田淵棟團隊論文火了!連續思維鏈優於CoT,打開LLM推理新範式
機器之心報導
機器之心編輯部
一個非常簡單的更改,就能提高 LLM 推理能力。
在認知科學領域,關於語言是用於思考還是用於交流的辯論一直持續。
隨著 LLM 和 CoT 的興起,語言已經成為機器推理的預設媒介 —— 但它真的是最佳方法嗎?
一般而言,LLM 被限制在語言空間(language space)內進行推理,並通過思維鏈(CoT)來表達推理過程,從而解決複雜的推理問題。
然而,語言空間可能並不總是最適合推理的。例如,很多單詞 token 主要用於文本連貫性,而不是推理本身,而一些關鍵 token 則需要複雜的規劃,這種差異給 LLM 帶來巨大的挑戰。
為了探索 LLM 在不受限制潛在空間中的推理潛力,而非使用自然語言,來自 Meta、加州大學聖地亞哥分校的研究者提出了一種新的範式 ——Coconut(連續思維鏈,Chain of Continuous Thought),來探索 LLM 在潛在空間中的推理。

-
論文標題:Training Large Language Models to Reason in a Continuous Latent Space
-
論文地址:https://arxiv.org/pdf/2412.06769
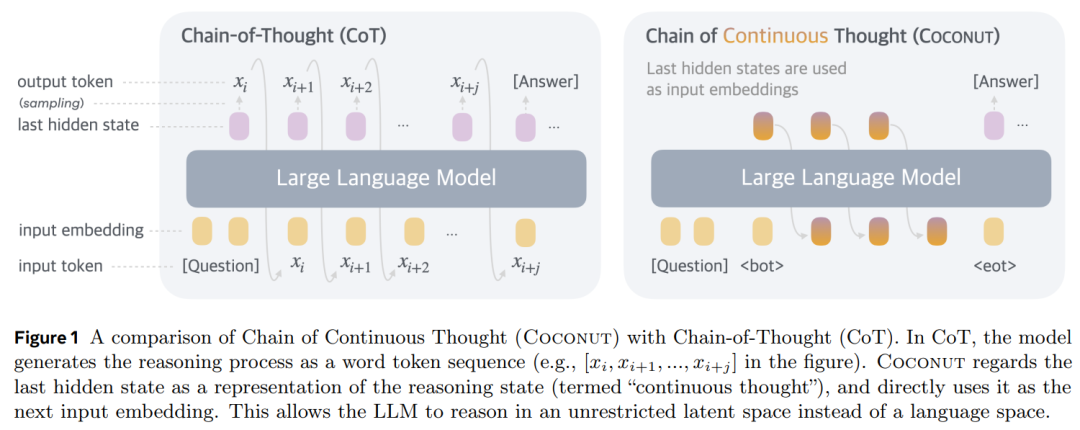
Coconut 涉及對傳統 CoT 過程的簡單修改:Coconut 不再通過語言模型頭(language model head)和嵌入層將隱藏狀態與語言 token 進行映射,而是直接將最後的隱藏狀態(即連續思維)作為下一個 token 的輸入嵌入(如圖 1 所示)。
這種修改將推理從語言空間中解放出來,並且由於連續思維是完全可微的,因此可以通過梯度下降對系統進行端到端優化。為了增強潛在推理的訓練,本文採用了多階段訓練策略,該策略有效地利用語言推理鏈來指導訓練過程。
這種範式帶來了高效的推理模式,與基於語言的推理不同,Coconut 中的連續思維可以同時編碼多個潛在下一步,從而實現類似於 BFS(breadth-first search)的推理過程。儘管模型在初始階段可能做出不正確的決策,但它可以在連續思維中保持許多可能的選項,並通過推理逐步排除錯誤路徑,這一過程由一些隱含的價值函數引導。這種高級的推理機制超越了傳統的 CoT,即使模型並沒有顯式地接受訓練或指示以這種方式操作。
實驗表明,Coconut 成功增強了 LLM 的推理能力。對於數學推理(GSM8k),使用連續思維被證明有利於提高推理準確率,這與語言推理鏈的效果相似。通過鏈接更多連續思維,可以擴展和解決日益具有挑戰性的問題。
在邏輯推理方面,包括 ProntoQA 和本文新提出的 ProsQA,這需要更強的規劃能力,Coconut 及其一些變體甚至超越了基於語言的 CoT 方法,同時在推理過程中生成的 token 明顯更少。
這項研究在 X 上的討論量非常高,其中單人轉發的瀏覽量就高達 20 多萬。

連續思維鏈:Coconut
方法概述。在 Coconut 方法中,LLM 在語言模式和潛在模式之間切換(圖 1):
-
在語言模式下,該模型作為標準語言模型運行,自回歸生成下一個 token。
-
在潛在模式下,它直接利用最後一個隱藏狀態作為下一個輸入嵌入。這個最後的隱藏狀態代表當前的推理狀態,稱為連續思維。
特殊 token < bot >、< eot > 分別用於標記潛在思維模式的開始和結束。
訓練。本文專注於問題 – 解決設置,其中模型接收問題作為輸入,並通過推理過程生成答案。作者利用語言 CoT 數據來監督連續思維。如圖 2 所示,在初始階段,模型在常規 CoT 實例上進行訓練。在後續階段,即第 k 階段,CoT 中的前 k 個推理步驟被替換為 k × c 個連續思維,其中 c 是一個超參數,用於控制替換單個語言推理步驟的潛在思維的數量。

推理過程。Coconut 的推理過程類似於標準的語言模型解碼過程,不同之處在於,在潛在模式下,本文直接將最後一個隱藏狀態作為下一個輸入嵌入。這樣做面臨的挑戰是確定何時在潛在模式和語言模式之間切換。當專注於問題 – 解決設置時,本文會在問題 token 後立即插入一個 < bot >token。對於 < eot >,作者考慮兩種潛在策略:a) 在潛在思維上訓練二元分類器,使模型能夠自主決定何時終止潛在推理,或 b) 始終將潛在思維填充到恒定長度。本文發現這兩種方法效果都相當好。除非另有說明,本文在實驗中使用第二種選項以簡化操作。
實驗
研究團隊通過三個數據集驗證了大語言模型在連續潛空間中進行推理的可行性。實驗主要評估模型生成答案的準確性和推理效率。
實驗涉及兩類主要任務:數學推理和邏輯推理。數學推理使用 GSM8k 數據集。邏輯推理則採用了兩個數據集:5-hop ProntoQA 與該團隊自行開發的 ProsQA。
ProntoQA 給出一個層級分類的知識結構,要求模型判斷不同類別之間的從屬關係是否正確。而 ProsQA 中是更具挑戰性的推理任務,包含許多隨機生成的有向無環圖,要求模型進行大量規劃和搜索。
實驗設置
在實驗設置方面,研究採用預訓練的 GPT-2 模型,學習率為 1×10^−4,批量大小為 128。
對於數學推理任務,每個推理步驟使用 2 個潛在思維向量表示,整個訓練過程分為 4 個漸進式階段。
在邏輯推理任務中,每步使用 1 個潛在思維向量,訓練分為 7 個漸進式階段,逐步增加難度。所有實驗均在標準訓練流程後繼續訓練至第 50 輪,並通過在驗證集上評估準確率來選擇性能最佳的模型檢查點用於最終測試。
基線方法和各種版本的 Coconut
為了全面評估方法效果,研究團隊設置了以下基線方法進行對比:
1. 傳統的 CoT:使用完整的思維鏈進行訓練,讓模型生成每一步的推理過程
2. No-CoT:模型直接生成最終答案,不要求中間推理步驟
3. iCoT:採用漸進式策略,逐步移除推理鏈中的步驟
4. Pause token:在問題和答案之間插入特殊的暫停 token
同時,他們還評估了 Coconut 的三個變體版本:
1. 無課程學習版本:跳過漸進訓練,直接採用最終階段的訓練方式
2. 無思維版本:移除連續思維表示,僅保留分階段訓練機制
3. 思維替換版本:用特殊 token 替代連續思維的表示方式
結果與討論
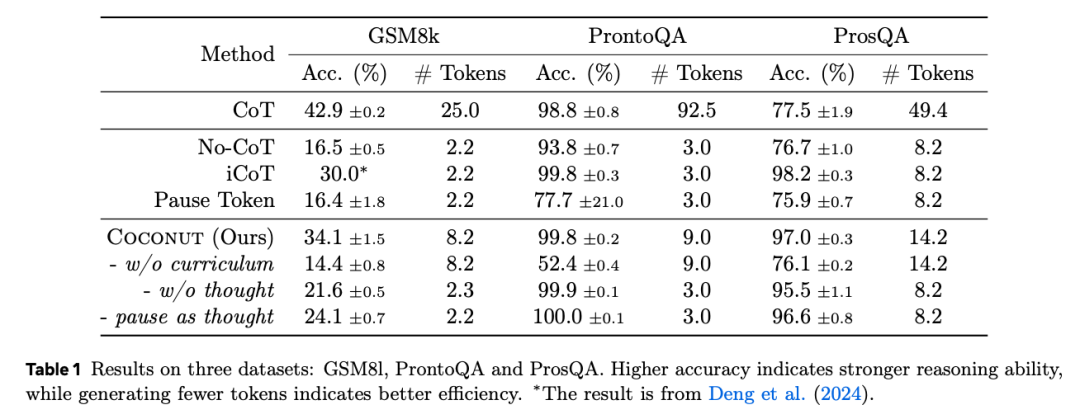
表 1 展示了所有數據集的整體結果。連續思維有效增強了大語言模型的推理能力,這從其相比無 CoT 基線的一致性提升可以看出。在 ProntoQA 和 ProsQA 上,其表現甚至超過了 CoT。
研究團隊從實驗中得出了以下幾個關鍵結論:
連續思維的「鏈式」組合增強了推理能力。
在傳統 CoT 中,輸出 token 會作為下一步的輸入,這被既有的研究證明可以增加模型的有效深度和表達能力。
該團隊進一步探索了這一特性是否也適用於潛空間推理,因為這意味著這種方法可以通過鏈接多個潛在思維來解決更複雜的問題。
在 GSM8k 數據集的實驗中,Coconut 的表現優於其他採用類似策略訓練的架構,特別是超過了最新的 iCoT 基線,也顯著優於同樣能增加計算能力的 Coconut(pause as thought)變體。
雖然此前的研究已經證明特殊的 token 可以解決高度並行化的問題,該研究團隊的結果顯示 Coconut 架構在一般問題上更有效,比如數學應用題這種後續步驟高度依賴前序步驟的問題。
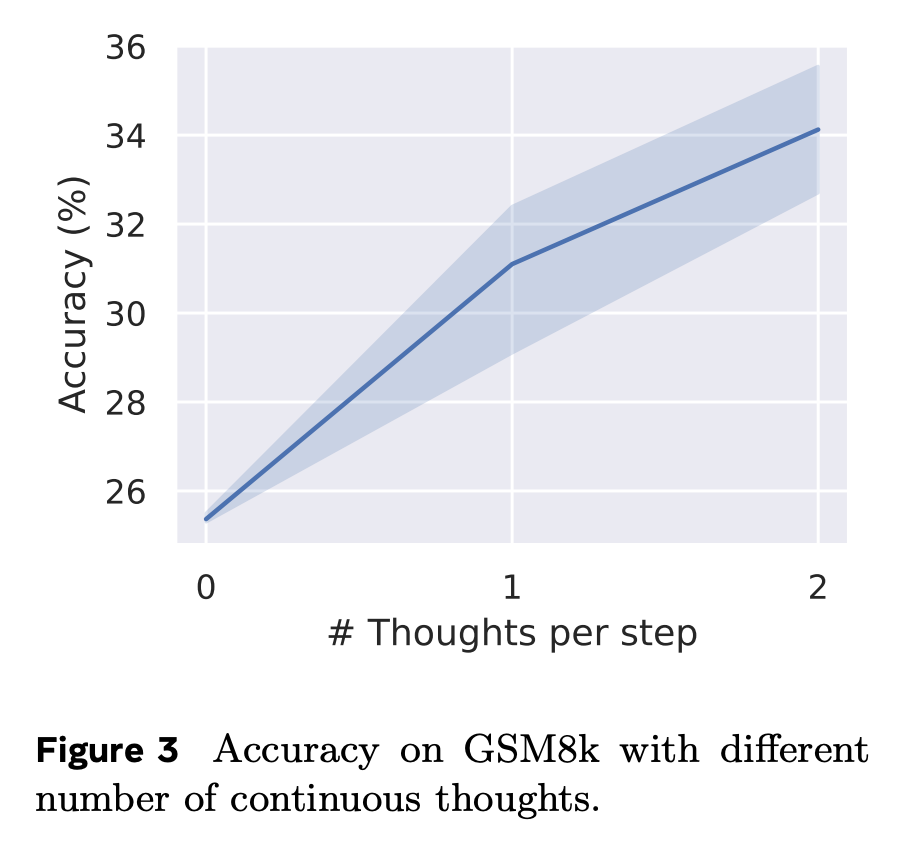
此外,當調整控制每個語言推理步驟對應潛在思維數量的參數 c 時(見圖 3),隨著 c 從 0 增加到 1 再到 2,模型性能穩步提升。這表明類似 CoT 的鏈式效應在潛空間中也存在。
潛在空間推理在規劃密集型任務中優於語言推理。複雜推理往往要求模型「賽前分析」並評估每一步的合理性。在研究團隊的數據集中,GSM8k 和 ProntoQA 由於問題結構直觀且分支有限,相對容易預測下一步。相比之下,ProsQA 的隨機生成 DAG 結構顯著挑戰了模型的規劃能力。
如表 1 所示,CoT 相比 No-CoT 並無明顯改進。然而,Coconut 及其變體和 iCoT 在 ProsQA 上大幅提升了推理能力,表明潛空間推理在需要大量規劃的任務中具有明顯優勢。
模型仍需指導來學習潛在空間推理
理想情況下,模型應該能通過問答數據的梯度下降自動學習最有效的連續思維(即無課程學習版本的 Coconut)。然而,實驗結果顯示這種訓練方式的表現並不優於 no-CoT。將訓練分解按照目標劃分為多階段課程,Coconut 在各種任務中都取得了最佳性能。
連續思維是推理的高效表示
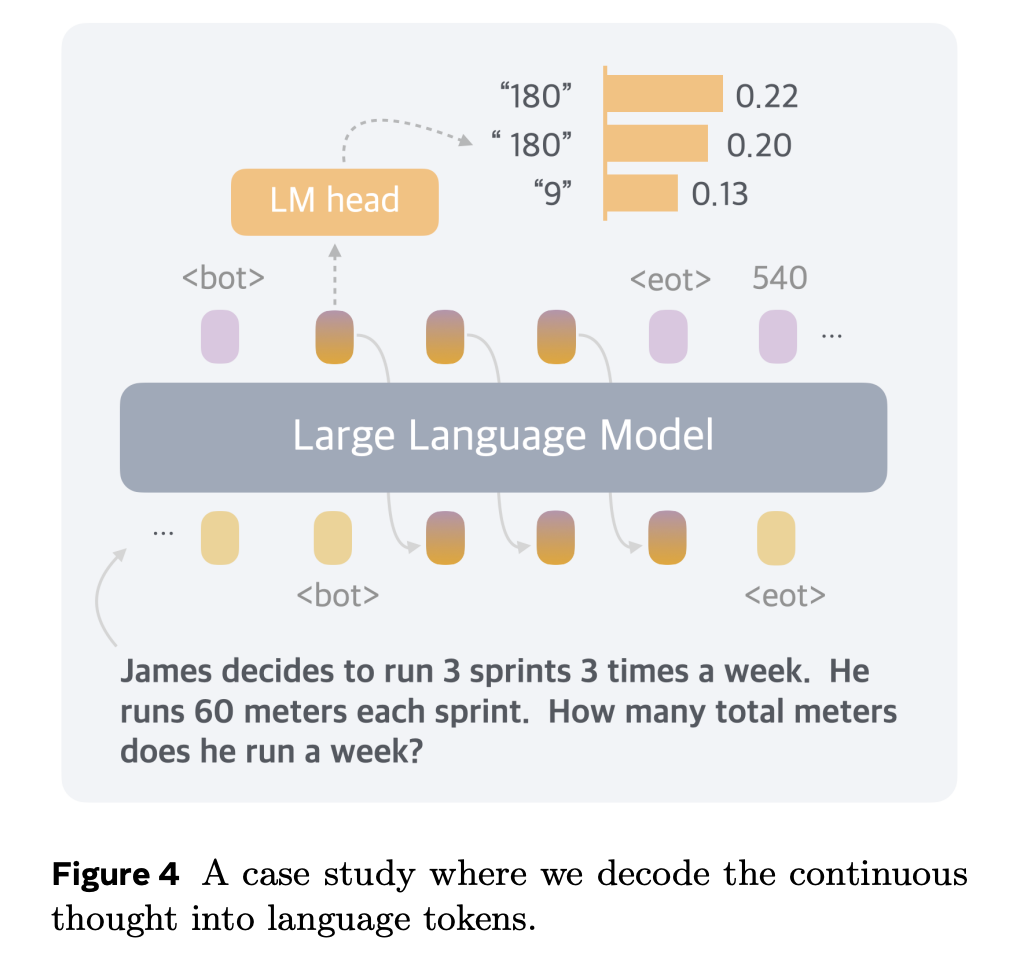
雖然連續思維最初並不是為了轉換成具體的語言文字而設計的,但該團隊發現它可以用來直觀地解釋推理過程。
圖 4 展示了一個由 Coconut(c=1)解決的數學應用題案例研究。第一個連續思維可以解碼為「180」、「180」(帶空格)和「9」等 token。這個問題的推理過程應該是 3×3×60=9×60=540,或 3×3×60=3×180=540。
這恰好對應瞭解題過程中的第一步中間計算結果(3×3×60 可以先算出 9 或 180)。更重要的是,連續思維能夠同時包含多種不同的解題思路,這種特性使它在需要複雜規劃的推理任務中表現出色。
理解 Coconut 中的潛在推理機制
接下來,作者使用 Coconut 的一個變體對潛在推理過程進行了分析。
模型:Coconut 允許通過在推理期間手動設置 < eot > 的位置來控制潛在思維的數量。當強迫 Coconut 使用 k 個連續思維時,該模型預計將從第 k + 1 步開始,用語言輸出賸餘的推理鏈。實驗採用 k∈{0,1,2,3,4,5,6} 在 ProsQA 上測試 Coconut 的變體。
圖 5 展示了在 ProsQA 上對不同推理方法的對比數析。隨著更多的推理在連續思維中進行(k 值增加),最終答案的準確率(圖 5 左)以及正確推理過程的比例(圖 5 右中的 Correct Label 和 Correct Path)都得到了提高。此外,幻覺(Hallucination)和錯誤目標(Wrong Target)的發生率也下降。這也表明,當更多的推理髮生在潛在空間中時,模型的規劃能力得到了提升。
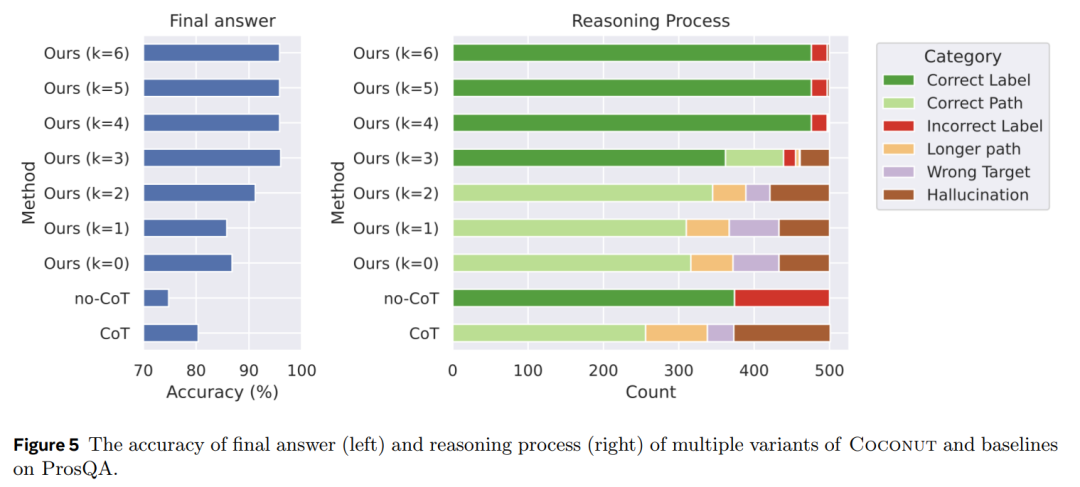
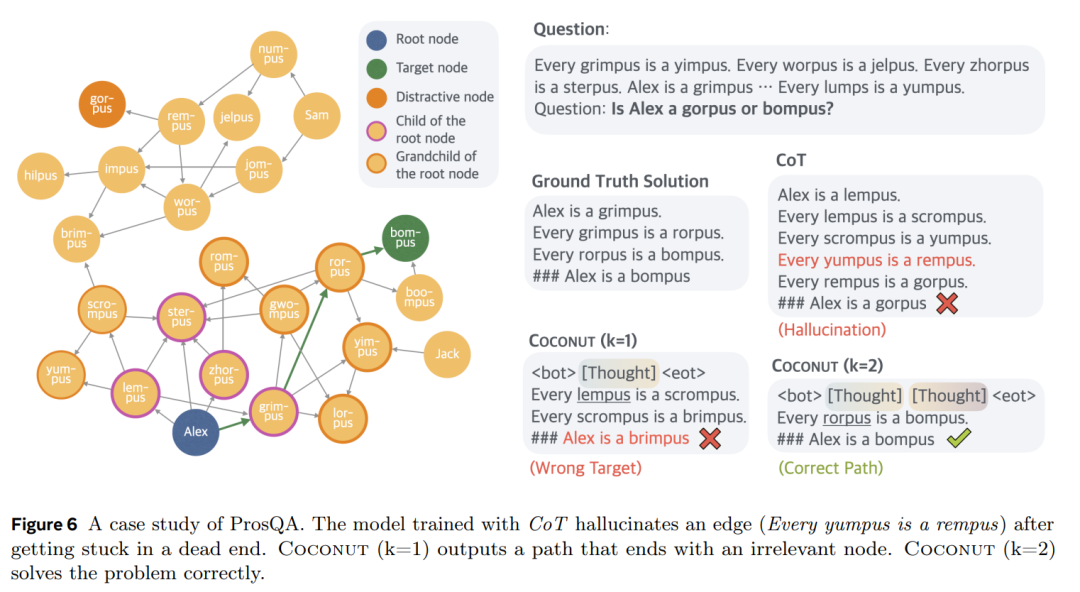
圖 6 為一個案例研究,其中 CoT 產生了幻覺,Coconut(k = 1)導致錯誤的目標,但 Coconut(k = 2)成功解決了問題。在此示例中,模型無法準確確定在早期步驟中選擇哪條邊。但是,由於潛在推理可以避免在前期做出艱難的選擇,因此模型可以在後續步驟中逐步消除不正確的選項,並在推理結束時實現更高的準確率。
潛在搜索樹的解釋
由於連續思維可以編碼多個潛在的下一步,潛在推理可以被解釋為一個搜索樹,而不僅僅是推理「鏈」。以圖 6 為例,第一步可以選擇 Alex 的任一子節點:{lempus, sterpus, zhorpus, grimpus}。
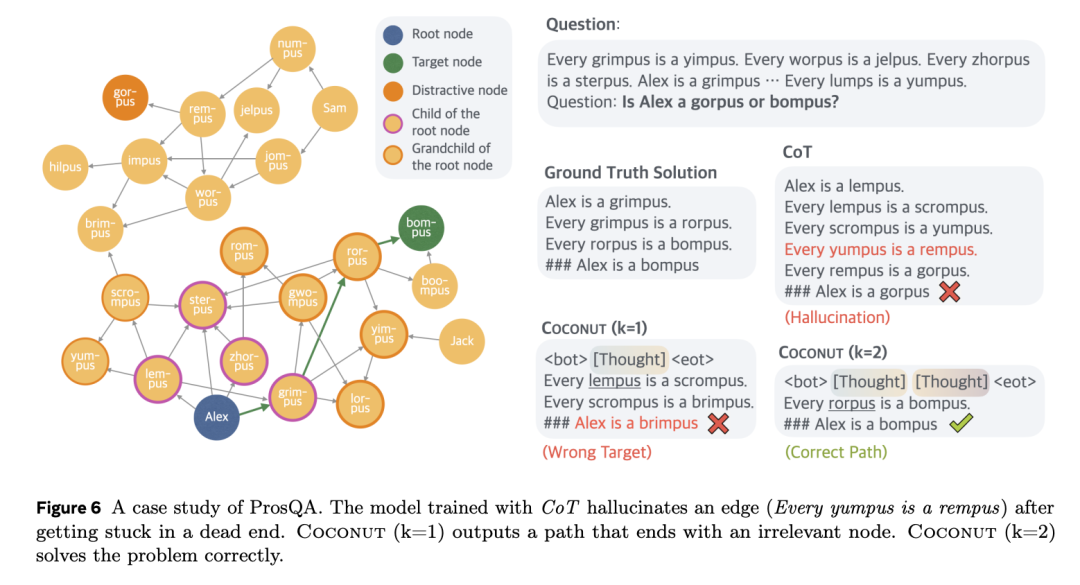 圖 7 左側展示了所有可能的分支。同樣,第二步的前沿節點是 Alex 的孫節點(圖 7 右側)。
圖 7 左側展示了所有可能的分支。同樣,第二步的前沿節點是 Alex 的孫節點(圖 7 右側)。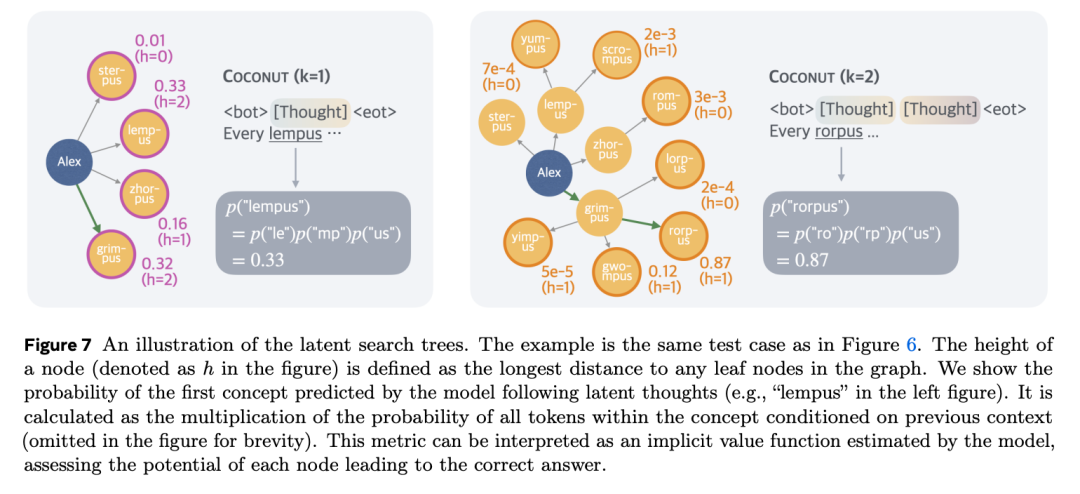
與標準廣度優先搜索不同,模型展現出優先探索有希望的節點同時剪枝不相關節點的能力。通過分析模型在語言空間的後續輸出,研究團隊發現了模型的偏好。例如,當模型在一個潛在思維後切換回語言空間(k=1),它會以結構化格式預測下一步。通過檢查概率分佈,研究團隊得到了根節點 Alex 的子節點的數值(圖 7 左)。同樣,當 k=2 時,也獲得了所有前沿節點的預測概率(圖 7 右)。
圖 8 展示了模型如何在潛在思維空間中進行推理。在第一個潛在思維階段,模型會同時考慮多個可能的推理方向,保持思維的多樣性。到了第二個潛在思維階段,模型會逐步縮小範圍,將注意力集中在最可能正確的推理路徑上。這種從發散到收斂的推理過程,體現了模型在潛在空間中的推理能力。
為什麼潛在空間更適合規劃?
在這一節中,研究團隊探討了潛在推理在規劃中的優勢。例如,圖 6 中的「sterpus」是葉節點,無法通向目標節點「bompus」,容易被識別為錯誤選項。相比之下,其他節點有更多後續的節點需要探索,推理難度更大。
研究團隊通過測量節點在樹中的高度(到葉節點的最短距離)來量化探索潛力。他們發現高度較低的節點更容易評估,因為探索潛力有限。在圖 6 中,模型對高度為 2 的「grimpus」和「lempus」節點表現出更大的不確定性。
為了更嚴格地驗證這個假設,研究團隊分析了測試集中第一步和第二步潛在推理過程中模型預測概率與節點高度之間的相關性。圖 9 揭示了一個規律:當節點高度較低時,模型會為錯誤節點分配較低值,為正確節點分配較高值。
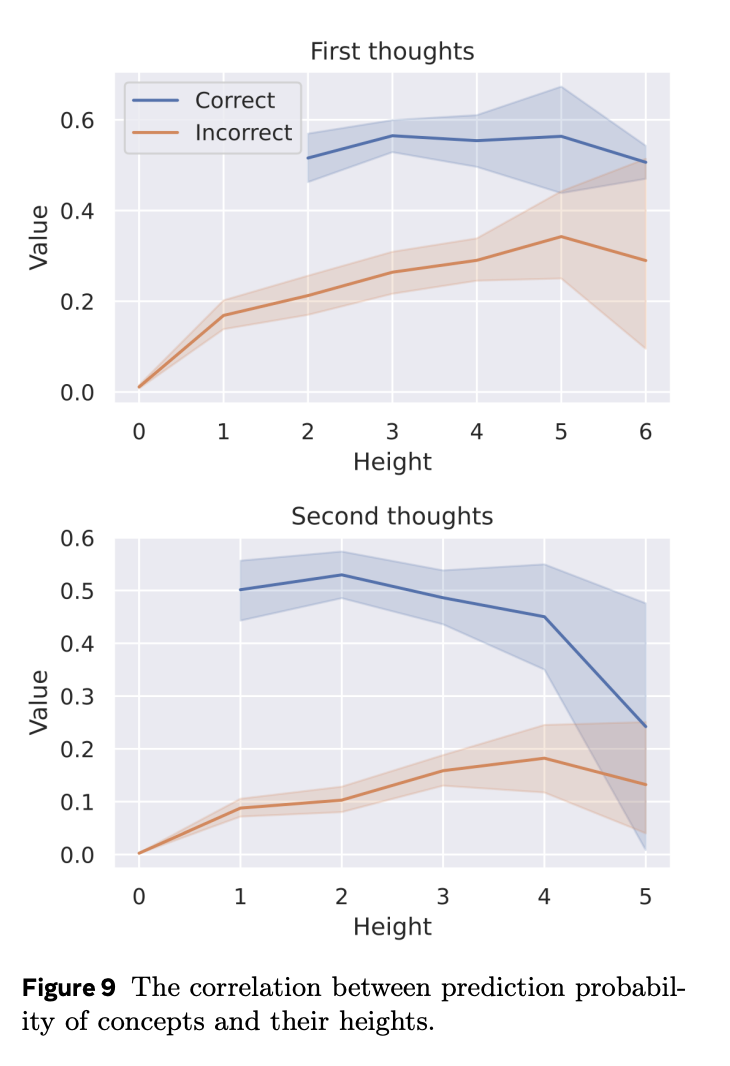
然而,隨著節點高度增加,這種區分變得不那麼明顯,表明評估難度增大。總之,這些發現突出了利用潛在空間進行規劃的優勢。模型通過延遲做出決策,並在潛在推理過程中不斷探索,最終將搜索推向樹的終端狀態,從而更容易區分出正確和錯誤的節點。
更多研究細節,請參閱原文。
參考鏈接:
https://arxiv.org/pdf/2412.06769



















