決策過程是魔法還是科學?首個多模態大模型的可解釋性綜述全面深度剖析
AIxiv專欄是機器之心發佈學術、技術內容的欄目。過去數年,機器之心AIxiv專欄接收報導了2000多篇內容,覆蓋全球各大高校與企業的頂級實驗室,有效促進了學術交流與傳播。如果您有優秀的工作想要分享,歡迎投稿或者聯繫報導。投稿郵箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
本文由香港科技大學(廣州)、上海人工智能實驗室、中國人民大學及南洋理工大學聯合完成。主要作者包括香港科技大學(廣州)研究助理黨運楷、黃楷宸、霍家灝(共同一作)、博士生嚴一博、訪學博士生黃思睿、上海AI Lab青年研究員劉東瑞等,通訊作者胡旭明為香港科技大學/香港科技大學(廣州)助理教授,研究方向為可信大模型、多模態大模型等。
本文介紹了首個多模態大模型(MLLM)可解釋性綜述,由香港科技大學(廣州)、上海人工智能實驗室、以及中國人民大學聯合發佈。文章系統梳理了多模態大模型可解釋性的研究進展,從數據層面(輸入輸出、數據集、更多模態)、模型層面(詞元、特徵、神經元、網絡各層及結構)、以及訓練與推理過程三個維度進行了全面闡述。同時,深入分析了當前研究所面臨的核心挑戰,並展望了未來的發展方向。本文旨在揭示多模態大模型決策邏輯的透明性與可信度,助力讀者把握這一領域的最新前沿動態。

-
論文名稱:Towards Explainable and Interpretable Multimodal Large Language Models: A Comprehensive Survey
-
論文鏈接:https://arxiv.org/pdf/2412.02104
多模態大模型可解釋性
近年來,人工智能(AI)的迅猛發展深刻地改變了各個領域。其中,最具影響力的進步之一是大型語言模型(LLM)的出現,這些模型在文本生成、翻譯和對話等自然語言任務中展現出了卓越的理解和生成能力。與此同時,計算機視覺(CV)的進步使得系統能夠高效地處理和解析複雜的視覺數據,推動了目標檢測、動作識別和語義分割等任務的高精度實現。這些技術的融合激發了人們對多模態 AI 的興趣。多模態 AI 旨在整合文本、視覺、音頻和影片等多種模態,提供更豐富、更全面的理解能力。通過整合多種數據源,多模態大模型在圖文生成、視覺問答、跨模態檢索和影片理解等多模態任務中展現了先進的理解、推理和生成能力。同時,多模態大模型已在自然語言處理、計算機視覺、影片分析、自動駕駛、醫療影像和機器人等領域得到了廣泛應用。
然而,隨著多模態大模型的不斷髮展,一個關鍵挑戰浮現:如何解讀多模態大模型的決策過程?
多模態大模型(MLLMs)的飛速發展引發了研究者和產業界對其透明性與可信度的強烈關注。理解和解釋這些模型的內部機制,不僅關係到學術研究的深入推進,也直接影響其實際應用的可靠性與安全性。本綜述聚焦於多模態大模型的可解釋性,從以下三個關鍵維度展開深入分析:
1. 數據的解釋性:數據作為模型的輸入,是模型決策的基礎。本部分探討不同模態的輸入數據如何預處理、對齊和表示,並研究通過擴展數據集與模態來增強模型的可解釋性,增強對模型決策的理解。
2. 模型的解釋性:本部分分析模型的關鍵組成部分,包括詞元、特徵、神經元、網絡層次以及整體網絡結構,試圖揭示這些組件在模型決策中的具體作用,從而為模型的透明性提供新的視角。
3. 訓練與推理的解釋性:本部分探討模型的訓練和推理過程可能影響可解釋性的因素,旨在理解模型的訓練和推理過程背後的邏輯。
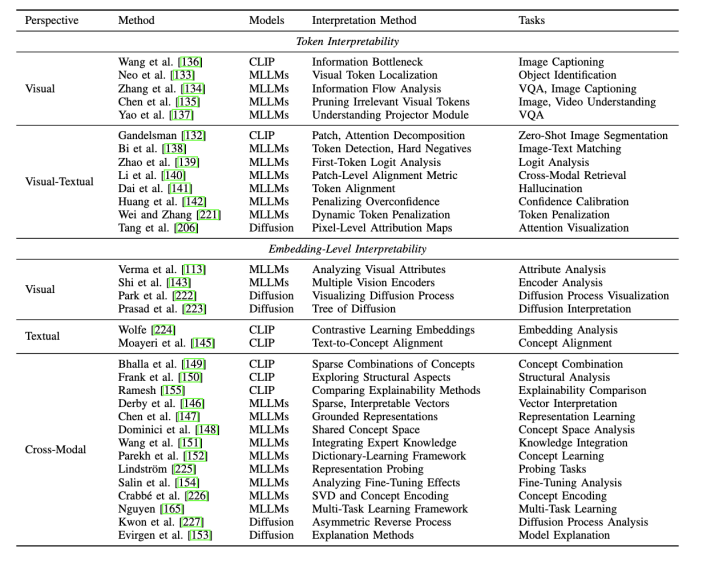
多模態大模型可解釋性文章彙總
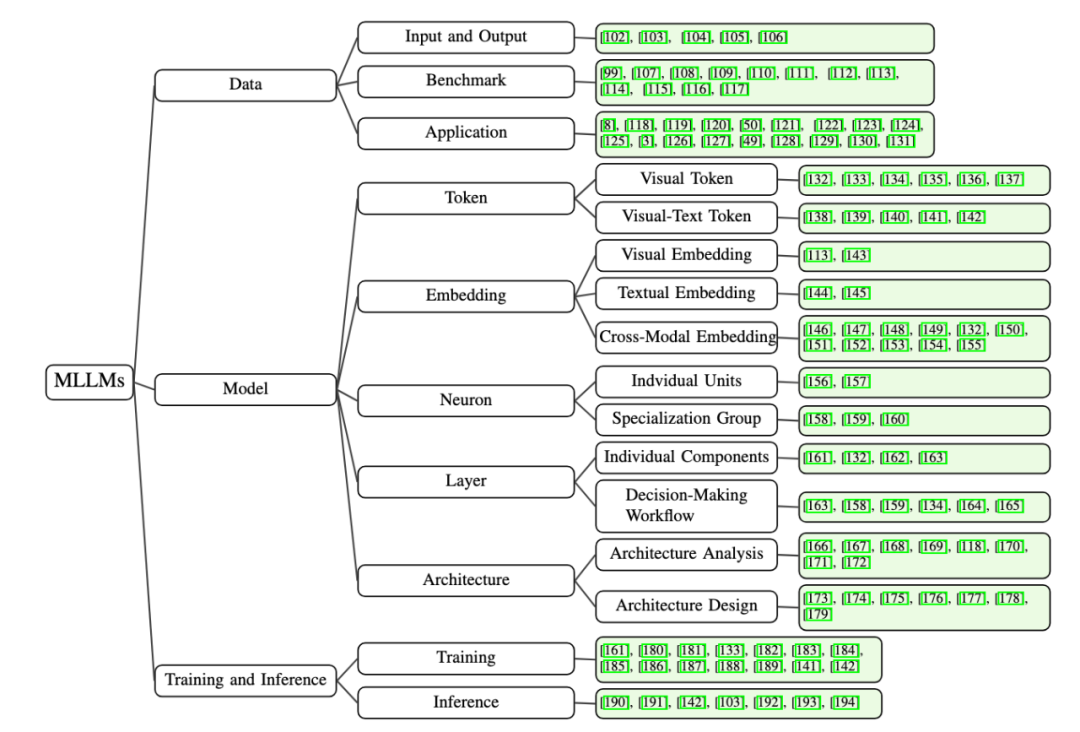
我們將現有的方法分類為三個視角:數據(Data)、模型(Model)和訓練及推理(Traning & Inference)。具體如下:
1、數據視角的可解釋性:從輸入(Input)和輸出(Output)角度出發,研究不同數據集(Benchmark)和更多模態的應用(Application),探討如何影響模型的行為與決策透明性。
2、模型視角的可解釋性:我們深入分析了模型內部的關鍵組成部分,重點關注以下五個維度:
-
Token:研究視覺詞元(Visual Token)或視覺文本詞元(Visual-textual Token)對模型決策的影響,揭示其在多模態交互中的作用。
-
Embedding:評估多模態嵌入 (Visual Embedding, Textual Embedding, Cross-modal Embedding) 如何在模型中進行信息融合,並影響決策透明度。
-
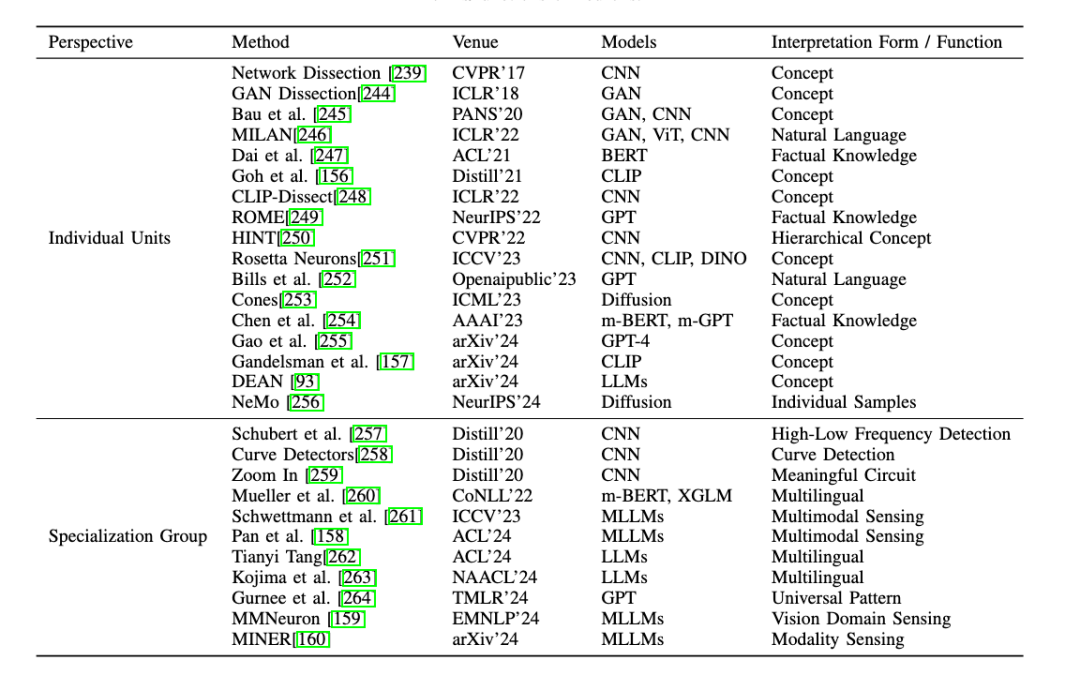
Neuron:分析個體神經元(Indvidual Units)和神經元組 (Specialization Group) 對模型輸出的貢獻。
-
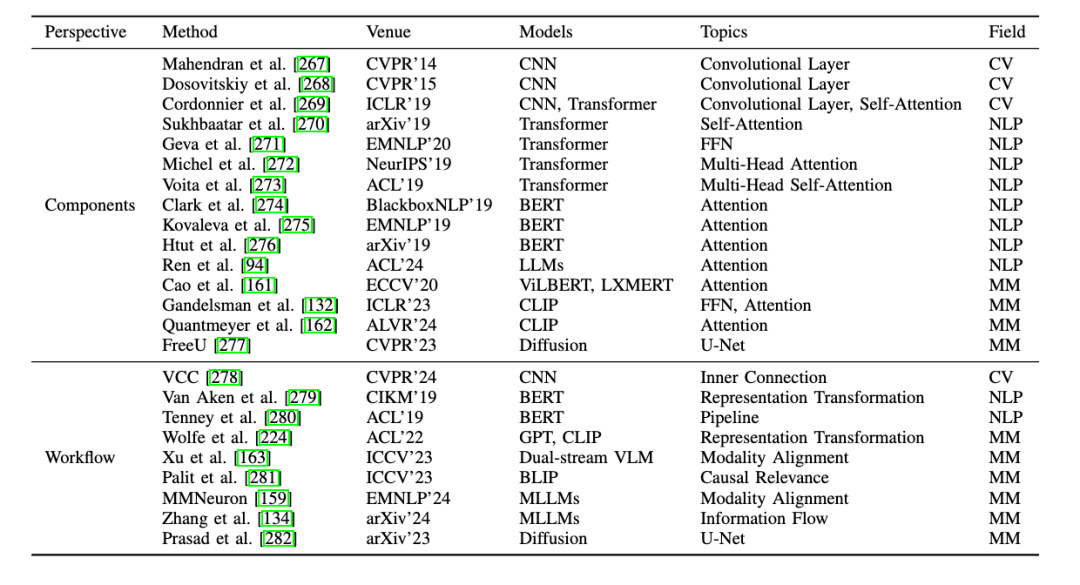
Layer:探討單個網絡層(Individual Components)和不同網絡層(Decision-Making Workflow)在模型決策過程中的作用。
-
Architecture:通過對網絡結構分析(Architecture Analysis)和網絡結構設計(Architecture Design),促進模型架構的透明度和可理解性。
3、訓練與推理的可解釋性:我們從訓練和推理兩個階段研究多模態大模型的可解釋性:
-
訓練階段:總結多模態大模型預訓練機制或訓練策略,重點討論如何增強多模態對齊、減少幻覺現象,對提高模型可解釋性。
-
推理階段:研究無需重新訓練的情況下,緩解幻覺等問題的方法,如過度信任懲罰機制和鏈式思維推理技術,以提升模型在推理階段的透明性和魯棒性。
解碼多模態大模型
從詞元到網絡結構的可解釋性全面剖析
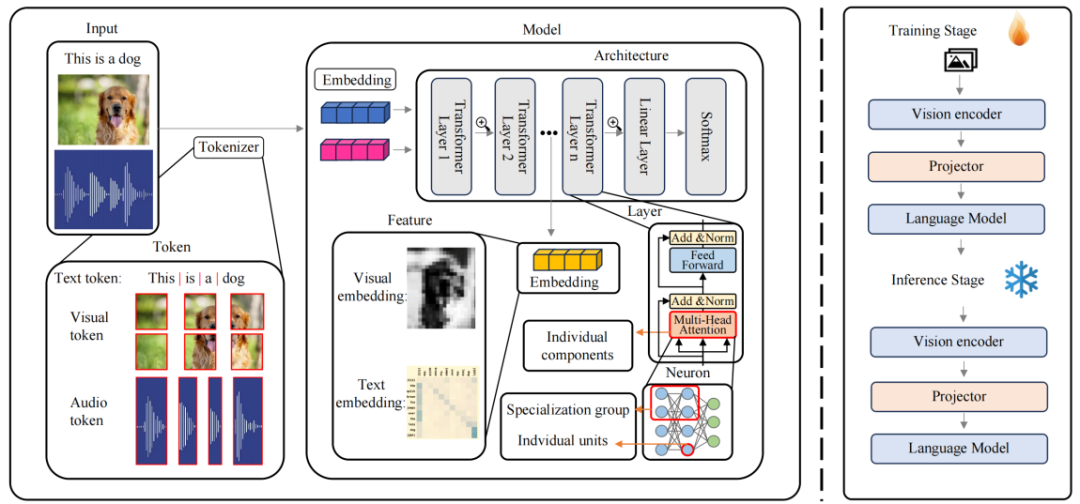
詞元與嵌入(Token and Embedding) 的可解釋性:詞元(Token)和嵌入(Embedding)作為模型處理和表示數據的關鍵單元,對於模型的可解釋性具有重要意義。
-
詞元研究:我們通過分析視覺詞元 (Visual Token),揭示了模型如何將圖像分解為基本視覺組件,從而理解單個詞元對預測的影響。同時,通過探索視覺 – 文本詞元 (Visual-Textual Token) 的對齊機制,揭示其在複雜任務(如視覺問答、活動識別)中的影響。
-
嵌入研究:在特徵嵌入 (Embedding) 方面,研究聚焦於多模態特徵的表示方式,旨在提升模型的透明度和可解釋性。例如,通過生成稀疏、可解釋的向量,捕捉多模態的語義信息,進一步揭示特徵嵌入在多模態對齊中的作用。
神經元 (Neuron) 的可解釋性:神經元是多模態大模型的核心組件,其功能和語義角色的研究對揭示模型內部機制至關重要。
-
單個神經元的研究:對於單個神經元,一些研究通過將單個神經元與特定的概念或功能關聯起來,發現能夠同時響應視覺和文本概念的神經元,為理解多模態信息整合提供新的視角。
-
神經元群體的研究:對於神經元群體,研究表明某些神經元組可以集體負責特定任務,例如檢測圖像中的曲線、識別高低頻特徵,或在語言模型中調節預測的不確定性。此外,在多模態任務中,神經元群體被用來連接文本和圖像特徵,提出了新的方法來檢測跨模態神經元,為多模態信息處理的透明化提供了重要依據。
層級結構 (Layer) 的可解釋性:深度神經網絡由多個層級組成,層級結構的研究揭示了各層在模型決策過程中的作用。
-
單個層的研究:研究者探索了注意力頭(Attention Heads)、多層感知器(MLP)等層內組件對於模型決策的影響。
-
跨層研究:對跨層的整體決策過程進行分析,增強跨模態信息的整合能力。
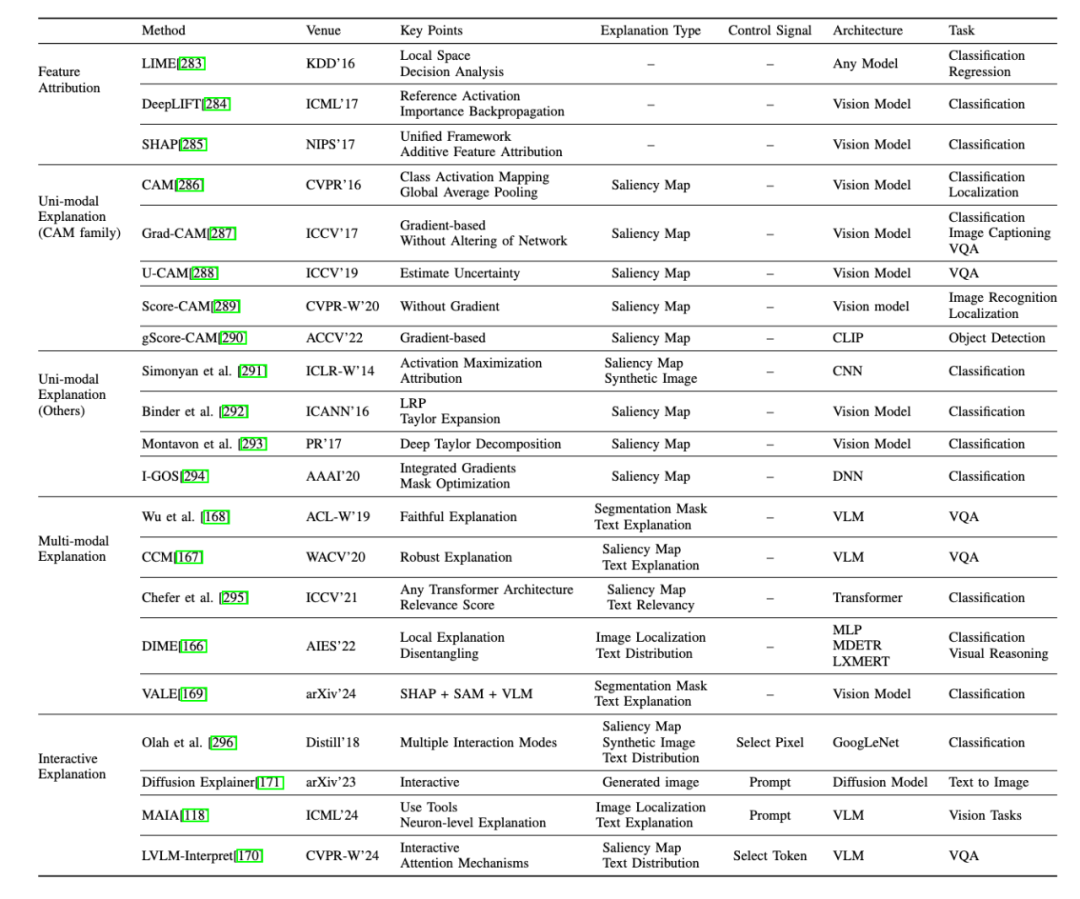
網絡結構(Architecture)的可解釋性:除了在神經元和層級層面探討多模態大模型的可解釋性外,一些研究還從更粗粒度的網絡結構層面進行探索。與之前聚焦於 MLLMs 具體組件的方法不同,這裏從整體網絡結構視角出發,研究分為網絡結構分析與設計兩大類:
1、網絡結構分析:這種方法獨立於任何特定的模型結構或內部機制,包括:
-
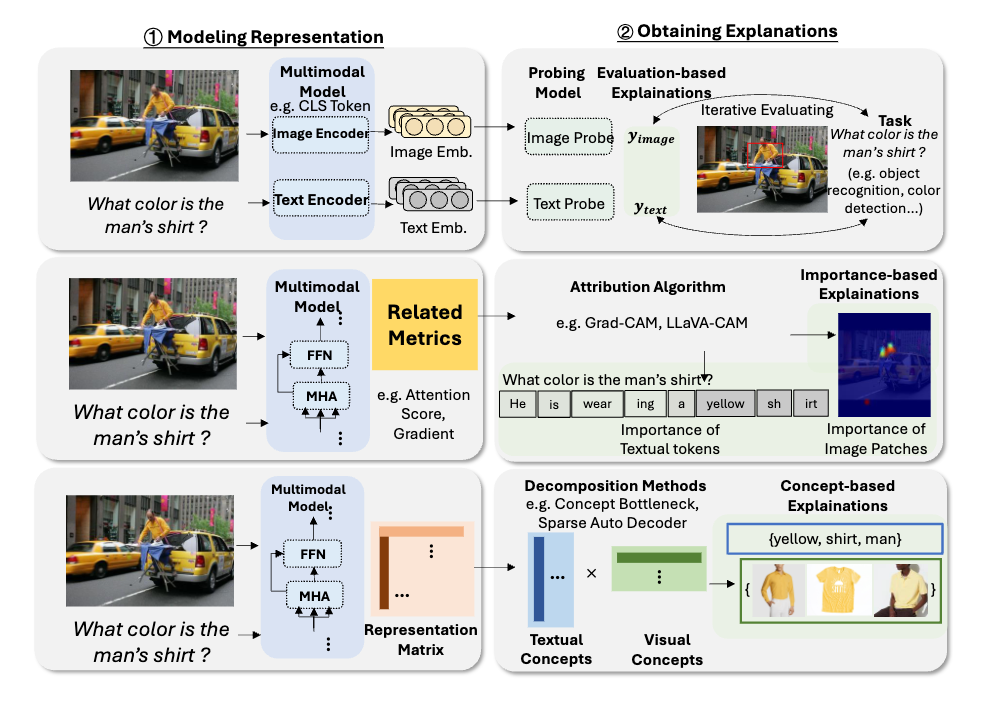
特徵歸因:通過為特徵分配重要性分數,提供基礎性解釋方法,。
-
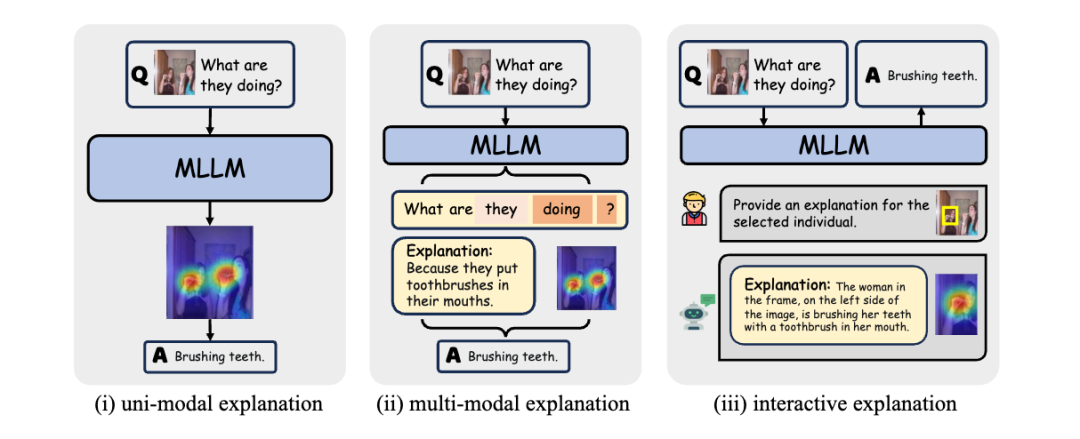
單模態解釋:提供單一模態(主要是圖像模態)的解釋。
-
多模態解釋:提供多模態(如圖像和文本結合)的解釋。
-
交互式解釋:根據人類的指令或偏好提供解釋的方法。
-
其他:包括通過模型比較提供探究的網絡結構級模型分析方法等。
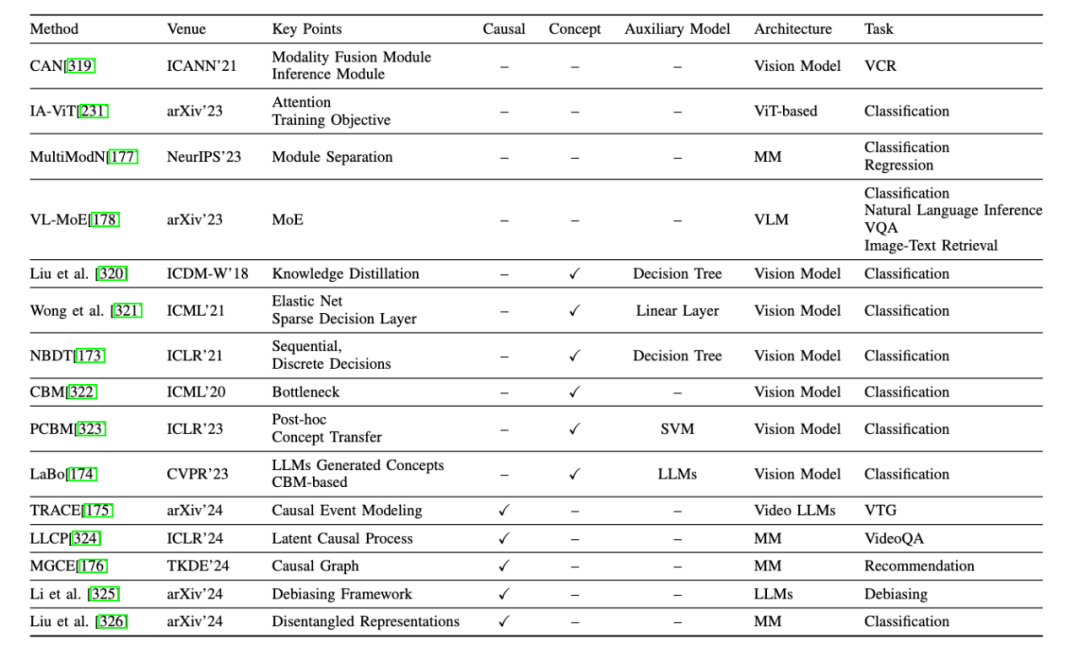
2、網絡結構設計:這類方法通過在模型網絡結構中引入高度可解釋的模塊來增強模型的可解釋性。專注於特定的模型類型,利用獨特的結構或參數來探索內部機制。這一類包括:
-
替代模型:使用更簡單的模型,如線性模型或決策樹,來近似複雜模型的性能。
-
基於概念的方法:使模型能夠學習人類可理解的概念,然後使用這些概念進行預測。
-
基於因果的方法:在網絡結構設計中融入因果學習的概念,如因果推理或因果框架。
-
其他:包括網絡結構中無法歸類到上述類別的其他模塊相關的方法。
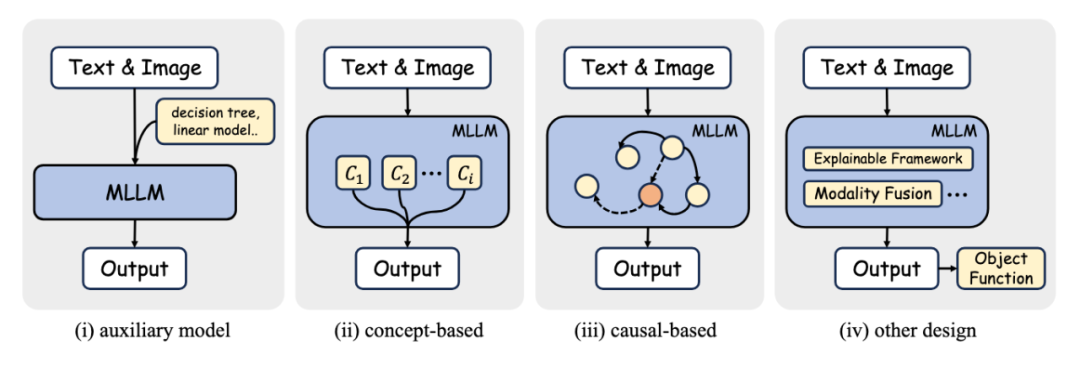
訓練和推理(Training & Inference)的可解釋性:在多模態大模型(MLLMs)的訓練與推理中,通過優化策略提升模型的透明性:
-
訓練階段:通過合理的預訓練策略優化多模態對齊,揭示跨模態關係,同時減少生成過程中的偏差與幻覺現象,為模型魯棒性提供支持。
-
推理階段:鏈式思維推理和上下文學習技術為實現結構化、可解釋的輸出提供了新的可能性。這些方法有效緩解了模型在生成內容中的幻覺問題,有效提升了模型輸出的可信度。
挑戰與機遇並存
多模態大模型的可解釋性未來展望?
隨著多模態大模型(MLLMs)在學術與工業界的廣泛應用,可解釋性領域迎來了機遇與挑戰並存的未來發展方向。以下是我們列出一些未來的展望:
-
數據集與更多模態的融合:改進多模態數據的表示和基準測試,開發標準化的預處理和標註流程,確保文本、圖像、影片和音頻的一致性表達。同時,建立多領域、多語言、多模態的評估標準,全面測試模型的能力。
-
多模態嵌入與特徵表示:加強對模型預測結果的歸因,探索動態詞元重要性機制,確保結果與人類表達方式一致。通過優化視覺與文本特徵的對齊,構建統一框架,揭示模型處理多模態信息的內在機制。
-
模型結構的可解釋性:聚焦神經元間的對齊機制和低成本的模型編輯方法,解析多模態信息處理中的關鍵內部機制。同時,探索視覺、音頻等模態向文本嵌入空間對齊的過程,為跨模態理解提供支持。
-
模型架構的透明化:改進架構設計,深入分析不同模塊在跨模態信息處理中的作用,揭示從模態輸入到集成表示的全流程信息流動。這將提升模型的魯棒性與信任度,並為實際應用提供更可靠的支持。
-
訓練與推理的統一解釋框架:在訓練階段優先考慮可解釋性和與人類理解的對齊,推理階段提供實時、任務適配的可解釋結果。通過建立覆蓋訓練與推理的統一評估基準,開發出透明、可靠且高性能的多模態系統。
未來的研究不僅需要從技術層面推動多模態大模型的可解釋性,還需注重其在人類交互和實際應用中的落地,為模型的透明性、可信性、魯棒性和公平性提供堅實保障。



















