專治大模型「套殼」!上海AI實驗室等給LLM做「指紋識別」,剪枝合併也無所遁形
上海AI Lab邵婧課題組 投稿
量子位 | 公眾號 QbitAI
大模型「套殼」事件防不勝防,有沒有方法可以檢測套殼行為呢?
來自上海AI實驗室、中科院、人大和上交大的學者們,提出了一種大模型的「指紋識別」方法——REEF(Representation Encoding Fingerprints)。
在不改變模型性能的前提下,利用REEF就可以精準識別未經授權的後續開發行為。

REEF依賴模型在微調後表徵「不變性」的特點,基於表徵編碼實現對大模型的「指紋鑒別」。
並且即使經過剪枝、合併、參數排列和縮放變換等一系列操作,同樣能讓「套殼」行為無所遁形。
可以說,這項研究給大模型開發團隊提供了一種應對大模型侵權問題的新手段。
大模型表徵具有「微調不變性」
註:
在下文中,「源模型」是指從頭訓練的LLM(即論文中victim model),如Llama、Qwen等;
「被測模型」(即論文中的suspect model),分為兩類——基於源模型開發/訓練的「衍生模型」和其他「無關模型」。
REEF的目標是,給定一個被測模型,檢測其是否是來自「源模型」的「衍生模型」,即所謂的「套殼」模型。
鑒於訓練大語言模型的投入巨大,模型所有者和第三方迫切需要一種準確高效的方法,以判斷被測模型是否來自某一源模型(例如Code-llama從Llama-2訓練而來)。
然而,現有的水印方法不僅增加了額外的訓練成本,還可能削弱模型的通用性能,且水印容易被刪除。更重要的是,這些方法無法應用於已公開發佈的模型。
此外,基於權重的指紋識別缺乏魯棒性,惡意開發者可以通過不同權重修改手段輕鬆繞過檢測。
由於不同模型在訓練數據和模型架構上的差異,不同的LLM的特徵表示有所不同。
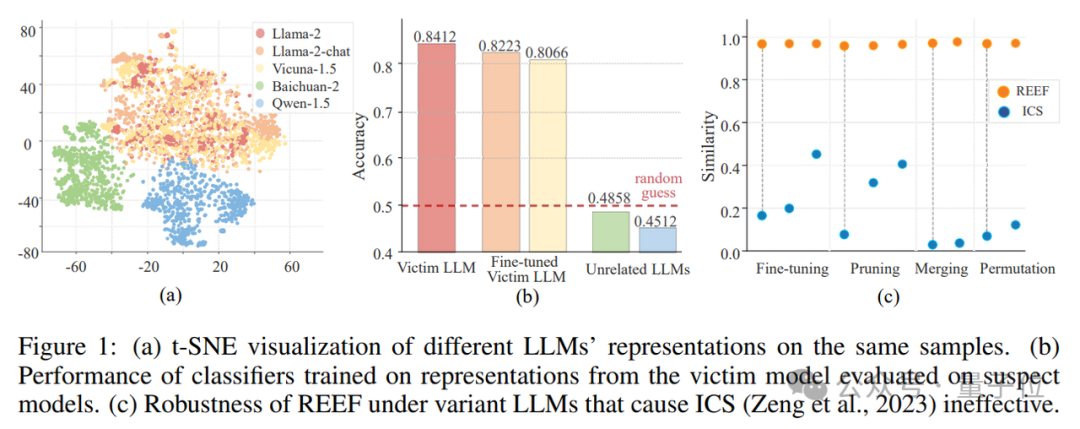
如下圖(a)所示,Llama的表徵與Baichuan和Qwen明顯不同,但與其微調模型(如Llama-chat和Chinese-llama)更為接近。
這一現象揭示了表徵作為LLM「指紋」的潛力。
基於以下兩點觀察,作者在源模型的表徵上訓練了一個二元分類器,並將其應用於各種被測模型的表徵,包括衍生模型和無關模型:
-
微調後的衍生模型的表徵與源模型的表徵相似,而無關模型的表徵顯示出不同的分佈;
-
一些高級語義概念在 LLM 的表徵空間中「線性」編碼,從而可以輕鬆分類,如安全或不安全、誠實或不誠實等。
具體而言,作者使用TruthfulQA數據集,分別選擇 Llama-2-7B和 Llama-2-13B作為源模型,並在其數據集表徵上訓練了多種深度神經網絡DNN分類器,例如線性分類器、多層感知器MLP、卷積神經網絡CNN 和圖卷積網絡GCN。
然後,作者將訓練好的DNN分類器應用於被測模型的表徵。
實驗結果表明:在源模型的表徵上訓練的分類器能夠有效遷移到其衍生模型的表徵上,但在無關模型的表徵上失效。
這意味著,表徵可以作為指紋來保護源模型的知識產權。

然而,使用DNN分類器識別源模型面臨以下挑戰:
-
DNN具有固定的輸入維度,如果對源模型進行改變表徵維度的剪枝操作,分類器不再適用;
-
DNN對表徵的排列缺乏魯棒性,惡意開發人員可能通過變換矩陣實現參數重排來規避檢測。
REEF:一種魯棒的LLM指紋識別方法
為瞭解決上述挑戰,作者提出一種新的基於表徵的指紋識別方法——REEF,具備良好的魯棒性。
REEF利用中心核對齊CKA相似性,重點關注LLM的內部特徵表徵。
在評估被測模型是否來自源模型時,REEF計算兩個模型對相同樣本的表徵之間的CKA相似性。
該方法簡單高效,能夠確保捕獲到任何顯著的相似性,從而揭示模型之間的潛在衍生關係。
CKA是基於高治伯特-施密特獨立性準則(HilbertSchmidt Independence Criterion,HSIC)的相似性指數,用於測量兩組隨機變量之間的獨立性。
X和Y之間的CKA相似度可以按如下方式計算:
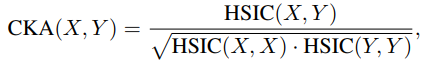
通過下面的定理1,論文在理論上證明了CKA相似度在任何列排列和縮放變換下具有不變性。同時,CKA能夠在不同維度的表徵之間建立對應關係。

因此,REEF 對源模型的各種後續開發(包括模型剪枝和表徵排列)表現出強魯棒性,從而確保基於表徵的指紋能夠準確識別源模型。
無懼後續開發,穩穩識別「套殼」模型
作者將REEF應用於通過微調、剪枝、合併、排列和縮放變換等方式從源模型衍生出的被測模型。
這些方式可能顯著改變模型的結構或參數,使得現有方法難以有效識別源模型。
然而,REEF在這些情況下依然能夠準確識別出源模型,進一步驗證了其魯棒性。

具體來說,從上面的表中,可以得出以下結論:
-
REEF對微調具有很強的魯棒性,即使在使用多達700B tokens的微調情況下(Llama-7B),REEF仍能達到0.9962的高相似度;
-
REEF對各種剪枝策略都表現出魯棒性,無論結構化剪枝還是非結構化剪枝,REEF都能夠有效識別源模型,即使剪枝比率高達90%,REEF依然能夠成功識別;
-
無論是基於權重或基於分佈的模型合併方法,REEF均能在識別合併模型的來源方面始終保持高準確性;
-
REEF 對任何列排列和縮放變換具有不變性,能夠抵禦該類規避技術。

魯棒且高效:跨數據集和樣本量
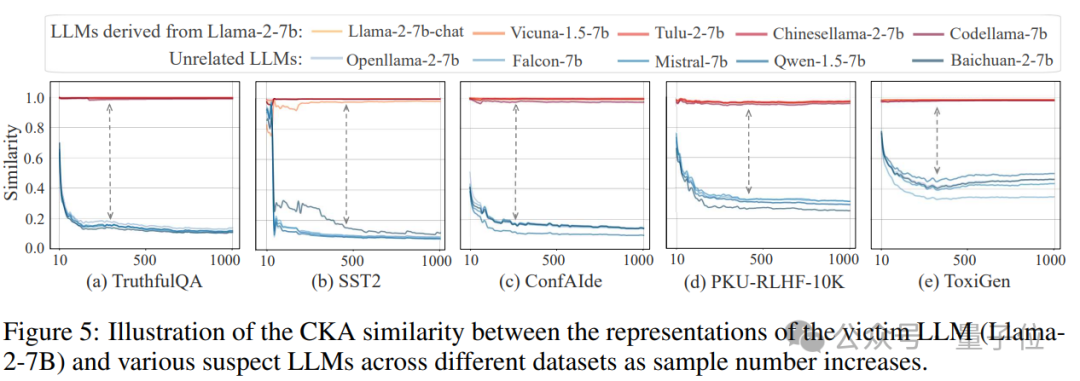
作者進一步分析了REEF在不同數據集和不同樣本數量下的表現。
一方面,除了前文提到的TruthfulQA數據集,作者還選擇了SST2、ConfAIde、PKUSafeRLHF和ToxiGen等數據集進行實驗;
另一方面,對於每個數據集,別在樣本數量從10到1000、每隔10的情況下進行采樣,以測試REEF的表現。
結果,REEF在不同數據集上均表現出有效性,對數據集不具強依賴性(圖示在不同數據集上,源模型與衍生模型之間的相似性顯著高於其與無關模型之間的相似性,表明REEF能夠跨數據集穩定識別源模型);
同時,REEF依賴少量樣本即可穩健識別模型指紋,具有高效性(圖示REEF在 200-300 個樣本後結果趨於穩定,表明其可以在較少的樣本數量下實現可靠的指紋識別)。
REEF它不僅保障了模型性能,還平衡了開放性與知識產權之間的關係,能夠確保衍生模型的責任可追溯。
作者相信,REEF將為AI模型保護和知識產權管理設立新的標準,促進更透明、協作的AI社區。
作者簡介
本文由上海AI Lab、中科院、人大和上交大聯合完成。
主要作者包括中科院博士生張傑、上海AI Lab青年研究員劉東瑞(共同一作)等。
通訊作者邵婧為上海AI Lab青年科學家,研究方向為AI安全可信。
論文地址:
https://arxiv.org/abs/2410.14273
項目主頁:
https://github.com/tmylla/REEF