Kimi如何避免服務宕機?鄭緯民院士揭秘:以存換算
新浪科技訊 12月12日下午消息,在2024大模型技術與應用創新論壇上,中國工程院院士、清華大學計算機系教授鄭緯民在分享中提及了月之暗面kimi對話AI產品避免大量用戶湧入導致服務宕機背後的技術原理——以存換算。
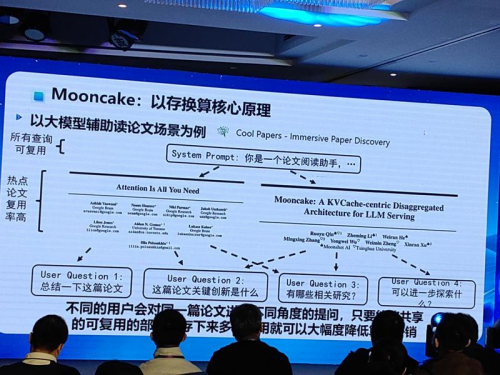
據鄭緯民介紹,保障kimi對話AI流暢運行背後的大模型推理框架,名為Mooncake,是一項叫做清華大學與月之暗面共同研發的推理系統方案。
鄭緯民指出,Kimi研發遵循的基本原則是:數據更多、模型更大、更長的上下文窗口,肯定會帶來更好的效果。因為kimi支持200萬字的上下文,效果很好,很多人都喜歡用它。
但是,在Kimi推出初期,遇到訪問過大服務宕機採用的應對策略便是買算力卡,但買了五次卡還是死機,並不能徹底解決問題。其背後的原因是,更高的推理負載意味著要買更多的推理卡,但推理卡多了存儲器也會不夠,用的人多了,問題也就大了。
據鄭緯民介紹,最後月之暗面與清華大學開發了Mooncake技術框架,通過將不同用戶與Kimi對話的公共內容提煉出來,存儲下來,遇到下次用戶再提問的時候直接讀取回覆,減少了每次用戶提問都要重新生成的過程,節省了許多算力卡,之後Mooncake就沒有再死過機。
“把存儲器好好用,也可以省很多卡。”鄭緯民表示。(文猛)