數字比你想得更複雜——一文帶你瞭解大模型數字處理能力的方方面面
AIxiv專欄是機器之心發佈學術、技術內容的欄目。過去數年,機器之心AIxiv專欄接收報導了2000多篇內容,覆蓋全球各大高校與企業的頂級實驗室,有效促進了學術交流與傳播。如果您有優秀的工作想要分享,歡迎投稿或者聯繫報導。投稿郵箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
目前大語言模型(Large Language Models, LLMs)的推理能力備受關注。從思維鏈(Chain of Thought,CoT)技術提出,到以 o1 為代表的長思考模型發佈,大模型正在展現出接近人類甚至領域專家的水平,其中數學推理是一個典型任務。
然而,與大模型能夠理解和求解各種複雜數學問題相對的,是其羸弱的數字處理能力。儘管大模型能夠提出看似合理的解決方案,但在實際運算之中,卻常常難以在不借助工具的情況下計算出準確的數值結果。此前引發廣泛討論的 「9.11>9.9」 就是典型例子。這種 「事實幻覺」 已經成為製約大模型實際應用的一個重大障礙。
過去的研究工作很少將 「數字理解和處理能力」(Number Understanding and Processing,NUPA)作為獨立任務進行研究。以往的研究更多聚焦於數學推理,涉及數學工具和定理應用,例如 GSM8K。對於數字本身的基礎理解和處理,如四則運算、比較大小、數位提取等,鮮有研究將其單獨衡量。同時,在現有的數學數據集中,數字相關的部分往往被簡化處理。許多數據集中的數字通常僅限於簡單的整數和小數,而較長的整數、小數和分數等較複雜的數字形式往往被忽視,這與現實中複雜多變的應用場景存在較大差距。實際應用中,若遇到涉及更複雜任務的情況,如金融、物理等領域的應用,這種簡化後的數字能力可能無法有效應對。
儘管大模型可以通過調用外部計算器一定程度上彌補數字處理能力的不足,這個問題本身仍然值得深入探討。首先,考慮到數字處理作為各種複雜推理的基礎,在涉及高頻數字處理的情況下頻繁調用外部工具會顯著減慢模型響應,模型應當具備自我解決較為簡單問題的能力(如判斷 9.11 < 9.9)。更重要的是,從發展通用人工智能的角度出發,如果模型不具備最基礎的數字理解能力而只能依賴計算器,那麼不可能指望其真正掌握複雜推理、幫助人類發現新定理或發明新工具,達到人類級別的通用智能更是無從談起。這是因為,人類正是在充分理解、掌握數字和運算的基礎上才發明的計算器。
近日,北京大學張牧涵團隊在投稿至 ICLR-2025 的論文中,關注了這一問題。作者將數字理解和處理能力(number understanding and processing ability, NUPA)從數學或常識推理能力等任務中分離出來,單獨衡量大模型的數字能力。基於中小學數學課本範圍,作者提出了一個涉及四種數字表式(整數、浮點數、分數、科學計數法)和四個能力範疇下的 17 個任務類型,共計 41 個數字理解和處理任務的基準集 NUPA(圖 1)。這些任務基本覆蓋了日常生活中常用的數學知識(如計算、大小比較、單位轉換、位操作等),亦是支撐 AGI 的必要能力之一。

-
論文標題:Number Cookbook: Number Understanding of Language Models and How to Improve It
-
論文地址:https://arxiv.org/abs/2411.03766
-
項目主頁:https://github.com/GraphPKU/number_cookbook

圖 1:NUPA benchmark 的 41 個任務;其中√表示包括的任務;—, O, X 分別表示因不適用、可由其它任務組合得到、以及因過於複雜而不實際,而被排除的任務。
現有大模型性能測試
作者首先在不借助額外工具和思維鏈幫助的情況下,測試了模型在不同難度(數字長度)下的表現。部分結果如圖 2 所示,準確率根據生成的數字與基準答案的嚴格一致來評估。測試涵蓋了多種常見的大模型,包括 GPT-4o、Llama-3.1、Qwen(千問)-2、Llama-2、Mixtral。測試結果顯示,最新的大模型在常見的數字表示、任務和長度範圍表現良好。如圖 2 所示,在整數加法這一典型任務上,以及較短數字長度(1-4 位)情況下,各模型的準確率均超過 90%,其中,GPT-4o、Qwen2-72B 等模型甚至達到了接近 100% 的準確率。在浮點數加法、整數大小比較、整數長度判斷等任務上,各模型也普遍展現出超過 90% 的準確率。

圖 2:在經典任務和較短數字範圍內上模型性能普遍較好,其中加法任務為 1-4 位,其餘任務為 1-10 位的結果。
然而,涉及稍微複雜或者不常見的數字表示或任務時,模型的性能明顯下降。圖 3 進一步展示了部分任務上的準確率,S、M、L、XL 分別對應從短到長不同的數字長度範圍(所示任務分別對應 1-4 位、5-8 位、9-14 位、15-20 位)。儘管大部分模型在較短的數位範圍內能夠較好地解決整數和浮點數的加法問題,但在分數和科學計數法的加法上,模型的表現很差,準確率普遍低於 20%。此外,當任務涉及乘除運算、取模運算等稍微複雜的運算時,即使是在較短的長度範圍內,大模型也難以有效解決問題。


圖 3:部分任務的結果顯示,大模型在處理少見任務和長數字時存在困難。
同時,數字長度仍然是大模型尚未解決的難題,從圖 3 中可以看出,隨著數字長度的增加,模型性能明顯下降。以整數加法為例,當輸入數字長度達到 9-14 位(即圖中 L 範圍)時,除 GPT-4o 和 Qwen2-72B 的準確率維持在約 40% 外,其餘模型的準確率僅約為 10%;而當涉及 15-20 位整數的加法(圖中 XL 範圍)時,GPT-4o 和 Qwen2-72B 的性能進一步下降至約 15%,其餘模型幾乎無法給出正確答案。
此外,這一測試還發現大模型在處理最簡單的數位相關任務時存在明顯不足。具體而言,在諸如 「數字長度」(length)、「返回給定數位的數字」(get digit)、「數位比較大小」(digit max)等任務上,模型的表現均不能令人滿意,尤其是在數字較長時,性能下降尤為明顯。例如,當詢問一個長 60-100 位長整數的長度和特定數位的數字時,包括 GPT-4o 在內的模型準確率均不超過 20%;而在 digit max 任務上,幾乎所有模型均無法正確回答。考慮到數位是數字處理中的基本概念,這表明現有大模型在數字處理上存在本質缺陷,這也可能是模型在實際任務中頻繁出現 「事實幻覺」 的原因。

圖 4:和數位相關的任務性能。
作者在原文中還提供了更多的觀察,並基於更多任務、長度範圍和準確度度量的進行了分析。此外,考慮到該測試涉及數字表示、任務類別、數字長度和度量等多個方面,作者還提供了一個可交互式的網站,便於更清楚地展示結果,詳情請訪問:https://huggingface.co/spaces/kangshijia/NUPA-Performance。
提升大模型數字能力的三個方面
測試結果顯示,現有大模型在數字理解和處理方面存在系統性不足。為此,作者研究了提升大模型數字理解能力的三個方向,包括預訓練階段的數字相關技術、預訓練後的微調,以及思維鏈技術。
預訓練中分詞器對數字性能的影響
首先,一種普遍的猜想是,大模型在數字能力上的薄弱與其對數字的分詞(tokenization)方式有關。目前大多數流行的大模型由於詞彙表固定,需要將長數字分拆為多個 token,這種方式可能會削弱模型對數字的理解。在早期的 GPT-2 和 GPT-3 等模型中,採用的 BPE tokenizer 對數字分詞沒有特殊優化。這種分詞方式會生成不固定長度的數字 token,研究已證明這對大模型的數位對齊有負面影響 [1]。後續的 Llama 等模型均採用了從左到右的貪心式分詞器,其機制是對於預設的最大長度 k,從左到右依次截取 k 個數字組成一個 token,直至遇到非數字字符為止。在 k 的選取上,較早的 Llama-2 模型採用 k=1,即每個數位作為一個 token 的策略;而更新的 GPT-3.5,GPT-4 和 Llama-3 均選取了 k=3 的策略。近來的研究 [1] 又進一步改進了分詞方向,將整數部分的分詞方向改為從右到左,以更貼合人類對數字的理解習慣。

圖 5:四種不同的分詞器設計,從上到下分別為(a)GPT-2 使用的未經處理的 BPE 分詞器、(b)Llama-2 使用的單數位分詞器、(c)Llama-3 和 GPT-3.5、GPT-4 使用的 3 數位貪心分詞器,以及(d)改進對齊後的 3 數位分詞器。
儘管針對分詞器的設定有所不同,但最新模型普遍傾向於使用更大的詞彙表,即更大 k 和更長的 token。然而,這一趨勢未經充分驗證和解釋。為此,作者基於 NUPA 提供的數據集,針對不同的分詞器大小進行了系統驗證。實驗中,作者改進對齊分詞器,設置 k 為 1、2、3,分別訓練不同參數規模的 Transformer 模型,並在 1-8 位整數或浮點數的加法、乘法等任務上進行學習,再測試其在 1-20 位數字任務上的性能。實驗結果顯示(圖 6),無論是在訓練的數字長度範圍內(in-domain)還是超出訓練長度(out-of-domain)的長度泛化性能上,詞彙表更小的分詞器(k=1)的性能均優於或接近 2 位或 3 位分詞器,同時具備更快的收斂速度。

圖 6:以整數乘法為例,1-3 位分詞器的性能對比;橫軸為訓練所見樣本數,縱軸為生成準確率;從左到右分別為 6 位 – 10 位數字加法的測試集準確率。
此外,作者還研究了最近提出的概率分詞器(即在分詞時不採用貪心算法,而是隨機取不超過 k 個數字組成一個 token)。實驗結果表明,儘管概率分詞器在長度泛化上表現出一定優勢,但總體性能仍然不如一位分詞器。綜上,作者認為,目前流行的擴大數字詞彙表的傾向實際上不利於數字處理,相反,更早期的一位分詞器可能才是更優選項。
其它預訓練中的數字相關技術
除分詞器的影響之外,過去的研究還從位置編碼(positional encoding,PE)和數字格式等角度分析了數字能力,特別是在數字的長度泛化方面。作者在 NUPA 任務上測試了這些典型技術,結果顯示:
從位置編碼的角度,以 NoPE 和 Alibi 為代表的改進型位置編碼能夠有效解決長度泛化問題。這些方法適用於多種數字表示和任務類型,雖然會犧牲一定的訓練速度,但能提升模型在超出訓練長度範圍時的性能。
針對數字格式,研究發現補零對齊(zero-padding)和反向數字表示(reverse representation)等技術有助於數位對齊。其中,僅針對整數部分進行反向表示能夠顯著提升結果。這一部分的結論較多,感興趣的讀者可以參考原文進行深入閱讀。

圖 7:一些用於幫助數位對齊的數字表示。
後訓練微調對數字性能的影響
微調是提升大模型在特定任務上表現的常見方法。作者針對 NUPA 進行了微調實驗,使用 NUPA 提供的 41 個任務構建了包括多種數字表示、任務類型和數字長度的訓練集,並在 Llama-3.1-8B 基礎上進行參數高效微調(Parameter-Efficient Fine-Tuning, PEFT)。為了測試數字長度上的泛化性能,作者只選擇了 S 和 M 兩個長度範圍進行訓練,並在 S、M、L、XL 四個長度範圍內進行測試。
訓練結果表明,模型通過少量的訓練步數(約兩千步)即可顯著提升性能,如圖 6 所示,經過微調的模型在多個任務上表現明顯優於未經微調的 Llama-3.1-8B 模型;在一些任務上,微調後的模型甚至接近 GPT-4o 或超過了 GPT-4o 的性能。這表明,模型在某些任務上表現較差的原因可能是缺乏足夠多樣的任務和數字表示訓練數據。增加這些數據有望改善模型表現。然而,即使經過微調,該模型的準確率也未能達到在整個區間上達到接近 100% 的水平。


圖 8:經過微調的模型和其它模型的對比,其中 – ft 表示經過微調的模型。
然而,在後訓練階段,嘗試通過微調調整位置編碼、分詞策略或數據格式的實驗並未得到正面結果。具體而言,作者在微調階段嘗試修改原始模型使用的位置編碼、分詞器,或採用修改後的數字格式,但不同技術組合的微調結果均不如直接微調的結果,且改動越多性能下降越明顯。作者認為,這可能與預訓練階段與微調階段之間的差異過大有關。這表明,目前提出的大部分技術無法在微調階段直接使用,因此必須在預訓練階段就考慮使用。
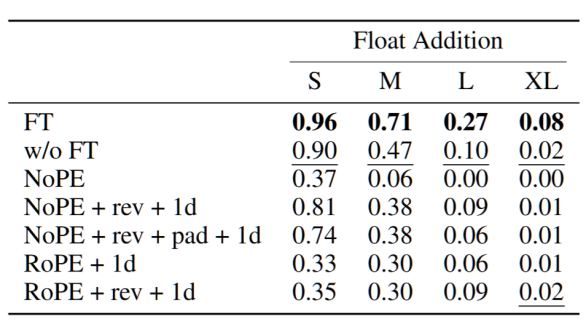
圖 9:以浮點數加法為例,其中 rev 表示數字反向表示、pad 表示數字首位補零對齊,1d 表示使用 1 位 tokenizer;FT 和 w/o FT 分別為直接進行微調和不使用微調的原始參數。模型均採用 Llama-3.1-8B,可以看到所有組合的結果都劣於直接進行微調。
思維鏈是否足以解決數字處理難題
上述實驗是在不使用思維鏈的情況下進行的,考慮到數字處理任務通常是更複雜任務的基礎,生成思維鏈可能會導致過長的輸出或分心。然而,考慮到思維鏈方法對推理任務普遍有效,作者進一步測試了思維鏈技術是否能夠解決數字處理問題。
具體而言,作者採用了一種名為 「規則跟隨」(Rule-Following)的思維鏈範式,將明確的計算規則以代碼的方式提供給大模型,模型微調後按照這些規則解決問題。實驗結果表明,訓練得到的具有規則跟隨能力的模型性能上普遍超過 GPT-4o 及一般微調的 Llama-3.1-8B。然而,該模型的推理時間、顯存開銷較大,使用思維鏈生成的平均耗時是直接生成的 10 倍以上,且容易受到顯存或上下文長度限制,導致無法解決較長的問題。這表明,思維鏈技術並非解決數字處理問題的萬能方法。

圖 10:規則跟隨的思維鏈大模型具有遠超直接生成的性能,但受到長度限制明顯,「-」 表示在兩千個 token 限制內無法生成答案。

圖 11:指令跟隨的思維鏈大模型的平均耗時普遍在 10 倍以上。
總結
本文提出了一系列獨立於數學問題和常識問題之外的數字理解和處理任務,涵蓋了 4 種數字表示和 17 種任務類型,並對常見的大模型進行了評測。結果表明,現有大模型在數字理解和處理方面的性能仍然局限於最常見的任務和較短的數字範圍。作者從預訓練技術、訓練後微調和思維鏈三個方面探索了提升數字處理能力的可能性。儘管一些方法在提升模型性能上有一定效果,但仍存在不足,離徹底解決數字處理問題還有一定距離。
作者指出,大模型目前被視為通向 AGI 的重要工具,儘管其在解決最複雜問題的高級能力方面備受關注,但 「數字處理」 等基礎能力的研究同樣不可忽視,否則推理和思維將成為空中樓閣。作者希望本文提供的任務和數據集能夠為大模型提升數字處理能力提供有力支持,並以此為基礎進一步加強其在數學等領域的表現。這些任務和數據集,可以有效地為預訓練過程中引入更多樣的數字相關任務提供參考,也可以啟發更好的數字分詞、編碼、格式處理等新技術的提出。
[1] Aaditya K. Singh, DJ Strouse, Tokenization counts: the impact of tokenization on arithmetic in frontier LLMs. 2024



















