MIT的新方法讓3D建模變得簡單又有趣
 (來源:MIT News)
(來源:MIT News)製作 VR、電影和工程設計等所需的逼真 3D 模型通常是一個繁瑣的過程,需要大量的手動嘗試與調整。
儘管生成式 AI 圖像模型可以通過文本提示生成逼真的 2D 圖像,從而簡化藝術創作過程,但這些模型並不適用於生成 3D 形狀。為瞭解決這一問題,研究人員最近開發知名為「Score Distillation」的技術,利用 2D 圖像生成模型來創建 3D 形狀,但生成的結果往往模糊或帶有過度的卡通風格。
MIT 的研究人員深入探索了生成 2D 圖像與 3D 形狀的算法之間的關係與差異,找出了 3D 模型質量較低的根本原因。基於此,他們對 Score Distillation 進行了簡單的改進,使其能夠生成更加清晰、高質量的 3D 形狀,這些形狀的質量更接近於目前最佳的模型生成 2D 圖像水平。

 (來源:MIT News)
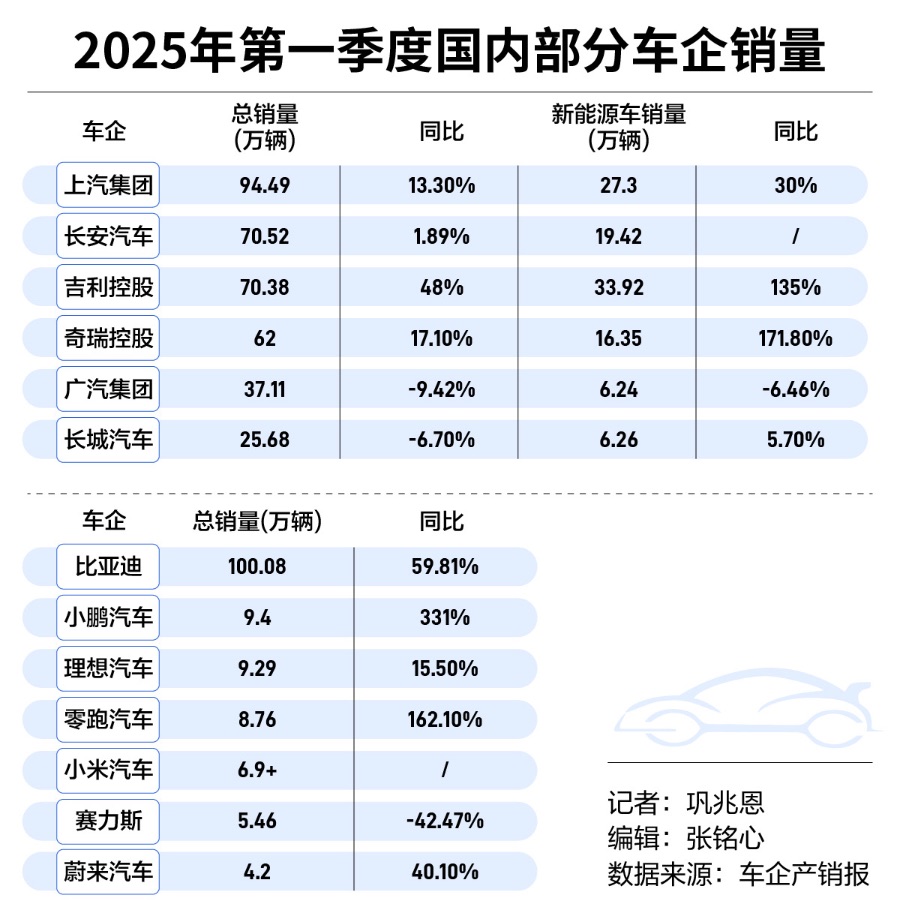
(來源:MIT News)如上圖,這些示例展示了兩個不同的 3D 旋轉物體:一個機器蜜蜂和一顆草莓。研究人員通過基於文本的生成式人工智能和他們的新技術生成了這些 3D 物體。
一些其他方法試圖通過重新訓練或微調生成式人工智能模型來解決這個問題,但這些方法通常代價高昂且耗時。
相比之下,MIT 開發的技術無需額外訓練或複雜的後處理,就能生成質量相當或優於這些方法的 3D 模型。
此外,通過找到問題的根本原因,研究人員提升了對 Score Distillation 及相關技術的數學理解,為未來進一步提升性能打下了基礎。
「現在我們知道了努力的方向,這使我們能夠找到更高效、更快速且質量更高的解決方案。」該技術相關論文的第一作者、電子工程與計算機科學研究生 Artem Lukoianov 說道,「從長遠來看,我們的研究可以幫助將這一過程轉變為設計師的輔助工具,讓創建更加真實的 3D 形狀變得更簡單。」
Lukoianov 的合作者包括牛津大學研究生 Haitz Sáez de Ocáriz Borde、MIT-IBM Watson AI Lab 研究科學家 Kristjan Greenewald、豐田研究院科學家 Vitor Campagnolo Guizilini、Meta 研究科學家 Timur Bagautdinov,以及兩位資深作者:MIT 電子工程與計算機科學助理教授、計算機科學與人工智能實驗室(CSAIL)場景表示小組負責人 Vincent Sitzmann,以及 CSAIL 幾何數據處理小組負責人、電子工程與計算機科學副教授 Justin Solomon。該研究將在 NeurIPS 上發表。

從 2D 圖像到 3D 形狀
擴散模型(如 DALL-E)是一種生成式 AI 模型,可以從隨機噪聲中生成逼真的圖像。為了訓練這些模型,研究人員向圖像中添加噪聲,然後教模型逆向處理以去除噪聲。模型利用這一學習到的「去噪」過程,根據用戶的文本提示生成圖像。
然而,擴散模型在直接生成真實的 3D 形狀時表現不佳,因為可用於訓練的 3D 數據不足。為瞭解決這一問題,研究人員在 2022 年開發了一種名為 Score Distillation Sampling (SDS) 的技術,利用預訓練的擴散模型將多個 2D 圖像結合成 3D 表示。
該技術從一個隨機的 3D 表示開始,先從隨機相機角度渲染出所需物體的 2D 視圖,再向該圖像添加噪聲,然後使用擴散模型去噪,並優化初始的 3D 表示,使其更接近去噪後的圖像。研究人員重覆這一過程,直到生成目標 3D 物體。
然而,通過這種方式生成的 3D 形狀往往顯得模糊或顏色過飽和。
「這一瓶頸問題已經存在了一段時間。我們知道底層模型本身能夠表現得更好,但人們一直不明白為什麼在處理 3D 形狀時會出現這種問題。」MIT 研究生 Artem Lukoianov 解釋道。
MIT 研究人員深入研究了 SDS 的每一步驟,併發現了一個關鍵公式與 2D 擴散模型的對應部分存在不匹配。這個公式決定了模型如何通過一步步添加和去除噪聲,更新隨機表示,使其更接近目標圖像。
由於公式的一部分涉及一個複雜的方程,難以高效求解,SDS 用每一步隨機采樣的噪聲代替了該方程。但 MIT 研究人員發現,正是這種隨機噪聲導致了模糊或卡通化的 3D 形狀。

巧妙的近似解法
研究人員沒有嘗試精確求解這一複雜公式,而是測試了多種近似技術,最終找到了最佳方案。他們的方法並非隨機采樣噪聲項,而是通過當前 3D 形狀的渲染結果推斷出缺失的噪聲項。
「通過這樣做,正如論文中的分析所預測的那樣,我們能夠生成清晰、逼真的 3D 形狀。」Lukoianov 解釋道。
此外,研究人員還提高了圖像渲染的解像度,並調整了一些模型參數,進一步提升了 3D 形狀的質量。
最終,他們利用現成的預訓練圖像擴散模型,無需昂貴的重新訓練,就能創建平滑且逼真的 3D 形狀。生成的 3D 物體在清晰度上與依胡禮定解決方案的其他方法相當。
「如果只是盲目地調整不同參數,有時有效,有時無效,但你不知道原因所在。而現在,我們明確了需要解決的方程,這讓我們可以思考更高效的求解方式。」Lukoianov 說道。
由於他們的方法依賴於預訓練的擴散模型,這一模型的偏差和不足也被繼承了下來,因此可能會出現幻覺現象或其他錯誤。改進底層擴散模型將進一步提升這一過程的效果。
除了研究如何更高效地解決這一公式,研究人員還希望探索這些見解如何改進圖像編輯技術。
Artem Lukoianov 的研究得到了豐田–CSAIL 聯合研究中心的資助。Vincent Sitzmann 的研究獲得了美國國家科學基金會、新加坡國防科學與技術局、美國內政部以及 IBM 的支持。Justin Solomon 的研究部分由美國陸軍研究辦公室、國家科學基金會、CSAIL 未來數據項目、MIT–IBM Watson AI 實驗室、緯創集團以及豐田–CSAIL 聯合研究中心資助。
原文鏈接:
https://news.mit.edu/2024/creating-realistic-3d-shapes-using-generative-ai-1204