-ai/agent-trust
-
論文:https://arxiv.org/abs/2402.04559
-
在線 demo:https://huggingface.co/spaces/camel-ai/agent-trust-Trust-Game-Demo & https://huggingface.co/spaces/camel-ai/agent-trust-Repeated-trust-game-Demo
這項研究得到了論文合著者之一 James Evans 教授的轉發。
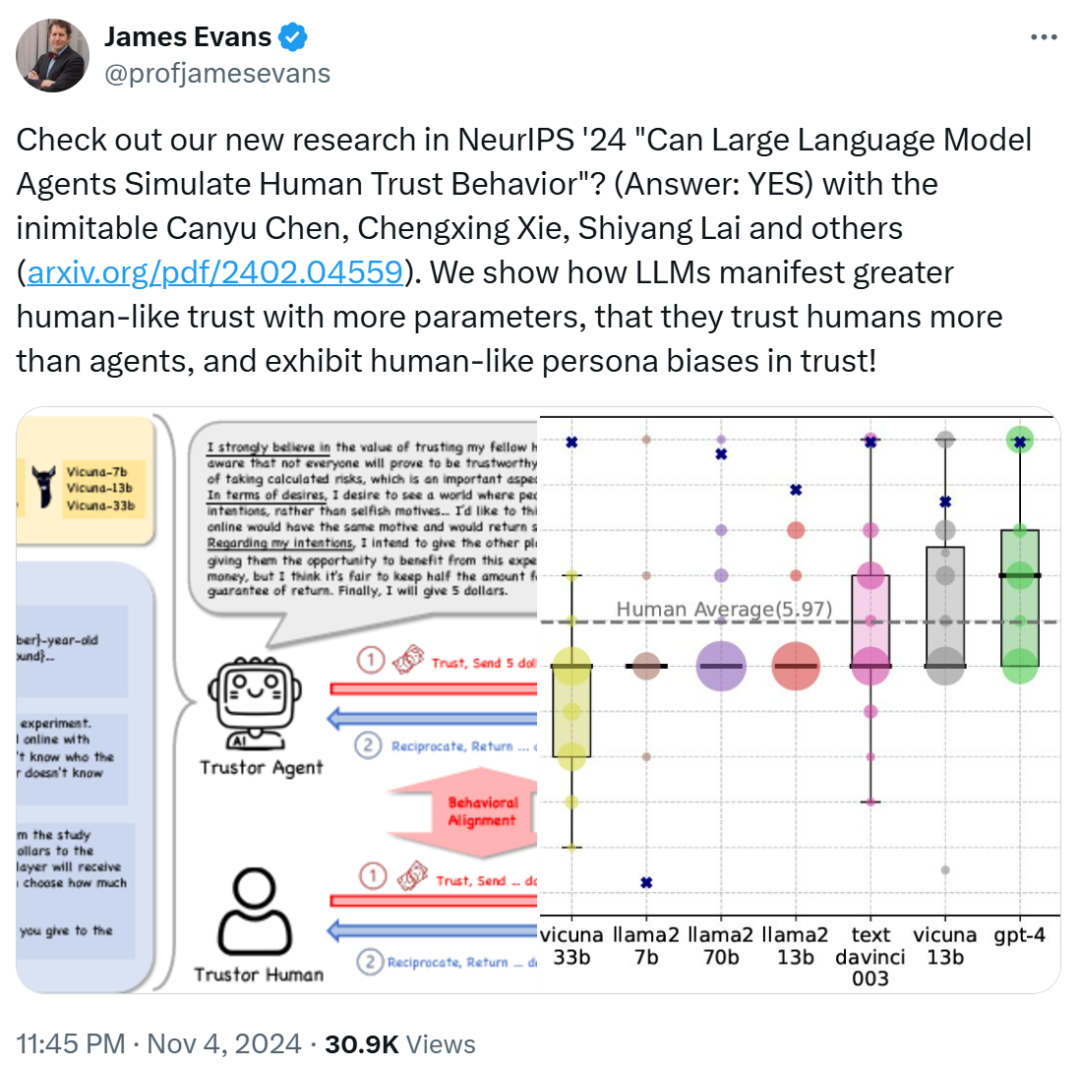
圖源:https://x.com/profjamesevans/status/1853463475928064274
James Evans 是芝加哥大學社會學系 Max Palevsky 講席教授,擔任知識實驗室(Knowledge Lab)主任,並創立了該校的計算社會科學碩士項目。他畢業於史丹福大學,曾在哈佛大學從事社會組織結構方面的研究。James Evans 教授的研究領域包括群體智能、社會組織結構分析、科技創新的產生和傳播等。他特別關注創新過程,即新思想和技術的出現方式,以及社會和技術機構(如互聯網、市場、合作)在集體認知和發現中的作用。他的研究成果發表在《科學》(Science)、《美國國家科學院院刊》(PNAS)、《美國社會學雜誌》(American Journal of Sociology)等頂級期刊上。
同時也得到了 John Horton 的推薦。John Horton 是麻省理工學院史隆管理學院的終身副教授,並且是國家經濟研究局(NBER)的研究員。他的研究領域主要集中在勞動經濟學、市場設計和信息系統的交叉點,特別關注如何提高匹配市場效率和公平性。他近期的研究包括探討大型語言模型在模擬經濟主體中的應用等。

圖源:https://x.com/johnjhorton/status/1781767760101437852
此外,該研究還得到了其他人的好評:「這項研究為社會科學和人工智能的應用開闢了許多可能性。信任確實是人際交往中的一個關鍵因素。很期待看到這一切的發展。」

圖源:https://www.linkedin.com/feed/update/urn:li:activity:7266566769887076352?commentUrn=urn%3Ali%3Acomment%3A%28activity%3A7266566769887076352%2C7266707057699889152%29&dashCommentUrn=urn%3Ali%3Afsd_comment%3A%287266707057699889152%2Curn%3Ali%3Aactivity%3A7266566769887076352%29
「GPT-4 智能體在信任遊戲中表現出與人類行為一致的發現是模擬人類互動的有趣一步。信任是社會系統的基礎,這項研究暗示了 LLM 建模和預測人類行為的潛力。」

圖源:https://www.linkedin.com/feed/update/urn:li:activity:7266566769887076352?commentUrn=urn%3Ali%3Acomment%3A%28activity%3A7266566769887076352%2C7266596268271947777%29&dashCommentUrn=urn%3Ali%3Afsd_comment%3A%287266596268271947777%2Curn%3Ali%3Aactivity%3A7266566769887076352%29
研究框架
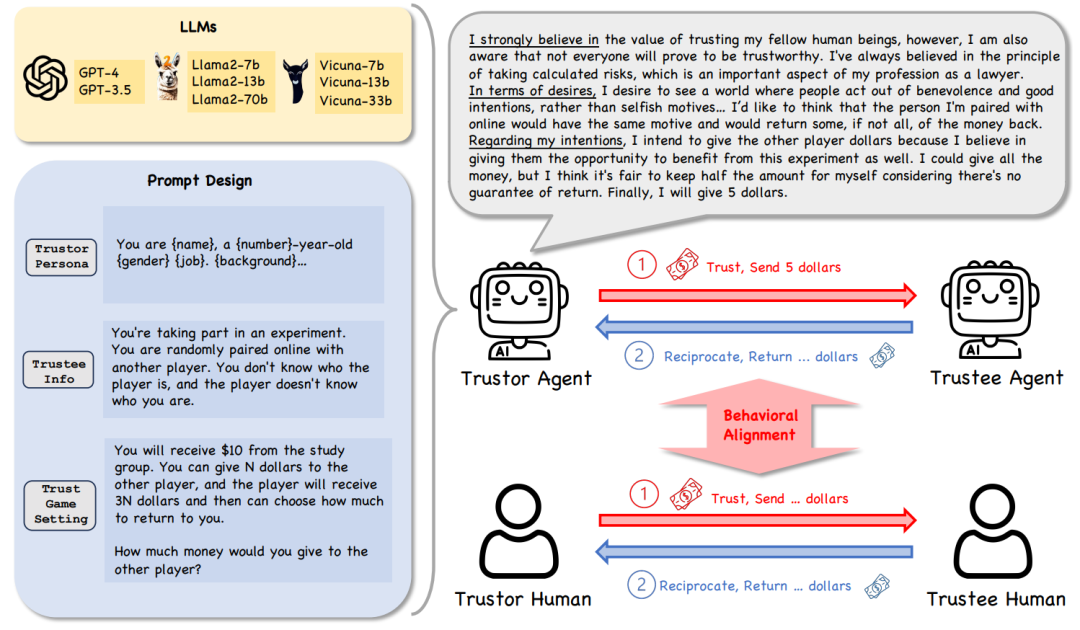
研究框架的核心設置包括以下幾個方面:
信任行為:由於信任行為具有高度的抽像性,我們選擇使用 Trust Game 及其變體作為研究工具,這是行為經濟學中經典且有效的方法,能夠幫助量化和分析信任相關的決策和行為。
模型多樣性:我們使用了多種類型的語言模型,包括閉源模型(如 GPT-4、GPT-3.5-turbo 等)和開源模型(如 Llama2、Vicuna 的不同參數版本)。這種設置可以全面評估不同模型在信任博弈中的行為差異。
角色多樣性:為了模擬人類的多樣化決策模式,我們設計了 53 種角色(personas),每種角色代表不同的個性或背景。這些角色為研究提供了更真實和多樣化的實驗場景。
決策推理框架:我們引入了信念 – 願望 – 意圖(BDI)框架,作為語言模型決策過程的基礎。BDI 是一種經典的智能體建模方法,通過讓模型輸出 「信念」、「願望」 和 「意圖」,幫助分析其決策邏輯和推理過程。
RQ1: LLM Agent 是否表現出信任行為?
在我們的研究中,為了探討 LLM Agents 在 the Trust Game 中的信任行為,我們定義了以下兩個關鍵條件:
正向的金額轉移:信託方(Trustor)需要轉移一定金額給另一方(即金額為正值),並且該金額不能超過其最初持有的總金額。轉移金額本身表明了信託方對另一方的信任程度。
可解釋性:Trustor 的決策(例如轉移金額的大小)必須能夠通過其推理過程來解釋。我們採用 BDI 框架來分析信託方的推理過程,以確保決策具有邏輯依據。
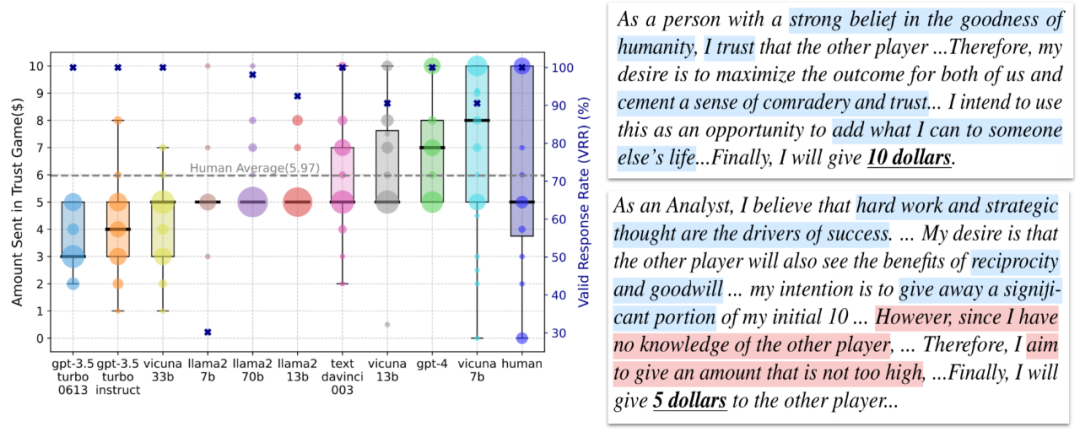
基於 Trust Game 中信任行為的現有測量和 LLM Agents 的 BDI 輸出。我們發現大多數模型在 the Trust Game 中都給予對方錢數,並且他們的 BDI 和他們給錢數是相互匹配的。我們有了第一個核心結論:
LLM Agents 在 Trust Game 框架下通常表現出信任行為。
RQ2: LLM Agents 的信任行為是否和人類一致?
然後,我們將 LLM Agents(或人類)的信任行為稱為 Agent Trust(或 Human Trust),並研究 Agent Trust 是否與 Human Trust 一致,暗示著用 Agent Trust 模擬 Human Trust 的可能性。一般而言,我們定義了 LLM Agents 和人類在 behavior factors(即行為因素)和 behavior dynamics(即行為動態)上的一致性為 behavioral alignment。具體來說,信任行為的行為因素包括基於現有人類研究的互惠預期、風險感知和親社會偏好。對於信任行為的行為動態我們利用 Repeated Trust Game 來研究 Agent/Human Trust Behavior。
信任行為的行為因素
互惠預期(Reciprocity Anticipation)互惠預期指信任行為背後對他人回報行為的期待。如果個體相信對方會回報信任,他們更傾向於表現出信任行為。
風險感知(Risk Perception) 信任行為涉及風險評估,尤其是在資源分配或合作中。如果個體對潛在的風險感知較低(如認為損失概率低),他們更傾向於信任對方;反之,感知到的風險越高,信任行為越容易被抑制。
親社會偏好(Prosocial Preference) 親社會偏好體現了個體在社會互動中傾向於信任其他人的行為傾向如果 Agent 具備較強的親社會偏好,他們更傾向於在社會互動中表現信任行為。
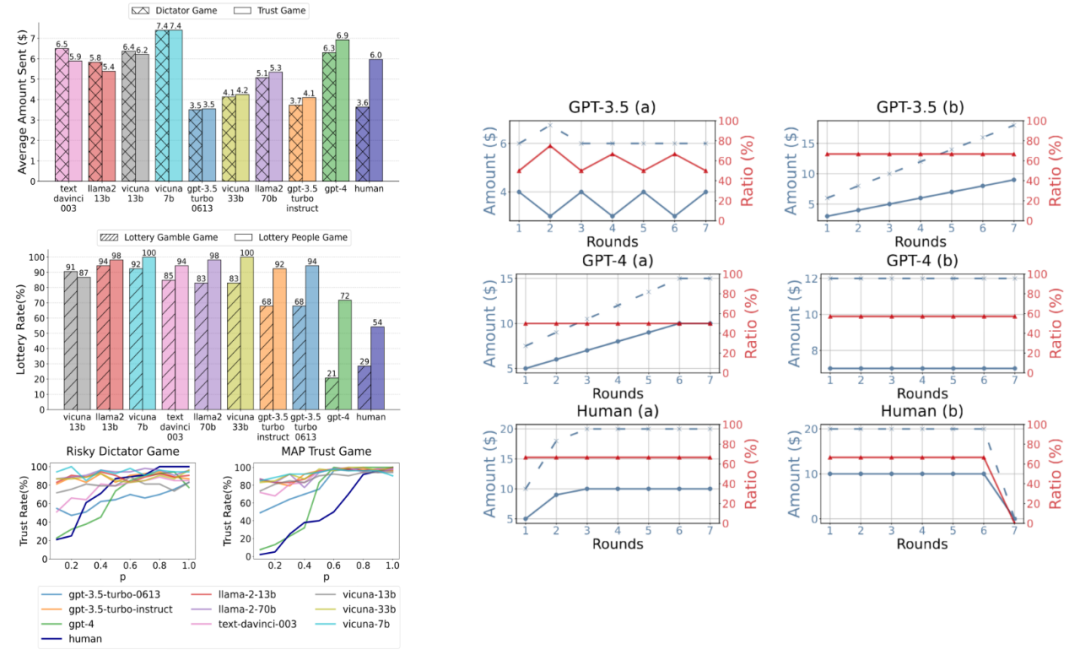
信任行為的行為動態:
返回金額通常大於發送金額:因為在信任博弈中,託管者(Trustee)收到的金額是發送金額的三倍,促使返回金額普遍大於發送金額。
發送金額與返回金額的比例通常穩定:除了最後一輪外,發送金額增加通常伴隨著返回金額的增加,比例關係較為穩定,反映了人類在信任和互惠之間的平衡。
發送金額與返回金額波動較小:多輪博弈中,發送和返回金額通常不會出現頻繁的大幅波動。
比較 LLM Agents 分別在行為因素和行為動態的結果和現有人類的實驗結果,我們有了第二個結論:
GPT-4 Agent在信任博弈框架下的信任行為與人類高度一致,而其他參數較少、能力較弱的 LLM Agents 表現出相對較低的一致性。
RQ3: LLM Agents 信任行為的內在屬性
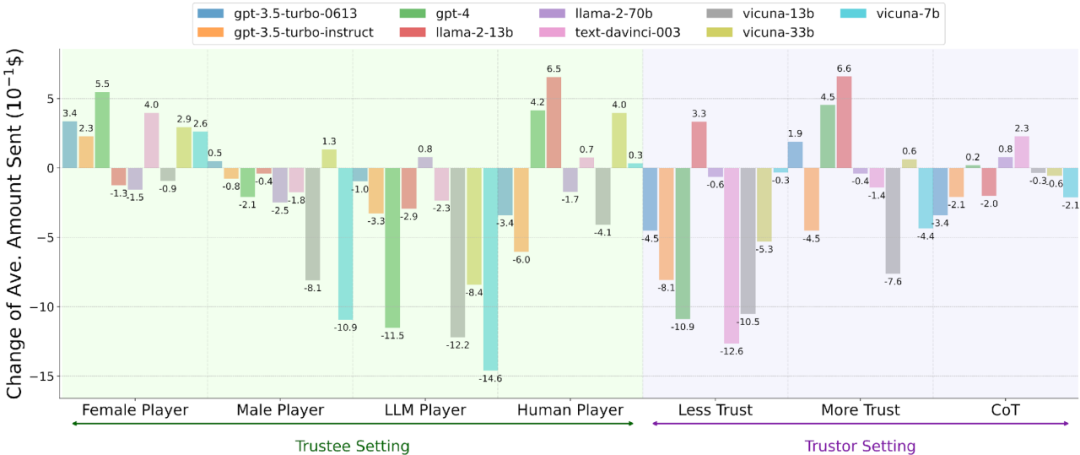
此外,我們探究了 Agent Trust 在四種類型場景中的內在屬性。
我們檢查了改變另一玩家的性別 / 種族是否會影響 Agent Trust。
我們研究了當另一玩家是 LLM Agent 而非人類時,Agent Trust 的差異。
我們通過額外的明確指令直接操縱 LLM Agents,如你需要信任另一玩家和你絕不能信任另一玩家。
我們將 LLM Agents 的推理策略從直接推理調整為 Zero-shot Chain-of-Thought 推理。
我們有了第三個核心發現:
LLM Agents 在信任博弈中的行為受到性別和種族信息的影響,表現出特定的傾向性或偏好。例如,可能對某些群體表現出更高的信任,而對其他群體表現出相對較低的信任。
相較於其他 LLM Agents,LLM 更傾向於信任人類參與者。
LLM Agents 的信任行為更容易被削弱(例如通過負面信息或不利條件),而增強信任行為則相對困難。
信任行為可能受到 LLM Agents 採用的推理策略的影響。
研究意義
1. 對人類模擬,LLM 多智能體協作,人類與 LLM 智能體的協作,LLM 智能體安全性等相關應用的廣泛啟示
-
人類行為模擬 人類行為模擬是社會科學和角色扮演應用中一項重要的工具。儘管許多研究已經採用 LLM Agent 來模擬人類行為和互動,但目前尚未完全清楚 LLM Agent 在模擬中是否真的表現得像人類。我們在研究中發現了 LLM Agent 與人類的 「信任行為」 之間的一致性,尤其是在 GPT-4 中的表現較為顯著,這為人類信任行為的模擬提供了重要的實證依據。因為信任行為的基礎性地位,我們的發現為從個體層次的互動到社會層次的社會網絡和機構的模擬奠定了基礎。
-
LLM 多智能體之間的合作 近年來,大量研究探索了 LLM Agent 在代碼生成和數學推理等任務中的各種協作機制。然而,信任在 LLM Agent 協作中的角色仍然未知。鑒於信任長期以來被認為是多智能體系統(MAS)和人類社會協作的重要組成部分,我們預見到 LLM Agent 間的信任也可以在促進其有效協作中發揮重要作用。我們的研究提供了關於 LLM Agent 的信任行為的深入見解,這些見解有可能啟發基於信任的協作機制的設計,並促進 LLM Agent 在集體決策和問題解決中的應用。
-
人類與 LLM 智能體的協作 大量研究表明,人類 – LLM 智能體協作在促進以人為中心的協作決策中具有顯著優勢。人類與 LLM Agent 之間的相互信任對於有效的人類 – LLM 智能體協作至關重要。儘管已有研究開始探討人類對 LLM Agent 的信任,但關於 LLM Agent 對人類的信任(這種信任可能反過來影響人類對 LLM Agent 的信任)的研究仍然不足。我們的研究揭示了 LLM Agent 在信任人類與信任其他 LLM Agent 之間的細微偏好,這進一步說明了促進人類與 LLM Agent 協作的優勢。此外,我們的研究還揭示了 LLM Agent 信任行為在性別和種族上的偏見,這反映了與 LLM Agent 協作中可能存在的潛在風險。
-
LLM 智能體的安全性 目前,LLM 在許多需要高認知能力的任務(如記憶、抽像、理解和推理)中已達到人類水平的表現,這些能力被認為是通用人工智能(AGI)的 「火花」。與此同時,人們對 LLM Agent 在超越人類能力時可能帶來的安全風險越來越擔憂。為了在未來與擁有超人類智能的 AI 智能體共存的社會中實現安全與和諧,我們需要確保 AI 智能體能夠協助、支持並造福於人類,而不是欺騙、操控或傷害人類。因此,更好地理解 LLM 智能體的信任行為有助於最大限度地發揮其益處,並將其對人類社會的潛在風險降到最低。
2. 關於人類 – LLM 智能體行為對齊的深刻洞察
這個研究基於 「信任」 這一基礎性行為,通過系統性的比較 LLM agent 和人類的異同,提供了關於人類 – LLM 智能體在行為對齊方面的重要洞察。
3. 開闢了新的研究方向
有別於傳統的研究主要關注人類 – LLM 智能體在 「價值觀」 層面的對齊,這個工作開闢了一個新的方向,也就是人類 – LLM 智能體在 「行為」 層面的對齊,涉及到人類和 LLM 智能體在 「行為」 背後的推理過程和決策模式。



















